# XPath 路径表达式
# 节点的基本类型
XPath 是一门在 XML 文档中查找信息的语言,虽然是被设计用来搜寻 XML 文档的,但是它也能应用于 HTML 文档,并且大部分浏览器也支持通过 XPath 来查询节点。在 Python 爬虫开发中,经常使用 XPath 查找提取网页中的信息,因此 XPath 非常重要。
在 XPath 中,XML 文档是被作为节点树来对待的,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档 (根) 节点。树的根被称为文档节点或者根节点。以下面的 XML 文档为例进行说明:
<?xml version="1.0" encoding="UTF-8"?> | |
<bookstore> | |
<book> | |
<title lang="eng" class="good">Harry Potter</title> | |
<price>29.99</price> | |
</book> | |
<book> | |
<title lang="eng">Learning XML</title> | |
<price>39.95</price> | |
</book> | |
</bookstore> |
- 根节点(Root Node)
根节点是一棵树的最顶层,根节点是唯一的。树上其它所有元素节点都是它的子节点或后代节点。对根节点的处理机制与其它节点相同。对树的匹配总是先从根节点开始。文档中的 <bookstore> 即为根节点。
- 元素节点(Element Nodes)
元素节点相对应的是文档中每个元素(即标签),一个元素节点的子节点可以为元素节点、注释节点、处理指令节点和文本节点。元素节点可以定义一个唯一的标识 (id)。元素节点可以有拓展名,由两部分组成:命名空间 URL 和本地命名。文档中的 <book> 即为元素节点。
- 文本节点(Text Nodes)
文本节点包含一组字符数据,任何一个文本节点都没有相邻的兄弟文本节点,而且文本节点没有扩展名。文档中的 Learning XML 即为文本节点。
