# 第一集
好那这个现在要讲的是 meta learning 啊 这是这一门课最后一个主题了 那什么是 meta learning 呢 mea 这个词汇又是什么意思呢 mea 这个词汇啊 如果你要翻成中文的话 通常会翻译成圆 哪个人呢 就是一元复始那个圆 那 meta learning 这个 meta 到底是什么意思呢 当你说一个东西是 meta x 的时候 代表说这个东西是 x 的 x 所以 meta learning 从他字面的意思来看 就我这边说什么叫 made a learning made a learning 就是 learn to learn 如果翻译成中文的话 所以这个 may learning 呢跟我们之前讲的 machine learning 已经 是另外一个层次的东西了 拿来作为这堂课的收尾 刚刚好 就我们要迈向下一个领域 想想看你在这门课的作业都在做什么事情啊 也许你的朋友觉得你在做很潮的东西 在门口有很多很潮的作业 比如说呃动画人物的生存啊 比如说翻译啊 比如说玩 atari 的游戏啊等等 然后你的指导教授知道说 machine learning 背后有很多数学 那你自己呢这个图的意思就是你觉得自己很强了 啊希望你觉得有有觉得自己很强 但事实上你在做的事情是什么呢 事实上你就要调参数 对不对 你大部分的时候 deep learning 就是在调 hyperparameter 我其实不会否认这件事 deep learning 就是就是不能不调 hyperboremeter 那条 hyperparameter 真的是一件非常烦的事情 决定什么 network 的架构啊 决定 learning ray 啊等等 真的是一件很烦的事情 那有什么好方法来调 learning rate 呢
实际上没有什么好方法来调这些 hyperparameter 今天业界最长拿来解决条 hyperparameter hyperparameter 的方法呢就是买很多张 gpu 了哦 对业界来说 他们劝 model 的时候就像是这个翻车鱼一样 一次训练多个 model 那有的 串不起来就丢掉 最后只看那些可以串起来的 model 他会得到什么样的 performance 所以在业界啊 你做实验的时候 往往就是一次开个 1000 张 gpu 1000 张 gpu 跑 1000 组不同的 hyperparameter 看看哪一组 hyperparameter 可以给你最好的结果好 但是在学界呢 在学界哇 你没有 1000 张 gpu 其实我这边说业界用 1000 张 gpu 这个都是低 这其实都是低估他们使用的 gpu 的量啊 然后这个 flag 那些大公司在才买 gpu 的时候 他们的单位都是用万来算的 这次要买 3 万张 gpu 这种等级啊 所以这个呃业界今天在 deep learning 上的规模呢真的是跟学界是不 太一样啊 很高兴一次可以用 1000 张 gpu 回来 就突然不知道怎么做实验了啊 因为在学校每个人只有一张 gpu 所以那怎么办呢 通常这个时候你只能通点而祈祷说啊 凭着你的经验跟直觉定义组好的 hyperparameter 祈祷这种 hyperparameter 可以给你好的结果 但是有没有更好的方法来决定这些 hyperparameter 今天既然我们说我们在做的是 machine learning 机器可以自动选出一个 model 那 hyperparameter 能不能用学的呢 learning rate 啊 network 架构啊 这些东西能不能直接用 ln 的根据 data 去把
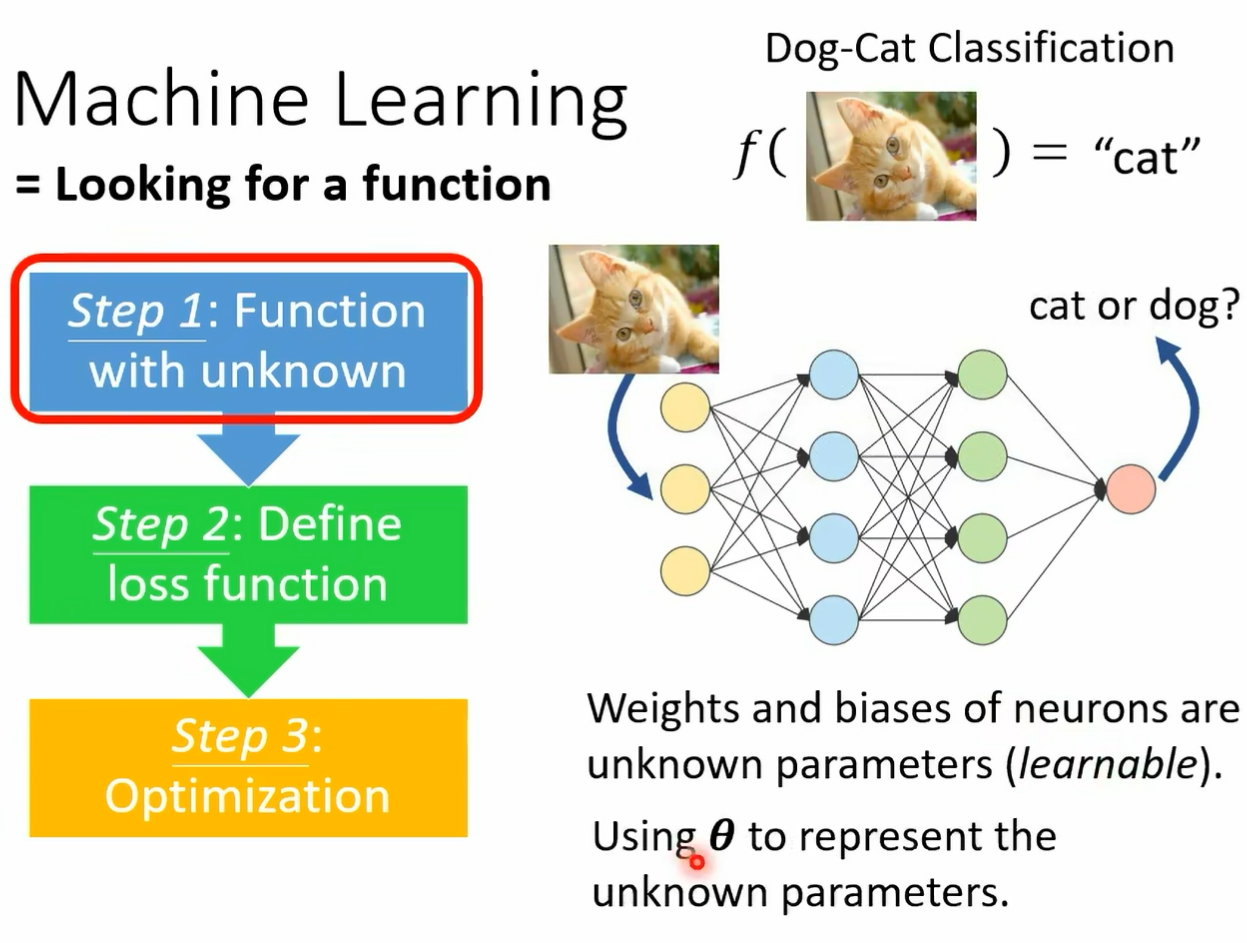
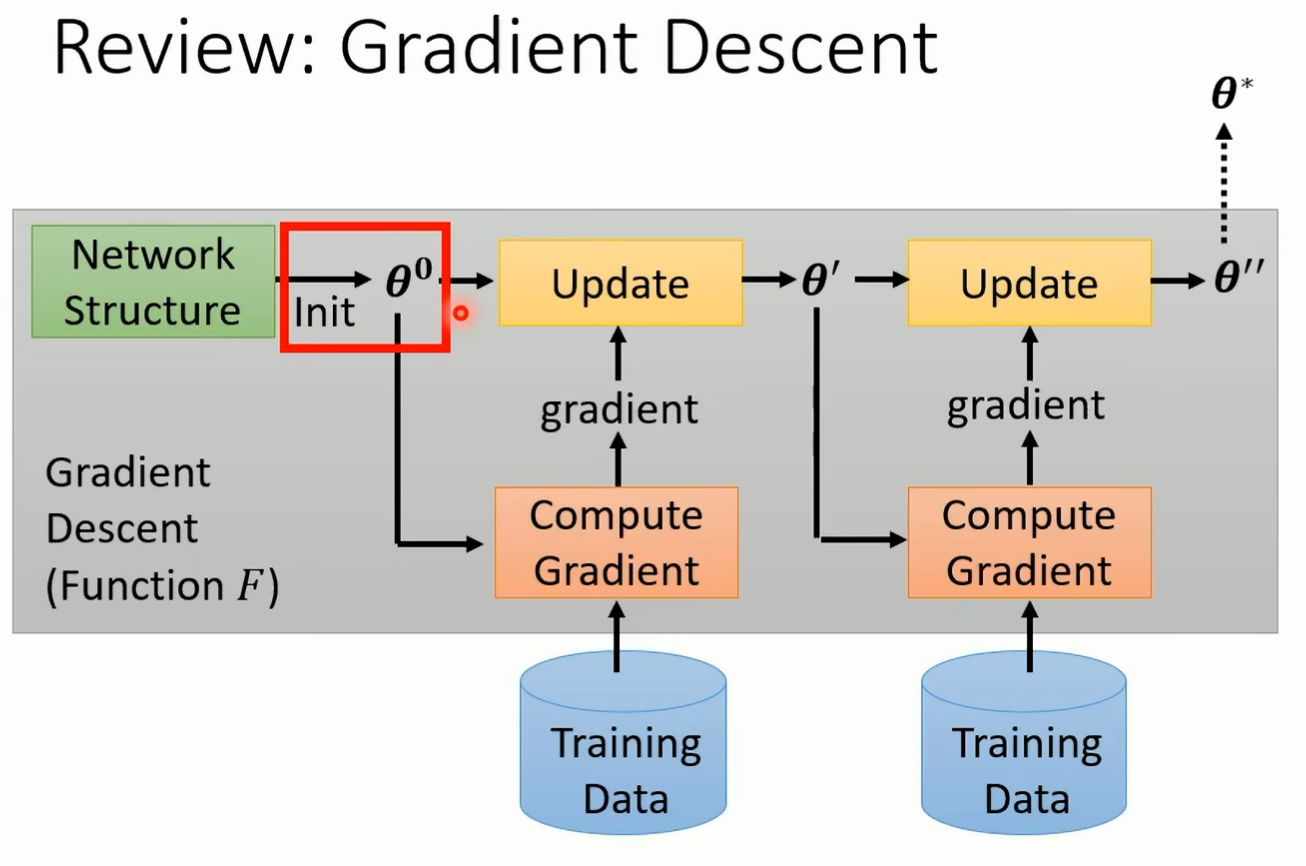
它认出来呢 这就是 made a learning 其中一个可以帮助我们的事情好 那在讲 made a learning 之前呢 你打电话 你等一下会发现说 made a learning 最基本的想法跟 machine learning 最基本的想法其实并没有非常大的差异 好 machine burning 到底在做什么呢 我们这边要讲的东西跟我们第一堂课讲的是一模一样的 所以就首尾呼应 我们用 meta learning 做节首尾呼应 回不过来 我们到底讲了些什么 第一堂课的时候 我告诉你说什么是 machine learning machine learning 就是找一个 function 比 如说你要做一个影像辨识的系统怎么办 找一个 function 输入是一张图片输出 是影像辨识的结果 那我们说 machine learning 就是三个步骤 还记得吗 第一堂课就告诉你 machine learning 就是三个步骤 第一个步骤是什么 第一个步骤是第一个 function 这个 function 里面有一些未知的参数 在 deep learning 这个领域里面 所有未知参数的 function 其实就是一个 network 而 network 里面的 weight 和 bias neural 的 weight 和 bias 就是这些未知的参数 它们是准备要被学出来的 那在这门课里面呢 我们通常用 set up 来表示这些准备要被学出来的参数 那一个 network 呢在这堂课里面 我 们常常把它写成下标 代表说 network 本身是一个 function 这个 function 里面有一些参数 这些参数我们用 来表示它 这是第一步
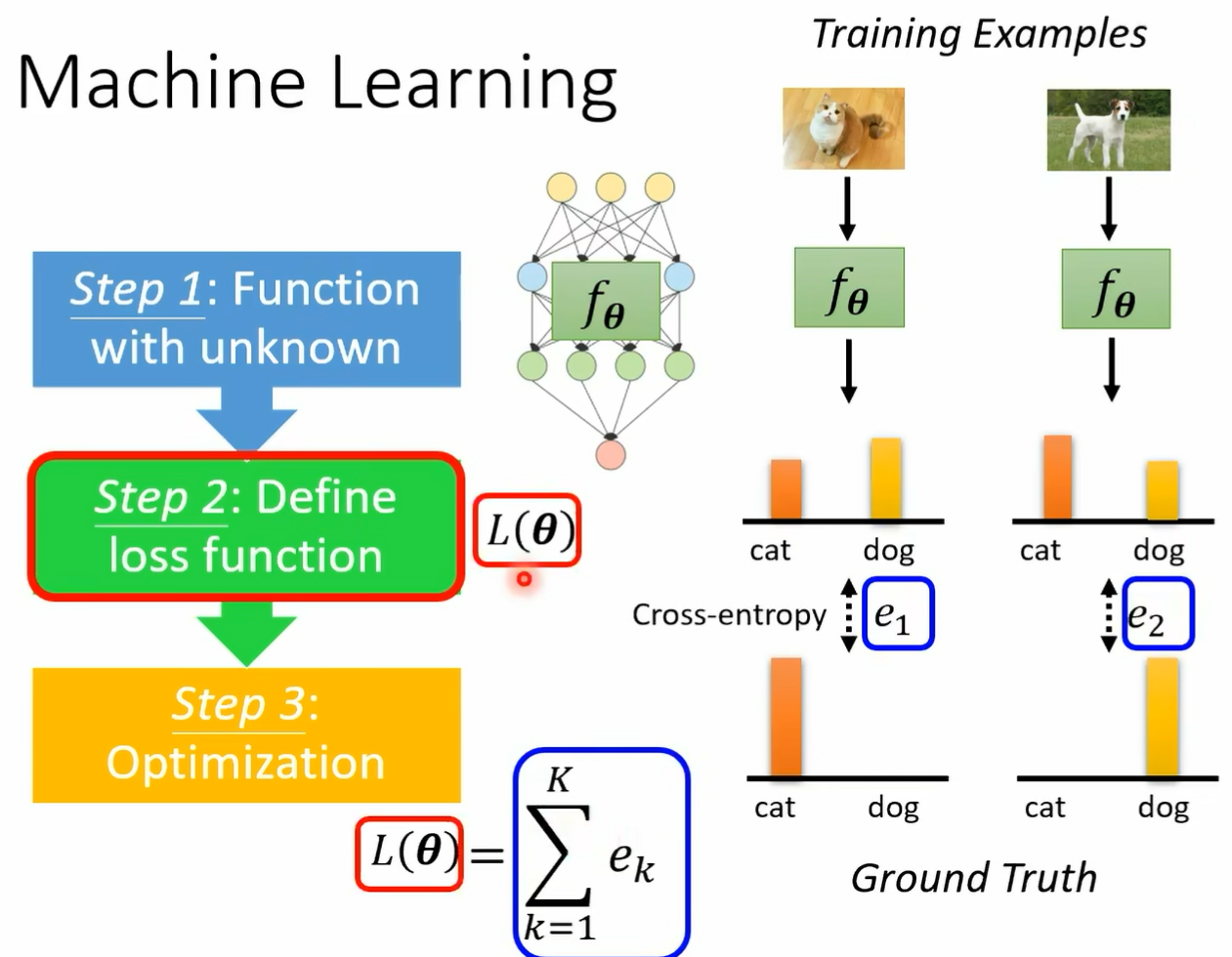
第二步是什么 第二步是我们要定义一个 loss function 哦 这个 loss function 是一个未知参数 theta 的 function 把 c 大代入 lost 我们就知道这个赛是好还是不好 怎么定这个 loss function 呢 那你需要有一些训练资料 这些训练资料需要有 label 那你把这些训练资料假设是要做影像辨识的话 就把这些图片丢到某一个 function 里面 由 sea 所 parameterized 的那个 function 里面 看看他会得到什么样的输出 再跟你的正确答案算一下距离 我 们通常如果是分类问题 就算 cross entrob 把每一个 example 的 cross entrop 通通都加起来 就是我们的 loss
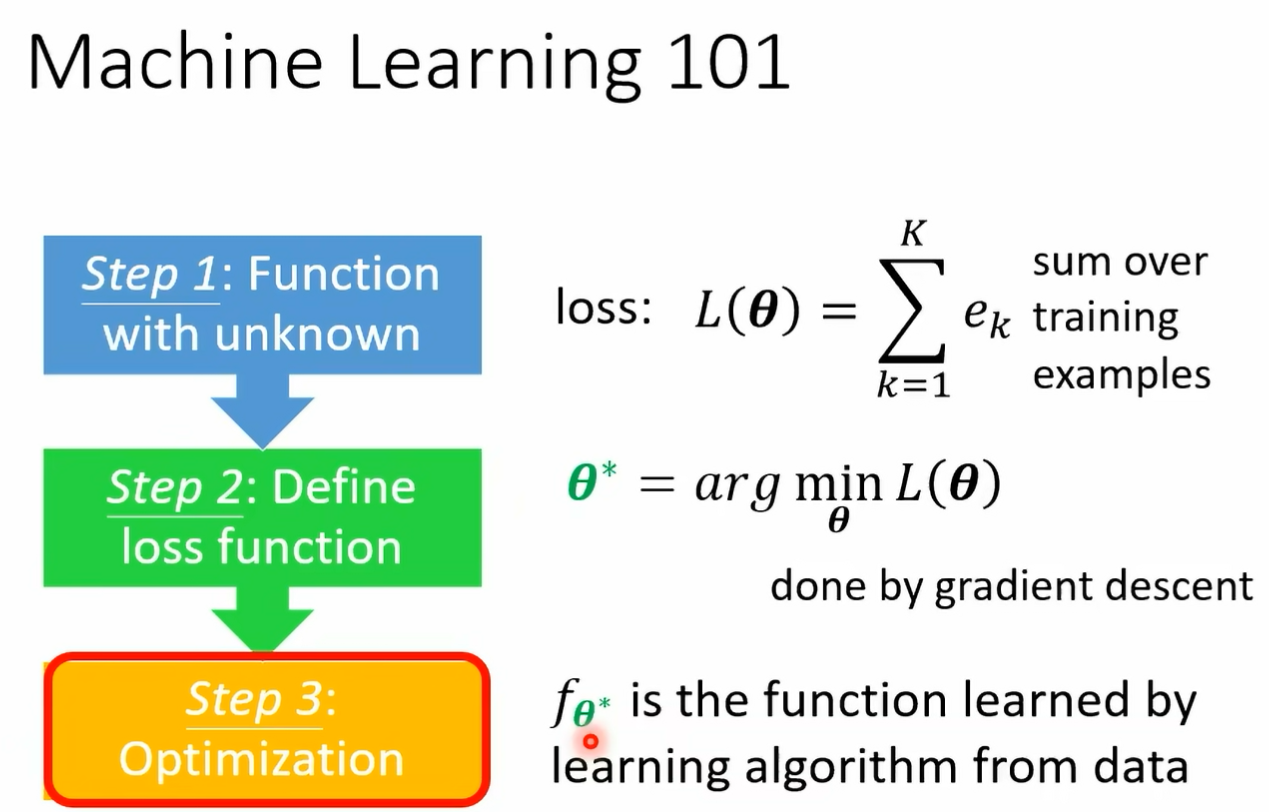
那第三步呢 第三步就是要找一个 setup 这个 setup 可以让 loss 越小越好 所以我们会写一个这样的式子 我们就是要找一个 c 这个 c 可以让 capital l 越小越好 这个可以让 loss 最小的 setup 我们用 sea star 来表示它 那要怎么解这个问题呢 啊在这堂课里面 我们用的都是 gradient descent 找出赛道 star 然后就结束了啊 你有一个赛大 star 就有一个 fc 大二 那你就可以拿 fk 大 star 来做 你想要他做的事情 你就可以拿 f cup star 来做影像的分类 这个 这个是我们在第一堂课就跟大家讲过的内容好 接下来我们进入 meta learning
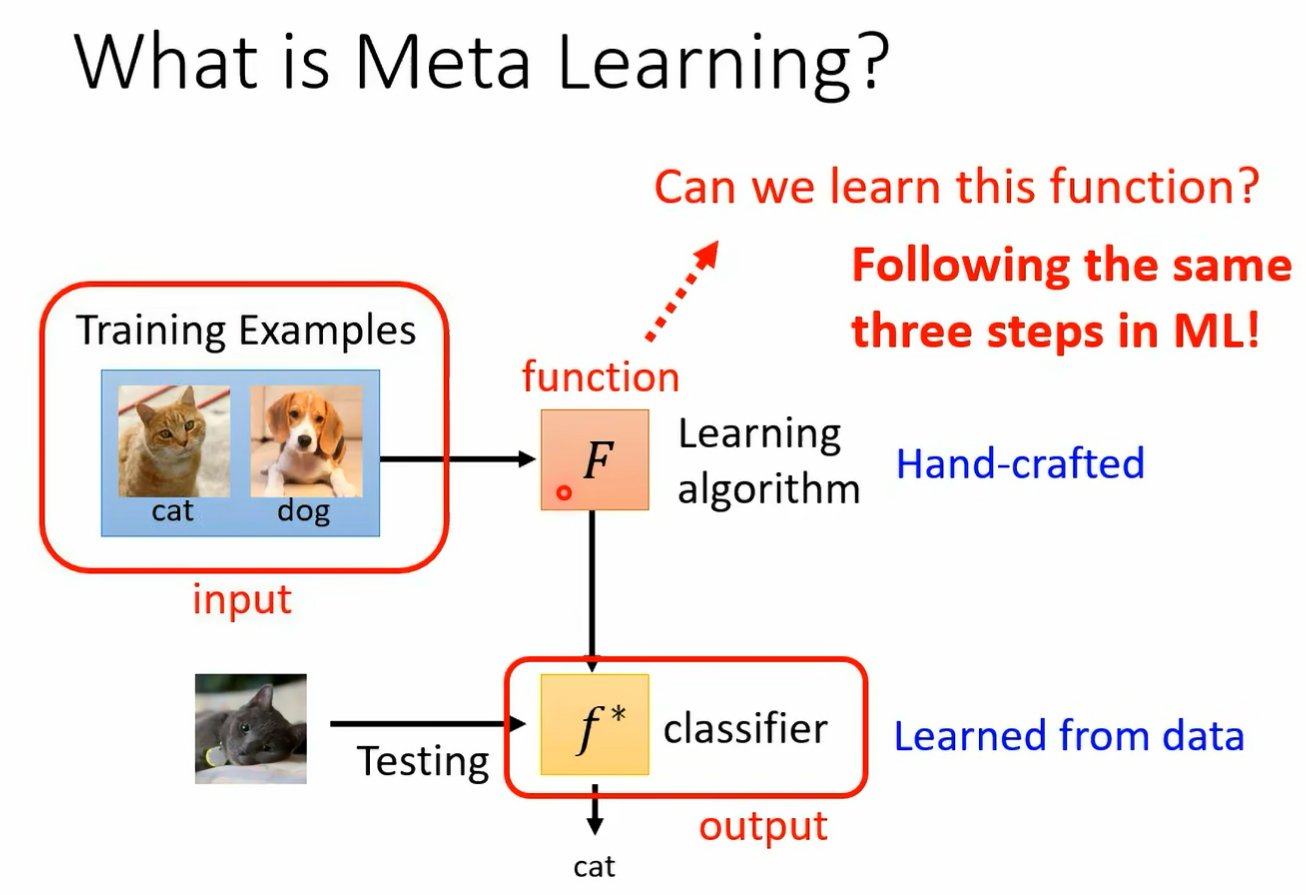
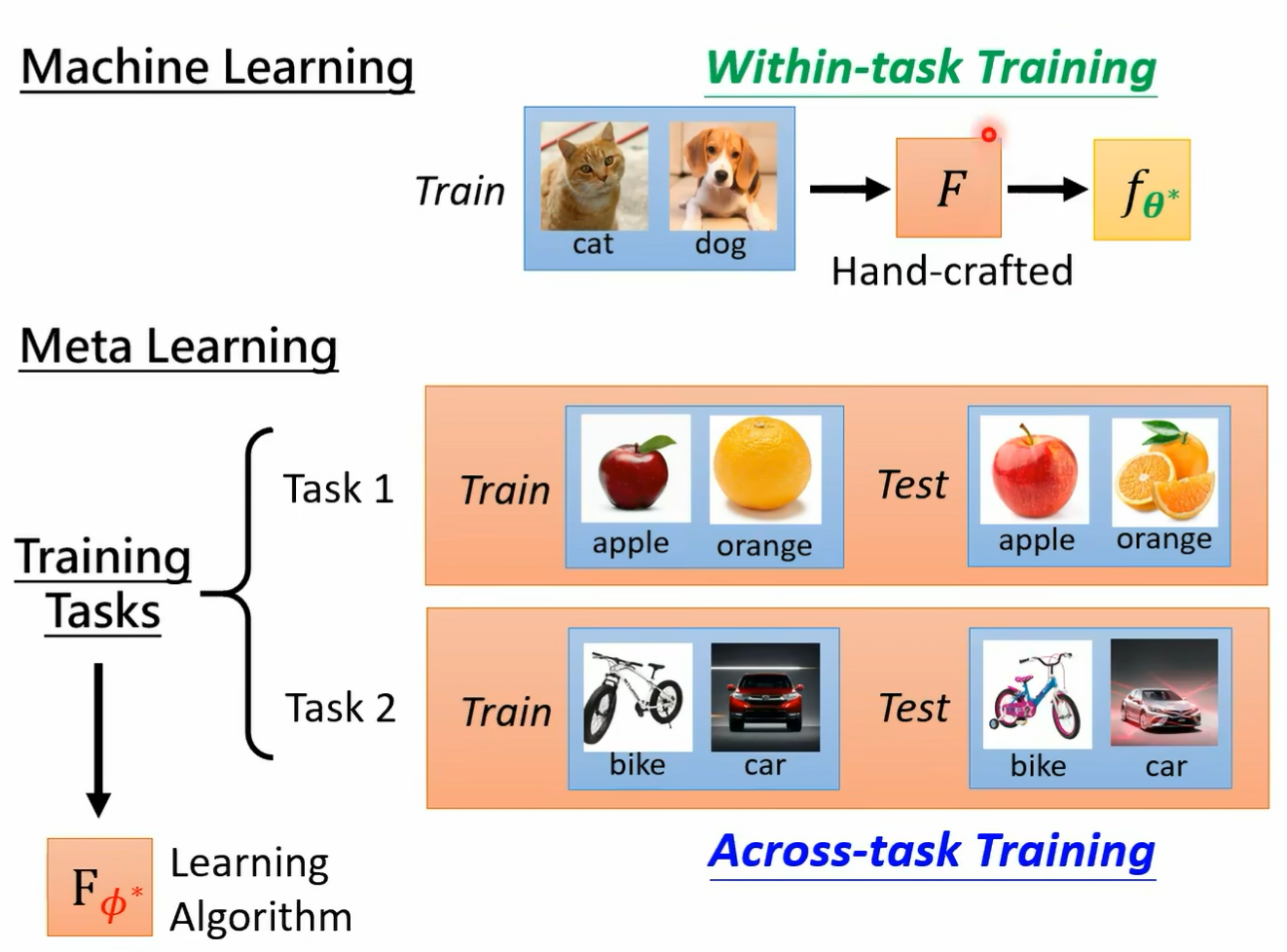
一个 machine learning 的 awm 你把它简化来看 其实它就是一个 function 这个 function 我们用大写的 f 来表示它这个方向的输入是什么 这个方程的输入不是一张图片 而是一个 data set 你把你的训练资料丢到这个 function 里面 它输出什么 他输出训练完的结果 假设我们要训练的是一个 classifier 那这个 function 就是吃训练资料作为输入输出 就是 classify 我们要拿来分类的那个 classify 有了这个 classify 以后 你就可以把测试资料丢进去 然后希望他输出来的结果是我们要的 所以一个 learning algorithm 它是一个 function 我们这边用大 f 来表示它 而它的输入就是训练资料 它的输出是另外一个 function 它的输出是一个 classify 那这个大 f 这个方程是怎么来的呢 它是 handcrafted 所谓 hand crafted 的意思就是他是人定的 它是人想出来的 我们今天的这些 learning album deep learning 啊 然后 gradient descend 啊等等都是人想出来的 那我们能不能够直接学这个 function 呢 我们能不能够用 machine learning 的概念来学这个方式呢 并没 有那么异想天开 想想看在 machine learning 里面我们是怎么找一个 function 的 透过我们讲的三个步骤 在 meta learning 里面 其实我们要找的也是一个 function 只是这个 function 跟 machine learning 一般要找 function 不一样 我们要找的 function 是一个 learning equism 但是我们也可以透过在 machine learning 里面学过的三个步骤
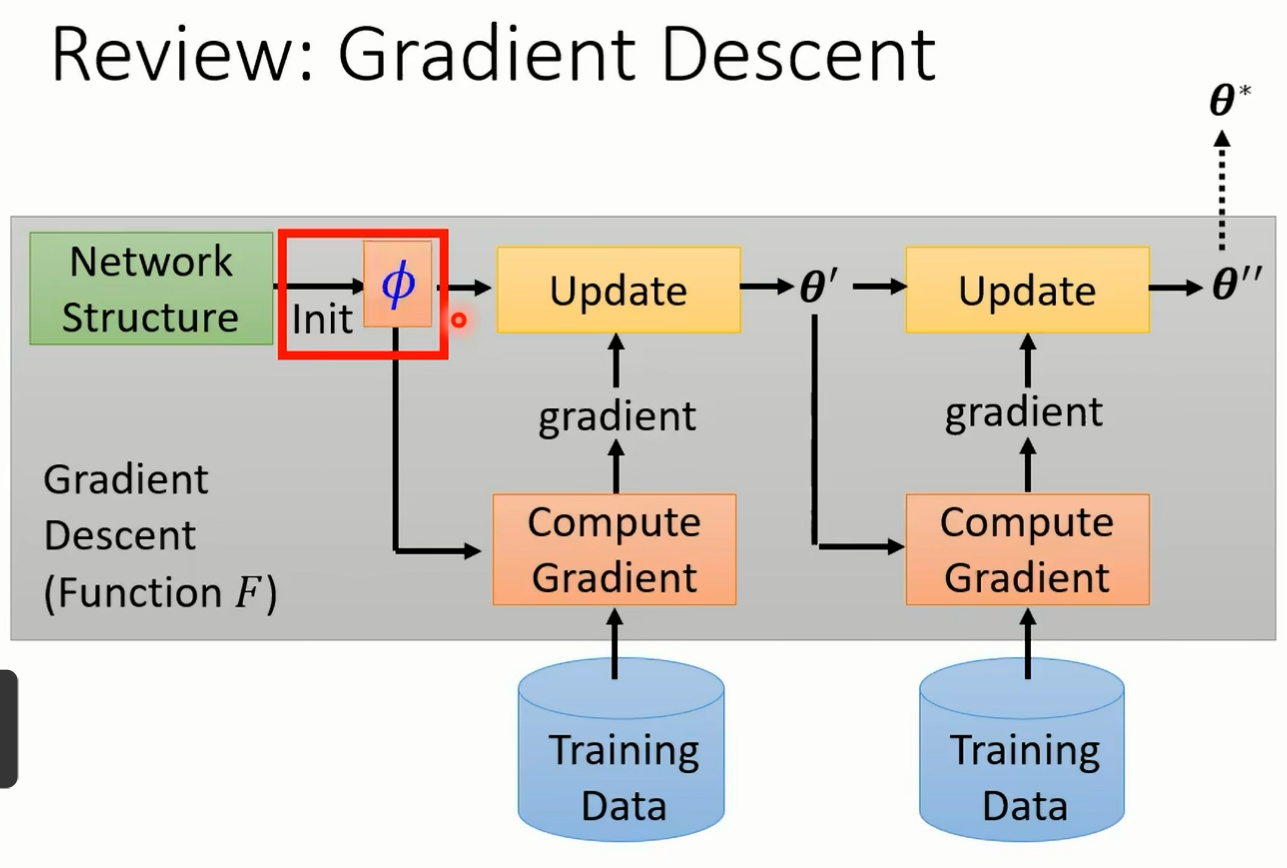
