从广义上讲,它们可以分为三类
- GPT-like (also called auto-regressive Transformer models)
- BERT-like (also called auto-encoding Transformer models)
- BART/T5-like (also called sequence-to-sequence Transformer models)
上面提到的所有 Transformer 模型(GPT,BERT,BART,T5 等)都已作为语言模型进行训练。这意味着他们已经以自我监督的方式接受了大量原始文本的培训。自我监督学习是一种训练类型,其中目标从模型的输入中自动计算出来。这意味着不需要人类来标记数据
这种类型的模型发展了对它所训练的语言的统计理解,但它对于特定的实际任务并不是很有用。因此,一般的预训练模型然后经历一个称为迁移学习的过程。在此过程中,模型以监督方式进行微调 - 即使用人工注释的标签 - 针对给定任务。
任务的一个例子是在阅读了前 n 个单词后预测句子中的下一个单词。这称为因果语言建模 causal language modeling,因为输出取决于过去和现在的输入,而不是未来的输入。
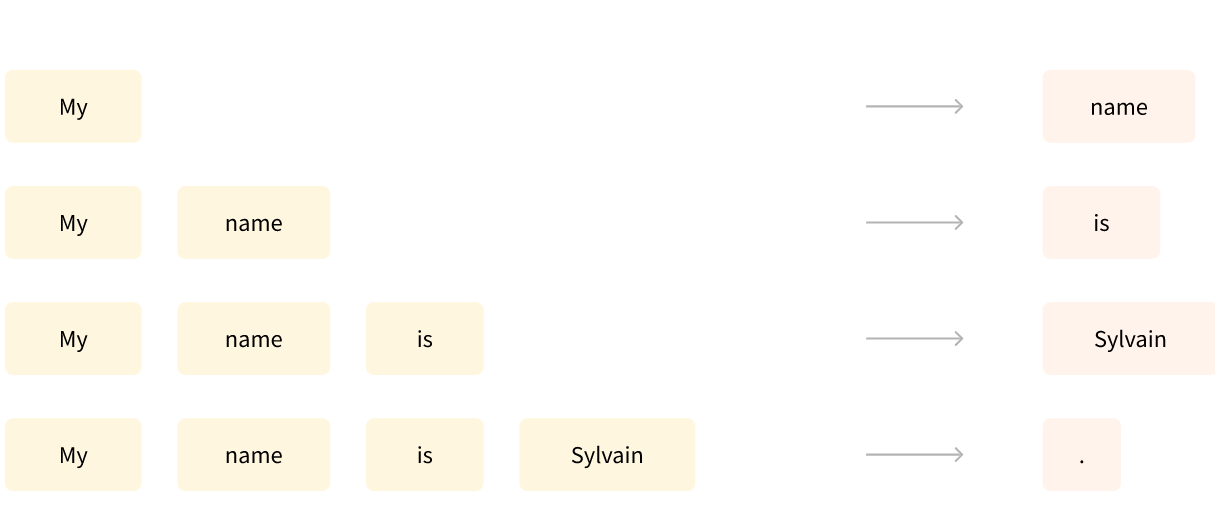
另一个例子是掩码语言建模 masked language modeling,其中模型预测句子中被掩蔽的单词。

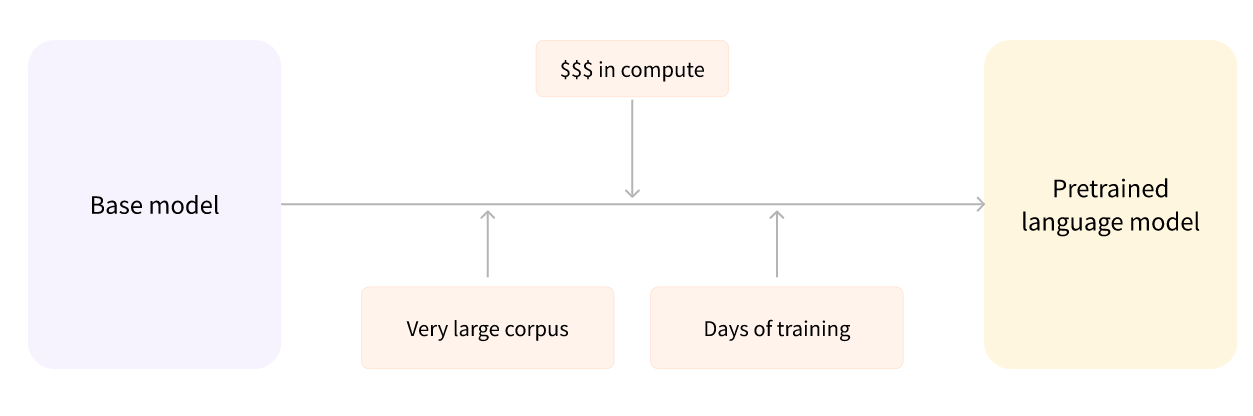
预训练 Pretraining 是从头开始训练模型的行为:权重被随机初始化,训练在没有任何先验知识的情况下开始。
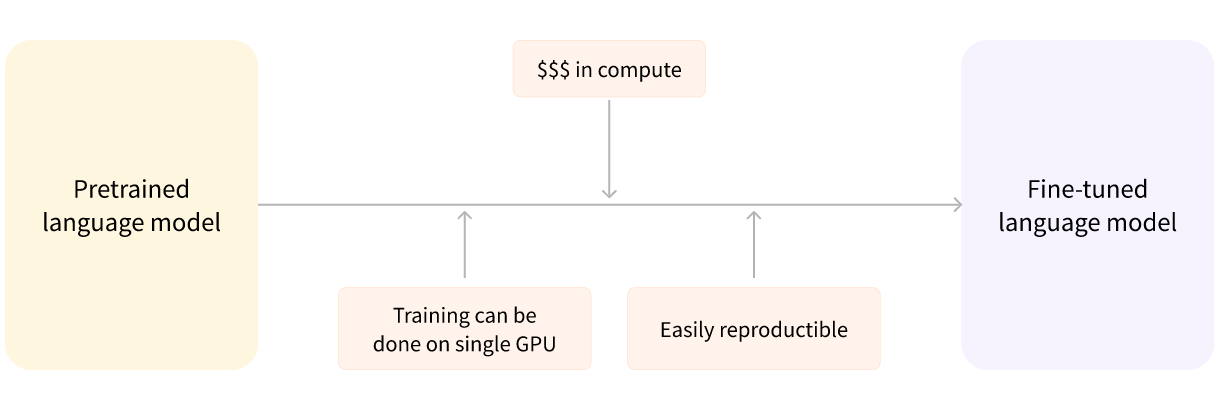
另一方面,微调是在预先训练模型后完成的训练。若要执行微调,请首先获取预训练的语言模型,然后使用特定于任务的数据集执行其他训练。等等 - 为什么不直接为最终任务进行训练呢?有几个原因:
- 预训练模型已经在与微调数据集有一些相似之处的数据集上进行训练。因此,微调过程能够利用初始模型在预训练期间获得的知识(例如,对于 NLP 问题,预训练的模型将对您用于任务的语言具有某种统计理解)。
- 由于预训练模型已经在大量数据上进行训练,因此微调需要更少的数据来获得体面的结果。
- 出于同样的原因,获得良好结果所需的时间和资源要少得多。
例如,可以利用在英语上训练的预训练模型,然后在 arXiv 语料库上对其进行微调,从而产生基于科学 / 研究的模型。微调只需要有限数量的数据:预训练模型获得的知识是 “转移的”,因此称为迁移学习。
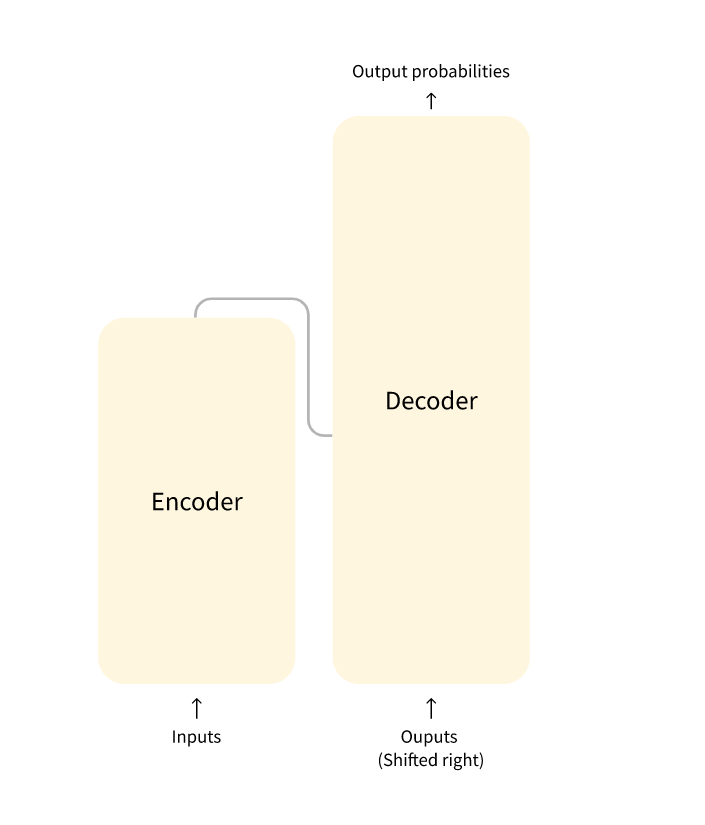
一般结构
该模型主要由两个块组成:
- 编码器(左):编码器接收输入并构建输入的表示(其特征)。这意味着模型经过优化,可以从输入中获取理解。
- 解码器(右):解码器使用编码器的表示(特征)以及其他输入来生成目标序列。这意味着模型已针对生成输出进行了优化。
这些部分中的每一个都可以独立使用,具体取决于任务:
- 仅编码器模型:适用于需要了解输入的任务,例如句子分类和命名实体识别。
- 仅解码器模型:适用于生成任务,如文本生成。
- 编码器 - 解码器模型或序列到序列模型:适用于需要输入的生成任务,如翻译或汇总 summarization。
Attention layers
在处理每个单词的表示时,该层将告诉模型特别注意您传递的句子中的某些单词(并且或多或少忽略其他单词)。
要将此置于上下文中,请考虑将文本从英语翻译成法语的任务。给定输入 “You like this course”,,翻译模型还需要注意相邻的单词 “You” 才能获得单词 “like” 的正确翻译,因为在法语中,动词 “like” 根据主语的不同而有不同的共轭。然而,句子的其余部分对该词的翻译没有用处。同样,在翻译 “this” 时,模型也需要注意 “course” 这个词,因为 “this” 的翻译方式不同,这取决于相关的名词是阳性还是阴性。同样,句子中的其他单词对于 “this” 的翻译无关紧要。对于更复杂的句子(和更复杂的语法规则),模型需要特别注意句子中可能出现的更远的单词,以正确翻译每个单词。
The original architecture
The Transformer 架构最初是为翻译而设计的。在训练期间,编码器接收特定语言的输入(句子),而解码器接收所需目标语言的相同句子。在编码器中,注意力层可以使用句子中的所有单词(因为正如我们刚刚看到的,给定单词的翻译可以取决于句子中它之后和之前的内容)。然而,解码器是按顺序工作的,只能注意它已经翻译的句子中的单词(因此,只有当前生成的单词之前的单词)。例如,当我们预测了翻译目标的前三个单词时,我们将它们交给解码器,然后解码器使用编码器的所有输入来尝试预测第四个单词。
为了在训练期间加快速度(当模型可以访问目标句子时),解码器被输入整个目标,但不允许使用未来的单词(如果在尝试预测位置 2 的单词时可以访问位置 2 的单词,那么问题不会很难!例如,当尝试预测第四个单词时,注意力层将只能访问位置 1 到 3 中的单词。
原始的 Transformer 架构如下所示,左侧是编码器,右侧是解码器:
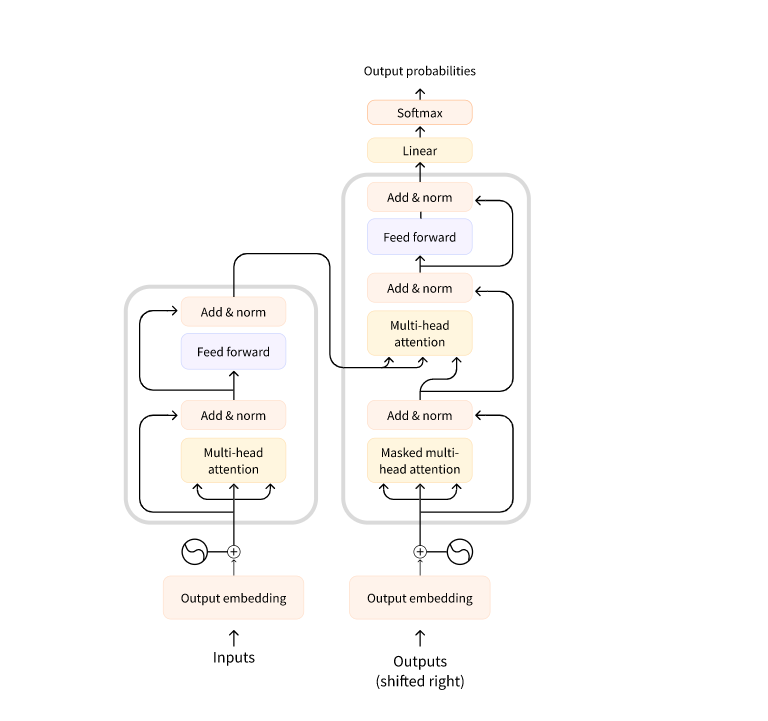
请注意,解码器块中的第一个注意层关注解码器的所有(过去)输入,但第二个注意层使用编码器的输出。因此,它可以访问整个输入句子,以最好地预测当前单词。这非常有用,因为不同的语言可以具有语法规则,将单词按不同的顺序排列,或者句子后面提供的某些上下文可能有助于确定给定单词的最佳翻译。
The attention mask 还可以在编码器 / 解码器中使用,以防止模型注意某些特殊单词 - 例如,在批处理句子时用于使所有输入具有相同长度的特殊填充词。
Architectures vs. checkpoints
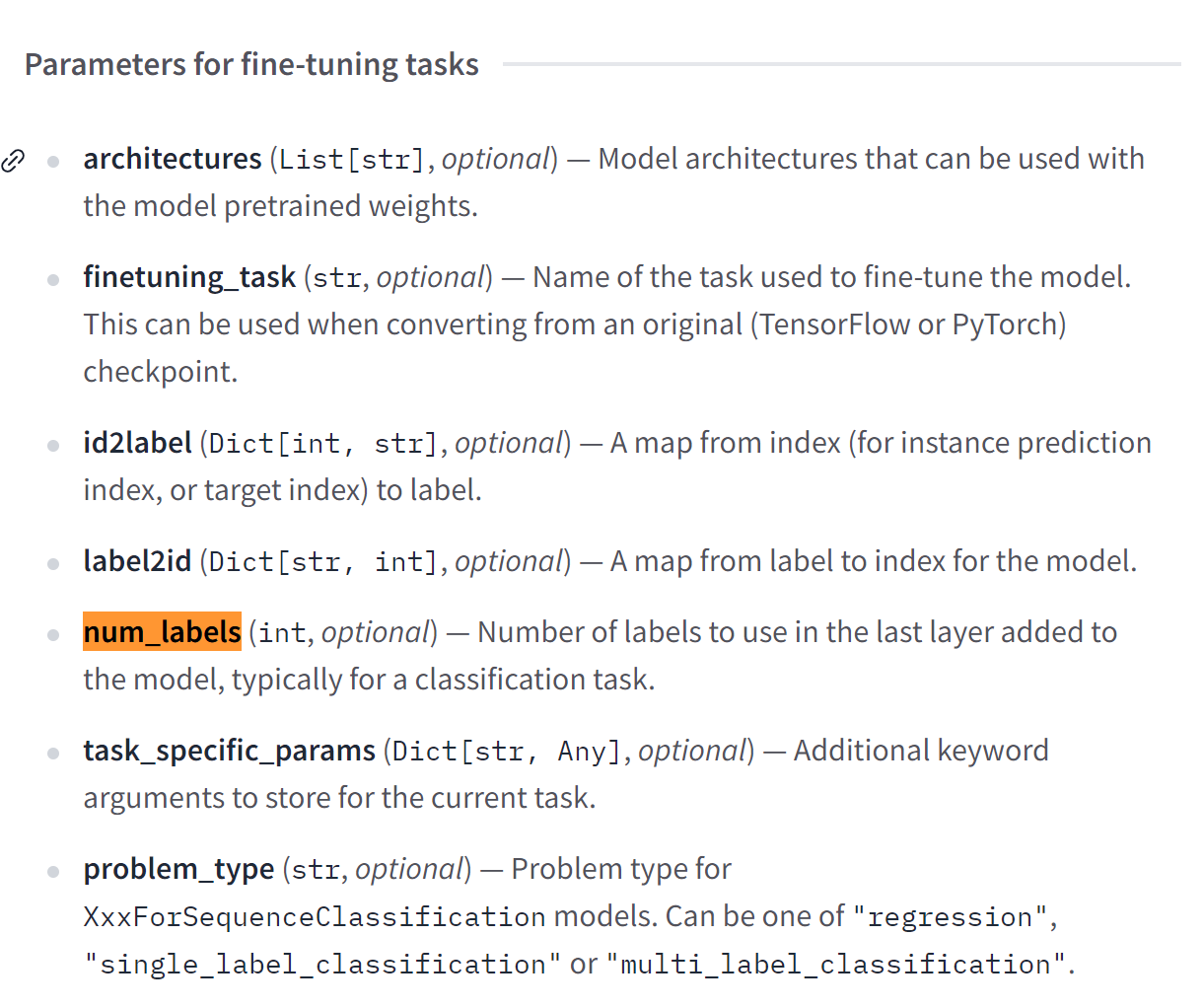
Architecture: This is the skeleton of the model — the definition of each layer and each operation that happens within the model. 是模型的骨架 - 每个层的定义以及模型中发生的每个操作。
Checkpoints: These are the weights that will be loaded in a given architecture. 这些是将在给定体系结构中加载的权重。
Model: This is an umbrella term that isn’t as precise as “architecture” or “checkpoint”: it can mean both. This course will specify architecture or checkpoint when it matters to reduce ambiguity. 这是一个总括性术语,不如 “架构” 或 “检查点” 精确:它可以表示两者。本课程将在需要减少歧义时指定架构或检查点。
Encoder models
编码器模型仅使用转换器模型的编码器。在每个阶段,注意力层可以访问初始句子中的所有单词。这些模型通常被描述为具有 “双向” 注意,并且通常称为自动编码模型。
这些模型的预训练通常围绕着以某种方式破坏给定的句子(例如,通过屏蔽其中的随机单词)并让模型找到或重建初始句子。
编码器模型最适合需要了解完整句子的任务,例如句子分类、命名实体识别(以及更一般的单词分类)和提取式问答。
该系列型号的代表包括:
ALBERT
BERT
DistilBERT
ELECTRA
RoBERTa
Decoder models
解码器模型仅使用转换器模型的解码器。在每个阶段,对于给定的单词,注意力层只能访问句子中位于它前面的单词。这些模型通常称为自回归模型。
解码器模型的预训练通常围绕着预测句子中的下一个单词。