- 属性节点(Attribute Nodes)
每个元素节点有一个相关联的属性节点集合,元素是每个属性节点的父节点,但属性节点却不是其父元素的子节点。这就是说,通过查找元素的子节点可以匹配出元素的属性节点,但反过来不成立,只是单向的。再有,元素的属性节点没有共享性,也就是说不同的元素节点不共有同一个属性节点。文档中的 lang="eng" 即为属性节点。
- 命名空间节点(Namespace Nodes)
每个元素节点都有一个相关联的命名空间节点集。在 XML 文档中,命名空间是通过保留属性声明的。因此,在 XPath 中,该类节点与属性节点极为相似,它们与父元素之间的关系是单向的,并且不具有共享性。
- 处理指令节点(Processing Instruction Nodes)
处理指令节点对应于 XML 文档中的每一条处理指令。它也有扩展名,扩展名的本地命名指向处理对象,而命名空间部分为空。
- 注释节点(Comment Nodes)
注释节点对应于文档中的注释。
# Xpath 路径表达式的基本语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是沿着路径 (path) 或者步 (steps) 来选取的。接下来介绍如何选取节点,首先了解一下常用的路径表达式,来进行节点的选取,如下表所示:
| 表达式 | 描述 |
|---|---|
nodename | 选取此节点的所有子节点 |
/ | 从根节点选取 |
// | 选择任意位置的某个节点 |
. | 选取当前节点 |
.. | 选取当前节点的父节点 |
@ | 选取属性 |
根据路径表达式的规则,我们对上文的的 XML 文档进行节点选取,如下表所示。
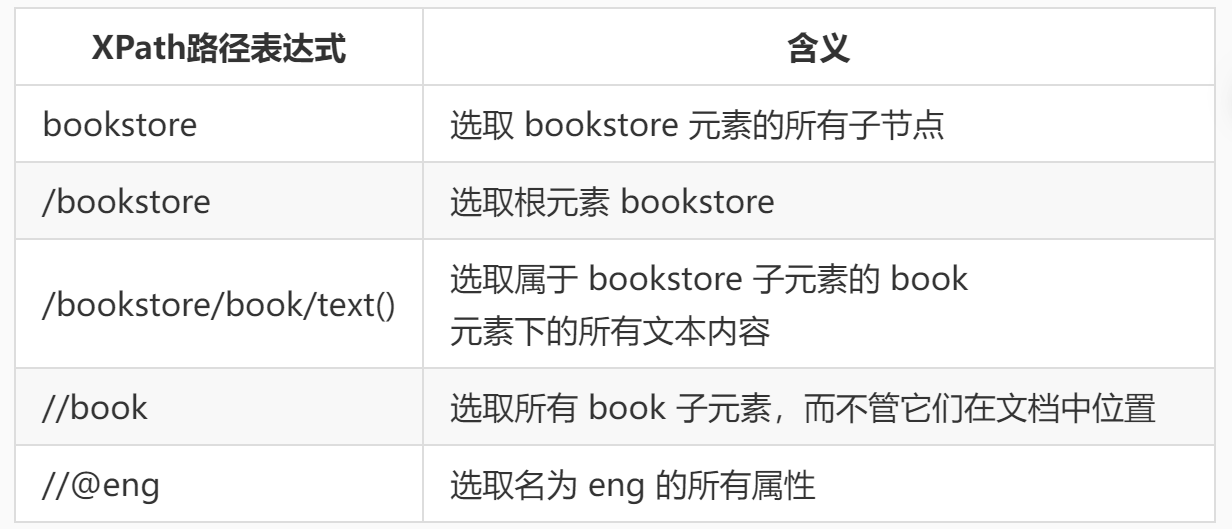
上面选取的例子最后实现的效果都是选取了所有符合条件的节点,是否能选取某个特定的节点或者包含某一个指定的值的节点呢?这就需要用到谓语,谓语被嵌在方括号中,谓语的用法如下表所示。
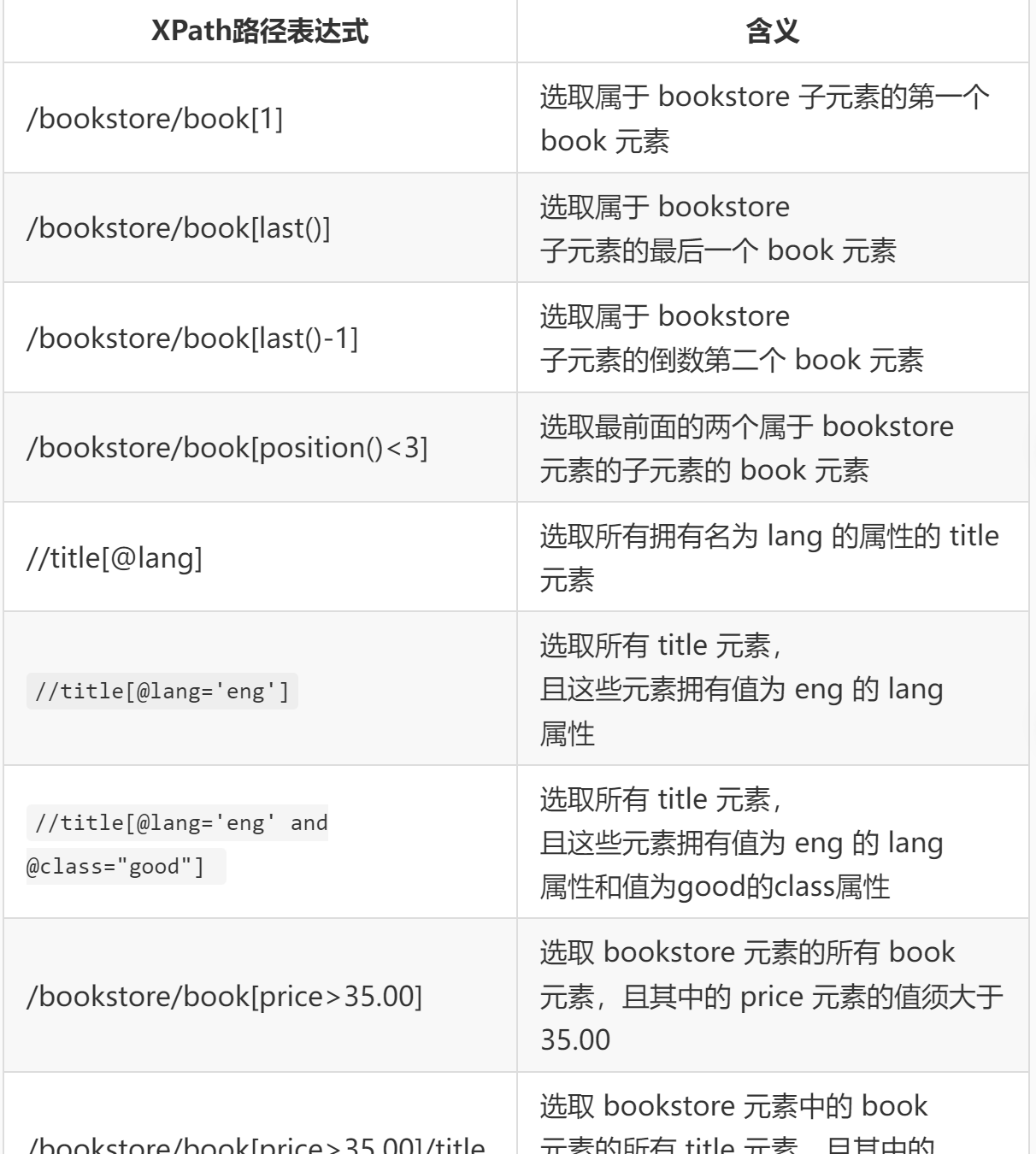