来想办法把这个 learning 的 album 找出来 这个就是 made a learning 要做的事情 好 我们在这边看一下有没有同学要问问题的 他并没有像办法像翻车鱼一样 翻车鱼 就是每次都会生好几亿个卵嘛 然后只要有其中一只翻车鱼活下来就好了 那就我所知 对不对 它好像没有办法 也是生产很多的后代诶 就是这样 好那我们刚才说 machine learning 透过三个步骤来找 function 那 made a learning 透过三个步骤来找 learning alism 第一个步骤是你的 learning alism 里面要有一些要被学的东西 我就像在 machine learning 里面 我们说 neuron 的 weight 和 bias 是要被学出来的 那在 learning over 里面有什么东西是要被学出来的呢 那就看你什么东西 你想要让机器自己帮你决定 那那些就是要被学出来的东西 在 deep learning 里面 你可能会考虑想要自动学出 network 的架构 你可能会考虑想要学初始化的参数 那你可能会考虑想要学 learning rate 那这些我们之前都是啊让机器自己决定 但是呃不是之前说错了 之前我们都是人自己决定的这些什么 network 的架构啊 learning rate 啊 那个是你自己设的 你会设不同的参数 看看哪一个参数可以得到最好的结果 现在我们期待他们是可以被学出来的 我们把这些在 learning average 里面 我们想要他学的东西啊 统称为 f 哦 之前我们是用 set up 来代表一个 function 里面我们要学的东西 那我们现在用 file 来代表一个 learning equism 里面
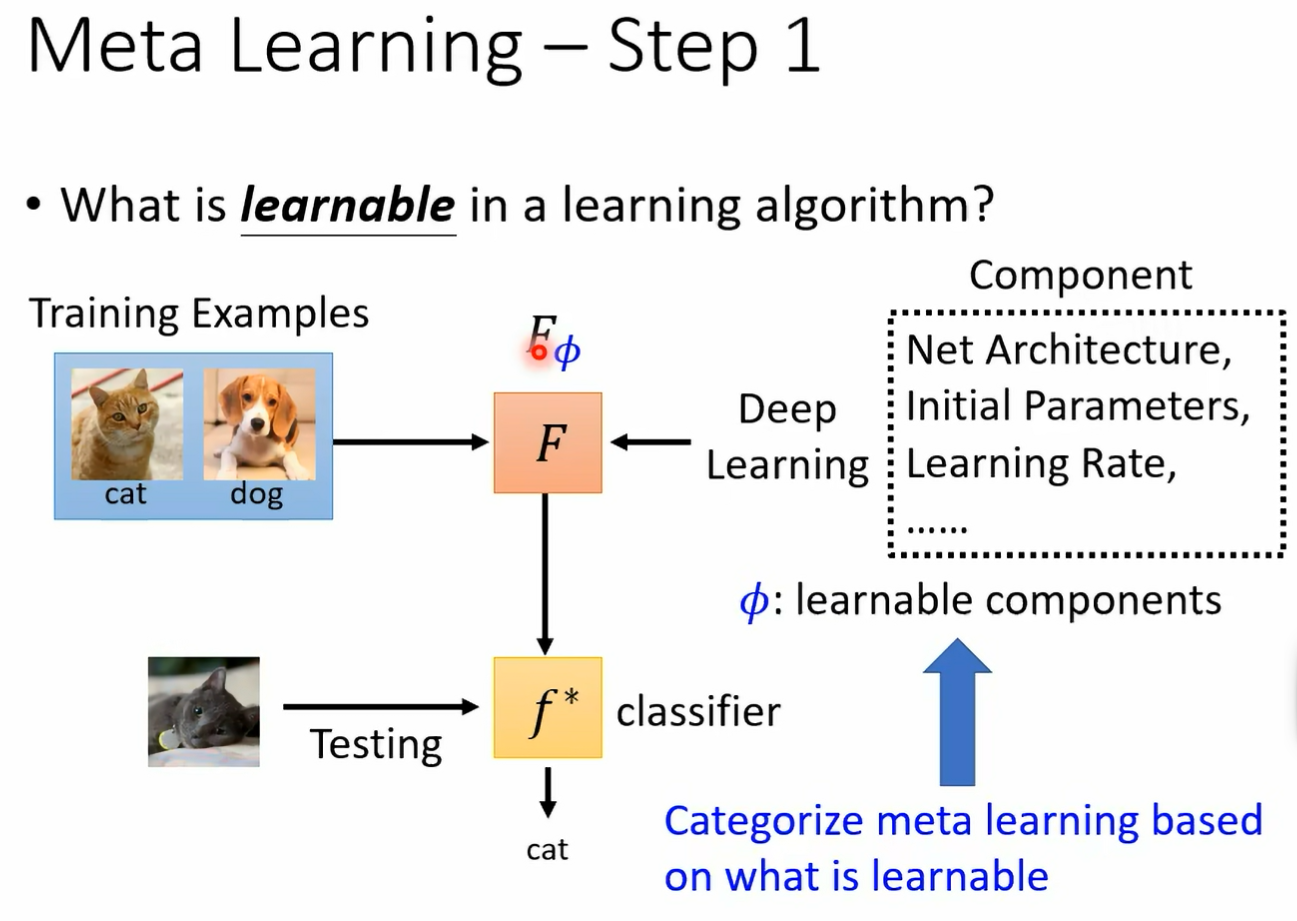
我们想要他学的东西 我说一个 learning aid 在接下来的投影片里面 我们都把它写成 f 和 f 下标方代表说这个 learning algorithm 里面有些是未知的 有发这个参数它是未知的好 那其实不同的 mata learning 的方法 他就是想办法去学不同的呃 component 它就是想办法去学一个 learning equisite 里面不同的 component 当我们去学不同的 component 的时候 我们就有了不同的 meta learning 的方法好 那第二步呢 第二步我们说定一个 loss function 这个 loss function 会决定说某一组参数它有多好 那现在我们的 loss function 在 made a learning 里面 我们的 loss function 就是要决定一个 learning equism 它有多好 那我们这边用同样用大 l 来代表这个 loss function 大 l 的 fine 就代表说现在这个 elm 用来作为这个参数的这个 album 它到底有多好 如果 l of five 哦 它的值很小 肉很小 就代表它吃的好的 learning algm 反之它就是一个不好的 learning algm 但是我们要怎么决定这个大 l 呢 在一般的 machine learning 里面 我们说大 l 来自于训练资料 在 meta learning 里面大 l 是如何决定的呢 我们的训练资料是什么呢 在 made a learning 里面 我们收集的是训练的任务 假设你今天想要训练一个 binary 的 classify 想要训练一个二元的分类器 那你要准备很多二元分类的任务诶 我们就要准备很多二元分类的任务 举例来说啊 你有一个任务 一个任务一呢就是要分别苹果跟橘子的差别哦 你有一个任务二 它就是要分别从跟脚踏车的差别
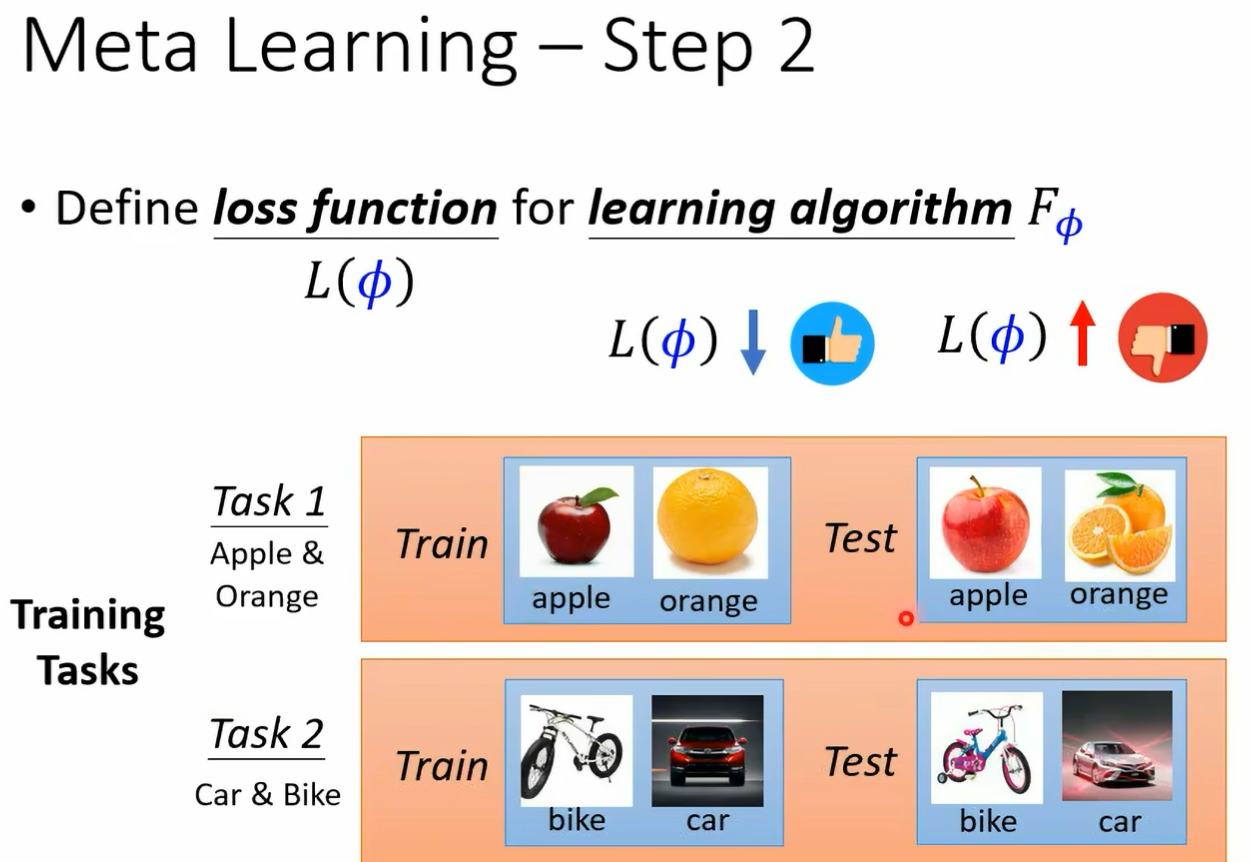
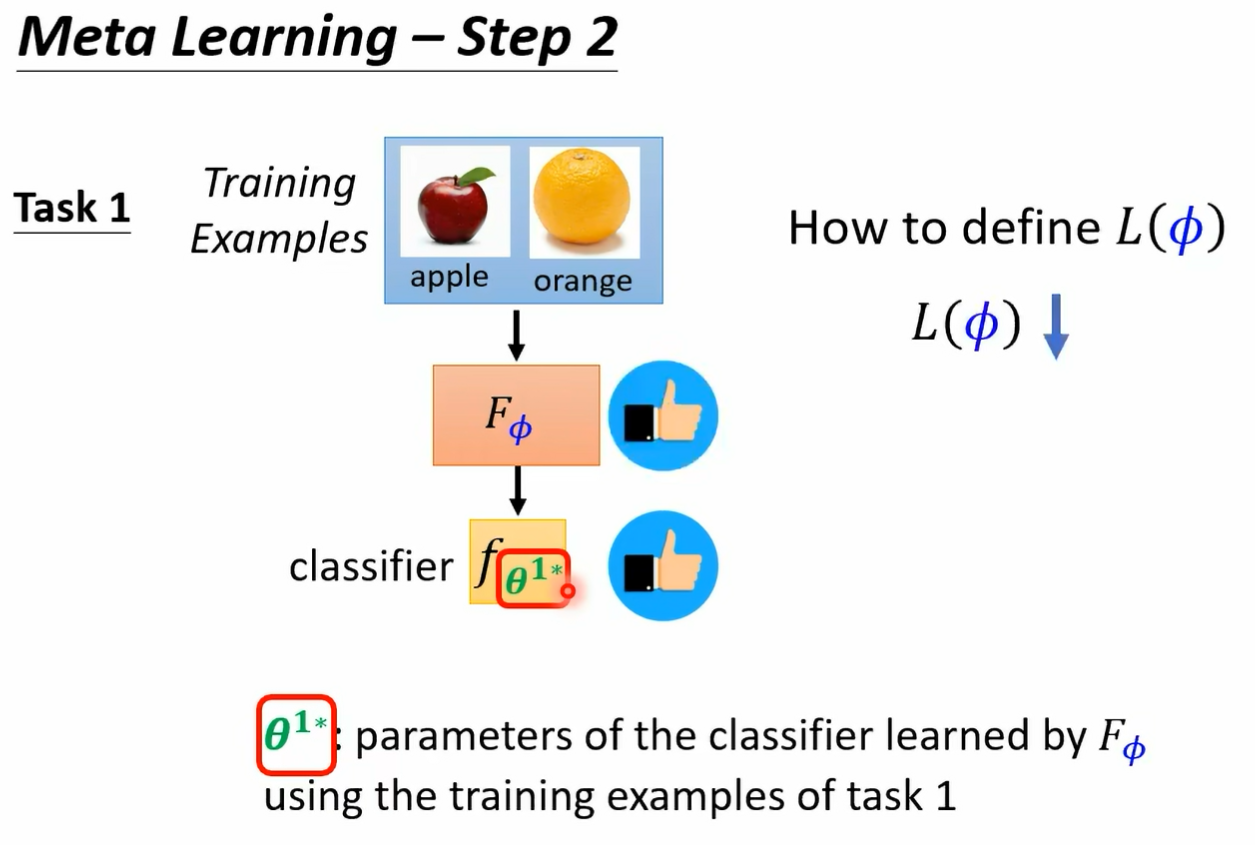
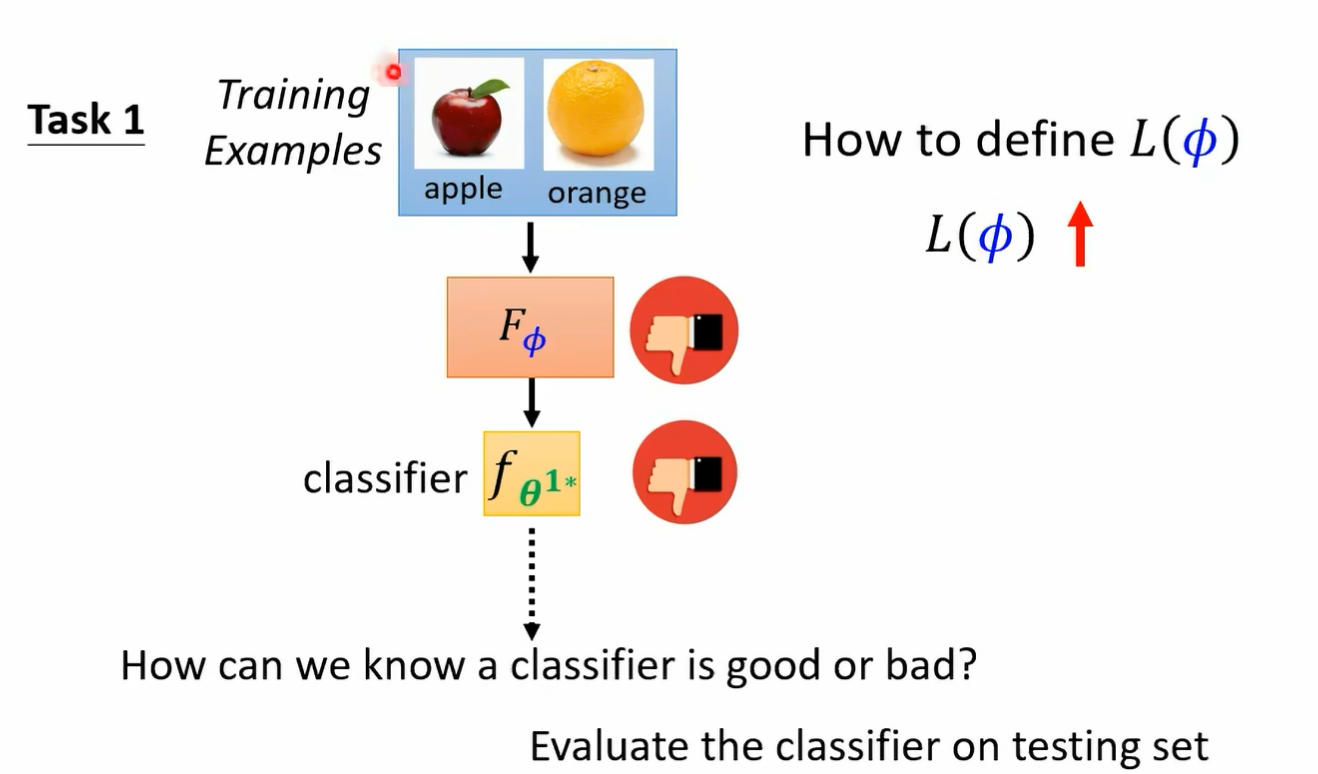
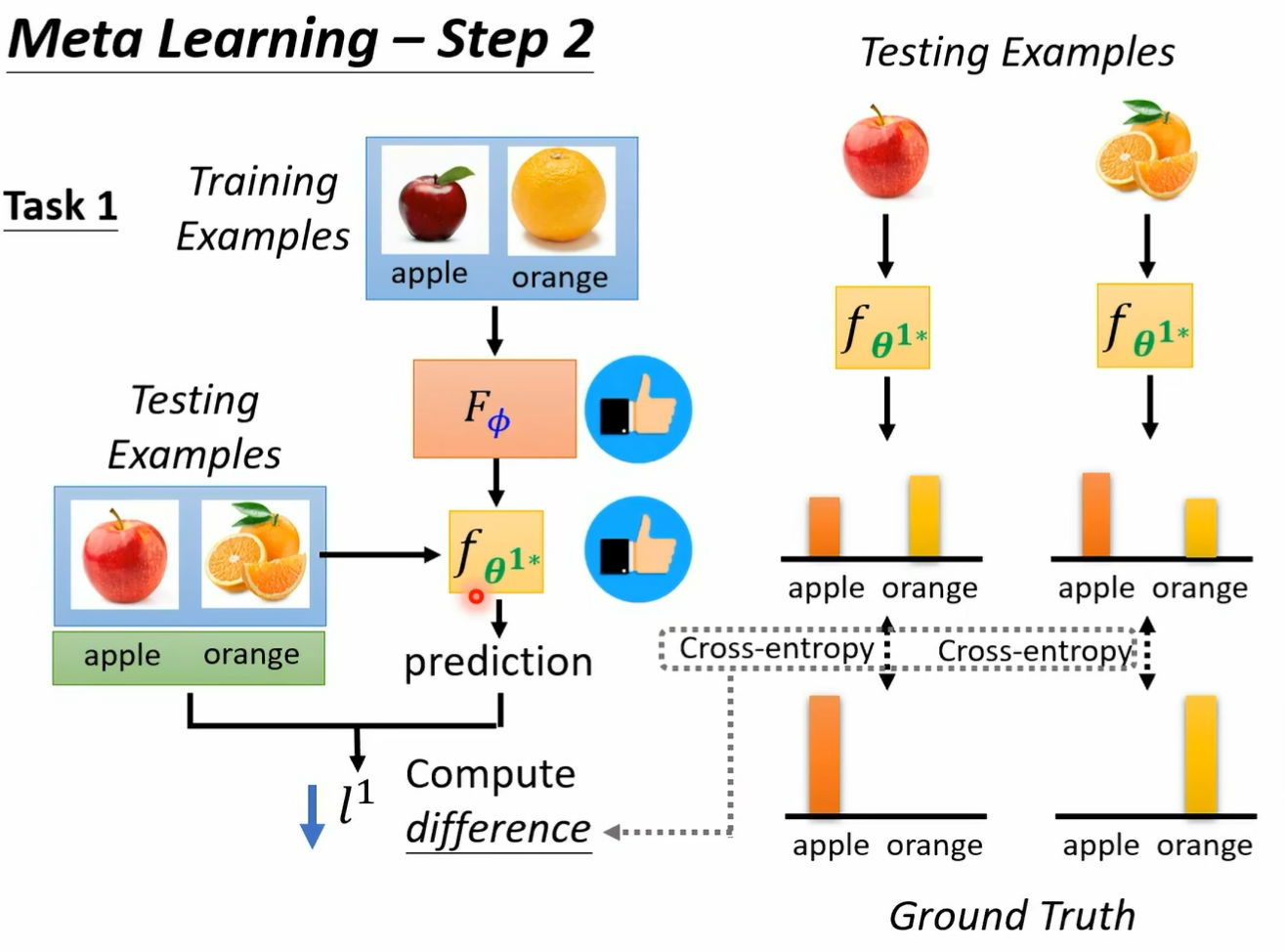
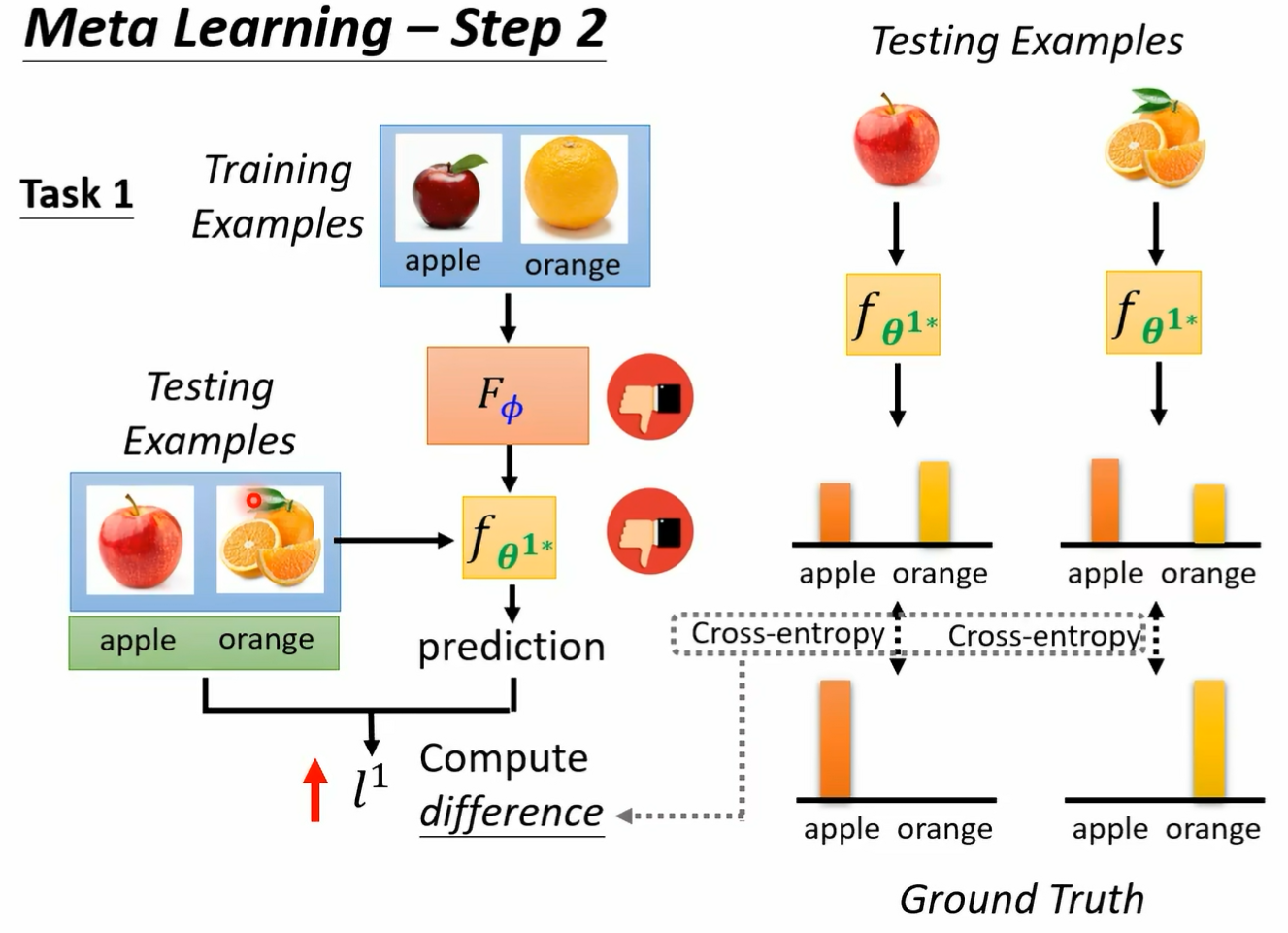
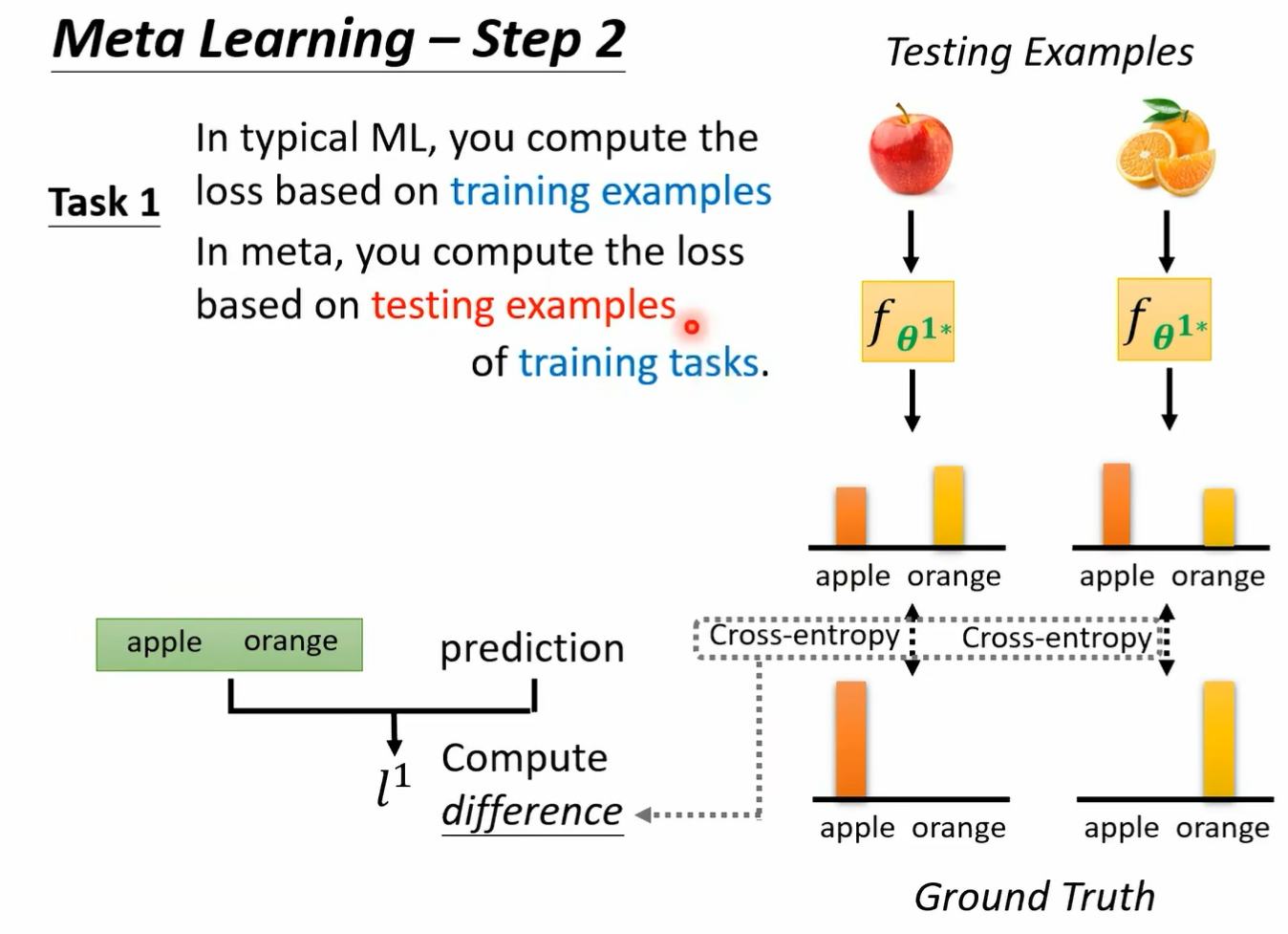
而每一个任务里面我们都会有分训练资料跟测试资料哦 所以这个 may have learning 呢 它是有点复杂的 我们有训练的任务 每一个任务里面有训练资料 有测试资料好 那接下来我们就是要来定这个大 l 应该长什么样子好 我们怎么知道一个 album 好不好呢 那就把某一个任务里面的训练资料拿出来给这个 album 学看看好 所以我们有一个任务 一任务一是分辨苹果跟橘子 我们就把任务一里面的训练资料拿出来丢给这个 learning egm 那就会学出一个 classify 我们这边用 fc 打这个上标一二来代表说啊 这个是任务一的 classify 他的工作呢是分辨苹果跟橘子 它是根据这个 learning algism 它找出来的最好的 classifi 好 那我们怎么知道这个 classify 好不好呢 如果这个 classify 是好的 那就代表我们的 el 规则是好的 反之如果这个 classify 是不好的 就代表说这个 egm 是不好的 那不好的 album 我们就会给它比较大的这个大写的 l 的这个 loss 那怎么知道这个 classify 好不好呢 我们就把这个 classify 套在训练资料上 所以不要忘了每一个任务里面说错了 我们就把这个 classify 跑在测试资料上 那不要忘了这边每一个任务里面都是有训练资料跟测试资料的 所以我们就用训练资料得到一个 classify 以后 把测试资料拿出来 然后用这个 classify 来分类看看看看会得到什么样的结果 按照我们的这个测试资料啊 是有标注的哦 在我们的每一个任务里面 我们的训练资料是有标注的 测试资料也是有标注的 所以我们可以把测试资料的这些图片 d 到 f fi 学出来的这个 classify 里面得到 classify predict 的结果 然后再跟正确答案做一下比较
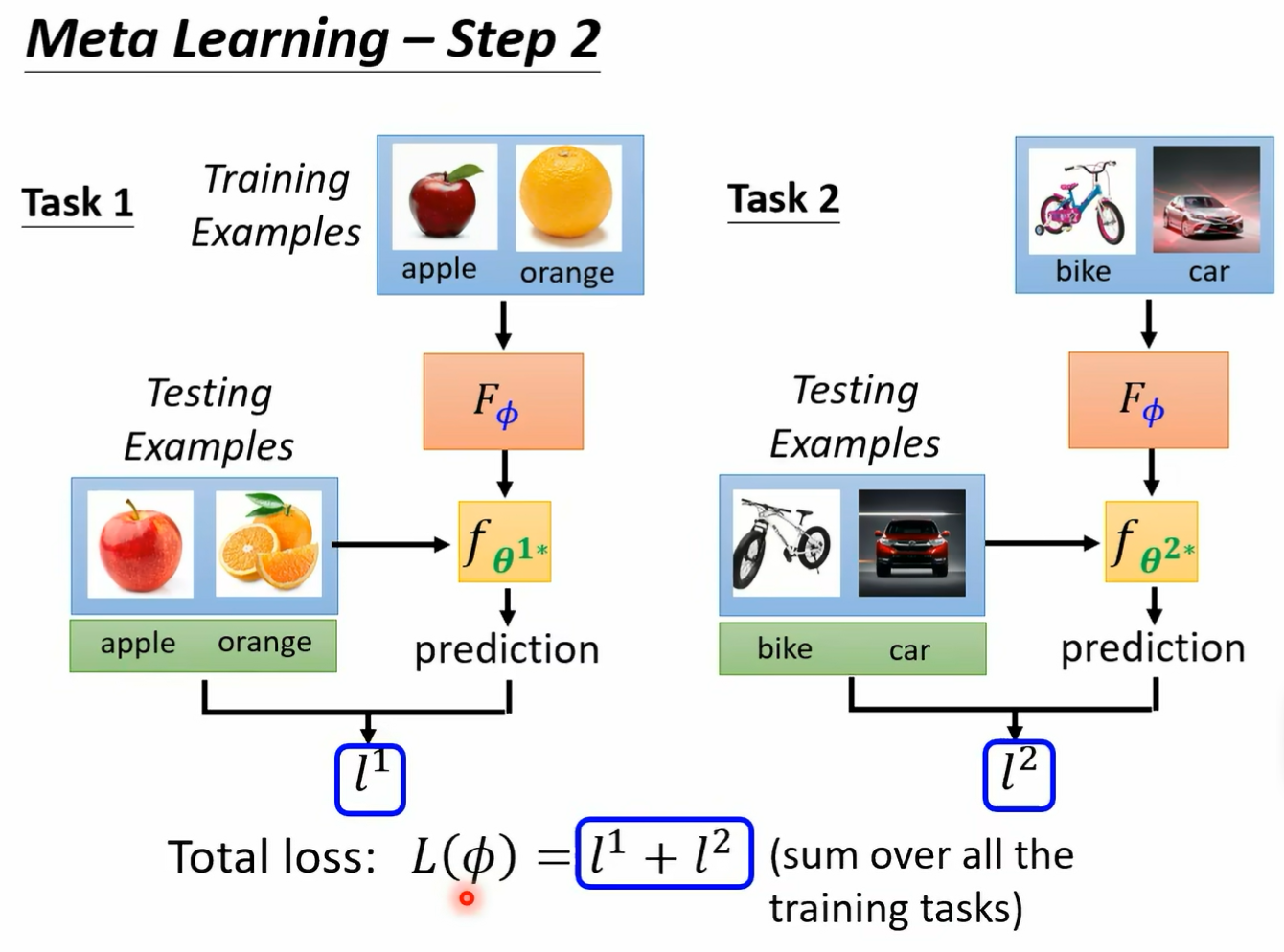
然后呢我们就得到一个 l 上标一 那这个 l 上标一就代表说这个 classify 用在这些测试资料上的时候 它的表现如何 那如果这个 l 上哦 这边讲一下这个 l 上标一是怎么被计算出来的啊 怎么计算 l 上标一呢 其实跟我们在做我们训练的时候是很像的 我们就是把测试的这些资料丢到 fc 打上标 e star 里面好吧 在测试资料丢到 fc 打上标 e star 里面 然后它会得到输出 然后计算输出跟正确答案之间的差异 计算 cross entropy 把 cross entrop 统统加起来 就得到 l3 标一 如果这个 l 上标一的值越小啊 这个 loss 越小 在测试资料上面的这个 loss 越小 就代表我们训练出来的 classify 越好 那这样就代表我们的 learning algm 略号 它是一个 lost 小的 learning alg 好 那反之呢 如果这个 l 越大 也就是我们认出来的这个 classify 用在测试资料上的结果越差 就代表说我们现在的这个 learning algm 是一个不好的 learning algm 那到目前为止啊 我们都只考虑了一个任务 那在 meta learning 里面 你不会只考虑一个任务 你准备了一大堆的训练的任务 所以你不会只用苹果和橘子的分类来看一个 binary classify learning algorism 它的好坏哦 这是一个可以学 binary classified alism 但我们不会只拿苹果和橘子的分类来看它好不好 你还会拿别的二元分类的任务来测试它 比如说你就把那个呃分脚踏车跟汽车的训练资料丢给这个 classify 叫他交给这个 learning egm 叫他写一个 classify 像这两个 learning egm 是一样的 但是因为丢进去的训练资料不一样 所以产生的 classify 也不一样
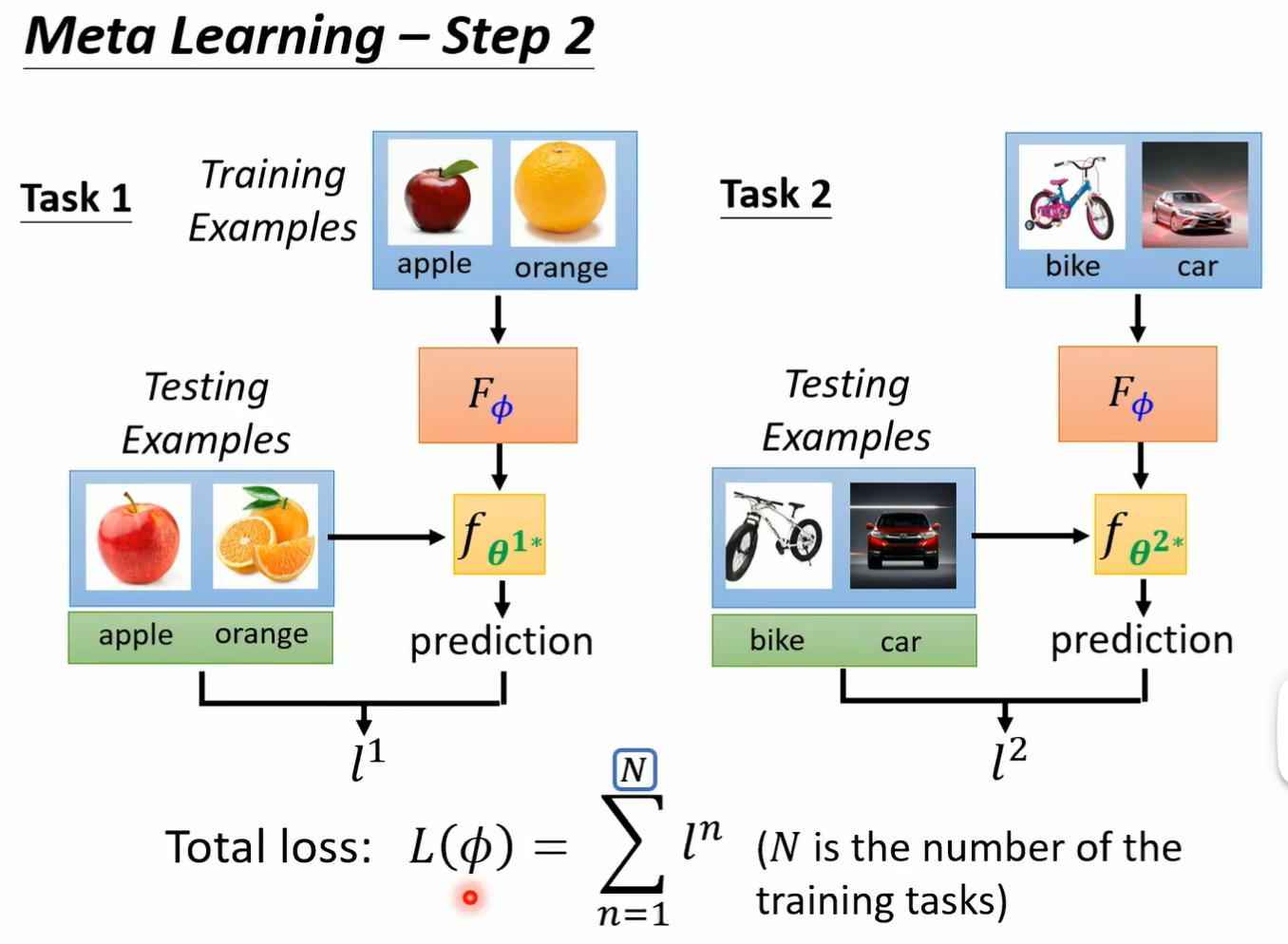
再打上标 e star 代表的是说呢这个呃呃这这一个 classify 他做的事情是分类苹果跟橘子 那这个 set 打上标二 estar 是分类脚踏车跟汽车好 那我们一样这个测任务二呢它有一些 testing 的 data 我们一样把他的 testing data 呢丢给这个 fc 打上标 20star 然后看看说得到的正确率怎么样 我们就计算出 l2 l2 就是这个 learning algorithm 它在第二个任务上的表现 我们现在知道说这个 learning 的 album fi 在任务一和任务二上的表现以后 我们就把任务一和任务二上的表现把它加起来 就得到这个 alism 的 total loss 那这边呢我们在做 我们在做举例的时候呢 只讲了两个任务 但是实际上你在做 made a learning 的时候 你不会只准备两个任务 你会准备一大堆的任务哦 所以你今天的大 l 的 fire 这个发音到底有多好呢 你会看在所有任务上面 lost 的平均值 你会准备大 n 个任务 这个 n 可以是一个很大的数字 你准备一个大 n 个 binary 2 元分类的任务 然后把用 fire 来当做参数的这个 learning algazine 去这个些大 n 个任务上都跑过一遍 在这大 n 个任务上都训练出大 n 个 lefire 然后在大 n 个任务的测试资料上去看看 说这个 class fi 大 n 个 classify 表现怎么样 然后计算出大 n 个 loss 把所有的 lows 平均起来 就代表了现在这个 learning over them 他的表现有多好 好讲到这边呢有一件事情你可能会觉得有点怪怪的 这边在每一个任务我们要计算一个 loss 的时候 对每一个任务要计算 loss 的时候 我们是用测试资料来进行计算 而在一般的 machine learning 里面 一般的 machine learning 里面所谓的 loss 其实是用训练资料来进行计算的 对不对