这些模型最适合于涉及文本生成的任务。
该系列型号的代表包括:
CTRL
GPT
GPT-2
Transformer XL
Sequence-to-sequence models
编码器 - 解码器模型(也称为序列到序列模型)使用转换器体系结构的两个部分。在每个阶段,编码器的注意力层可以访问初始句子中的所有单词,而解码器的注意力层只能访问输入中给定单词之前的单词。
这些模型的预训练可以使用编码器或解码器模型的目标来完成,但通常涉及更复杂的事情。例如,T5 的预训练是通过将文本的随机跨度(可以包含多个单词)替换为单个掩码特殊单词,然后目标是预测此掩码单词替换的文本。
序列到序列模型最适合于围绕根据给定输入生成新句子的任务,例如摘要、翻译或生成式问答。
Representatives of this family of models include:
BART
mBART
Marian
T5
Bias and limitations
如果您的目的是在生产中使用预训练模型或微调版本,请注意,虽然这些模型是功能强大的工具,但它们存在局限性。其中最大的问题是,为了能够对大量数据进行预训练,研究人员经常抓取他们能找到的所有内容,从互联网上获得的最佳和最差的内容进行抓取。
from transformers import pipeline | |
unmasker = pipeline("fill-mask", model="bert-base-uncased") | |
result = unmasker("This man works as a [MASK].") | |
print([r["token_str"] for r in result]) | |
result = unmasker("This woman works as a [MASK].") | |
print([r["token_str"] for r in result]) | |
['lawyer', 'carpenter', 'doctor', 'waiter', 'mechanic'] | |
['nurse', 'waitress', 'teacher', 'maid', 'prostitute'] | |
result | |
{'score': 0.039145778864622116, | |
'token': 7500, | |
'token_str': 'farmer', | |
'sequence': 'this man works as a farmer.'}, | |
{'score': 0.03280145302414894, | |
'token': 6883, | |
'token_str': 'businessman', | |
'sequence': 'this man works as a businessman.'}, | |
{'score': 0.029292339459061623, | |
'token': 3460, | |
'token_str': 'doctor', | |
'sequence': 'this man works as a doctor.'}] |
当被要求填写这两个句子中缺失的单词时,模型只给出了一个无性别的答案(服务员 / 女服务员)。其他的通常是与一个特定性别相关的工作职业 - 是的,最终进入了模特与 “女性” 和 “工作” 相关的前 5 种可能性。即使 BERT 是罕见的 Transformer 模型之一,而不是通过从互联网上抓取数据而构建的,而是使用明显中立的数据(它是在英语维基百科和 BookCorpus 数据集上训练的)构建的,也会发生这种情况。
因此,当您使用这些工具时,您需要牢记您正在使用的原始模型很容易产生性别歧视,种族主义或恐同内容。对数据进行微调模型不会使这种内在偏差消失。
Behind the pipeline
from transformers import pipeline | |
classifier = pipeline("sentiment-analysis") | |
classifier( | |
[ | |
"I've been waiting for a HuggingFace course my whole life.", | |
"I hate this so much!", | |
] | |
) | |
[{'label': 'POSITIVE', 'score': 0.9598047137260437}, | |
{'label': 'NEGATIVE', 'score': 0.9994558095932007}] |
pipeline 将三个步骤组合在一起:预处理、通过模型传递输入和后处理:
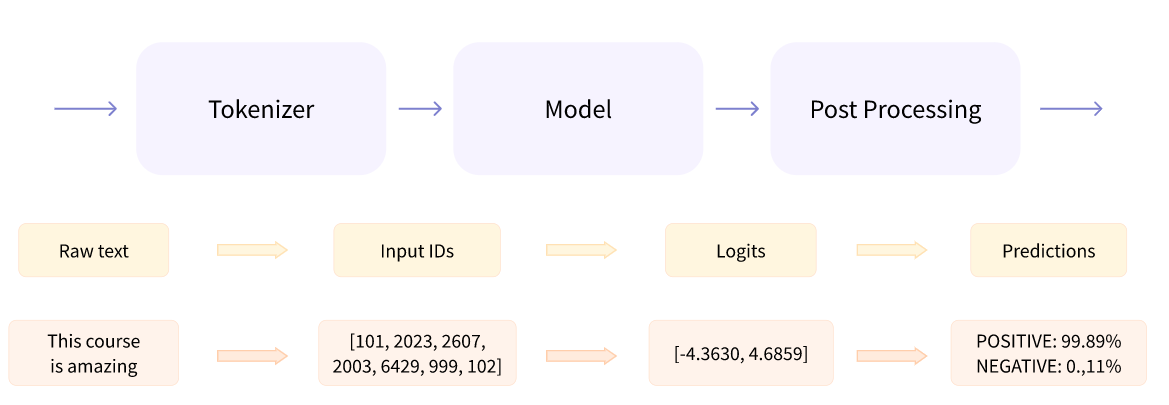
Preprocessing with a tokenizer
与其他神经网络一样,Transformer 模型不能直接处理原始文本,因此我们 pipeline 的第一步是将文本输入转换为模型可以理解的数字。为此,我们使用 tokenizer,它将负责:
将输入拆分为称为 tokens 的单词、子单词或符号(如标点符号)
将每个 tokens 映射到一个整数
添加可能对模型有用的其他输入
所有这些预处理都需要以与预训练模型时完全相同的方式完成,因此我们首先需要从模型中心下载该信息。为此,我们使用类 AutoTokenizer 及其方法 from_pretrained ()。使用我们模型的 checkpoint 名称,它将自动获取与模型的分词器关联的数据并将其缓存(因此仅在您第一次运行以下代码时下载)
Since the default checkpoint of the sentiment-analysis pipeline is distilbert-base-uncased-finetuned-sst-2-english (you can see its model card here), we run the following:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
一旦我们有了分词器,我们就可以直接将我们的句子传递给它,我们将得到一个字典,该字典已准备好提供给我们的模型!唯一要做的就是将输入 ID 列表转换为张量。
为了指定我们想要返回的张量类型(PyTorch,TensorFlow 或普通的 NumPy),我们使用参数:return_tensors
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
padding 填充 truncation 截断
以下是 PyTorch 张量的结果:
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
输出本身是一个包含两个键 input_ids 和 attention_mask 的字典。 input_ids 包含两行整数(每个句子一行),它们是每个句子中标记的唯一标识符。
Going through the model
Transformers 提供了一个 AutoModel 类,该类还具有一个方法:AutoModel.from_pretrained ()
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)

AutoModel 没有专门的头,加载模型时提示有些权重并没有被加载到模型中
此体系结构仅包含基本 Transformer 模块:给定一些输入,它输出我们称之为 hidden states 隐藏状态(也称为 features)的内容。对于每个模型输入,我们将检索一个高维向量,该向量表示 Transformer 模型对该输入的上下文理解。
虽然这些隐藏状态本身很有用,但它们通常是模型另一部分(称为头部)的输入。在第 1 章中,不同的任务可以使用相同的体系结构执行,但是这些任务中的每一个都有一个与之关联的不同头。
A high-dimensional vector?