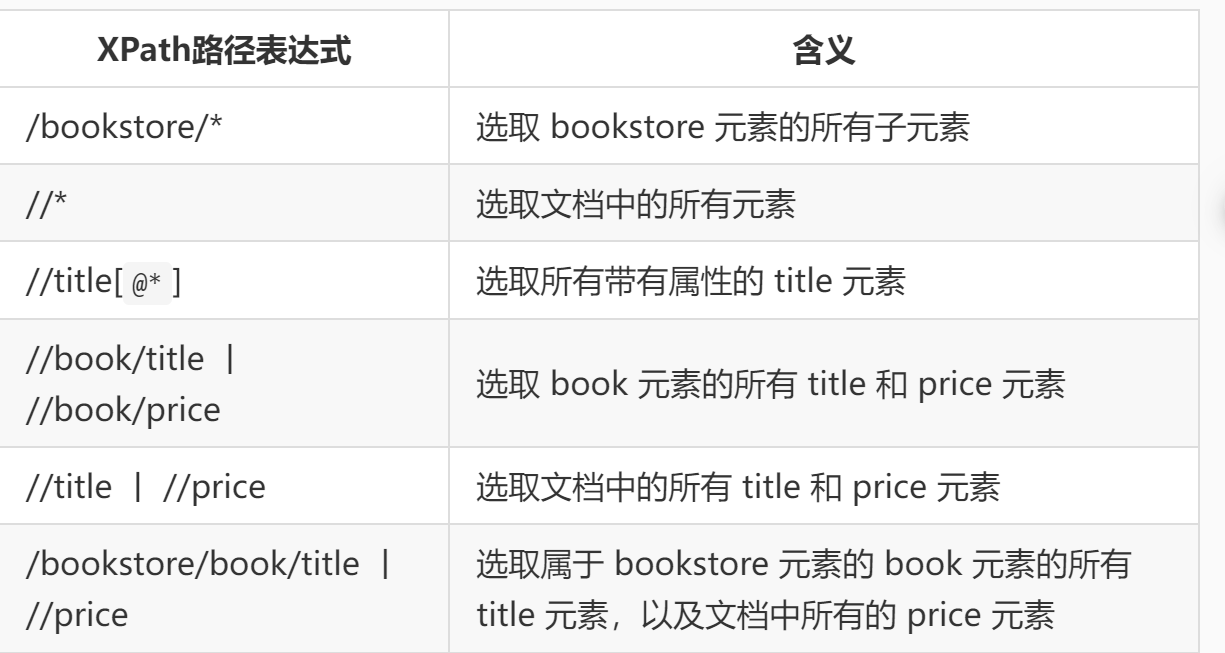
XPath 在进行节点选取的时候可以使用通配符 * 匹配未知的元素,同时使用操作符 | 一次选取多条路径,使用示例如下表所示。
1.选取bookstore元素的所有子节点
********** Begin *********
bookstore
*********** End **********
2.选取所有拥有名为 lang 的属性的 title 元素
********** Begin *********
//title[@lang]
*********** End **********
3.选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性和值为good的class属性
********** Begin *********
//title[@lang='eng' and @class='good']
*********** End **********
4.选取属于 bookstore 子元素的book元素下的所有文本内容
********** Begin *********
/bookstore/book/text()
*********** End **********
5.选取属于 bookstore 子元素的第一个 book 元素
********** Begin *********
/bookstore/book[1]
*********** End **********
# XPath 轴定位
# 轴
在爬虫里面经常要用到定位,XPath 定位有着举足轻重的地位,因为它功能很强大。结合它里面的文本定位、模糊定位、逻辑定位等,基本能搞定所有的元素定位问题。
轴定义了所选节点与当前节点之间的树关系。在 Python 爬虫开发中,提取网页中的信息时,会遇到这种情况:首先提取到一个节点的信息,然后想在在这个节点的基础上提取它的子节点或者父节点,这时候就会用到轴的概念。轴的存在会使提取变得更加灵活和准确。