在一般的 machine learning 里面 我们的大 l 是用训练资料进行计算 但是在 meta learning 里面 我们的这个小 l 是用测试资料进行计算 你一听到什么用测试资料 是不是就觉得让你心跳一下 咦这边怎么可以用测试资料呢 我们在第一堂课就有学过说你是在训练资料上面进行训练 然后把你的 classify 用在测试资料上啊 在训练资料上训练一个模型 然后用在测试资料上啊 你怎么会把测试资料拿来做使用呢 但是这边呢跟一般 machine learning 不一样的地方是我们做的是 meta learning 我们的训练的单位是任务 所以你可以用训练的任务里面的测试资料哦 训练的任务里面的测试资料是可以在 meta learning 的训练的过程中被使用到的 那我知道听到这边也许你会有一点 confuse 诶 这个在胡说什么 也有测试资料 听起来乱乱的 那等一下呢我们把 meta learning 的演算法介绍完以后 我们会把 made a learning machine learning 再做一次比较 希望那个比较可以让你更清楚 made a learning 跟一般 machine learning 他们相同的不相同的地方在哪里好 我们讲完了两个 step 我们现在已经知道要劝什么 我们也可以定出 loss 第三个任务就是要找一个 learning algorithm 找一个 f 让 loss 越小越好 这件事怎么做呢 我们已经写出了那个 lost function 啊 叫 l 到 fl 的发 some mention over 大 n 个任务的 l n 那我们现在要找一个 fine 去让 l 发它的值最小 那怎么做呢 你就是找一个发让 l 的翻译的值最小 那这个可以让 l 的翻译的值最小的这个发音我们叫做 find star 那怎么解这个 optimization 的问题呢 就看看你要用什么方法解都可以呀 看你知道什么 你可以解 optimization 问题的方法

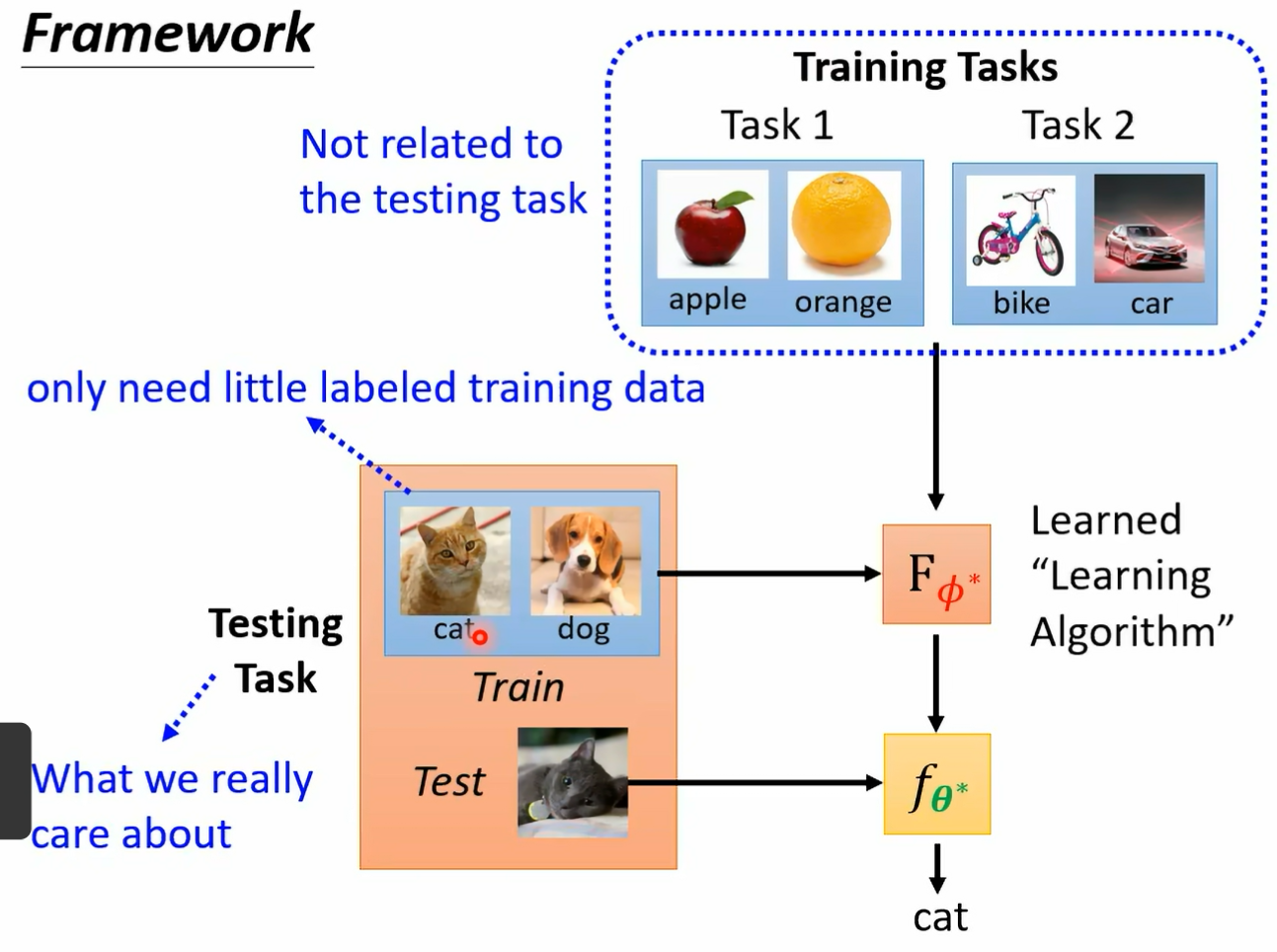
假设今天呢我们知道怎么计算 partial fine partial l of fine 是我们会计算这个规定 那没有问题 直接用 gradient descent 就结束了 但是有时候你会遇到一些问题 就是如果这一项是没有办法计算的呢 因为这个发它可能是一些什么内 work 架构啊之类很复杂的东西 如果 partial fine partial l 的发这个发音对大 l 的 gradient 是无法计算的 那怎么办呢 那就不记得 我告诉你说 如果你在解一个 actimization 的 problem 的时候 如果你没有办法计算 gradient 没有办法计算微分的时候 怎么办呢 用 reinforcement learning 映衬下去就结束了 所以假设今天 l 的 fi 没有办法对 fa 做为分 那没关系 也许你可以考虑用 ile 定做 或者是也有人会用一些 evolutionary 的 alism 硬做 反正就是硬把这个 optimization 问题解开 你就得到一个 learning 的 album 叫做 fiest 好 那假设反正呢不管用什么方法 我们现在把这个 optimization 的问题解开了 得到 five star 了 那就结束了 我们就让机器自己找出来的一个 learning algorithm 这个 learning algm 是一个被认出来的 learning algorithm 我们叫它 f 下标法一二好 所以怎么 make a learning framework 是这个样子 你收集了一大堆训练资料 根据这些训练资料 透过我们刚才讲的三个步骤 你有个 learned 的 learning alism 添加点拗口啊 它是一个 learn learning algm 我们叫做 f five star
然后接下来呢你有测试的任务啊 假设训练的时候 训练的任务是教机器分苹果跟橘子交机器 分脚踏车跟汽车 测试的时候是要分猫跟狗 那每一个任务里面都有训练资料 都有测试资料 那你就把测试任务里面的训练资料 这个点拗口哦 它是测试任务里面的训练资料 学出一个 classify 然后呢再把这个 classify 用在测试任务里面的测试资料上 然后你就可以得到你想要的结果 好那测试的任务是我们真正关心 真正要解的真正希望我们有好结果的任务 那用这些训练的任务 以后用在测试的任务上 希望会有好的结果 它厉害在哪里呢 呃不知道大家有没有听过 f 下 learning 翻译成中文 通常是翻译成那个小样本 每个类别都只给他三张图片 它就可以学会做分类 那很多人听到 fclearning 往往会跟 made a learning 搞混在一起 就想说 made a learning 其实就是 fx learning 那其实它们两者是有不太一样的区别的 feel 像 learning 比较像 是我们期待机器达成的目标 就是只用一点点训练资料就可以训练出我们要的结果 但是为什么大家会觉得 fx learning 跟 man 哈 learning 非常的像呢 那就是因为今天你想要达到 future learning 他只要看到一点点的资料就可以学起来 所以那些 few 下 learning algorim 通常就是用 made a learning 得到的 所以大家往往会觉得说诶 feel 下 learning 几乎就等同于是 mea learning 不过两者还是有微妙的区别的 好我们到这边看一下同学们有没有问题要问的 好我看一下 好这个建成说等于测试任务是不能碰的 对照一般 n l 的话没错
对照一般 n l 的话 这个是你的训练资料 这个是你的测试资料 不过我觉得在 made a learning 里面 我们就不要我们讲这个训练资料 这句话的时候要非常的小心啊 我们也在测试任务 训练的任务拿来训练 fire star 然后用在测试任务上 没有有个同学说每个 task 的 testing data 对于 meta learning 算是 training data 对 就是 training task 里面的 training data and testing data 就是我们的 training data 但是在 meta learning 里面 我们要避免用 train data 这个词 那个很多 paper 在写这个没啥人理相关的事情的时候 他其实就没那么讲究 他就会告诉你说哦我用了一些 train data 他就没有讲清楚 说他的 training data 到底是指 training task 还是说 testing task 里面的 training data 那个这个就非常容易造成误解 所以在这堂课里面 我们就说训练的任务里面有训练资料跟测试资料 测试的任务里面有训练资料跟测试资料 就想成是 training task 跟 testing test 就好 对对对 就是要想成 training task 跟 testing task testing tek 的 training data 在 ma learning 里面是不能碰的 对 testing task 的 training data 是不能碰的 好那个建成说 few shot 是目标 meta 是手段 对对就是这个意思 那看起来大家都还这观念观念都还蛮正确的 那接下来呢呃就先跟大家稍微比较一下 machine learning 和 ming 的差异 然后呢我们再休息十分钟 好 我们来看一下 machine learning 跟 made a learning 的目标 machine learning 的目标是要找一个 function 我们这边用小 f 来表示

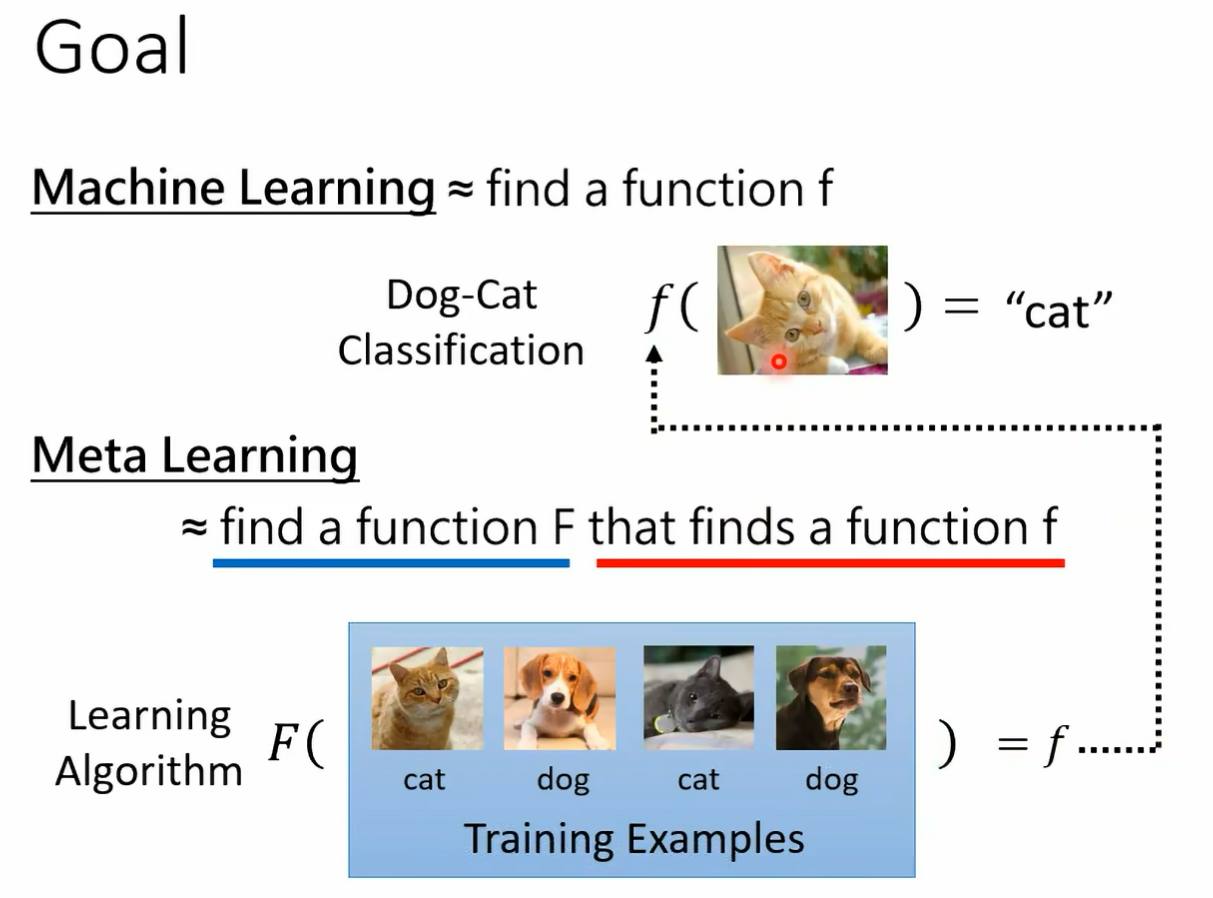
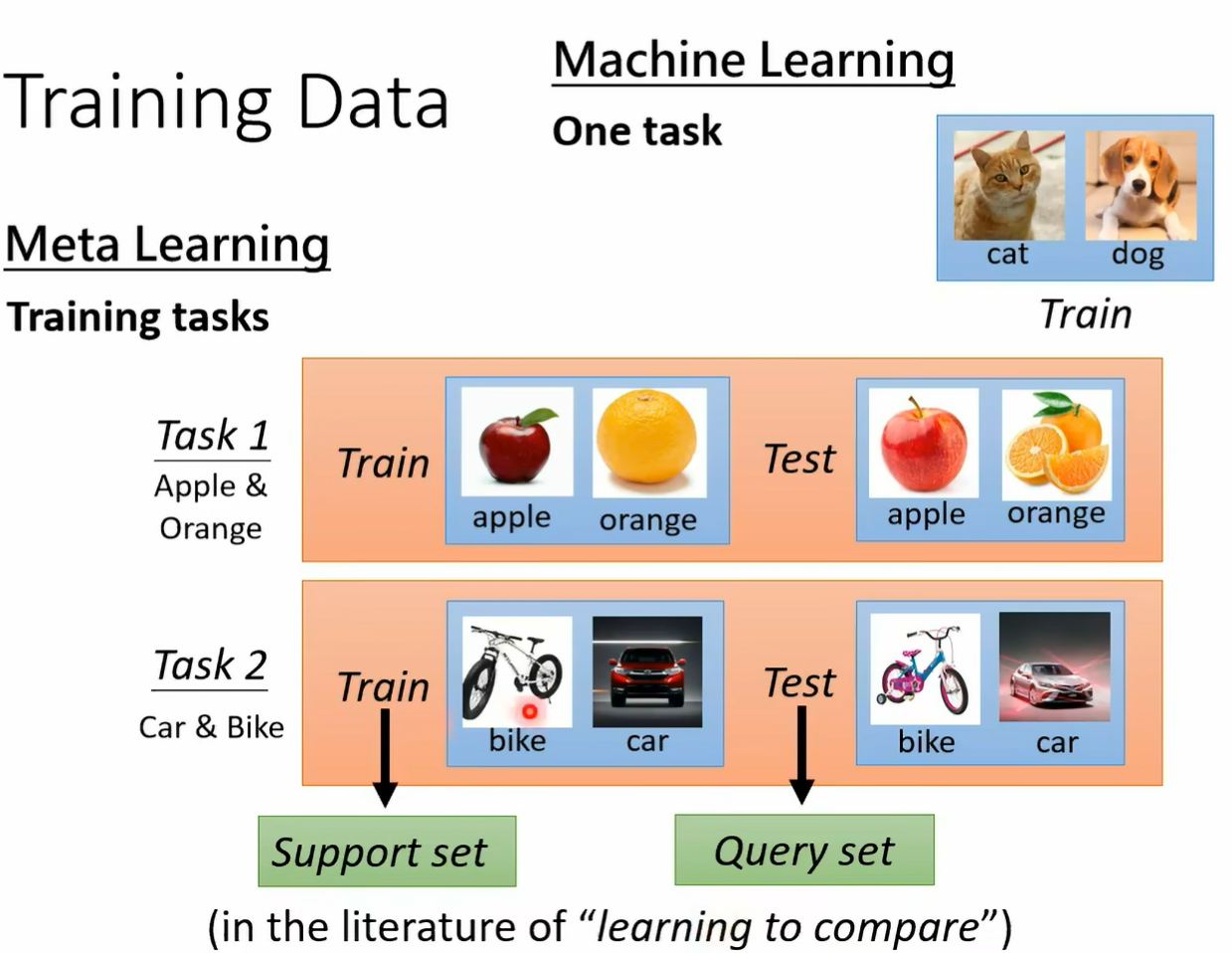
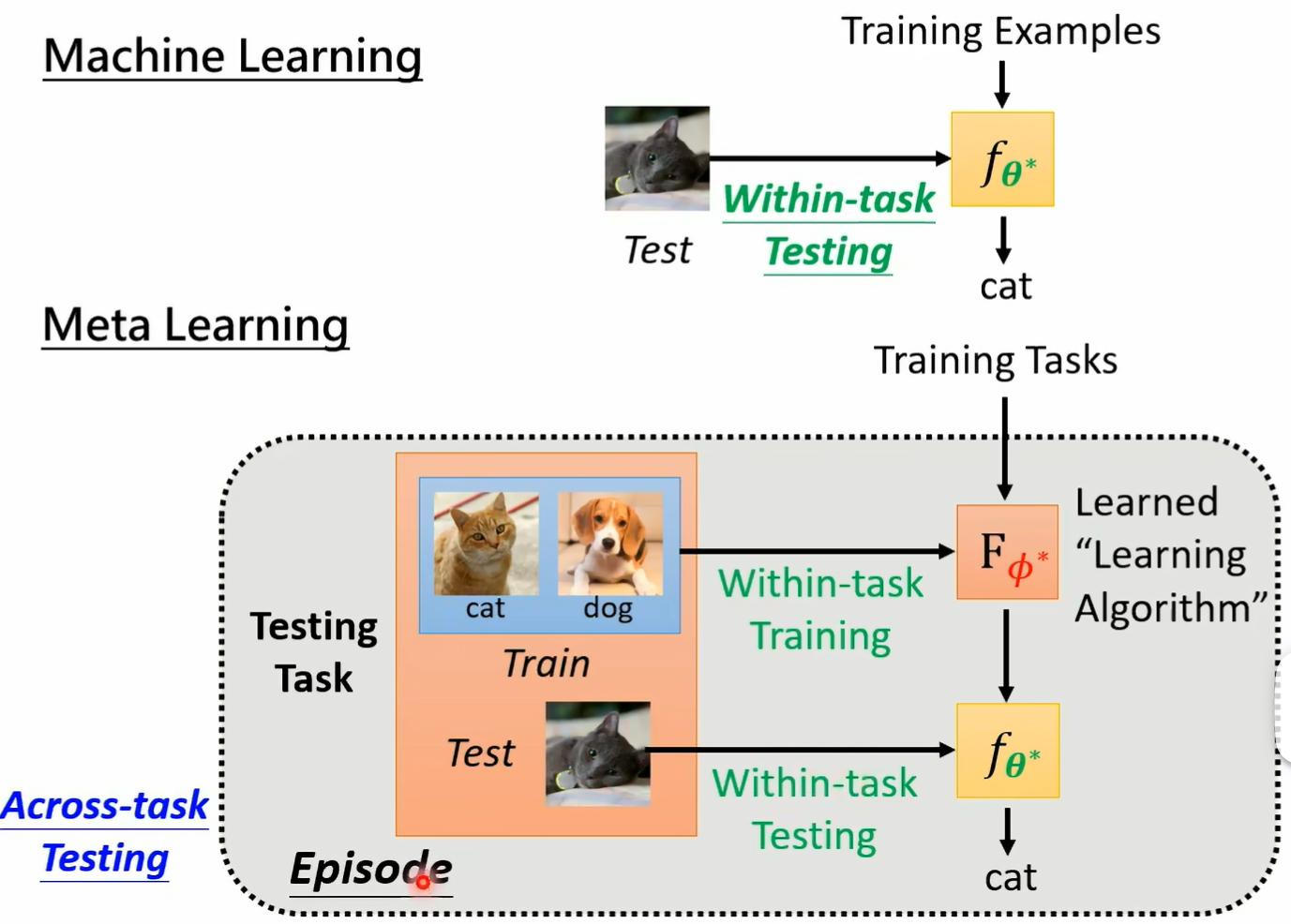
这个 function 可能是一个 classify 百张图片丢进去 它就告诉你分类的结果 meta learning 一样是找一个 function 但他要找的方式 我们这边用大 f 来表示 我们要找一个大 f 这个大 f 是一个可以找小 f 的大 f 不知道大家听不听得懂我在说什么 总之你有一个 learning algm 叫做大 f 这个大 f 持训练资料作为输入 它直接输出训练的结果 也就是一个 classify 希望这个 classify 可以被拿来使用 希望这个 classify 可以丢一张图片进去 就输出分类的结果 好的训练资料呢 这不就在 machine learning 里面 你是拿某一个任务里面的训练资料来进行训练 在 meta learning 里面呢 我们是拿训练的任务来进行训练 这个很容易搞混 所以你会发现很多文献为了解套 怎么解套呢 他们不把任务里面的训练资料跟测试资料叫做训练资料跟测试资料 在文献上常常有一个解套的方法是把任务里面的训练资料叫做 support 把测试资料叫做 query 尤其是在一个叫做 learning to compare 那个系列的 work 里面 更常使用 suppose 跟 query 这个词汇啊 所以你看到有个 paper 说呃 他用 spose 做了做了什么 在用 query set 怎样怎样怎样 这个 suse query set 指的就是一个任务里面的训练资料跟测试资料好 那在 machine learning 里面呢 我们就是有一个 hcrafted learning algm 训练资料丢进去训练 结果也就是一个 classified 跑出来 在 made a learning 里面 我们是有一堆训练的任务 那因为 may learning 他所谓的训练是 involve 一大堆任务的