Transformer 模块的矢量输出通常很大。它通常有三个维度:
Batch size 批大小:一次处理的序列数(在我们的示例中为 2)。
Sequence length: 序列长度:序列的数字表示形式的长度(在我们的示例中为 16)。
Hidden size 隐藏大小:每个模型输入的矢量维度。
它被称为 “高维”,因为最后一个值。隐藏大小可能非常大(768 对于较小的模型很常见,在较大的模型中,这可以达到 3072 或更多)。
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
torch.Size([2, 16, 768])
请注意,Transformers 模型的🤗输出的行为类似于 namedtuples or dictionaries。您可以通过属性(就像我们所做的那样)或按键(outputs ["last_hidden_state"]))甚至按索引访问元素,如果您确切地知道要查找的内容(outputs [0])的位置,则可以访问元素。
Model heads: Making sense out of numbers
模型头将隐藏状态的高维向量作为输入,并将它们投影到不同的维度上。它们通常由一个或几个线性层组成:
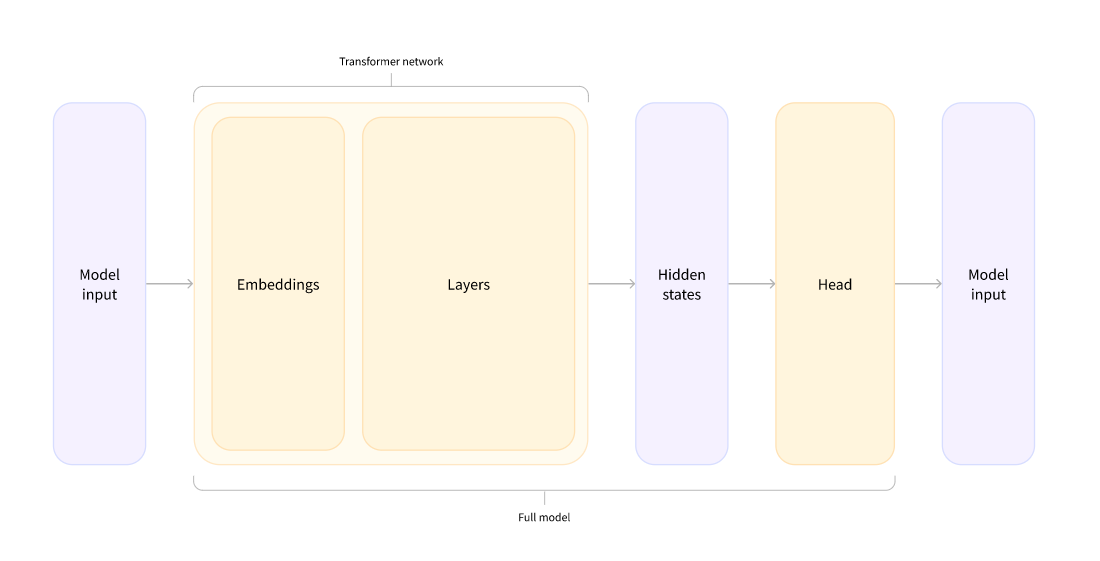
Transformer 模型的输出直接发送到模型头进行处理。
在此图中,模型由其嵌入层和后续层表示。嵌入层将标记化输入中的每个输入 ID 转换为表示关联令牌的向量。随后的层使用注意力机制操纵这些向量,以产生句子的最终表示。

对于我们的示例,我们需要一个具有序列分类头的模型(以便能够将句子分类为正数或负数)。因此,我们实际上不会使用该类,而是 AutoModelForSequenceClassification
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
模型加载时没有其他的提示信息
现在,如果我们看一下输入的形状,维度会低得多:模型头将我们之前看到的高维向量作为输入,并输出包含两个值的向量(每个标签一个):
print(outputs.logits.shape)
torch.Size([2, 2])
由于我们只有两个句子和两个标签,因此我们从模型中获得的结果是形状为 2 x 2。
Postprocessing the output
我们从模型中获得的输出值本身并不一定有意义。让我们来看看:
print(outputs.logits)
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
我们的模型预测了第一句话和第二句话。这些不是概率,而是 logits,即模型最后一层输出的原始、非规范化分数。要转换为概率,它们需要经过 SoftMax 层(所有 Transformers 模型都🤗输出 logits,因为用于训练的损失函数通常会将最后一个激活函数(例如 SoftMax)与实际的损失函数(例如交叉熵)融合在一起)
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)
我们的模型预测了第一句话 [0.0402, 0.9598] 和第二句话 [0.9995, 0.0005] 。这些不是概率,而是 logits,即模型最后一层输出的原始、非规范化分数。要转换为概率,它们需要经过 SoftMax 层(所有 Transformers 模型都🤗输出 logits,因为用于训练的损失函数通常会将最后一个激活函数(例如 SoftMax)与实际的损失函数(例如交叉熵)融合在一起):
要获得与每个位置对应的标签,我们可以检查模型配置的属性 id2label
model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}
ow we can conclude that the model predicted the following:
First sentence: NEGATIVE: 0.0402, POSITIVE: 0.9598
Second sentence: NEGATIVE: 0.9995, POSITIVE: 0.0005
Creating a Transformer
初始化 BERT 模型需要做的第一件事是加载一个配置对象:
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config
model = BertModel(config)
该配置包含许多用于构建模型的属性:
print(config)
BertConfig {
[...]
"hidden_size": 768,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
[...]
}
Different loading methods
从默认配置创建模型会使用随机值对其进行初始化:
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
# Model is randomly initialized!
该模型可以在此状态下使用,但它会输出胡言乱语;它需要首先接受训练。我们可以在手头的任务上从头开始训练模型,但正如您在第 1 章中看到的那样,这将需要很长时间和大量数据,并且它将对环境产生不可忽视的影响。为了避免不必要和重复的工作,必须能够共享和重用已经过训练的模型。
加载已经训练的 Transformer 模型很简单 — 我们可以使用以下方法 from_pretrained () 执行此操作:from_pretrained ()
from transformers import BertModel
model = BertModel.from_pretrained("bert-base-cased")
正如您之前看到的,我们可以用等效的类 AutoModel 替换 BertModel。从现在开始,我们将这样做,因为这会产生与 checkpoint 无关的代码;如果您的代码适用于一个 checkpoint,则它应该与另一个 checkpoint 无缝协作。即使体系结构不同,只要 checkpoint 是针对类似任务(例如,情绪分析任务)训练的,这也适用。
Saving methods
model.save_pretrained("directory_on_my_computer")
这会将两个文件保存到磁盘:
ls directory_on_my_computer
config.json pytorch_model.bin
pytorch_model.bin 文件称为状态字典;它包含模型的所有权重。这两个文件是相辅相成的。配置对于了解模型的体系结构是必要的,而模型权重是模型的参数。
Using a Transformer model for inference 使用转换器模型进行推理
假设我们有几个序列
sequences = ["Hello!", "Cool.", "Nice!"]
分词器将这些转换为词汇索引,这些词汇表通常称为输入 ID。现在,每个序列都是一个数字列表!生成的输出为
encoded_sequences = [
[101, 7592, 999, 102],
[101, 4658, 1012, 102],
[101, 3835, 999, 102],
]
这是编码序列的列表:列表的列表。张量只接受矩形形状(思考矩阵)。这个 “数组” 已经是矩形的,所以把它转换成张量很容易:
import torch
model_inputs = torch.tensor(encoded_sequences)
Using the tensors as inputs to the model
While the model accepts a lot of different arguments, only the input IDs are necessary.
Tokenizers
分词器是 NLP 管道的核心组件之一。它们只有一个目的:将文本转换为可由模型处理的数据。模型只能处理数字,因此分词器需要将我们的文本输入转换为数字数据。
Word-based
我想到的第一种类型的分词器是基于单词的。它通常很容易设置和使用,只有几条规则,而且通常会产生不错的结果。例如,在下图中,目标是将原始文本拆分为单词,并为每个单词找到一个数字表示形式:

Character-based
Subword tokenization 子词标记化
子词标记化算法依赖于这样一个原则,即常用词不应拆分为较小的子词,但稀有词应分解为有意义的子词。
例如,“annoyingly” 可能被认为是一个罕见的词,可以分解为 “烦人” 和 “ly”。这两者都可能更频繁地作为独立的子词出现,而与此同时,“烦人地” 的含义被 “烦人” 和 “ly” 的复合含义所保留。
加载和保存
from_pretrained () 加载
save_pretrained () 保存
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
与 AutoModel 类似,该类 AutoTokenizer 将根据 checkpoint 名称在库中获取正确的分词器类,并且可以直接与任何检查点一起使用
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
现在,我们可以使用分词器
tokenizer("Using a Transformer network is simple")
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
保存分词器与保存模型相同:
tokenizer.save_pretrained("directory_on_my_computer")
Encoding 编码
将文本转换为数字称为编码。编码通过两个步骤完成:标记化,然后转换为输入 ID。
正如我们所看到的,第一步是将文本拆分为单词(或单词的一部分,标点符号等),通常称为标记。有多个规则可以控制该过程,这就是为什么我们需要使用模型的名称实例化分词器,以确保我们使用的规则与预先训练模型时使用的规则相同。
第二步是将这些令牌转换为数字,这样我们就可以从中构建一个张量并将它们提供给模型。为此,分词器具有一个词汇表,这是我们使用该方法实例化它时下载的部分。同样,我们需要使用与预训练模型时相同的词汇。from_pretrained ()
Tokenization
The tokenization process is done by the tokenize() method of the tokenizer:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
此分词器是子词分词器:它拆分单词,直到获得可由其词汇表表示的标记。这里的 transformer 情况就是 ,它被分成两个标记 transform and ##er.