位置路径可以是绝对的,也可以是相对的。绝对路径起始于正斜杠 / ,而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割: /step/step/.. (绝对位置路径), step/step/.. (相对位置路径)。
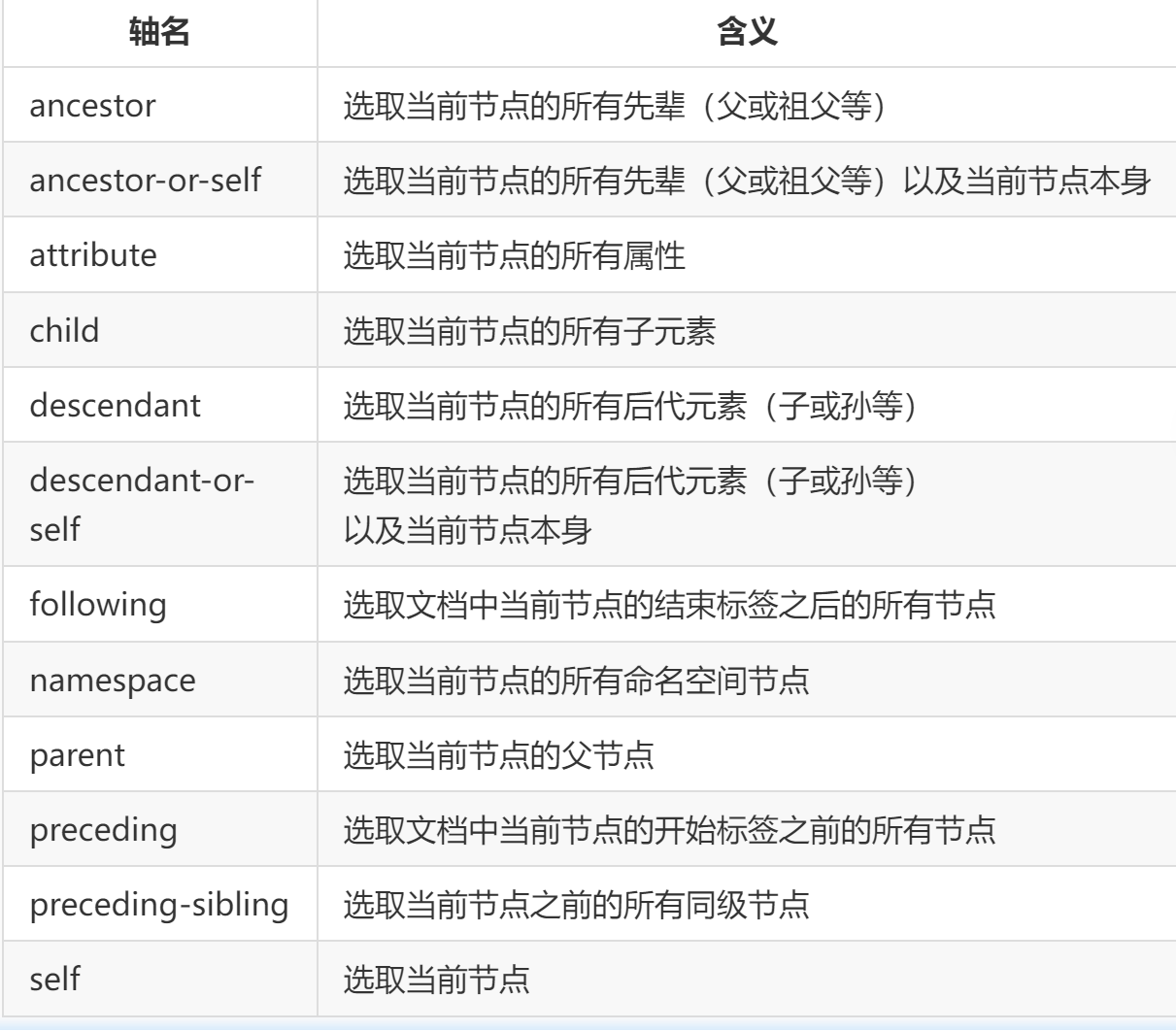
步 (step) 包括:轴 (axis)、节点测试 ( node-test)、零个或者更多谓语 ( predicate),用来更深入地提炼所选的节点集。XPath 中的轴名及含义如下表所示:
# 轴的使用
轴需要通过步的语法,来实现节点的选取。步的语法为: 轴名称::节点测试[谓语]
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng" class="good">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
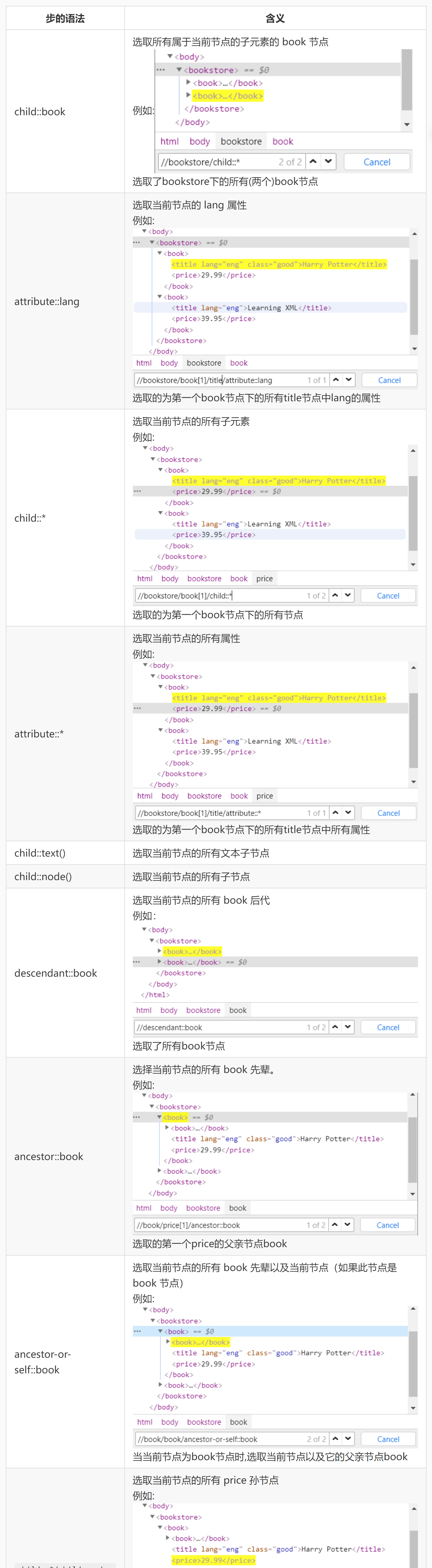
1.选取所有属于当前节点的子元素的 book 节点
********** Begin *********
child::book
*********** End **********
2.选取当前节点的 lang 属性
********** Begin *********
attribute::lang
*********** End **********
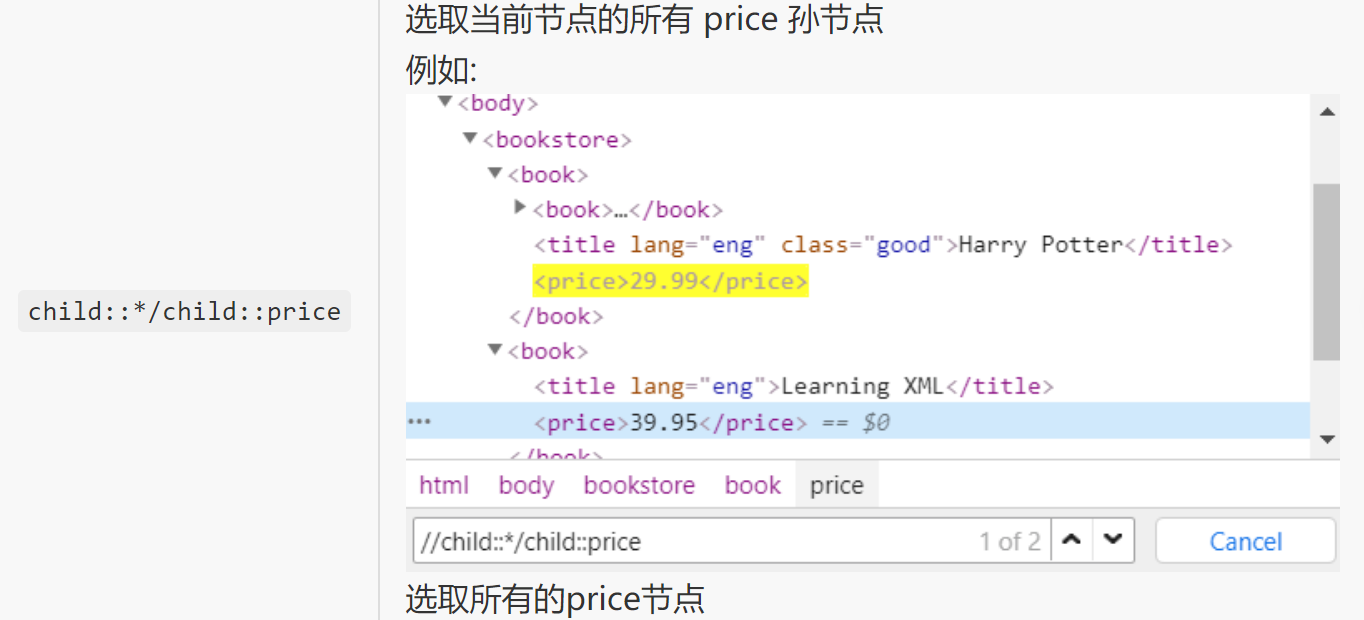
3.选取当前节点的所有 price 孙节点
********** Begin *********
child::*/child::price
*********** End **********
# XPath 解析
# lxml 的安装
lxml 是 一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 数据。lxml 和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的 XPath 语法,来快速地定位特定元素以及节点信息。