所以在这堂课里面 我们把 meta learning 的 learning 叫做 across task learning across test training 我们把一般的训练 因为如果我们讲 training 的时候 你很容易误解 不知道他是这样子的 training 任一个 learning ison 的 training 还是有了 learning algorm 以后 找出某一个 classified training 这两个 training 都是不一 这两个 training 是不一样的哦 所以这也是一个 training 的过程 这也是一个 training 的过程 但为了区别这两种圈内的过程 我们把根据一堆任务学出 learning album 这件事叫做 across task journey 只用一个任务里面的训练资料来学出一个 classify 这件事叫做 within test 的 training 好 那所以在 machine 在 machine learning 里面呢 完整的 framework 就是你有训练资料 然后你把这些训练资料拿去产生一个 classify 然后把 testing data 丢到这个 classify 里面 你就得出 classify 的结果 而在 meta learning 里面 你是有一堆训练的任务 把这些训练的任务拿来产生一个学出来的 learning album 叫做 fa sea fist 然后接下来六个测试的任务 测试的任务里面有 query set 跟 testing set 也就是这个 support set 跟 query set 啊 你把这个测试任务里面的训练资料丢到 learning 的认出来的 learning album 里面 得到一个 classify 再把测试资料丢进去 然后得到分类的结果 那我们把这个 math learning 里面的这个测试叫做 across test 的 testing 因为它不是一般的 testing 一般的 machine learning 你的这个 testing 呢我们叫做 within test testing
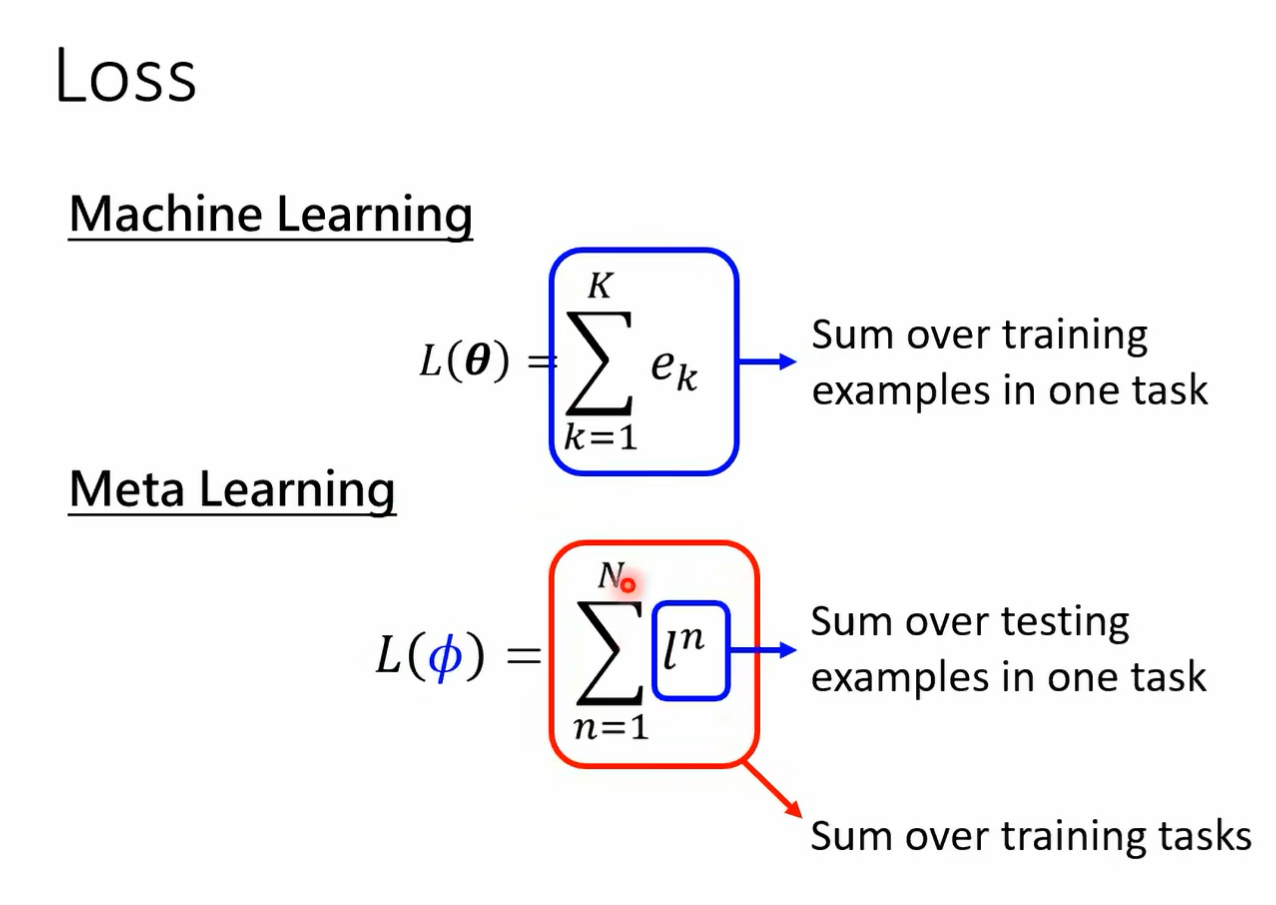
就是你就是把测试资料丢进去就结束了 但在 made a learning 里面 我们要测试的不是一个 classify 表现的好坏 而是一个 learning vim 表现的好坏 所以在 meta learning 里面 大家了解吗 在 meta learning 里面 所以为了强调说 made a learning the testing 不是一般的 testing 我这边叫做 tc 跨任务的测试 在这个跨任务的测试里面 所以今天在 across test testing 里面 你有为 fintest 的 training 加 waftest test 那有时候呢我们也在一些文件上会看到说这整个流程一次 we fintest the training 加一次 reftk 的 testing 这两个这个流程合起来叫做一个 episode 叫做一个 episode 好 那 loss 那在 machine learning 里面我们有一个大写的 l of sea 那这个 l 是 some mention over 所有的 training data 但这个 training data 是来自于某一个任务 在 meta learning 里面呢 我们是 some mention over 在在 meta learning 里面呢 这个小写的 l 他是 some mention over 某一个任务里面所有的测试资料 而这个 sumention 呢是 some mention over 所有的任务 所以 machine learning 你的大 l 是用一个任务算出来的 meta learning 的大 l 是用一把任务大 n 个任务算出来的好 那接下来呢我们来稍微讲一下 training 的时候会发生什么样的状况 在 meta learning 里面呢 假设你 training 的时候需要算小 l of fine 小 a 小 l 说错了 小 l 的 n 因为因为一般我们在做 training 的时候 假设你今天要用 gradient descent 那通常会需要把你的 loss 能够求出来 你当然要能够求出你的 boss 那你要能够求出这个大 l 我们就要能够算每一个任务的小 l 要算每一个任务的小黑
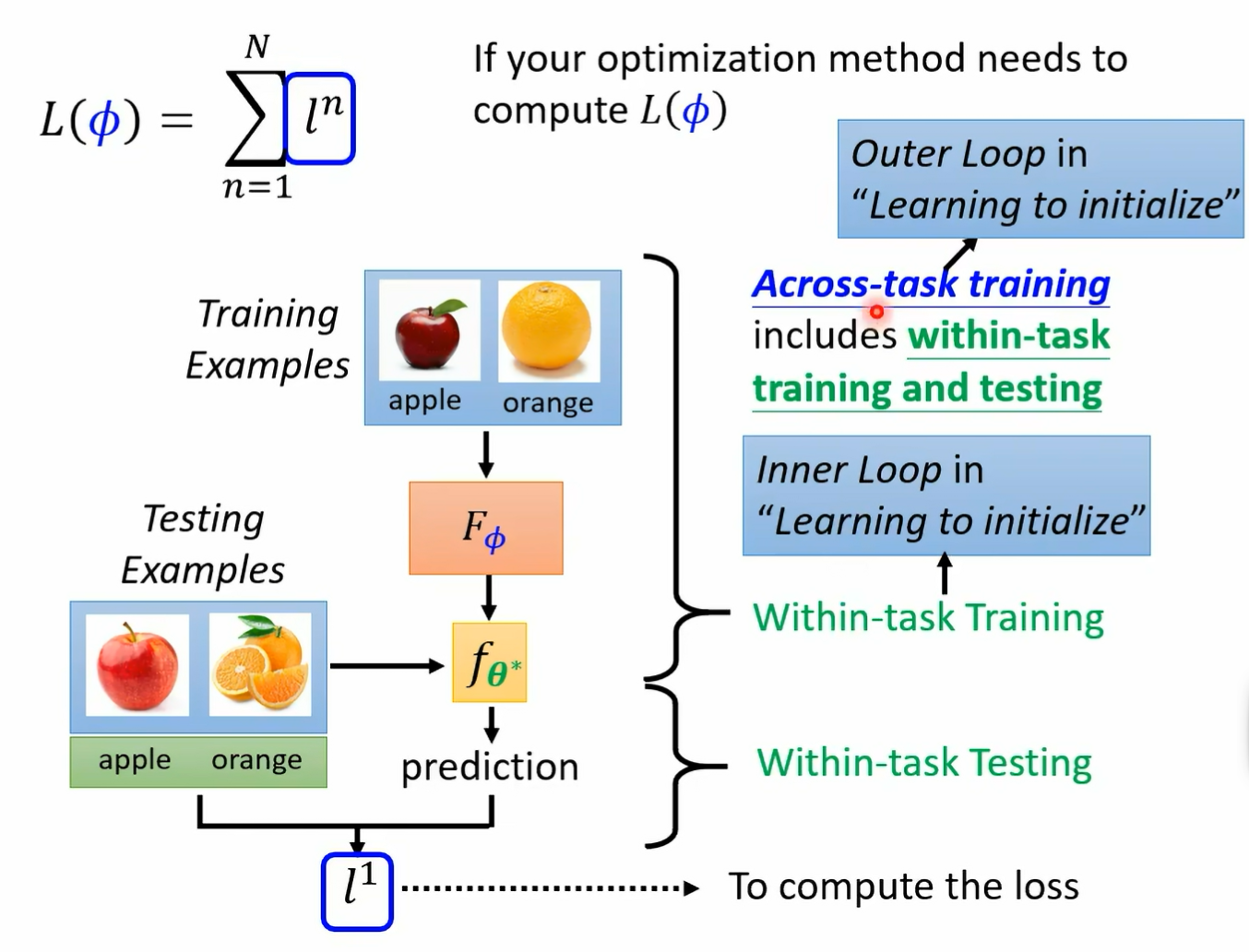
其实没有那么容易 要算每一个任务的小 l 你需要经过一次 within test 的 training 一次 within test testing 也就是一个完整的 episode 你才能够算出一个小 l 哦 所以这边要算一个小 l y 这个运算量往往非常大 你光是要算一个任务的小 l 然后把它统统加起来变成大 l 你就要做一次完整的训练 再做一次测试 你才能够把这个小 l 把它给算出来 好 那假设啊我们今天这个 optimization 的 album 里面 你要找一个发音 让 l 的发音最小 这件事情的时候 你需要算这个大 l 很多次的话哇 跟 within test testing 好多次 那在文献上啊 尤其是 learning to initialize 也就是非常知名的 memo 那系列的 work 里面 往往把 across task training 叫做 auto lo 把 within test training 叫做 inner loop 因为你在 across test training 里面 你要跑好几次 within test training 所以 across test training 是 alter loop 那 within test training 是 inner loop 不过奥特 loop inner loop 这个称呼通常只有在 learning to initialize 那个系列的 work 上才会有了 如果不是 learning to initiate 这个系列 work 通常也不会这样叫 因为有时候你的那个 learning 的 elf 真的他不见得是 erative 我们在做 gradient descent 的时候 那个 learning algorithm 就是要反复跑嘛 要 iterated 去跑嘛 所以他有很多 loop 所以这边叫 alter loop 跟 in the loop 但有些 learning algm 其实没有 loop 那这样叫 alter loop 跟 in the loop 就有点怪了

所以我这边就叫做 within test training the across test training 但是在 learning to initialize 那个系列的文章里面 within test training 叫 in the loop across test training 叫做 outer 路好 刚才讲的都是 made a learning 跟 machine learning 的差别 那他们有没有什么一样的地方呢 他们其实也有蛮多一样的地方的 事实上很多人在 machine learning 那边学到的知识跟基本概念 都可以直接搬到 ma learning 来 用 举例来说 在 machine learning 上面你会害怕 er fee 在你的 training data 上 对不对 你会害怕 所以在 training data 上做得很好 但是在 testing data 上做的不好 在 meta learning 里面也有一样的问题 你会害怕说你 machine 找了一个 learning algorithm 那这个 learning algorithm 只有在 training the task 上做得好 来一个新的 tc 的 task 反而会做得不好 所以 made a learning 也有可能有 overfitting 的问题 如果遇到 open f 点问题怎么办呢 在 machine learning 里面 你是不是最釜底抽薪的方法 就是收集更多的训练资料 在 made a learning 里面也可以做一样的事 你要 made a learning 真的做得好 那你就收集更多的训练的任务啊 就是你看有些你你你如果训练的任务越多 就代表你的 training example 越多 那你训练你在这些圈里任务上学出 来 learning alism 就越有机会可以 generalize 用到新的任务上面 那我们在 machine learning 上会做 data augmentation 你会用一些方法来增加在无在没有增加太多额外附带的情况下 增加你的训练资料 在 meta learning 里面你也可以做 augmentation 你也可以想一些方法来增加你的训练的任务 好