From tokens to input IDs
到输入 ID 的转换由分词器方法 convert_tokens_to_ids () 处理
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
[7993, 170, 11303, 1200, 2443, 1110, 3014]
Decoding
解码正朝着相反的方向发展:从词汇索引中,我们想要得到一个字符串。这可以通过以下方式使用方法完成:decode ()
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
'Using a Transformer network is simple'
请注意,该 decode 方法不仅将索引转换回标记,而且还将属于同一单词的标记组合在一起以生成可读的句子。当我们使用预测新文本(从提示生成的文本,或用于转换或摘要等序列到序列问题)的模型时,此行为将非常有用
Models expect a batch of inputs
Handling multiple sequences
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor(ids)
# This line will fail.
model(input_ids)
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
问题在于,我们向模型发送了单个序列,而🤗变形金刚模型默认需要多个句子。在这里,当我们将分词器应用于时,我们尝试在幕后执行它所做的一切,但是如果您仔细观察,您会发现它不仅将输入 ID 列表转换为张量,而且还在其上添加了一个维度:sequence
tokenized_inputs = tokenizer(sequence, return_tensors="pt")
print(tokenized_inputs["input_ids"])
tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,
2607, 2026, 2878, 2166, 1012, 102]])
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
input_ids = torch.tensor([ids])
print("Input IDs:", input_ids)
output = model(input_ids)
print("Logits:", output.logits)
Input IDs: [[ 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012]]
Logits: [[-2.7276, 2.8789]]
Padding the inputs
以下列表列表无法转换为张量:
batched_ids = [
[200, 200, 200],
[200, 200]
]
为了解决这个问题,我们将使用填充来使我们的张量具有矩形形状。填充通过向具有较少值的句子添加一个称为填充标记 padding token 的特殊单词来确保我们的所有句子具有相同的长度。例如,如果您有 10 个包含 10 个单词的句子和 1 个包含 20 个单词的句子,则填充将确保所有句子包含 20 个单词。在我们的示例中,生成的张量如下所示:
padding_id = 100
batched_ids = [
[200, 200, 200],
[200, 200, padding_id],
]
填充令牌 ID 可在 tokenizer.pad_token_id 中找到。让我们使用它,通过模型单独发送我们的两个句子,并一起批处理:
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequence1_ids = [[200, 200, 200]]
sequence2_ids = [[200, 200]]
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
print(model(torch.tensor(sequence1_ids)).logits)
print(model(torch.tensor(sequence2_ids)).logits)
print(model(torch.tensor(batched_ids)).logits)
tensor([[ 1.5694, -1.3895]], grad_fn=<AddmmBackward>)
tensor([[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
tensor([[ 1.5694, -1.3895],
[ 1.3373, -1.2163]], grad_fn=<AddmmBackward>)
这是因为 Transformer 模型的关键特征是将每个令牌上下文化 contextualize 的注意力层。这些将考虑填充标记,因为它们关注序列的所有标记。为了在通过模型传递不同长度的单个句子时,或者在传递具有相同句子并应用了填充的批处理时获得相同的结果,我们需要告诉这些注意层忽略填充标记。这是通过使用注意力掩码完成的。
Attention masks
注意力掩码是与输入 ID 张量形状完全相同的张量,填充有 0 和 1:1 表示应该注意相应的标记,0 表示不应注意相应的标记(即,它们应该被模型的注意力层忽略)。
batched_ids = [
[200, 200, 200],
[200, 200, tokenizer.pad_token_id],
]
attention_mask = [
[1, 1, 1],
[1, 1, 0],
]
outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)
tensor([[ 1.5694, -1.3895],
[ 0.5803, -0.4125]], grad_fn=<AddmmBackward>)
Longer sequences
对于 Transformer 模型,我们可以传递模型的序列长度是有限制的。大多数模型处理最多 512 或 1024 个令牌的序列,当要求处理较长的序列时,这些序列会崩溃。此问题有两种解决方案:
使用具有较长的受支持序列长度的模型。
截断序列。
模型具有不同支持的序列长度,有些专门处理非常长的序列。Longformer 就是一个例子,另一个例子是 LED。如果您正在处理需要很长序列的任务,我们建议您查看这些模型
否则,我们建议您通过指定参数来截断序列:max_sequence_length
sequence = sequence[:max_sequence_length]
Putting it all together
在过去的几节中,我们一直在尽最大努力手工完成大部分工作。我们探讨了分词器的工作原理,并研究了分词化、转换为输入 ID、填充、截断和注意力掩码。
但是,正如我们在第 2 节中所看到的,🤗 Transformers API 可以通过一个高级函数为我们处理所有这些问题,我们将在这里深入探讨。当您直接调用句子时,您将获得准备通过模型传递的输入:tokenizer
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
在这里,变量 model_inputs tokenizer 包含模型正常运行所需的所有内容。对于 DistilBERT,这包括输入 ID 以及注意力掩码。接受其他输入的其他模型也将具有对象 tokenizer 的这些输出。
正如我们将在下面的一些示例中看到的那样,此方法非常强大。首先,它可以标记单个序列:
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
它还一次处理多个序列,API 中没有变化:
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
model_inputs = tokenizer(sequences)
它可以根据几个目标进行填充:
# Will pad the sequences up to the maximum sequence length
model_inputs = tokenizer(sequences, padding="longest")
# Will pad the sequences up to the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, padding="max_length")
# Will pad the sequences up to the specified max length
model_inputs = tokenizer(sequences, padding="max_length", max_length=8)
它还可以截断序列:
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Will truncate the sequences that are longer than the model max length
# (512 for BERT or DistilBERT)
model_inputs = tokenizer(sequences, truncation=True)
# Will truncate the sequences that are longer than the specified max length
model_inputs = tokenizer(sequences, max_length=8, truncation=True)
该 tokenizer 对象可以处理到特定框架张量的转换,然后可以直接将其发送到模型。例如,在下面的代码示例中,我们提示分词器从不同的框架返回张量 — "pt" 返回 PyTorch 张量,"tf" 返回 TensorFlow 张量,"np" 并返回 NumPy 数组:
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
# Returns PyTorch tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="pt")
# Returns TensorFlow tensors
model_inputs = tokenizer(sequences, padding=True, return_tensors="tf")
# Returns NumPy arrays
model_inputs = tokenizer(sequences, padding=True, return_tensors="np")
Special tokens
如果我们看一下分词器返回的输入 ID,我们会发现它们与我们之前的情况略有不同:
sequence = "I've been waiting for a HuggingFace course my whole life."
model_inputs = tokenizer(sequence)
print(model_inputs["input_ids"])
tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
在开头添加了一个令牌 ID,在末尾添加了一个令牌 ID。让我们解码上面的两个 ID 序列,看看这是关于什么的:
print(tokenizer.decode(model_inputs["input_ids"]))
print(tokenizer.decode(ids))
"[CLS] i've been waiting for a huggingface course my whole life. [SEP]"
"i've been waiting for a huggingface course my whole life."
分词器在开头添加了特殊单词 [CLS],在末尾添加了特殊单词 [SEP]。这是因为模型是用它们预先训练的,所以为了获得相同的推理结果,我们还需要添加它们。请注意,某些模型不会添加特殊单词,也不会添加不同的单词;模型也可以仅在开头添加这些特殊单词,或仅在末尾添加这些特殊单词。在任何情况下,分词器都知道哪些是预期的,并将为您处理此问题。
Wrapping up: From tokenizer to model 总结:从分词器到模型
现在我们已经看到了对象在应用于文本时使用的所有单个步骤,让我们最后一次看看它如何处理多个序列(填充!),很长的序列(截断!)以及多种类型的张量及其主 API:tokenizer
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
处理数据
下面是我们如何在 PyTorch 中的一个批处理上训练一个序列分类器:
import torch
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
# Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
# This is new
batch["labels"] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
loss = model(**batch).loss
loss.backward()
optimizer.step()
当然,仅仅用两句话训练模型不会产生非常好的结果。为了获得更好的结果,您需要准备一个更大的数据集。
在本节中,我们将使用 MRPC(Microsoft Research Paraphrase Corpus)数据集作为示例,该数据集由 William B. Dolan 和 Chris Brockett 在一篇论文中介绍。该数据集由 5,801 对句子组成,带有一个标签,指示它们是否是释义(即,如果两个句子的含义相同)。我们在本章中选择了它,因为它是一个小数据集,所以很容易对其进行训练。
Loading a dataset from the Hub
数据集库提供了一个非常简单的命令,用于在 Hub 上下载和缓存数据集。我们可以像这样下载 MRPC 数据集:
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
如您所见,我们得到一个包含训练集、验证集和测试集的 DatasetDict 对象。其中每个都包含几列(sentence1,sentence2, label, and idx ) 和 num_rows 可变行数,这些行是每个集中的元素数(因此,训练集中有 3,668 对句子,验证集中有 408 对,测试集中有 1,725 对)。
我们可以通过索引来访问对象 raw_datasets 中的每对句子,就像使用字典一样
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
{'idx': 0,
'label': 1,
'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
我们可以看到标签已经是整数,因此我们不必在那里进行任何预处理。要知道哪个整数对应于哪个标签,我们可以检查我们的 features of our raw_train_dataset. 这将告诉我们每列的类型:
raw_train_dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
在后台,label 类型为 ClassLabel,整数到标签名称的映射存储在 names 文件夹中。 0 对应于 not_equivalent , 1 并对应于 equivalent
Preprocessing a dataset
要预处理数据集,我们需要将文本转换为模型可以理解的数字。正如您在上一章中看到的,这是使用分词器完成的。我们可以向分词器提供一个句子或一系列句子,这样我们就可以直接标记每对的所有第一个句子和所有第二个句子
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
但是,我们不能只是将两个序列传递给模型,然后预测这两个句子是否是释义。我们需要将这两个序列作为一对处理,并应用适当的预处理。幸运的是,分词器还可以采用一对序列,并按照我们的 BERT 模型期望的方式进行准备:
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
{
'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
token_type_ids 告诉模型输入的哪一部分是第一个句子,哪个是第二个句子。
如果我们将 input_ids 里面的 ID 解码回单词:input_ids
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]', 'this', 'is', 'the', 'second', 'one', '.', '[SEP]']
请注意,如果选择其他检查点,则标记化输入中不一定包含 token_type_ids (例如,如果使用 DistilBERT 模型,则不会返回这些检查点)。只有当模型知道如何处理它们时,它们才会返回,因为它在预训练期间已经看到了它们
预处理训练数据集的一种方法是:
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
为了将数据保留为数据集,我们将使用 Dataset.map() 方法。这也为我们提供了一些额外的灵活性,如果我们需要完成更多的预处理而不仅仅是标记化。该方法 map () 通过在数据集的每个元素上应用一个函数来工作,因此让我们定义一个函数来标记我们的输入:
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
此函数采用字典(如数据集中的项),并返回一个包含键 input_ids, attention_mask, 和 token_type_ids 的新字典。请注意,如果字典包含多个样本(每个键作为句子列表),它也有效,因为如前所述,它对成对的句子列表起作用。这将使我们能够在调用 map () 中使用该选项 batched=True ,这将大大加快标记化。由来自 Tokenizers 库的 Rust 编写的分词器支持。 🤗这个分词器可以非常快,但前提是我们一次给它很多输入。
请注意,我们暂时在标记化函数中省略了该参数 padding。这是因为将所有样本填充到最大长度是无效的:最好在构建批处理时填充样本,因为这样我们只需要填充到该批中的最大长度,而不是整个数据集中的最大长度。当输入的长度非常可变时,这可以节省大量时间和处理能力!