如果本地 Python 环境没有安装 lxml,可以在命令提示符窗口输入命令 pip install lxml ,安装 lxml 模块,
# lxml 的使用
使用 lxml,需要先导入相关包,语法如下:
from lxml import etree
现在有如下 HTML 代码,需要获取第一个 book 节点下的 title 节点中的 class 的属性值:
<html> | |
<head></head> | |
<body> | |
<bookstore> | |
<book> | |
<title lang="eng" class="good">Harry Potter</title> | |
<price>29.99</price> | |
</book> | |
<book> | |
<title lang="eng">Learning XML</title> | |
<price>39.95</price> | |
</book> | |
</bookstore> | |
</body> | |
</html> |
使用 xpath 表达式解析网页之前,需要获取元素树对象,这里有两种方法:
- 如果上述代码为本地文件,并且文件名为
test.html,获取元素树对象的代码如下所示:
parse = etree.HTMLParser(encoding='utf-8') # 添加编码
tree = etree.parse('test.html', parse) # 指定本地HTML文件读取
- 如果上述代码为字符串类型变量,并且变量名为 html,获取元素树对象的代码如下所示:
parse = etree.HTMLParser(encoding='utf-8') # 添加编码
tree = etree.HTML(html, parse) # html为python字符串
获取元素树对象后,就可以使用 XPath 表达式解析网页了,代码如下所示:
result = tree.xpath(xpath表达式) # 返回类型为列表