那这边有一个小 这边有一个 made a learning 的问题 主要在做 made a learning 的时候 我们还是要做 optimization 你还是要想办法去找一个 fine 可以让 l 的发音越小越好 但是假设你今天 minimize l of f 的方法一样 用的是 gradient descent 难道那个 gradient descent 就不用调参数了吗 假设你要 learn learning rate 但是你 learn learning rate 的时候 你也要用 gradient descent 你不是有另外一组 learning rate 要调吗 你就是有另外一组 learning rail 调 所以你在自己做 made a learning 的时候啊 也是要报调一波参数的 只是你报调的不是每一个任务训练的参数 而是 learn learning algorithm 的时候的参数 所以你有时候会觉得哇说明它 learning 好像是呃为了避免让自己压力更大 反而压力更大 为了避免秃头 然后让自己压力更大 结果反而秃头这样所以除非他能力也是需要调参数的 但是 made a learning 期待做到的目标是 假设我们假设花了很多力气爆挑一波参数 找到一个好的 learning algorithm 以后它可以用在任何新的任务上 以后在新的任务上就再也不用调参数了 一劳永逸 我们报调一次参数 找出一个好的 learning algorithm 这个好的 learning egm 就不必调参数了 可以用在任何新的任务上好 那既然讲到要调参数啊 那就遇到一个问题了 就记得在我们学 learning 的时候 我们把我们不是只有 train second testing and 我们是有全年 set 有 development set
有 testing set 你用 development set 来选择你的模型 对不对 你用 development set 来决定 比如说你的 network 架构应该长什么样子 而 meta learning 我们有参数要调啊 那 make a learning 是不是应该要有 development task 可能我认为 ma learning 应 该要有 development task 所以在 meta learning 里面你应该要有 training task 要有 development task 来决定训练那个 learning alism 的时候的一些 hyperparameter 然后才跑在 testing 的 task 上面 不过如果你读 make a learning 的文献 你会发现说很多没 learning 的文献诶 它是没有 development task 的 它是只有 training task and testing task 但是我认为 may learning 应该要有 development task 好 那我看看大家有没有问题要问的 好我看一下哦 对就是有可能会有这个问题 这就是一个梗啦 就是现在我 made a learning 对不对 以后就会有人去提 made a made a learning 还会有人再提 mea mea meta learning 不知道什么时候才会停止 什么状况 l of fi 会没办法对 fia 作为分 取决于你的 有同学问说 l of fire 什么时候没办法对发音作为分 取决于你的发音是什么 对不对 就是假设你的发音是 比如说 learning rate 你要能够做微分呐 你的你要那个东西 就是你拿 fi 去对 l 发作为分的时候 你要能够计算当翻译做小小变化的时候 发会有什么样的影响 假设你的 fly 它根本就是 discrete 的东西 它是离散的东西
比如说 network 架构一层两层三层 那他根本没有办法做小小的变化 你根本没有办法说从三层变到 3.1 层 看看会发生什么事吗 所 以如果你的 fire 是一些离散的东西 那你没办法做微分 对 然后 对有个同学说 像 made a learning 里面 i ga 之类的都可以用 对 lga 之类的都可以用 development task 是什么 这个 这个就是你想看你在做 ma learning 的时候呃 你不是比如说你用 gradient descent 来解那个 l lofi 吗 那 gradient descent 里面不是也要调 learning rate 吗 那你那个 learning rate 要怎么怎么决定 你是不是要是不同的 learning rate 那你是不同的 learning rate 有得到不同的 learning algorithm 以后 就我们现在的 learning rate 是要找 learning equism 的那个 learning ro 我们是不同的 learning rate 得到一把 learning equism 以后 你怎么知道哪一个是最好的呢 那你应该用 development set 来挑吧 然后用挑出 development set 最好的那个 learning algm 然后才把它用在 testing test 上面 对不对 这样你才不会 overfit 到那个 你才不会等于是拿那个 testing task 来调你的 hyperparameter 希望加我回答到大家的问题 很多人不知道用 development task 这件事 大家其实也不必太压抑 我觉得这个一个新的技术在发展的过程中啊 本来就会有很多的磕磕绊绊 那今天不是所有的论文 你会发现很多 ma learning 的论文他没有 development task 但是我相信在比如说 10 年后 大家都会知道应该要用 development task
其实我也没有修 我没签 我其实知道你知道就是自学这种课都不是你想修就可以修的吗 我当时也没签到了 我是旁听而已啦 那那个时候李娟田 老师就说哎不是每个人都知道要用 development data set 你读了很多论文 有些论文就没有用 development data set 它就是券在 training data 上 直接用在 testing data 塔上 用 testing data 来调参数啊 这个那个甜甜圈前老师就说这个是躯体 但我们要知道不要这么做 但今天大家都知道是 machine learning 你就是要切 training se development second testing set 那未来大家也都会知道说 meta learning 你就是要签 training task development task contesting task 希望这个回答大家的问题好 我们在这边休息一下 我们休息一下 我们十分钟后回来 我们就是 05:46 回来
# 第二集

那我们已经讲完了 meta learning 的基本概念 接下来就是举一些实例告诉你说在 meta learning 里面什么东西是可以被学的好 那我们一般最常用的 learning algorithm 呢 其实今天就是 gradient descent 啊 只说在 gradient descend 里面 我们就是要有一个 network 的架构 然后呢你初始化一下你的参数 我们把这个初始化的参数叫做 c 大零 然后呢你要有一些训练资料 那他们是从训练资料里面 simple 一个 batch 出来 对不对 我们第一堂课就跟大家讲过 batch simple batch 出来计算 gradient 然后用这个 gradient 呢来 update 你的参数 所以从 c 大零变成 sea plan 然后再重新计算一次 gradient 在 update 参数 然后就反复这样下去 直到次数够多 你满意为止 那就把最终训练的结果 最终得到的参数把它输出出来好 那在这整个过程中 哪些东西是可以劝的呢 首先 initialize 的参数可以劝的哦 所以 c 大林是可以劝的 怎么说呢 一般我们 c 大林呢你就是 render initialize 的吗 从某一个固定的 distribution 里面 simple 出来的嘛 但是你也知道说塞大林对结果往往有一定程度的影响 好的初始化参数不好的初始化参数可以天差地远 那我们能不能够透过一些训练的任务 来找出一个对训练就是特别有帮助的 引力雄的参数呢 可以这个算法就是最在我觉得在 meta learning 这一系列 work 里面 可能大家最耳熟能详的 model agnostic meta learning 它的缩写叫 memo 那它的发音呢就跟哺乳类动物有点像哦 但有另外一个这个 memo 的变形呢就叫做 reptile 那我觉得不知道是不是故意的哈 把这个名字取成 reptile

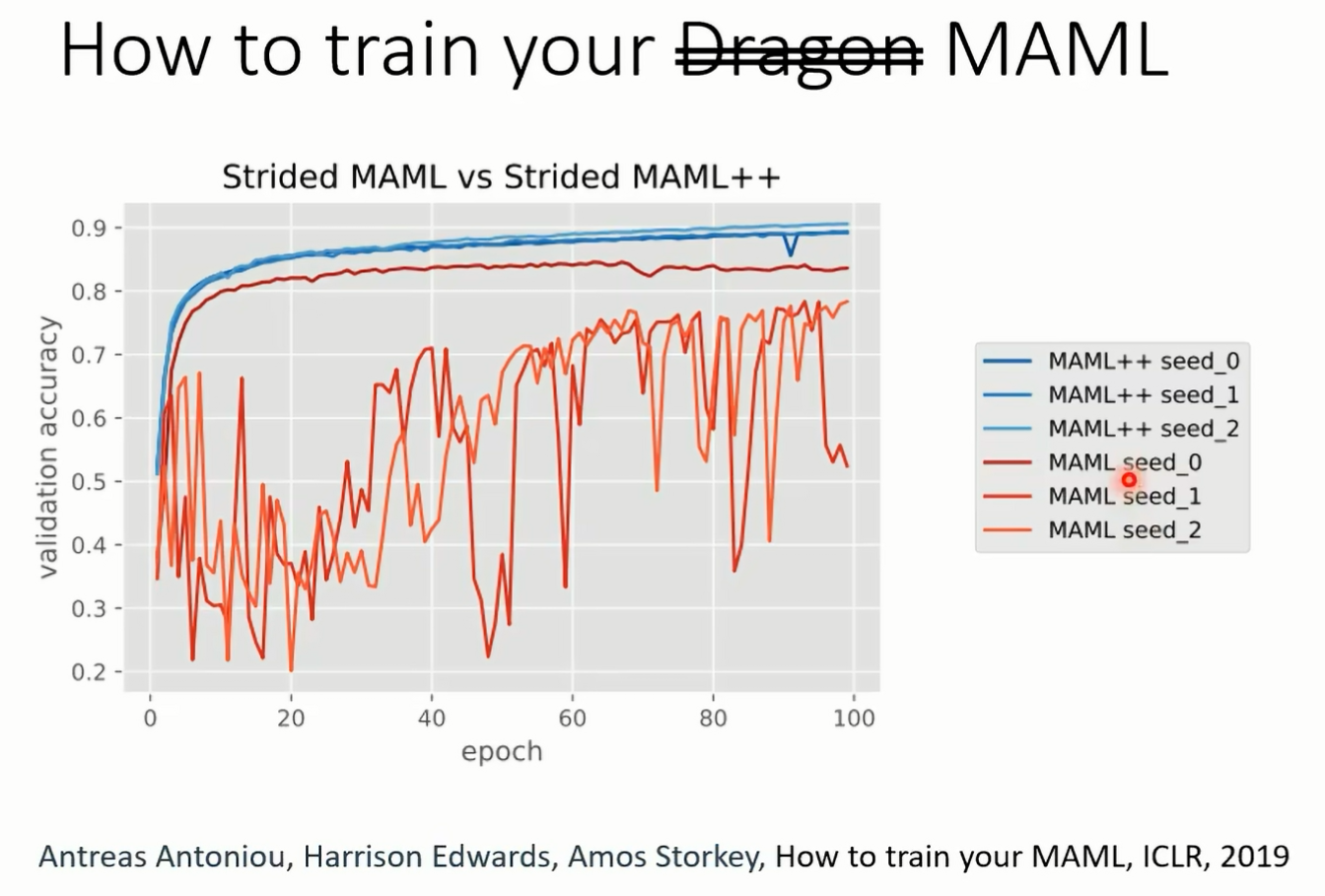
reptile 呢就是爬虫类的意思 这些方法的细节因为时间有限的关系 所以我们今天就都不细讲 我只是把一些 reference 列在这个投影片上给大家参考 但是在作业里面就这个我们会问很多跟 made a learning 跟 mmo 有关的问题 所以假设你想知道更多有关 mo 的细节 你在作业里面可以学到跟更多跟 memo 有关的事情好 所以有一系列的方法 它就是 learning to initialize 它去 learn 这些 initialized 的参数 其中最有代表性的就是 memo 但是就像我们刚才讲说做 made a learning 的时候 你也有 hyperparameter 是你需要挑的 所以做 memo 的时候 虽然你要去认一个 initialized parameter 但是 learn 这个 initialize parameter 的过程中 也是有很多 hyperparameter 你需要自己决定的 这实际上最原版的 mmo 并没有非常好劝啊 有一篇 paper 呢叫做 how to train your mammal 啊 这里是一个玩意梗啊 这个卡通叫 how to 有一个动画叫 how to train your dragon 嘛 他就把 dragon 改成 meal 所以这篇 paper 的 title 叫 how to train your memo 他就说他试着转的 memo 3 次也用不同的 rendc 你知道 train initial parameter 这件事他也需要 rendency 你也需要做 gradient descent 那如果你对这些有困惑的话 在作业里面你可以更详细的知道 memo 确定的细节啊 作业那个在在作业里面有这个 memo 的范例的城市 那你看那些城市以后可能可以让你对 memo 有更进一步的了解 老师劝 m 也是要调参数的 也是需要 random seed 的 只要试了三个不同 random seed 发现就是红色 这三条线有时候劝得起来 有时候劝不起来 所以在这篇 paper 里面 他就提出了一个新的方法叫做 memo 加加啊 期待说啊 mo 加加可以做起来