以下是我们如何一次在所有数据集上应用标记化函数。我们在调用 map 中使用 batched=True,因此该函数一次应用于数据集的多个元素,而不是分别应用于每个元素。这样可以加快预处理速度。
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
数据集库应用此处理的方式🤗是向数据集添加新字段,预处理函数返回的字典中的每个键对应一个字段:
DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
我们 tokenize_function 返回一个字典,其中包含键 input_ids, attention_mask, and token_type_ids 和 ,因此这三个字段被添加到数据集的所有拆分中。请注意,如果我们的预处理函数返回了我们应用 map (). 到的数据集中现有键的新值,我们也可能更改了现有字段。
Dynamic padding 动态填充
负责将批处理中的样本组合在一起的函数称为逐份打印函数 collate function。这是一个参数,你可以在构建 DataLoader 时传递,默认值是一个函数,它将只将你的样本转换为 PyTorch 张量并连接它们(如果你的元素是列表,元组或字典,则递归)。在我们的例子中,这是不可能的,因为我们拥有的输入不会都具有相同的大小。我们故意推迟了填充,仅在必要时将其应用于每个批次,并避免过长的输入和大量的填充。这将使训练速度加快相当快,但请注意,如果您在 TPU 上进行训练,则可能会导致问题 - TPU 更喜欢固定形状,即使这需要额外的填充。
为了在实践中做到这一点,我们必须定义一个排序规则函数,该函数将对要一起批处理的数据集的项目应用正确的填充量。幸运的是,🤗变形金刚库通过 DataCollatorWithPadding 为我们提供了这样的功能。当您实例化它时,它需要一个分词器(以了解要使用的填充令牌,以及模型是否期望填充位于输入的左侧或右侧),并将执行您需要的一切:
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
为了测试这款新玩具,让我们从训练集中抓取一些样本,这些样本是我们想一起批量处理的。在这里,我们删除列 idx, sentence1, and sentence2,因为它们不需要并且包含字符串(并且我们不能使用字符串创建张量),并查看批处理中每个条目的长度:
samples = tokenized_datasets["train"][:8]
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
[len(x) for x in samples["input_ids"]]
[50, 59, 47, 67, 59, 50, 62, 32]
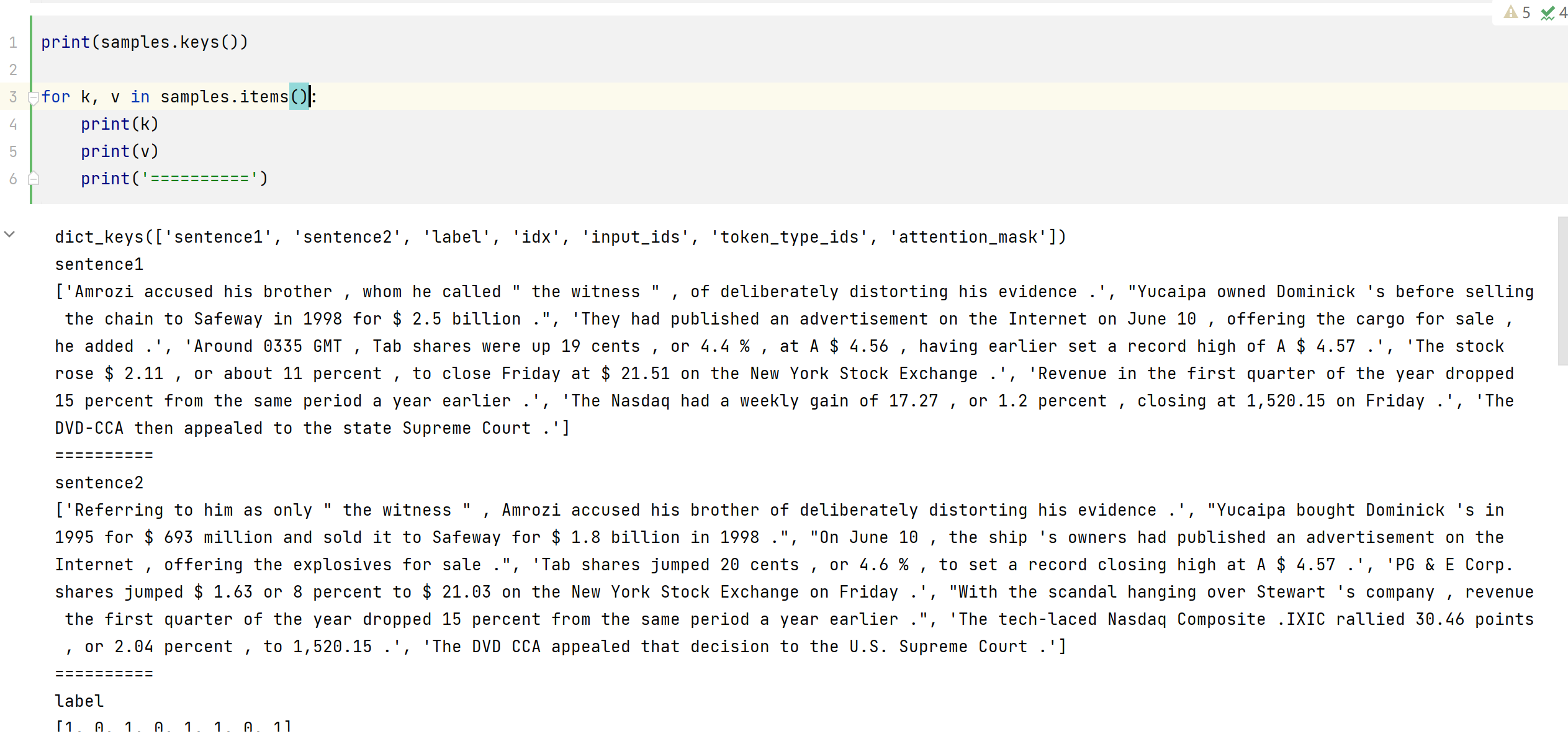
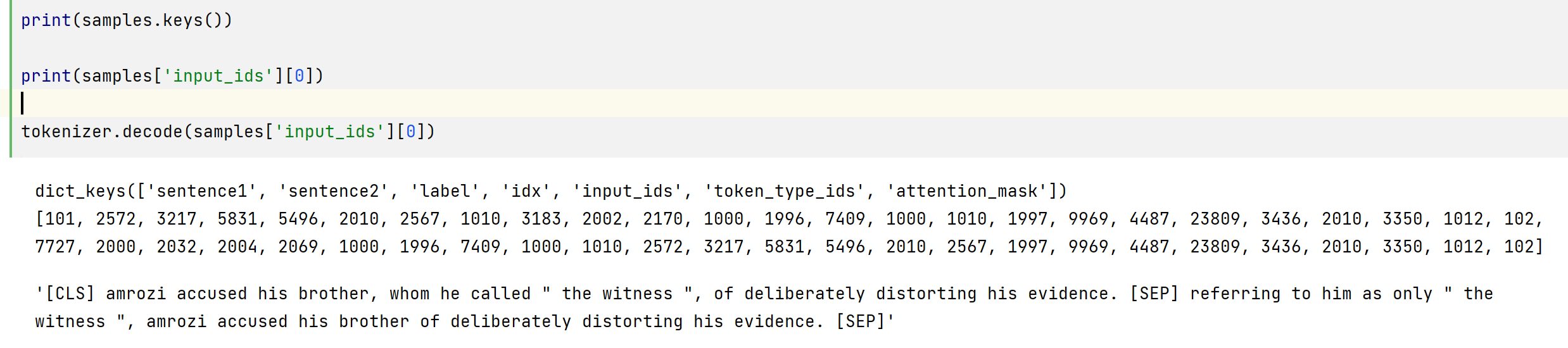
毫不奇怪,我们得到不同长度的样本,从 32 到 67。动态填充意味着该批次中的样品应全部填充到 67 的长度,即批次内的最大长度。如果没有动态填充,则必须将所有样本填充到整个数据集中的最大长度或模型可以接受的最大长度。让我们仔细检查一下,是否 data_collator 正确动态填充了批处理
batch = data_collator(samples)
{k: v.shape for k, v in batch.items()}
{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'token_type_ids': torch.Size([8, 67]),
'labels': torch.Size([8])}
Fine-tuning a model with the Trainer API
Transformers 提供了一个 Trainer 类,可帮助您微调它在数据集上提供的任何预训练模型。完成上一节中的所有数据预处理工作后,您只需几个步骤即可定义。最困难的部分可能是准备环境来运行 Trainer.train (),因为它在 CPU 上运行得非常慢。如果您没有设置 GPU,则可以在 Google Colab 上访问免费的 GPU 或 TPU。
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
Training
在我们定义 Trainer 之前的第一步是定义一个类 TrainingArguments,该类将包含将用于训练和评估的所有超参数。您必须提供的唯一参数是保存已训练模型的目录,以及沿途的检查点。对于所有其他内容,您可以保留默认值,这对于基本的微调应该非常有效。
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
第二步是定义我们的模型。与上一章一样,我们将使用带有两个标签的 AutoModelForSequenceClassification 类:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
https://huggingface.co/docs/transformers/v4.21.2/en/main_classes/configuration#transformers.PretrainedConfig.from_pretrained
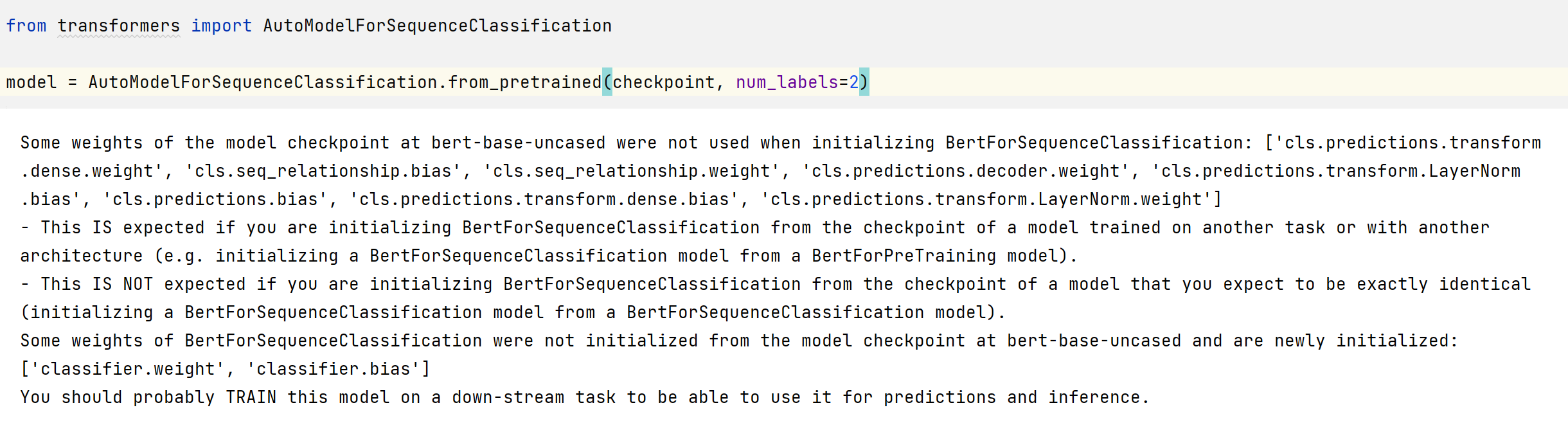
您会注意到,与第 2 章不同,在实例化此预训练模型后,您会收到一条警告。这是因为 BERT 尚未预先训练对句子对进行分类,因此已丢弃预训练模型的标头,并添加了适合序列分类的新标头。警告表明未使用某些权重(对应于丢弃的预训练头的权重),并且其他一些权重是随机初始化的(新头的权重)。最后,它鼓励您训练模型,这正是我们现在要做的事情。
一旦我们有了模型,我们就可以定义一个 Trainer ,方法是将它传递给到目前为止构建的所有对象 model - ,the training_args 的 ,训练和验证数据集,我们的 data_collator, and our tokenizer :
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
请注意,当您像我们在这里所做的那样传递 tokenizer 时,Trainer 使用的 data_collator 默认值将是前面定义的 DataCollatorWithPadding ,因此您可以跳过此调用中的行 data_collator=data_collator。在第 2 节中向您展示这部分处理仍然很重要
要在数据集上微调模型,我们只需要调用我们 Trainer 的 train ()
trainer.train()
这将开始微调(在 GPU 上应该需要几分钟),并每 500 步报告一次训练损失。但是,它不会告诉您模型的性能如何(或质量如何)。这是因为:
我们没有告诉 Trainer 在训练期间通过设置 evaluation_strategy 为 steps"(评估每个 eval_steps)或"epoch(在每个 epoch 结束时评估)来评估。
我们没有提供 Trainer 一个 compute_metrics () 函数来计算所述评估期间的指标(否则评估只会打印损失,这不是一个非常直观的数字)
Evaluation 评估
让我们看看如何构建一个有用的 compute_metrics () 函数,并在下次训练时使用它。该函数必须采用一个 EvalPrediction 对象(这是一个带有 predictions 字段和 label_ids 字段的命名元组),并将返回一个将字符串映射到浮点数的字典(字符串是返回的指标的名称,浮点数是它们的值)。要从我们的模型中获取一些预测,我们可以使用以下命令 Trainer.predict ()
predictions = trainer.predict(tokenized_datasets["validation"])
# predictions 的类型为 transformers.trainer_utils.PredictionOutput
print(predictions.predictions.shape, predictions.label_ids.shape)
(408, 2) (408,)
predict () 方法的输出是另一个命名元组,具有三个字段:predictions, label_ids, and metrics.。该 metrics 字段将仅包含所传递数据集的损失,以及一些时间指标(预测所花费的时间,总计和平均)。一旦我们完成 compute_metrics () 函数并将其传递给 Trainer,该字段还将包含 compute_metrics () 返回的指标。
如您所见, predictions 是一个形状为 408 x 2 的二维数组(408 是我们使用的数据集中的元素数)。这些是我们传递到的数据集的每个元素的 logits(如您在上一章中看到的,所有 Transformer 模型都返回 logits)。要将它们转换为可以与标签进行比较的预测,我们需要获取第二轴上具有最大值的索引
import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)
现在,我们可以将 preds 与标签进行比较。要构建 compute_metric () 函数,我们将依赖于评估库中的🤗指标。我们可以像加载数据集一样轻松地加载与 MRPC 数据集关联的指标,这次是使用 evaluate.load () 函数。返回的对象有一个我们可以用来计算指标的 compute () 方法:
import evaluate
metric = evaluate.load("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
您获得的确切结果可能会有所不同,因为模型头的随机初始化可能会更改其实现的指标。在这里,我们可以看到我们的模型在验证集上的准确率为 85.78%,F1 得分为 89.97。这是用于评估 GLUE 基准测试的 MRPC 数据集结果的两个指标。BERT 论文中的表格报告基本模型的 F1 得分为 88.9。这就是我们当前使用模型时的模型,这解释了更好的结果
将所有内容包装在一起,我们得到我们的函数:compute_metrics ()
def compute_metrics(eval_preds):
# eval_preds 的类型为 <transformers.trainer_utils.EvalPrediction object at 0x0000029704954910>
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
要查看它在每个 epoch 结束时用于报告指标的实际应用,以下是我们如何使用此 compute_metrics () 函数定义新 Trainer
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
请注意,我们创建了一个设置为 evaluation_strategy set to "epoch" 的新 TrainingArguments 和一个新模型 — 否则,我们只会继续训练我们已经训练过的模型。要启动新的训练运行,我们执行:
trainer.train()
A full training
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
Prepare for training
在实际编写训练循环之前,我们需要定义一些对象。第一个是我们将用于迭代批处理的数据加载器 dataloaders 。但是在我们定义这些数据加载器之前,我们需要对我们的 tokenized_datasets 应用一些后处理,以自动处理一些为我们做的事。具体而言,我们需要
删除与模型不期望的值对应的列(如 sentence1 和 sentence2 列)