以下演示了四种不同的 XPath 表达式,都能够获取第一个 book 节点下的 title 节点中的 class 的属性值。
# 相对路径 book 节点选择
print(tree.xpath('//book[1]/title/@class')[0])
# 相对路径 title 节点存在 class 属性条件选择
print(tree.xpath('//title[@class]/@class')[0])
# 同上, 但是使用了轴选择 class 属性值
print(tree.xpath('//title[@class]/attribute::class')[0])
# 绝对路径常规选择
print(tree.xpath('/html/body/bookstore//book[1]/title/@class')[0])
# 导入lxml库
from lxml import etree
# 读取lll.html文件并转化为元素树对象
parse = etree.HTMLParser(encoding='utf-8')
tree = etree.parse('src/step3/lll.html', parse)
# 补充xpath表达式,获取所有书的名称
# ********** Begin ********* #
print(tree.xpath('//bookstore/book/title/text()'))
# *********** End ********** #
# 补充xpath表达式,获取所有书的价格
# ********** Begin ********* #
print(tree.xpath('//bookstore/book/price/text()'))
# *********** End ********** #
# 填写代码, 获取价格低于30的书名
# ********** Begin ********* #
print(tree.xpath('//bookstore/book[price < 30.00]/title/text()')[0])
# *********** End ********** #