但有关更多 memo 加加细节 大家在自己去读 how to change 有 memo 这篇文章好 那讲到 memo 啊 讲到找一个好的 visualization 有没有让你想到课程的另外一个主题呢 在课程的另外一个主题讲 self supervised learning 的时候 我们是不是有提到好的 initialization 这件事情呢 在 memo 里面我们有一堆训练的任务 但每个任务里面有训练资料跟测试资料了 我们一堆训练的任务 根据这些训练的任务 找出一个好的 dralization 然后呢用在测试的任务上好 那但是在 self supervised learning 里面 我们是怎么做的呢 在 self supervised learning 里面 我们就是有一大堆的没有标记的资料 那这些没有标记的资料 我们可以用一些 proceed task 去训练它 比如说在 bt 里面就是用填空题来训练你的模型 那其实在影像上也可以做 cell superblearning 你也可以说把影像的其中一块盖起来 叫机器必须预测被盖起来的一块 但今天在做影像的 sales pervise learning 的时候 可能这个 masking 的这种方法 填空的方法不最常用的 今天比较流行用另外一个系列 我们在课这个课程里面没有介绍的 contrastive learning 的方法 那这个有兴趣大家再自己去研究 那总之讲到好的引力 itialization 这件事啊 是不是让你想到 self supervised learning 呢 在 cell supervised learning 里面 我们会先拿一大堆的资料去做 pretrain 那 pre 确的结果我们也说它是好的 initialization 然后把这些好的 initialization 一样可以用在测试的任务上 那这两者有什么不同呢 当然如果我们直接比较 memo 跟今日的 cell supervised learning 的话
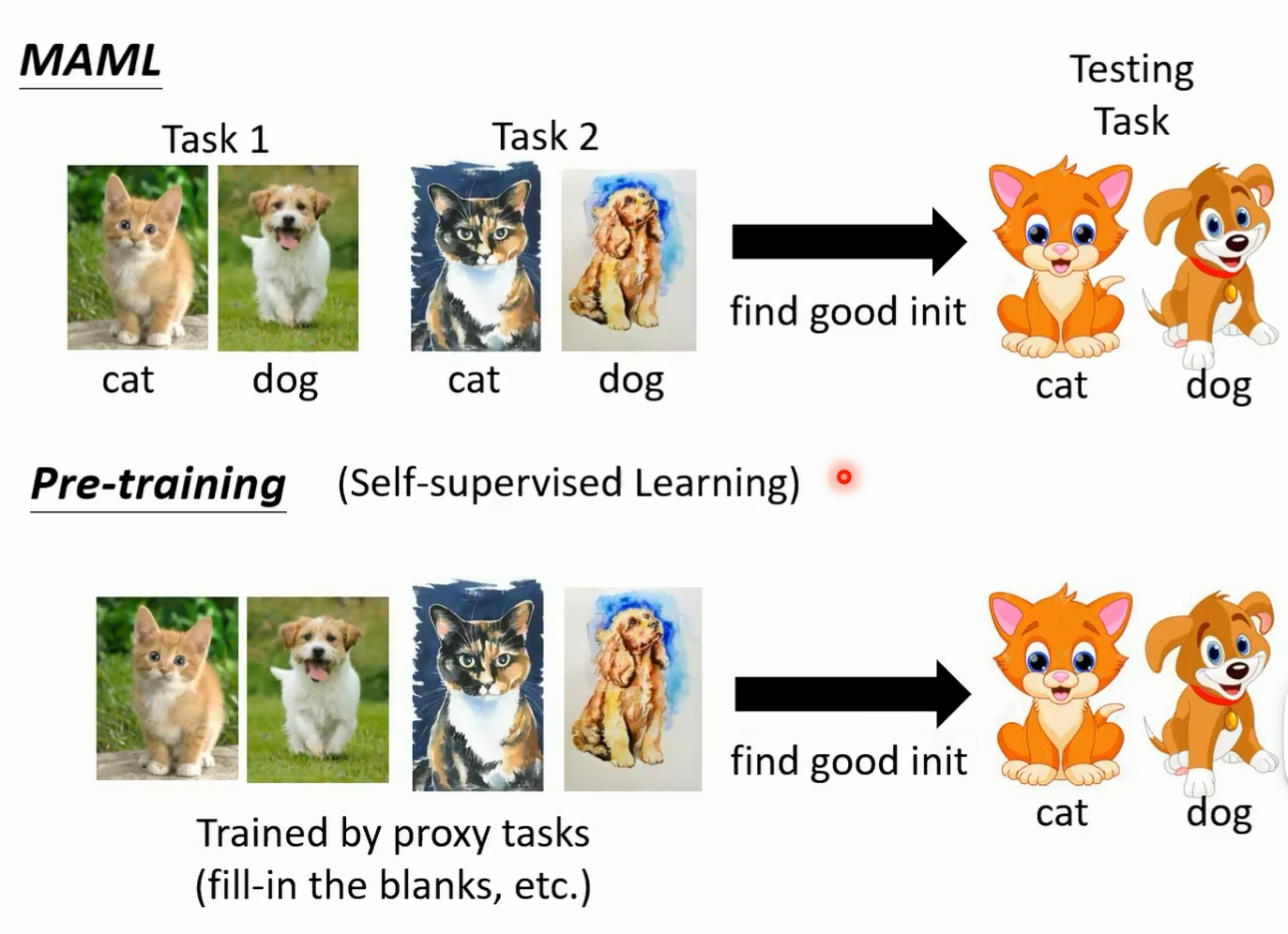
那至少最明显的不同是啊 memo 呢这些任务是有用到标注资料的 而在 self supervised learning 里面 我们是没有用到标注资料的 所以 pretrain 这一招 sell supervirning 这一招虽然会好 但是你不知道为什么会好 我们其实今天并没有非常清楚说 为什么这些 process 的任务对 testing test 会有帮助 而对 mo 而言 它会好是不是理所当然的 也许它就可以 transfer 到 testing 的任务上 但是如果你回到几年前 在还没有 self supervised learning 这个词汇的时候 你的 sal supervised learning 呢 它会这个词汇会爆红起来 也是伊拉克在 2019 年 4 月的时候说的 我记得是好像是 4 月 30 号之类的 第一次讲 memo 的时候 其实是 4 月 30 号之前的 那个时候我们都还不太清楚 sale supervise learning 这个词汇 那是师傅把任意这个词汇当然在养哪个 讲说这个 cell supervise learning 很厉害 之前其实也有人用过这个词汇了 只是之前如果你随便发明这些怪怪的词汇的话 你肯定会被别人抨击嘛 不过大神讲说有一个技术叫 cell supervised learning 那就有了 cell supervised learning 好 总之过去啊 在 sales supervised learning 这个系列还不红的时候 那个时候 pretraining 有另外一种想法 比较常见的做法是你一样有好几个任务的资料 你把这些好几个任务的资料通通都倒在一起 把它当做一个任务进行训练 然后接下来呢你一样可以找一组好的 itialization 一样可以把它用在测试的任务上 那像这样子把好多个任务的资料通通倒在一起 当做一个任务来训练的做法
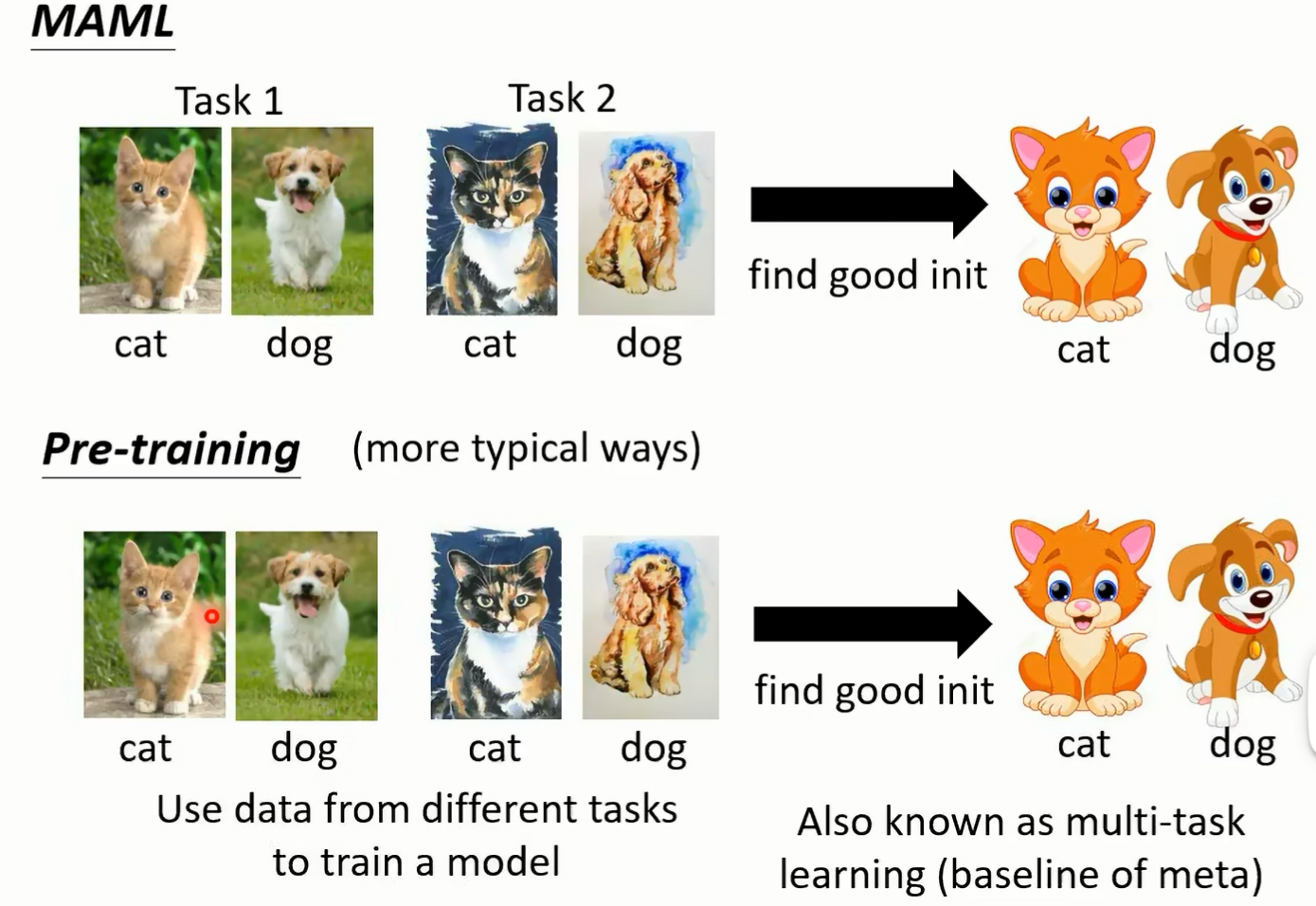
这个叫做 morttest ching 那其实一边今天一般你在做 memo 的研究的时候 那通常会把这种 mottest 圈联方法来当做 meta learning 的 basel 为什么会把这样的 mortal test learning 当做 memo 的 baseline 呢 因为仔细想想 你会发现说这两个方法他们用的资料都是一样的 一边只是我们会把不同的 task 分开 另外一边把所有的 task 的资料倒在一起 这两种方法有什么样的差别呢 好假设你想要知道更多 made a learning demo 跟 pretrain 的差别的话啊 你可以看一下这个影片 而在这个影片特别我今天特别要强调这个影片 这期这样请大家务必要看 是因为这个影片里面它是有防不胜防的业配的啦 那我现在要特别夜配这个影片 这个就是夜配的业配 就是 meta 也配好 那在这些投影片呢 你会发现说我们这边的训练的任务跟测试的任务差距并没有很大 刚才的举例里面我都说训练的任务是分类呃 这个呃苹果跟橘子分裂类 车子跟脚踏车 但是在今天这个例子 在这些投影片的例子上啊 我特别说我特别举了一个例子 是说诶每一个训练的任务都是要分类猫跟狗 只是现在每一个任务里面的图片 它的类型是不一样的 在任务一里面啊 是真实的图片 好在任务二里面呢是这个呃油画的图片啊 在任务栏里面是卡在测试任务里面是卡通的图片 那你很会说这个不就是 domain adaptation 吗 我们在某些任务上面学到的东西 在某一些某一些抖音上学到的东西 要被 transfer 到另外一个 dman 没错 他就是你也可以说它就是 domain adaptation 所以假设我们今天在做 main a learning 的时候 我们的不同的任务其实就只是不同的 dman 而已
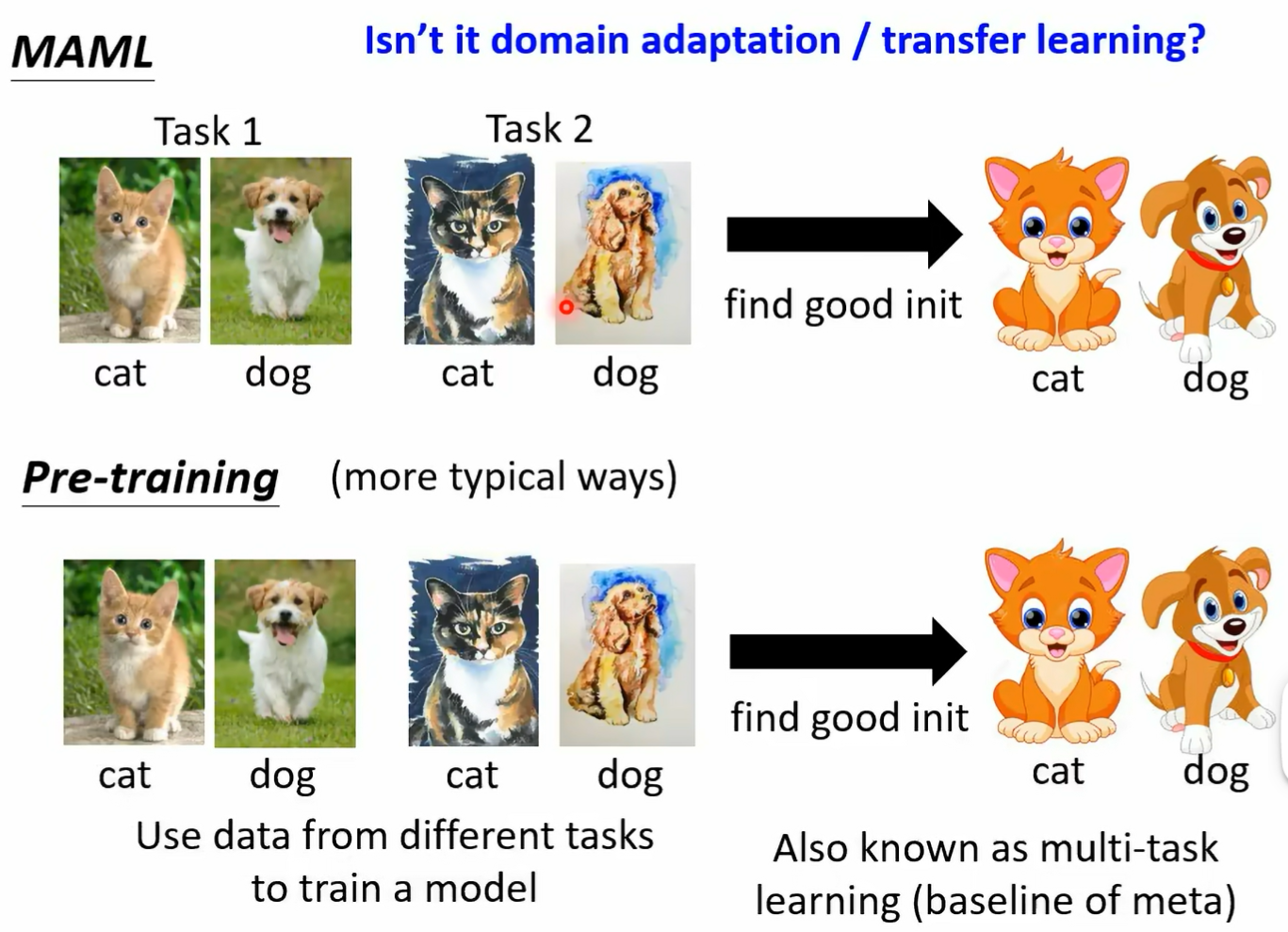
那你也可以说 maharmony 就是一种 dman adaptation 的方法 那就那那那当然有人可能 那其实在 machine learning 里面的这个 task 呢跟抖妹的定义 它们的分也并没有那么明确 我可以说这个是不同的抖妹 但我也可以说他们就是不同的任务 其实都是可以的 这假设你今天不同的任务其实就是不同的 抖面上的同样的分类问题的话 你也可以说没他的脸是一种解 dman addictation 的方法好 总之呢我觉得在 machine learning 这个领域里面呢 有千千万万的词汇不断的被新词汇不断的被发明出来 总觉得大家在研读这些文献的时候 其实也不用太拘泥于这些词汇 你要真正要在意的是 这些词汇背后所代表的含义是什么好 那 memo 到底为什么会好呢 有两个不同的假设 有一个假设是没 memo 找出来的那个 initial 的参数 它是一个很厉害的 initial 的参数 这个很厉害的 initial 的参数 它可以让我们的比如说 gradient descent 这种 learning algori 快速的找到每一个任务账号的参数 那另外一个假设是说这个 initialized 的参数 它本来就跟每一个任务上最终好的结果已经非常接近了 那所以因为他已经跟好的结果非常接近 所以你直接 apply gradient design 就可以轻易的找到好的结果 到底是哪一个呢 有一篇 paper 呢它里面提出来的一个方法叫做这个呃 有一篇 paper 呢它的 title 是 raid learning or featureuse 左边这个叫做 raid learning 右边这个叫做 featuring youth 那到底 mamal 它的好是好 在左边这个理由还是右边这个理由呢 那你可以自己去看一下 paper 会发现说呃在 paper 里面得到的结论是 feature reuse 才是 m 好的关键 那在这篇 paper 里面呢 同时提出来了另外一种 memo 的变形 叫做 annie 啊
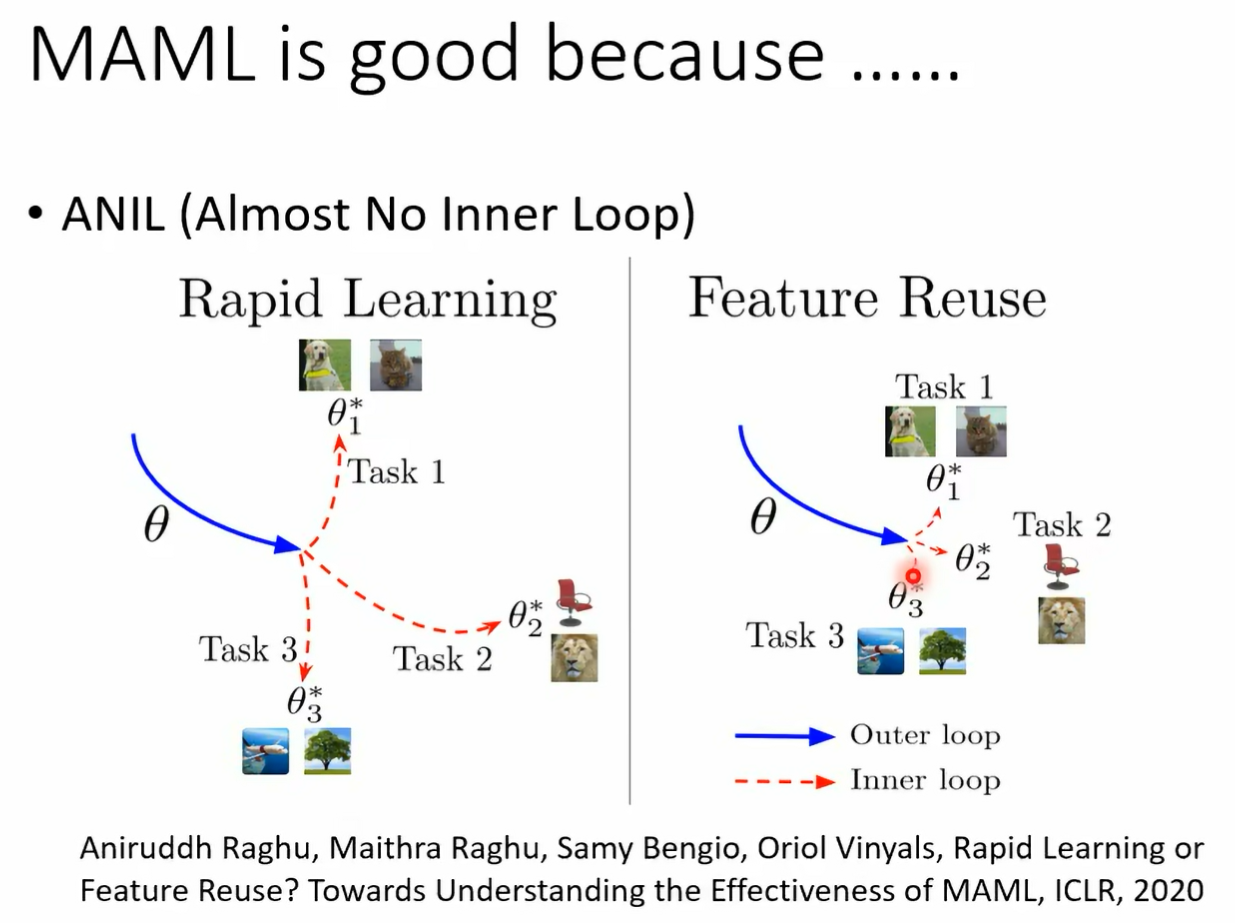
在我们的作业里面也会问大家一些跟 neo 相关的问题 a new 是 almost no in the loop 的缩写 almost no inner loop 啊 缩写是 annie 好的 may helen 你有非常多的变形了 假设你想要知道更多背后的数学的细节的话 你可以参考这支影片 那甲那 memo 有一个可以减大幅简化运算的变形 叫做 first order memo memo 大家可以看这支影片啊 如果你想知道什么是 rap tile 的话 你可以看这支影片啊 我们上课就不再讲 我们把这些呃内容留在这个作业的选择题里面 我们可以学 optimizer 你知道在 update 参数的时候 我们需要决定比如说 learning r momentum 呢等等参数等等 hyperparameter 而像 learning rate 这种 hyperparameter 是可以的 那像这样子的想法在很早以前就有了 nips 2016 就有一篇 paper 他的 title 叫 learning to learn by gradient descent by gradient descent 哦 这个不是 table 啊 它的名字真的就叫做 learning to learn by gradient descent by gradient descent 这个大家都是命名大师啊 大家都很会取这个有梗的 title 而在这篇 paper 里面呢 他就直接认了那个 optimizer 一般我们的 optimizer 什么 add a proper 是人想出来的 它的 after miser 它里面的参数是自动根据训练的任务学出来的 那他那边他把他的方法呢就直接叫做 l s t n 了 因为他把训训练那个和呃这个 optimizer 里面的这些参数