将列 label 重命名为 labels(因为模型期望将参数命名为 labels )
设置数据集的格式,以便它们返回 PyTorch 张量而不是列表。
对于每个步骤,我们 tokenized_datasets 都有一种方法:
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
tokenized_datasets["train"].column_names
["attention_mask", "input_ids", "labels", "token_type_ids"]
现在完成此操作,我们可以轻松定义数据加载器:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)
为了快速检查数据处理中没有错误,我们可以检查如下批次:
for batch in train_dataloader:
break
{k: v.shape for k, v in batch.items()}
{'attention_mask': torch.Size([8, 65]),
'input_ids': torch.Size([8, 65]),
'labels': torch.Size([8]),
'token_type_ids': torch.Size([8, 65])}
请注意,实际的形状可能会略有不同,因为我们为训练数据加载器进行了设置 shuffle=True,并且我们正在填充到批处理中的最大长度。
转向模型。我们完全按照上一节中的做法对其进行实例化:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
为了确保在训练期间一切顺利进行,我们将批处理传递给此模型:
outputs = model(**batch)
print(outputs.loss, outputs.logits.shape)
tensor(0.5441, grad_fn=<NllLossBackward>) torch.Size([8, 2])
所有 🤗 Transformers 模型在提供 labels 时都将返回损耗,我们还将获得 logits(对于批处理中的每个输入,即张量大小为 8 x 2)
我们几乎已经准备好编写训练循环了!我们只是缺少两样东西:优化器和学习速率调度器。由于我们尝试复制手动执行的操作,因此我们将使用相同的默认值。使用的优化器是 ,它与 Adam 相同,但对权重衰减正则化进行了扭曲
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=5e-5)
最后,默认使用的学习速率调度器只是从最大值 (5e-5) 到 0 的线性衰减。为了正确定义它,我们需要知道我们将采取的训练步骤的数量,即我们要运行的纪元数乘以训练批次的数量(这是训练数据加载器的长度)。默认情况下,它们 Trainer 使用三个 epoch,因此我们将遵循以下原则
from transformers import get_scheduler
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
print(num_training_steps)
1377
The training loop
最后一件事:如果我们可以访问 GPU,我们将希望使用 GPU(在 CPU 上,训练可能需要几个小时而不是几分钟)。为此,我们定义了一个 device,我们将我们的模型和批处理放在
import torch
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
device
device(type='cuda')
from tqdm.auto import tqdm
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
您可以看到,训练循环的核心看起来很像简介中的核心。我们没有要求任何报告,因此此训练循环不会告诉我们有关模型表现的任何信息。我们需要为此添加一个评估循环。
The evaluation loop
如前所述,我们将使用 Evaluate 库提供的 metric。我们已经看到了 metric.compute () 方法,但是当我们使用 add_batch () 方法进行预测循环时,metrics 实际上可以为我们积累批次。一旦我们积累了所有批次,我们就可以得到最终的结果。下面介绍如何在评估循环中实现所有这些功能
import evaluate
metric = evaluate.load("glue", "mrpc")
model.eval()
for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
metric.compute()
同样,由于模型头初始化和数据随机排列的随机性,您的结果将略有不同,但它们应该处于相同的大致值。
我们之前定义的训练循环在单个 CPU 或 GPU 上运行良好。但是使用 🤗 Accelerate 库,只需进行一些调整,我们就可以在多个 GPU 或 TPU 上启用分布式训练。从创建训练和验证数据加载器开始,我们的手动训练循环如下所示:
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
以下是更改:
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
要添加的第一行是导入行。第二行实例化一个 Accelerator 对象,该对象将查看环境并初始化正确的分布式设置。Accelerate 将为您处理设备放置,以便您可以删除将模型放在设备上的那一行(或者,如果您愿意,可以将它们更改为使用 accelerator.device 而不是 device)。
然后,在将数据加载器 dataloaders、模型 model 和优化器 optimizer 发送到 accelerator.prepare () 的行中完成大部分工作。这会将这些对象包装在适当的容器中,以确保您的分布式训练按预期工作。要进行的其余更改是删除将批处理放在 device 上的行(同样,如果要保留此行,只需将其更改为使用 accelerator.device),然后替换 loss.backward () 为 accelerator.backward (loss)
为了从云 TPU 提供的加速中受益,我们建议使用分词器的 “padding=”max_length“” 和 “max_length” 参数将样本填充到固定长度。
如果您想复制并粘贴它以进行游戏,以下是 Accelerate 的完整训练循环
from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
train_dl, eval_dl, model, optimizer = accelerator.prepare(
train_dataloader, eval_dataloader, model, optimizer
)
num_epochs = 3
num_training_steps = num_epochs * len(train_dl)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dl:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
将其放入 train.py 脚本中将使该脚本可在任何类型的分布式设置上运行。要在分布式设置中试用它,请运行以下命令
accelerate config
这将提示您回答几个问题,并将您的答案转储到以下命令使用的配置文件中:
accelerate launch train.py
这将启动分布式训练。
如果你想在笔记本中尝试此操作(例如,在 Colab 上使用 TPU 进行测试),只需将代码粘贴到 training_function () 中,然后运行最后一个单元格
from accelerate import notebook_launcher
notebook_launcher(training_function)
# THE DATASETS LIBRARY
# Introduction
发现在微调模型时有三个主要步骤:
从拥抱人脸中心加载数据集。
使用 Dataset.map () 预处理数据。
负载和计算指标。
但这只是触及数据集可以做什么的表面!在本章中,我们将深入研究该库。在此过程中,我们将找到以下问题的答案:

当数据集不在 Hub 上时,该怎么办?
如何对数据集进行切片和切块?(如果你真的需要使用熊猫怎么办?
当您的数据集很大并且会融化笔记本电脑的 RAM 时,您会怎么做?
“内存映射” 和 Apache Arrow 到底是什么?
如何创建自己的数据集并将其推送到中心?
# What if my dataset isn't on the Hub?
Working with local and remote datasets
Datasets 提供加载脚本来处理本地和远程数据集的加载。它支持几种常见的数据格式,例如:

如表中所示,对于每种数据格式,我们只需要在 load_dataset () 函数中指定加载脚本的类型,以及指定一个或多个文件的路径的 data_files 参数。让我们从本地文件加载数据集开始;稍后我们将了解如何对远程文件执行相同的操作。
Loading a local dataset
下载 https://github.com/crux82/squad-it/raw/master/SQuAD_it-train.json.gz https://github.com/crux82/squad-it/raw/master/SQuAD_it-test.json.gz 并解压缩
我们可以看到压缩文件已被 SQuAD_it-train.json 和 SQuAD_it-text.json 替换,并且数据以 JSON 格式存储。
要使用 load_dataset () 函数加载 JSON 文件,我们只需要知道我们是在处理普通的 JSON(类似于嵌套字典)还是 JSON Lines(行分隔的 JSON)。与许多问答数据集一样,SQuAD-it 使用嵌套格式,所有文本都存储在 data 字段中。这意味着我们可以通过指定 field 参数来加载数据集,如下所示
from datasets import load_dataset
squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
squad_it_dataset = load_dataset("json", data_files="../nlp-datasets/SQuAD_it-train.json", field="data")
# 第二个参数是路径
默认情况下,加载本地文件会创建一个 train 的 DatasetDict 对象。我们可以通过检查对象来看到这一点
squad_it_dataset
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
})
这向我们显示了与训练集关联的行数和列名。我们可以通过索引到 train 中来查看其中一个示例,如下所示
squad_it_dataset["train"][0]
{
"title": "Terremoto del Sichuan del 2008",
"paragraphs": [
{
"context": "Il terremoto del Sichuan del 2008 o il terremoto...",
"qas": [
{
"answers": [{"answer_start": 29, "text": "2008"}],
"id": "56cdca7862d2951400fa6826",
"question": "In quale anno si è verificato il terremoto nel Sichuan?",
},
...
],
},
...
],
}
但是,虽然这适用于训练集,但我们真正想要的是将 train 和 test 都包含在单个 DatasetDict 对象中,以便我们可以同时在两个拆分中应用 Dataset.map () 函数。为此,我们可以为 data_files 参数提供一个字典,该参数将每个拆分名称映射到与该拆分关联的文件:
data_files = {"train": "../nlp-datasets/SQuAD_it-train.json", "test": "../nlp-datasets/SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
squad_it_dataset
DatasetDict({
train: Dataset({
features: ['title', 'paragraphs'],
num_rows: 442
})
test: Dataset({
features: ['title', 'paragraphs'],
num_rows: 48
})
})
这正是我们想要的。现在,我们可以应用各种预处理技术来清理数据,标记评论等。
https://huggingface.co/docs/datasets/loading#local-and-remote-files
load_dataset () 函数的 data_files 参数非常灵活,可以是单个文件路径、文件路径列表或将拆分名称映射到文件路径的字典。您还可以根据 Unix shell 使用的规则将匹配指定模式的文件(例如,您可以通过设置 data_files="*.json" 将目录中的所有 JSON 文件作为单个拆分进行 glob)
数据集中的加载脚本实际上支持输入文件的自动解压缩,因此我们可以通过将参数直接指向压缩文件来跳过的使用
data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
如果您不想手动解压缩许多 GZIP 文件,这可能很有用。自动解压缩也适用于其他常见格式,如 ZIP 和 TAR,所以你只需要 data_files 指向压缩文件,你就可以了
Loading a remote dataset
如果你在一家公司担任数据科学家或程序员,那么你想要分析的数据集很有可能存储在某个远程服务器上。幸运的是,加载远程文件与加载本地文件一样简单!我们不是提供本地文件的路径,而是将 load_dataset () 的 data_files 参数指向存储远程文件的一个或多个 URL。例如,对于托管在 GitHub 上的 SQuAD-it 数据集,我们可以只指向 SQuAD_it-*.json.gz URL,如下所示
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {
"train": url + "SQuAD_it-train.json.gz",
"test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
这将返回上面获取的相同 DatasetDict 对象,但节省了手动下载和解压缩 SQuAD_it-*.json.gz 文件的步骤。这总结了我们对加载未托管在 Hugging Face Hub 上的数据集的各种方法的尝试
# Time to slice and dice
大多数情况下,您使用的数据不会为训练模型做好充分的准备。在本节中,我们将探讨数据集为清理数据集而提供的各种功能
Slicing and dicing our data
对于此示例,我们将使用托管在加州大学欧文分校机器学习存储库上的药物审查数据集,其中包含对各种药物的患者评论,以及正在治疗的病情和患者满意度的 10 星评级。
使用的数据集 https://archive.ics.uci.edu/ml/datasets/Drug+Review+Dataset+(Drugs.com)
https://archive.ics.uci.edu/ml/machine-learning-databases/00462/drugsCom_raw.zip
由于 TSV 只是 CSV 的一种变体,它使用制表符而不是逗号作为分隔符,因此我们可以通过使用 csv 加载脚本并在 load_dataset () 函数中指定 delimiter 参数来加载这些文件,
from datasets import load_dataset
data_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
# \t is the tab character in Python
drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
在进行任何类型的数据分析时,一个好的做法是抓取一个小的随机样本,以快速了解您正在处理的数据类型。在 Datasets, 中,我们可以通过将 Dataset.shuffle () 和 Dataset.select () 函数链接在一起来创建一个随机样本
drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
# Peek at the first few examples
drug_sample[:3]
{'Unnamed: 0': [87571, 178045, 80482],
'drugName': ['Naproxen', 'Duloxetine', 'Mobic'],
'condition': ['Gout, Acute', 'ibromyalgia', 'Inflammatory Conditions'],
'review': ['"like the previous person mention, I'm a strong believer of aleve, it works faster for my gout than the prescription meds I take. No more going to the doctor for refills.....Aleve works!"',
'"I have taken Cymbalta for about a year and a half for fibromyalgia pain. It is great\r\nas a pain reducer and an anti-depressant, however, the side effects outweighed \r\nany benefit I got from it. I had trouble with restlessness, being tired constantly,\r\ndizziness, dry mouth, numbness and tingling in my feet, and horrible sweating. I am\r\nbeing weaned off of it now. Went from 60 mg to 30mg and now to 15 mg. I will be\r\noff completely in about a week. The fibro pain is coming back, but I would rather deal with it than the side effects."',
'"I have been taking Mobic for over a year with no side effects other than an elevated blood pressure. I had severe knee and ankle pain which completely went away after taking Mobic. I attempted to stop the medication however pain returned after a few days."'],
'rating': [9.0, 3.0, 10.0],
'date': ['September 2, 2015', 'November 7, 2011', 'June 5, 2013'],
'usefulCount': [36, 13, 128]}
请注意,出于可重复性目的,我们已将种子固定在 Dataset.shuffle () 中。 Dataset.select () 期望索引的可迭代性,因此我们传入 range (1000) 从数据集中获取了前 1,000 个示例。从这个样本中,我们已经可以在我们的数据集中看到一些怪癖
The Unnamed: 0 列看起来可疑地像是每个患者的匿名 ID
condition 列包括大写和小写标签的混合
评论的长度各不相同,并且包含 Python 行分隔符()以及 HTML 字符代码(如 \r\n')的混合
让我们看看如何使用 Datasets 来处理这些问题。为了测试 Unnamed: 0 列的患者 ID 假设,我们可以使用 Dataset.unique () 函数来验证 ID 数是否与每个拆分中的行数匹配
for split in drug_dataset.keys():
assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
drug_dataset.keys () 为 dict_keys (['train', 'test'])
这似乎证实了我们的假设,因此让我们通过将 Unnamed: 0 列重命名为更易于解释的内容来清理数据集。我们可以使用 DatasetDict.rename_column () 函数一次性重命名两个拆分中的列:
drug_dataset = drug_dataset.rename_column(
original_column_name="Unnamed: 0", new_column_name="patient_id"
)
drug_dataset
DatasetDict({
train: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
num_rows: 161297
})
test: Dataset({
features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount'],
num_rows: 53766
})
})
接下来,让我们使用 Dataset.map () 规范化所有 condition 标签。正如我们在第 3 章中对标记化所做的那样,我们可以定义一个简单的函数,该函数可以应用于中每个拆分的所有行:
def lowercase_condition(example):
return {"condition": example["condition"].lower()}
drug_dataset.map(lowercase_condition)
AttributeError: 'NoneType' object has no attribute 'lower'
哦,不,我们的 map 遇到了问题!从错误中我们可以推断出 condition 列中的一些条目是 None,它们不能小写,因为它们不是字符串。让我们使用 Dataset.filter () 删除这些行,其工作方式与接收数据集的单个示例的 Dataset.map () 函数类似,并且期望该函数接收数据集的单个示例。而不是编写一个显式函数
def filter_nones(x):
return x["condition"] is not None
然后运行 drug_dataset.filter (filter_nones) ,我们可以使用 lambda 函数在一行中执行此操作。在 Python 中,lambda 函数是一些小函数,无需显式命名即可定义它们。它们采用一般形式
lambda <arguments> : <expression>
在 🤗 Datasets 上下文中,我们可以使用 lambda 函数来定义简单的映射和筛选操作,因此让我们使用此技巧来消除数据集中的条目
drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
删除 None 条目后,我们可以规范化 condition 列
drug_dataset = drug_dataset.map(lowercase_condition)
# Check that lowercasing worked
drug_dataset["train"]["condition"][:3]
['left ventricular dysfunction', 'adhd', 'birth control']
它的工作原理!现在我们已经清理了标签,让我们来看看清理评论本身。
Creating new columns 创建新列
每当您处理客户评论 reviews 时,一个好的做法是检查每个评论中的字数。评论可能只是一个单词,如 “Great!” 或一篇包含数千字的完整文章,根据用例,您需要以不同的方式处理这些极端情况。为了计算每个评论中的单词数,我们将使用基于按空格拆分每个文本的粗略启发式方法。
让我们定义一个简单的函数来计算每个评论中的字数
def compute_review_length(example):
return {"review_length": len(example["review"].split())}
与我们的 lowercase_condition () 函数不同,compute_review_length () 返回一个字典,其键与数据集中的某个列名不对应。在这种情况下,当 compute_review_length () 传递给 Dataset.map () 时,它将应用于数据集中的所有行以创建新列 review_length:
drug_dataset = drug_dataset.map(compute_review_length)
# Inspect the first training example
drug_dataset["train"][0]
{'patient_id': 206461,
'drugName': 'Valsartan',
'condition': 'left ventricular dysfunction',
'review': '"It has no side effect, I take it in combination of Bystolic 5 Mg and Fish Oil"',
'rating': 9.0,
'date': 'May 20, 2012',
'usefulCount': 27,
'review_length': 17}
正如预期的那样,我们可以看到 review_length 列已添加到我们的训练集中。我们可以对此新列进行排序 Dataset.sort (),以查看极值的外观
drug_dataset["train"].sort("review_length")[:3]
{'patient_id': [103488, 23627, 20558],
'drugName': ['Loestrin 21 1 / 20', 'Chlorzoxazone', 'Nucynta'],
'condition': ['birth control', 'muscle spasm', 'pain'],
'review': ['"Excellent."', '"useless"', '"ok"'],
'rating': [10.0, 1.0, 6.0],
'date': ['November 4, 2008', 'March 24, 2017', 'August 20, 2016'],
'usefulCount': [5, 2, 10],
'review_length': [1, 1, 1]}
正如我们所怀疑的那样,一些评论只包含一个单词,尽管对于情感分析来说可能是可以的,但如果我们想要预测这种情况,则不会提供信息。
向数据集添加新列的另一种方法是使用 Dataset.add_column () 函数。这允许您将列作为 Python 列表或 NumPy 数组提供,并且在不适合您的 Dataset.map () 分析的情况下可以很方便
sort 的 api
让我们使用 Dataset.filter () 函数删除包含少于 30 个字数的评论。与我们对 condition 所做的类似,我们可以通过要求评论的长度超过此阈值来过滤掉非常短的评论:
drug_dataset = drug_dataset.filter(lambda x: x["review_length"] > 30)
print(drug_dataset.num_rows)
{'train': 138514, 'test': 46108}
我们需要处理的最后一件事是我们的评论中存在 HTML 字符代码。我们可以使用 Python 的 html 模块来解开这些字符,如下所示
import html
text = "I'm a transformer called BERT"
html.unescape(text)
"I'm a transformer called BERT"
我们将使用 Dataset.map () 来取消文本集中的所有 HTML 字符
drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
The map() method's superpowers
Dataset.map () 方法采用一个 batched 参数,如果设置为 True,则会导致它一次向 map 函数发送一批示例(批大小是可配置的,但默认为 1,000)。例如,上一个取消转义所有 HTML 的 map 函数需要一些时间来运行(您可以从进度条中读取所花费的时间)。我们可以通过使用列表理解同时处理多个元素来加快速度。
指定 batched=True, 函数将接收包含数据集字段的字典,但每个值现在都是一个值列表 list of values,而不仅仅是单个值。 Dataset.map () 的返回值应该是相同的:一个字典,其中包含我们要更新或添加到数据集中的字段,以及一个值列表。例如,这是另一种取消外置所有 HTML 字符的方法,但使用 batched=True
new_drug_dataset = drug_dataset.map(
lambda x: {"review": [html.unescape(o) for o in x["review"]]}, batched=True
)
要使用快速分词器标记所有药物评论,我们可以使用如下函数
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["review"], truncation=True)
tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
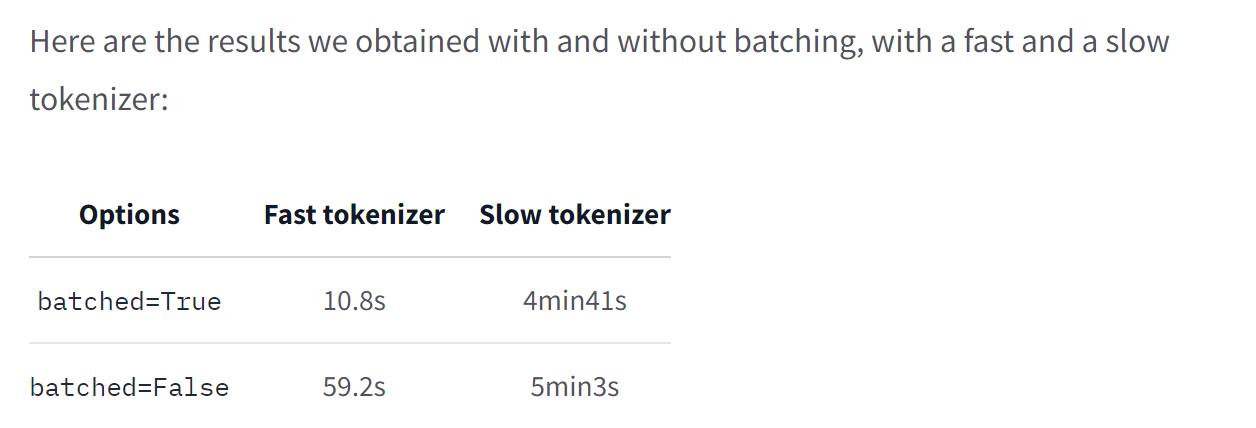
Dataset.map () 也有自己的一些并行化能力。由于它们没有 Rust 的支持,因此它们不会让慢速分词器赶上快速分词器,但它们仍然很有帮助(特别是如果您使用的是没有快速版本的分词器)。要启用多处理,请使用 num_proc 参数并指定要在调用 Dataset.map () 中使用的进程数:
slow_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased", use_fast=False)
def slow_tokenize_function(examples):
return slow_tokenizer(examples["review"], truncation=True)
tokenized_dataset = drug_dataset.map(slow_tokenize_function, batched=True, num_proc=8)

对于慢速分词器来说,这些是更合理的结果,但快速分词器的性能也得到了显着提高。但是,请注意,情况并非总是如此 - 对于 8 以外的 num_proc 值,我们的测试表明,如果没有该选项,batched=True 使用起来会更快。通常,我们不建议使 batched=True 用 Python 多处理来快速分词器。
在机器学习中,示例 example 通常定义为我们提供给模型的一组特征 features。在某些上下文中,这些功能将是 Dataset 中的列集,但在其他上下文中(如此处和问答),可以从单个示例中提取多个功能并属于单个列