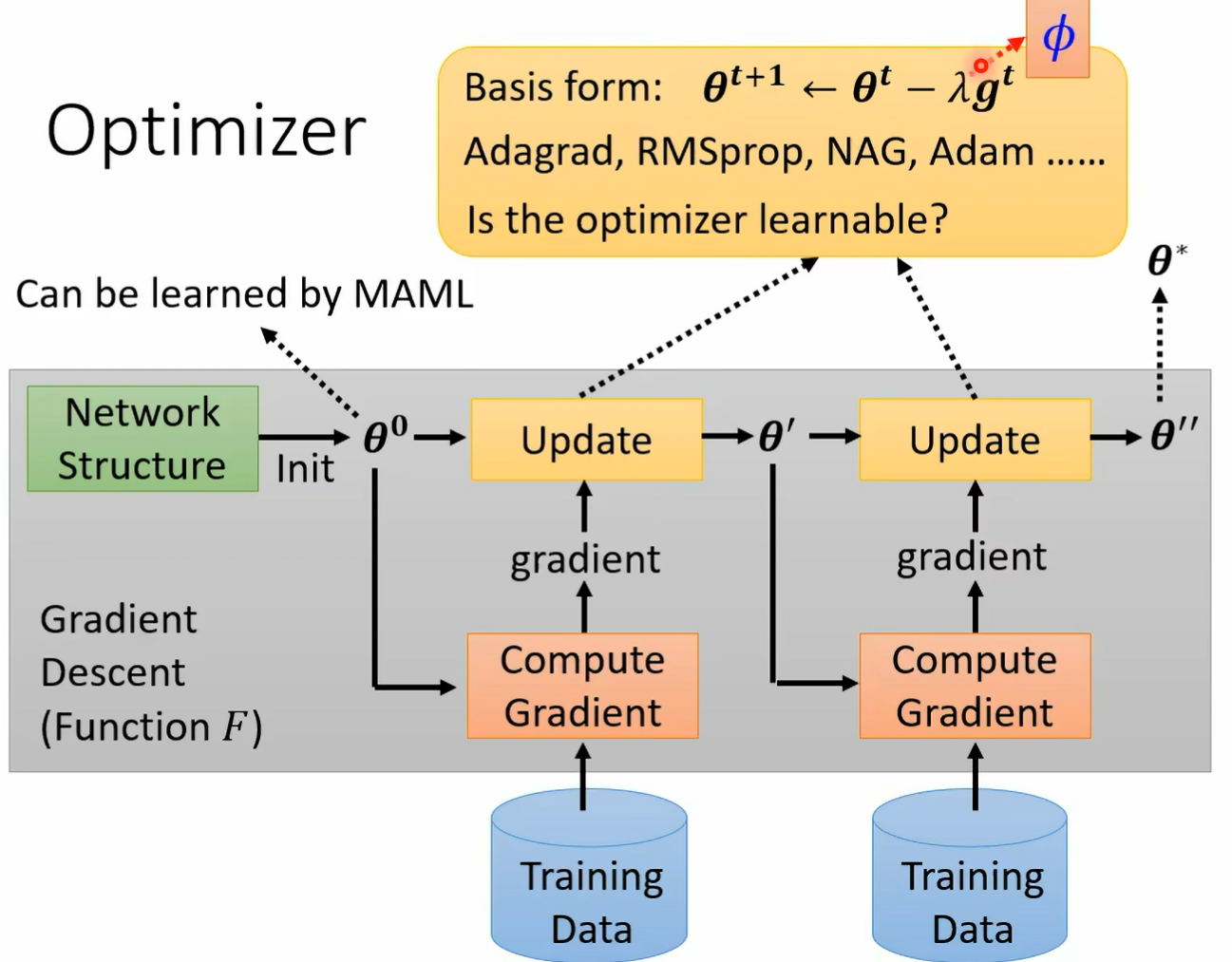
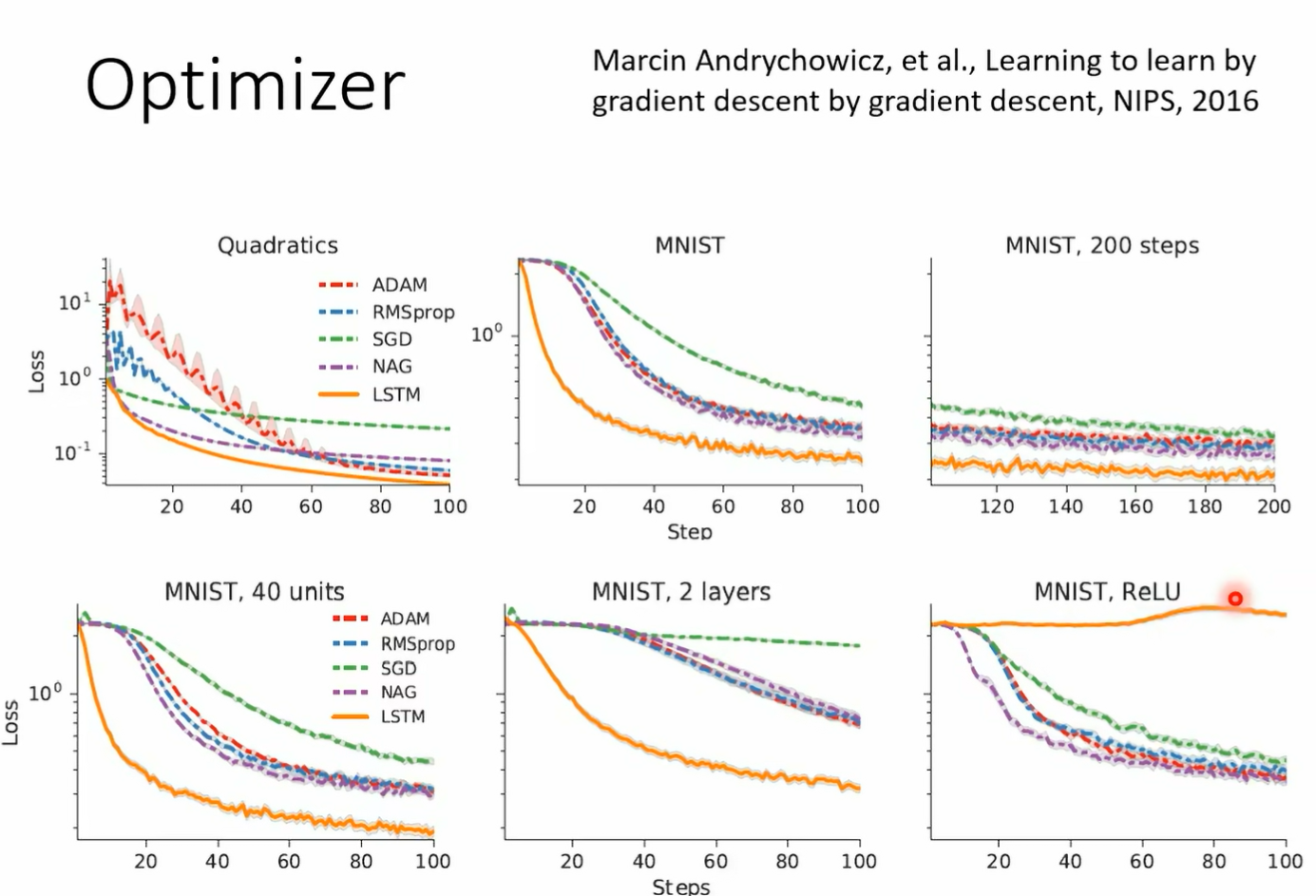
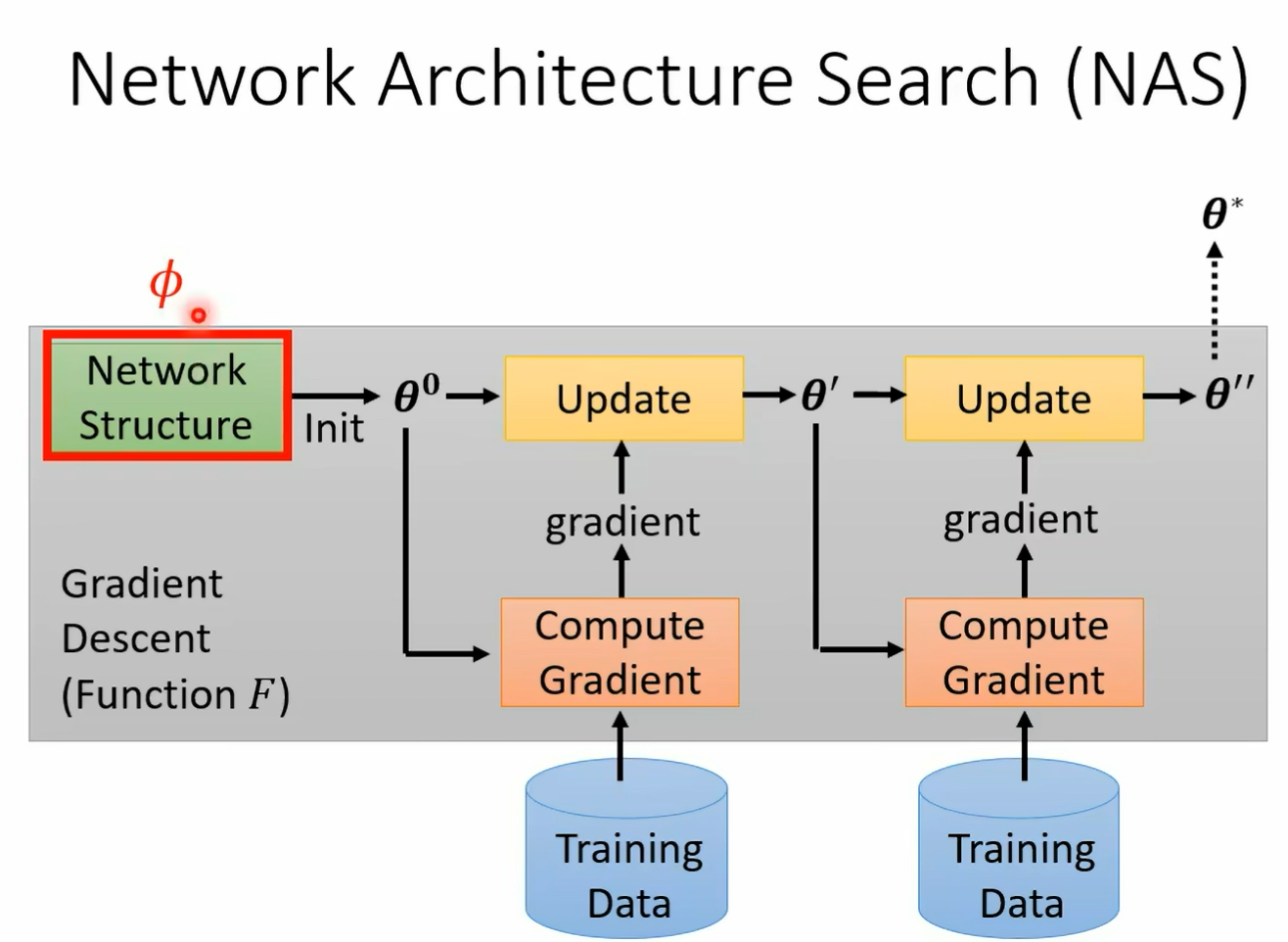
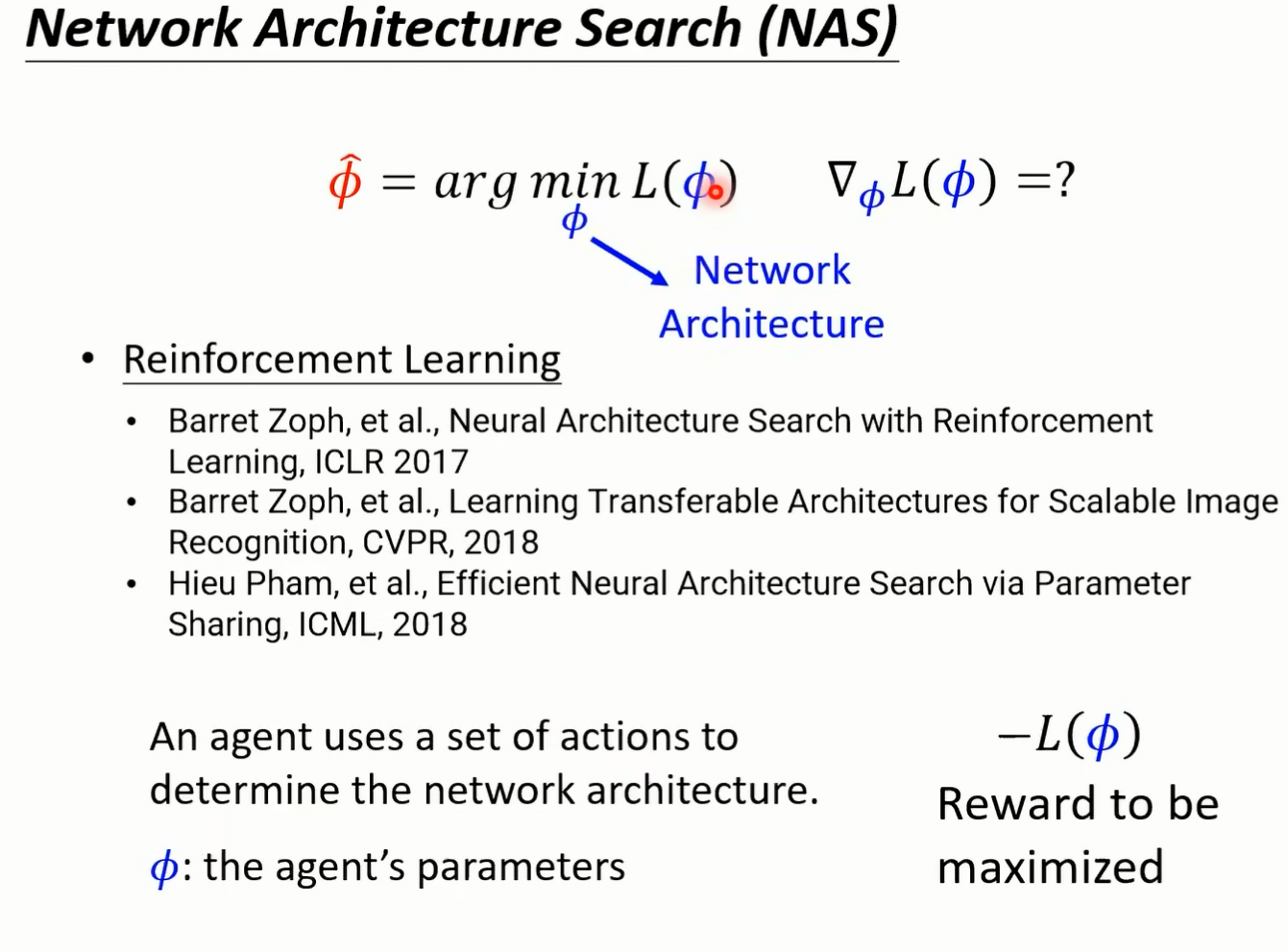
这件事情把它类比 要训练一个 l s t n 上 但我们这堂课里面没有讲过 l s d n 嘛 所以你不知道 l s t n 是什么 没关系 反正这个就是认出来的 optimization 那他做的第一组实验是训练在 n nest 上 然后直接测试在 n nest 上了 那所以得到的结果呢当然是挺不错的 橙色这一个是认出来的 timon 其他颜色的这个客服呢是其他的方法 但是如果我们是训练在 n nest 上 测试在 n nest 上 而且 network 架构都一样 这根本就是 cheating 嘛 这样没有什么特别厉害 但是早在 2016 年 试试看 然后呢诶结果不错 但测试任务呢测试任务改成两层 看看到底能不能够做得起来 它测试的时候测试在两层的内幕上可不可以做的起来可以 但他发现说呢改一下那个 activation function 就不 work 了 训练的时候如果没记错的话 应该是用 smo 但是测试的时候 network 架构里面改成 ru 哇 这个能认出来的 optimization 就坏掉了哦 好刚才讲了 我们可以训练初始化的参数 可以训练 optimizer 那能不能够训练 network 架构呢 当然可以训练 network 架构 那在训练 network 架构这系列的研究呢 就叫做 network 其实就是鼎鼎大名的 network architecture search 其实就是 early as 其实我知道很多同学应该都听过 network architecture search 这个记住只是你不太清楚他跟 made up learning 的关系是什么而已 如果你今天在 meta learning 里面
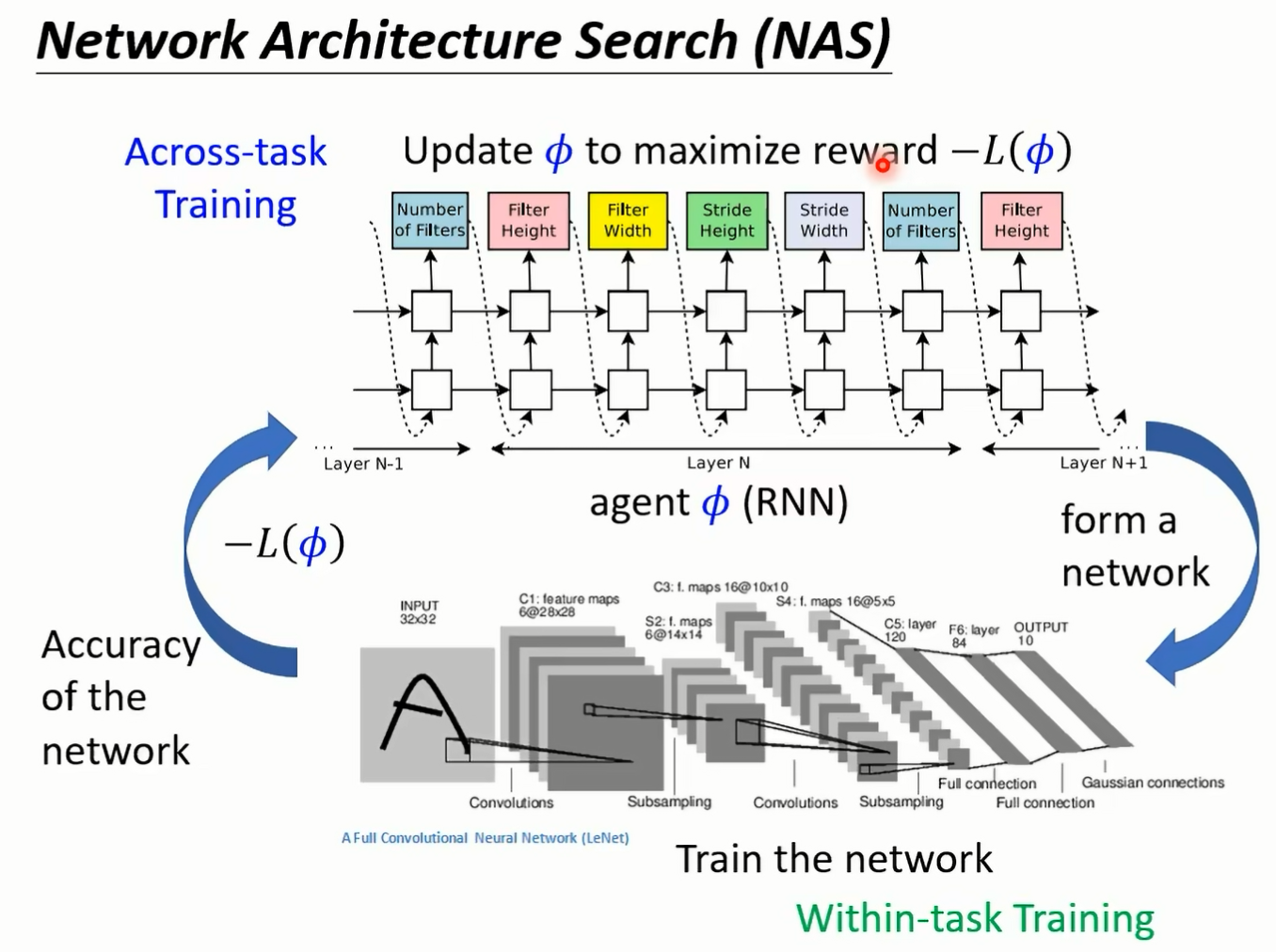
你认的就是 network 的架构翻译 你把 network 的架构当做翻译的话 那我们就是在做 n a s 好 但是在 n a s 里面呢 我们的 fire 是 network 架构 我们要找一个 fi 去 minimize l of fine 但既然 phynetwork 架构显然做微分就有问题了 显然算 brain 就有问题了 怎么办 记得我们这门课里面反复强调的 当你遇到 optimization 的问题 没办法上微分的时候 reinforcement learning 运作也许是一个 solution 好 怎么用 reforcement learning 硬做呢 你就把 fi 呢想成是一个 agent 的参数 然后这个 agent 呢 这个 reinforcement learning 里面的 agent 呢 它的 output 是什么 它的 output 就是 network 架构相关的 hyperparameter 举例来说它会 output 的 就是现在第一层 你到比如说 filter 它的长是多少 它的宽是多少 它的 strike 多少 filter 的数目是多少等等 今天你的 a 卷它的 output 就是 network 的架构相关的参数 然后接下来呢你就要训练你的 agent 让他去 maximize 一个 reward 那在这边我们的 reward 是什么呢 所以我们训练这个 a 卷去 maximize l to find a 乘上负号 就等于是 minimize l of f 我们用 i 的演算法直接去训练这个 fi 去 meml 到 five 那我们就是做了 network architecture search 好 那这边是有一个从文献上截下来的图 希望可以让你更清楚知道说这个 typical 的 n a s 是在做什么的啊 就是我们有一个 agent 那这个是比较早的 work 了 所以那个时候呢把 agent 呢想成就是一个 recurrent network
那这个 recurrent network 每次呢会输出一个 network 架构有关的参数 比如说他会先输出 filter 的高是多少 然后再输出 filter 的宽是多少 然后再输出 stride 的呃 横向的 strike 是多少 在输出纵向的 strike 是多少 在输出要多少的 filter 等等 然后第一层第二层输出完了以后 接下来再输出 n 加一层 接下来再输出 n 加二乘 以此类推 好的 有了这些参数以后 就根据这些参数建出一个内建完 neo 以后就去 train 这个 neo 缺一个 train network 的过程呢 其实就是 with ftk 的 training 好 然后接下来呢就去做 reinforcement learning 你可能会把这一个 network 他在测试资料上面的 accuracy 当做你的 reward 然后呢来训练你的 a 卷 那训练这个 agent to maximize reward 的过程其实就是 across task training 那我知道说在 network tea search 文献上其实不常提到什么 within test training 跟 across 全景这样子的讲法了 但是其实你想想看 neta search 它可以视为是没 a learning 的 其中的技术只是我们现在要认的是集中在 那我知道说比较早的 network architecture search 那些 paper 啊 他们往往训练的任务跟测试的任务就是同一个啊 比如说你训练的时候 你是要训练一个 agent 他可以找一个 network 这个 network 在塞发 ten 上做得好 那测试的时候你也是直接跑在三发 ten 上 感觉有点躯体 不过近年来啊 有很多 naval architecture search 的文章都已经进步到都已经呃有所改变 他们的 training 的任务跟测试的任务都已经有人尝试过 可以是不一样的了 好那除了这个 reinforcement learning 以外啊 你要用 evolutionary 的 algorithm 也是可以的啊 我们这边就直接列一些文献给大家参考
那其实啊你硬要把 nearchitecture 改一下 让它变得可以为分也是可以的 有一个经典的做法呢叫做大啊 缩写就是 fal architecture search 这个它是 defi teor sch 缩写 这个大词呢它就是想办法让这个问题变的是可以为分 你就可以直接用 gradient descent 来 minimize 这个 l of fine 那至于大致的细节就留给大家自己慢慢研究好 除了 nearchitecture 以外 还有什么可以认的呢 data processing 也有可能可以认 大家知道说诶我们在训练 network 的时候 你不知道做 data augmentation 吗 作业三还让大家自己尝试各种不同的 data augmentation 的方法 那当然 data augmentation 的方法 现在你是用 trial and error 去试出来的 那能不能够硬去学 data augmentation 这件事呢 能不能够训让我们去训练出怎么自动找 data augmentation 呢 是可以的 那我们就列一些 paper 在这边给大家参考 那我们知道说今天在 training 的时候啊 有时候你会需要给不同的 sample 不同的 weight 但是要怎么给每一笔 data 不同的权重呢 这边就有不同的策略 那有人的策略就是说哎如果有一些 example 距离帮对特别近 它是特别难的 example 也许就要给他比较大的 way 像 network 比较 focus 希望他可以学得比较好 但是你也会看到文献有相反的结论 说诶这个比较 noisy 的这些 label 应该给它比较小的位置 这些 example 如果他比较接近 boundary 可能代表它比较 noisy 代表它比较困难 他的难可能是不合理的 因为代表他 label 好不好 根本就标错了 也许你应该给它比较小的 we
那怎么决定这个 simple weight 的 strategy 呢 你可以用 lt 把 simple weight strategy 直接认出来 然后让我们迅呢根据让我们迅可以学到说诶 根据 data 的特性自动决定说 simple 的 weight 要怎么设计 到目前为止啊 我们看到的这些方法都是基于 gradient descent 再去做改进哦 我们刚才看到的所有方法都是认了 gradient descend 其中的 component 但是我们有没有可能完全舍弃掉 gradient descend 呢 我们有没有可能直接扔一个 network 这个 network 的参数就是 f 这个内部直接是训练资料作为输入 直接输出训练好的结果 如果真的有这样一个 network 它可以吃训练资料作为输入输出训练好的 network 的参数 那我们就可以说我们甚至让机器发明了新的 learning algorithm 我们已经抛弃了 gradient descent 机器发明新的 learning album 有没有可能做到这件事呢 也不是完全没有可能的 已经有一些论文往这个方向进站 而到目前为止啊 我们还是把训练跟测试分成两个阶段 我们的 learning 我们有一个 learning algm 它是拿训练资料进行训练 然后输出训练好的结果 然后把训练好的结果用在测试资料上 看有没有可能更进一步 直接把整个 episode 也就是一次训练加一次测试 这个是有可能的 有一个系列的做法 它就是直接把训练资料跟测试资料当做 network 的 input network 读完训练资料以后 你也不知道里面发生了什么事 也许他就是学出了一个 learning alism 也许他就是找出一组参数 不知道不知道他发生了什么事 他读完训练资料以后再给他测试资料 他直接输出这些测试资料的答案 也就是我们不再有训练跟测试的分界
一个 episode 里面不再分训练跟测试 而是直接用一个 network 把训练跟测试这件事情一次搞定 有没有可能做这样的事呢 其实这样的方法今日并不罕见 有一个系列的 may have learning 的方法叫做 learning to compare 它又叫做 metric base 的方法 这一系列的做法就可以看作是训练和测试没有分界 一个 network 直接把训练资料 测试资料都读进去 而直接输出测试资料的结果 那如果你想学更多跟 learning to compare 有关的东西的话 那其实在过去的上课有讲过 metric base approach 那这边就把过去上课的录音贴在这边给大家参考啊 最后啊也许你会很好奇 说 made a learning 这样的技术真的有应用吗 它真的有被用在任何地方吗 may have learning learn to learn 直接扔一个 album 听起来非常的科幻 他真的有实际的应用吗 今天你在做 meta learning 的时候啊 你最常拿来测试 ma learning 技术的任务叫做 few shot 的 image classification 在 few shot image classification 里面 你每一个任务都只有几张图片哦 你每一个类别每一个 class 都只有几张图片啊 比如说你现在分类的任务是有三个 class 进来一张 image 你要把它分成三个类别 每一个类别你都只有两张图片 每个类别你都只有两张图片 你希望透过这样一点点的资料就可以训练出一个模型 给他一张新的图片 他可以知道这张图片属于哪一个类别 那在做这种 few shot classification 的时候啊 最常见的一种 classification 的呃 你常常会看到一个名词叫做 n vk 下的 classification 那 n vk 下的 classification 是什么意思呢 n vk shop 的 classification 它的意思就是在每一个任务里面 我们有 n 个 class 而每一个 class 我们只有 k 个 example
举例来说 在上面这个例子里面 我们有三个 class 每一个 class 只有两个 example 那它就是 three way to shot 的 classification 好那在 meta learning 里面呢 如果我们今天要教 machine 能够做 n vk shot classification 那意味着说我们需要准备很多的 n vk 下的 classification 的 task 当做训练的任务 将马逊才能够学到 n vk 下的人民 album 那要怎么去找一堆 n v k 下的任务呢 要怎么去找一堆 n v k 下的全年的 task 那在文献上最常见的一种做法是使用 obliga 这个 cpus 当做 benchmarcus 你知道这个 omega 是这就好像说你今天在做生物实验的时候 你都用果蝇来做生物实验嘛 那在 made a learning 里面 如果你想要做快速做相关实验的话 最常做的选择就是使用 ea 在 onea 这个 cos 里面呢有 1623 个不同的 那每一个 character 呢有 20 个 example 啊 比如说这是某个 character 它就是勾起来 然后点两点 那像这个 character 它就有 20 个不同的 example 啊 就是找 20 个人 每个人呢都去写一遍这个 character 然后把他资料收集起来啊 所以每一个 character 有 20 个 example 总共 1623 个 character 那有这些 character 以后呢 你就可以去制造 n vk 下的 classification 举例来说 假设你要制造一个 twenty 位 one 下的 confication 任务的话 那你要怎么做呢 你就从那个 onega 里面呢选出 20 个 character 然后每一个 character 就只取一个 example 那你就得到一个 20 位 one shot 的 classification 的任务 好像这边这个样子好 这边呢每一个呃图片就代表某一个 character 每一个 character 这边只有一个 example
而每一个 character 在 n vk 下的任务里面就代表了一个 plus 哦 所以 20 位弯下的 classification 的任务 他的训练资料也就是 ort 就长这个样子 那测试资料呢测试资料就是你从这 20 个 character 里面 再去 onea data set 里面找某一个 example 出来 然后接下来就问你说诶这个 casting 的 example 这一个 query set 它是这 20 个 class 里面的哪一个啊 那这个东西到底是哪一个 class 呢 这个看起来有点像是豌豆射手了 其实人呐在做这种 future classification 是非常厉害的 所以这种 future fication 可以难倒机器 但往往难不倒人 像这个它是属于哪一个 class 呢 它是属于哪一个 character 呢 我相信你一眼就可以看出他应该是这个 character 了 好那在使用 onega 的时候呢 一半呢是拿来制造 training task character 另外一半是拿来制造 testing task character 然后这些 training character 啊 如果你要去制造一个 n vk 下的任务 你就是从这些 training the character 里面先随机 sample n 个 character 然后这 n 个 character 每个 character 再去 simple 开个 example 集合起来 你就得到一个训练的任务 那测试的任务呢 你就从这些测试的 character 里面拿出 n 个 character 然后每个 character simple 开个 example 那你就得到一个 n 位 k 下的测试任务 然后测试在测试任务上好 那你可能会问说这个更为开下的任务做在欧尼 ga 上面 这个有什么用呢 这个就是没有什么用了 但是 meta learning 不是只能用在 onea 上面 我这边呢这个 table 上面是列举了 meta learning 在语音还有自然语言处理上的应用 那这边的纵轴啊是不同 meta learning 的方法有 learning to initialize learning to compare 还有其他类型的 meta learning
的方法 比如说 network exture search 等等 而横轴啊就是不同的应用 比如说 some event detection he was buttt classification of voice conversion 呢 sequence machine tration speak regnition 等等 像这些语音 还有 nlp 相关的任务 都已经有人尝试在上面使用 meta learning 所以 meta learning 不是只能用非常简单的任务 今天在学界已经开始把 made a learning 推向更复杂的任务 看看未来 made a learning 这个技术能不能够真的用在现实的应用上 它可以走得多远好 那这个就是本学期想要跟大家分享的内容了
# 学习内容
马尔科夫决策过程:https://www.bilibili.com/video/BV1wb4y1C7LG/?spm_id_from=333.337.search-card.all.click&vd_source=1c562831fab1cb4101e5b95d41c170e0
# 参考视频
李宏毅:https://www.bilibili.com/video/BV11E411G7V9/?spm_id_from=333.880.my_history.page.click&vd_source=1c562831fab1cb4101e5b95d41c170e0
较能清除的解释的:https://www.bilibili.com/video/BV11E411G7V9/?spm_id_from=333.880.my_history.page.click&vd_source=1c562831fab1cb4101e5b95d41c170e0
马尔科夫链:https://zhuanlan.zhihu.com/p/448575579
在 maml 中使用马尔科夫链是指在求不同任务的概率时么?
x1 表示的是一个 task,还是一条数据?应该是一条数据,
hessian 矩阵:
# 阅读笔记