让我们来看看它是如何工作的!在这里,我们将标记我们的示例并将其截断为最大长度 128,但是我们将要求分词器返回文本的所有块,而不仅仅是第一个。这可以通过 return_overflowing_tokens=True 方式完成
def tokenize_and_split(examples):
return tokenizer(
examples["review"],
truncation=True,
max_length=128,
return_overflowing_tokens=True,
)
让我们先在一个示例中对此进行测试,然后再在整个数据集上使用 Dataset.map ()
result = tokenize_and_split(drug_dataset["train"][0])
[len(inp) for inp in result["input_ids"]]
[128, 49]
# THE TOKENIZERS LIBRARY
# Token classification
我们将探讨的第一个应用是 token 分类。此通用任务包含可表述为 “将标签归因于句子中的每个标记” 的任何问题,例如:
Named entity recognition (NER) 命名实体识别 查找句子中的实体(如人员、位置或组织)。这可以表述为通过每个实体有一个类和一个 “无实体” 的类来将标签归因于每个令牌。
Part-of-speech tagging (POS) 词性标记 将句子中的每个字词标记为对应于特定的词性(如名词、动词、形容词等)
Chunking 分块 查找属于同一实体的令牌。此任务(可以与 POS 或 NER 结合使用)可以表述为将一个标签(通常)归因于位于块开头的任何令牌,将另一个标签(通常)归因于块内的令牌,并将第三个标签(通常)归因于不属于任何块的令牌
Preparing the data
首先,我们需要一个适合令牌分类的数据集。在本节中,我们将使用 CoNLL-2003 数据集,其中包含路透社的新闻报道。
https://huggingface.co/datasets/conll2003
只要您的数据集由拆分为具有相应标签的单词的文本组成,您就可以根据自己的数据集调整此处描述的数据处理过程。
The CoNLL-2003 dataset
要加载 CoNLL-2003 数据集,我们使用 Datasets 库中的 load_dataset () 方法
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")
检查此对象向我们显示了存在的列以及训练集、验证集和测试集之间的拆分:
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})
特别是,我们可以看到数据集包含我们之前提到的三个任务的标签:NER,POS 和分块。与其他数据集的一大区别在于,输入文本不是以句子或文档的形式呈现的,而是以单词列表的形式呈现的(最后一列称为 tokens ,但它包含的单词是预先标记化的输入,仍然需要通过分词器进行子词标记化)
看一下训练集的第一个元素
raw_datasets["train"][0]["tokens"]
['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']
由于我们要执行命名实体识别,因此我们将查看 NER 标签:
raw_datasets["train"][0]["ner_tags"]
[3, 0, 7, 0, 0, 0, 7, 0, 0]
这些是准备训练的整数标签,但是当我们想要检查数据时,它们不一定有用。与文本分类一样,我们可以通过查看数据集的 features 属性来访问这些整数和标签名称之间的对应关系
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_feature
Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)
raw_datasets['train'].features # 类型为 datasets.features.features.Features
{'id': Value(dtype='string', id=None),
'tokens': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),
'pos_tags': Sequence(feature=ClassLabel(num_classes=47, names=['"', "''", '#', '$', '(', ')', ',', '.', ':', '``', 'CC', 'CD', 'DT', 'EX', 'FW', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NN', 'NNP', 'NNPS', 'NNS', 'NN|SYM', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB'], id=None), length=-1, id=None),
'chunk_tags': Sequence(feature=ClassLabel(num_classes=23, names=['O', 'B-ADJP', 'I-ADJP', 'B-ADVP', 'I-ADVP', 'B-CONJP', 'I-CONJP', 'B-INTJ', 'I-INTJ', 'B-LST', 'I-LST', 'B-NP', 'I-NP', 'B-PP', 'I-PP', 'B-PRT', 'I-PRT', 'B-SBAR', 'I-SBAR', 'B-UCP', 'I-UCP', 'B-VP', 'I-VP'], id=None), length=-1, id=None),
'ner_tags': Sequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], id=None), length=-1, id=None)}
因此,此列包含作为 ClassLabels 序列的元素。序列元素的类型位于 ner_feature 的 feature 属性中,我们可以通过查看 names 属性来访问名称列表
label_names = ner_feature.feature.names
label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']
O means the word doesn’t correspond to any entity.
B-PER/I-PER means the word corresponds to the beginning of/is inside a person entity.
B-ORG/I-ORG means the word corresponds to the beginning of/is inside an organization entity.
B-LOC/I-LOC means the word corresponds to the beginning of/is inside a location entity.
B-MISC/I-MISC means the word corresponds to the beginning of/is inside a miscellaneous entity.
现在解码我们之前看到的标签可以得到这个:
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)
'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'
对于混合 B- 和 I - 标签的示例,这是相同的代码在索引 4 处的训练集元素上给出的内容
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'
跨越两个单词的实体,如 “European Union” 和 “Werner Zwingmann”,被归因于 B - 第一个单词的标签和 I - 第二个单词的标签
Processing the data
像往常一样,我们的文本需要转换为令牌 ID,然后模型才能理解它们。正如我们在第 6 章中看到的,令牌分类任务的一大区别在于我们有预先标记化的输入。幸运的是,分词器 API 可以很容易地处理这个问题。我们只需要用一个特殊的标志来警告 tokenizer。
首先,让我们创建我们的 tokenizer 对象。如前所述,我们将使用 BERT 预训练模型,因此我们将从下载并缓存关联的分词器开始
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
可以将 model_checkpoint 替换为你从 Hub 中喜欢的任何其他模型,或者替换为已在其中保存预训练模型和分词器的本地文件夹。唯一的约束是分词器需要由 🤗 Tokenizers 库支持,因此有一个 “快速” 版本可用。您可以在这个大表 https://huggingface.co/transformers/#supported-frameworks 中看到快速版本附带的所有体系结构,并且要检查您正在使用的对象是否确实由🤗 Tokenizers 支持,您可以查看其 is_fast 属性
tokenizer.is_fast
True
要标记预先标记化的输入,我们可以像往常一样使用我们的,只需添加 is_split_into_words=True
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()
['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']
正如我们所看到的,分词器添加了模型使用的特殊标记(在开头 [CLS] 和 [SEP] 结尾),并且保留了大部分单词不变。lamb 然而,这个词被标记成两个子词,和。这引入了输入和标签之间的不匹配:标签列表只有 9 个元素,而我们的输入现在有 12 个标记。计算特殊令牌很容易(我们知道它们在开头和结尾),但我们还需要确保将所有标签与正确的单词对齐
幸运的是,由于我们使用的是快速分词器,因此我们可以访问 Tokenizers 分词器超能力,这意味着我们可以轻松地将每个标记映射到其相应的单词
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]
通过一点点工作,我们可以扩展标签列表以匹配令牌。我们要应用的第一个规则是,特殊令牌的标签为 - 100 。这是因为默认情况下,在我们将使用的损失函数(交叉熵)中忽略了一个索引 - 100 。然后,每个令牌都获得与启动其内部单词的令牌相同的标签,因为它们是同一实体的一部分。对于单词内但不在开头的标记,我们将 B - 替换为 I-(因为标记不以实体开头)
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Start of a new word!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Special token
new_labels.append(-100)
else:
# Same word as previous token
label = labels[word_id]
# If the label is B-XXX we change it to I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labels
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))
[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
一些研究人员更喜欢每个单词只归因于一个标签,并分配 - 100 给给定单词中的其他子标记。这是为了避免长单词分裂成许多子标记,从而严重导致损失。按照此规则更改上一个函数以将标签与输入 ID 对齐。
要预处理整个数据集,我们需要标记所有输入并应用 align_labels_with_tokens () 于所有标签。为了利用我们的快速分词器的速度,最好同时对大量文本进行标记,因此我们将编写一个函数来处理示例列表,并将 Dataset.map () 方法与选项 batched=True 一起使用。与我们之前的示例唯一不同的是, word_ids () 函数需要获取示例的索引,当分词器的输入是文本列表(或者在我们的例子中,是单词列表)时,我们想要的单词 ID,因此我们也添加它:
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputs
请注意,我们还没有填充我们的输入;稍后,在使用数据整理器 data collator 创建批处理时,我们将执行此操作。
现在,我们可以一次性将所有预处理应用到数据集的其他拆分上:
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)
Fine-tuning the model with the Trainer API
Data collation
我们不能使用 DataCollatorWithPadding,因为它只填充输入(输入 ID,注意力掩码和令牌类型 ID)。在这里,我们的标签应该以与输入完全相同的方式填充,以便它们保持相同的大小,用 - 100 作值,以便在损失计算中忽略相应的预测。
这一切都是由 DataCollatorForTokenClassification 完成的。像 DataCollatorWithPadding 一样,它采用 tokenizer 输入
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
为了在几个样本上测试这一点,我们可以在标记化训练集中的示例列表中调用它
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]
tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])
让我们将其与数据集中第一个和第二个元素的标签进行比较:
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]
正如我们所看到的,第二组标签已使用 - 100s 填充到第一组标签的长度。
Metrics
要让每个 epoch Trainer 计算一个指标,我们需要定义 compute_metrics () 函数,该函数采用预测和标签数组,并返回一个包含指标名称和值的字典。
用于评估令牌分类预测的传统框架是 seqeval。要使用此指标,我们首先需要安装 seqeval 库:
pip install seqeval
然后,我们可以通过 evaluate.load () 函数加载它,
import evaluate
metric = evaluate.load("seqeval")
此指标的行为与标准准确性不同:它实际上会将标签列表作为字符串而不是整数,因此我们需要在将预测和标签传递给指标之前对其进行完全解码。让我们看看它是如何工作的。首先,我们将获取第一个训练示例的标签:
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels
['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']
然后,我们可以通过更改索引 2 处的值来为这些预测创建虚假预测:
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])
请注意,该指标需要一个预测列表(而不仅仅是一个)和一个标签列表。下面是输出
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}
compute_metrics () 函数首先采用 logits 的 argmax 将其转换为预测(像往常一样,logits 和概率的顺序相同,因此我们不需要应用 softmax)。然后,我们必须将标签和预测从整数转换为字符串。我们删除 - 100 标签所在的所有值,然后将结果传递给 metric.compute () 方法:
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}
Defining the model
由于我们正在研究令牌分类问题,因此我们将使用 AutoModelForTokenClassification 类。定义此模型时要记住的主要事项是传递有关我们拥有的标签数量的一些信息。最简单的方法是将该数字通过参数 num_labels 传递,但是如果我们想要一个漂亮的推理小部件,就像我们在本节开头看到的一样,最好设置正确的标签对应关系。
它们应由两个字典 id2label 和 label2id 设置,其中包含从 ID 到标签的映射,反之亦然:
id2label = {str(i): label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}
现在,我们可以将它们传递给 AutoModelForTokenClassification.from_pretrained () 方法,它们将在模型的配置中设置,然后正确保存并上传到 Hub
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)
让我们仔细检查我们的模型是否具有正确数量的标签
model.config.num_labels
9
如果模型的标签数量错误,则在以后调用 Trainer.train () 方法时将收到一个模糊的错误(类似于 “CUDA error: device-side assert triggered”)。这是用户报告此类错误的错误的头号原因,因此请确保执行此检查以确认您具有预期的标签数。
Fine-tuning the model
we can define our TrainingArguments:
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)
我们设置了一些超参数(例如学习速率、要训练的 epoch 数和权重衰减),并且我们指定 push_to_hub=True 指示我们要保存模型并在每个纪元结束时对其进行评估,并且我们希望将结果上传到模型中心。请注意,您可以使用参数 hub_model_id 指定要推送到的存储库的名称(特别是,您必须使用此参数推送到组织)。例如,当我们将模型推送到拥抱脸课程组织时,我们添加了 hub_model_id="huggingface-course/bert-finetuned-ner". 默认情况下,使用的存储库将位于您的命名空间中,并以您设置的输出目录命名,因此在我们的例子中,它将是
最后,我们只是将所有内容传递给 Trainer 并启动训练
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()
请注意,在训练发生时,每次保存模型(此处为每个 epoch)时,都会在后台将其上传到 Hub。这样,如有必要,您将能够在另一台机器上恢复训练。
训练完成后,我们使用 push_to_hub () 方法来确保上传最新版本的模型
trainer.push_to_hub(commit_message="Training complete")
此命令返回它刚刚执行的提交的 URL,如果要检查它
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'
A custom training loop
Preparing everything for training
首先,我们需要从数据集构建 DataLoaders。我们将重用我们的 data_collator 作为 collate_fn 并洗牌训练集,但不重用验证集
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)
接下来,我们重新实例化我们的模型,以确保我们不会继续之前的微调,而是再次从 BERT 预训练模型开始
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)
然后我们需要一个优化器。我们将使用经典的 AdamW,它类似于 Adam,但是在应用权重衰减的方式上进行了修复