x = torch.ones(2, 2, requires_grad=True) | |
y = torch.ones(2, 2) | |
x.requires_grad #True | |
y.requires_grad #False |
只有在建立张量的时候设置了 requires_grad=True ,才会追踪梯度
# 报错
# 1.Autograd:自动求导
https://blog.csdn.net/qq_39208832/article/details/117415229
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True ,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward() ,来自动计算所有的梯度。这个张量的所有梯度将会自动累加到 .grad 属性.
要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。
为了防止跟踪历史记录 (和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
还有一个类对于 autograd 的实现非常重要: Function 。
Tensor 和 Function 互相连接生成了一个无圈图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个 .grad_fn 属性,该属性引用了创建 Tensor 自身的 Function (除非这个张量是用户手动创建的,即这个张量的 grad_fn 是 None )。
如果需要计算导数,可以在 Tensor 上调用 .backward() 。如果 Tensor 是一个标量 (即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。
# 1.1 grad can be implicitly created only for scalar outputs
根据文档 如果 Tensor 是一个标量 (即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。
所以当:
x = torch.ones(2,requires_grad=True) | |
print(x) | |
z = x + 2 | |
print(z) | |
z.backward() | |
print(x.grad) | |
# 出现 grad can be implicitly created only for scalar outputs | |
# 因为此时的 y 并不是一个标量 (即它包含一个元素的数据) | |
# 意思是只有对标量输出它才会计算梯度,而求一个矩阵对另一矩阵的导数束手无策。 | |
RuntimeError: grad can be implicitly created only for scalar outputs |
即:
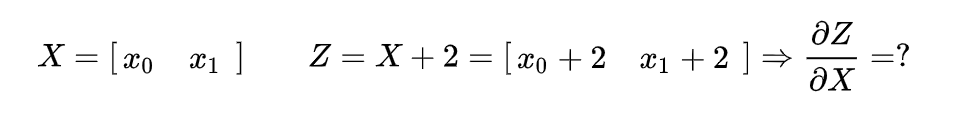
那么我们只要想办法把矩阵转变成一个标量不就好了?比如我们可以对 z 求和,然后用求和得到的标量在对 x 求导,这样不会对结果有影响,例如:
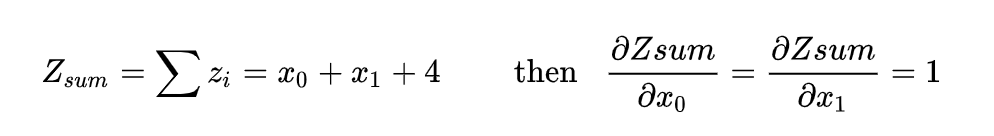
我们可以看到对 z 求和后再计算梯度没有报错,结果也与预期一样:
x = torch.ones(2,requires_grad=True) | |
z = x + 2 | |
z.sum().backward() | |
print(x.grad) | |
>>> tensor([1., 1.]) |
再回到文档但是如果它有更多的元素,则需要指定一个 gradient 参数,该参数是形状匹配的张量。
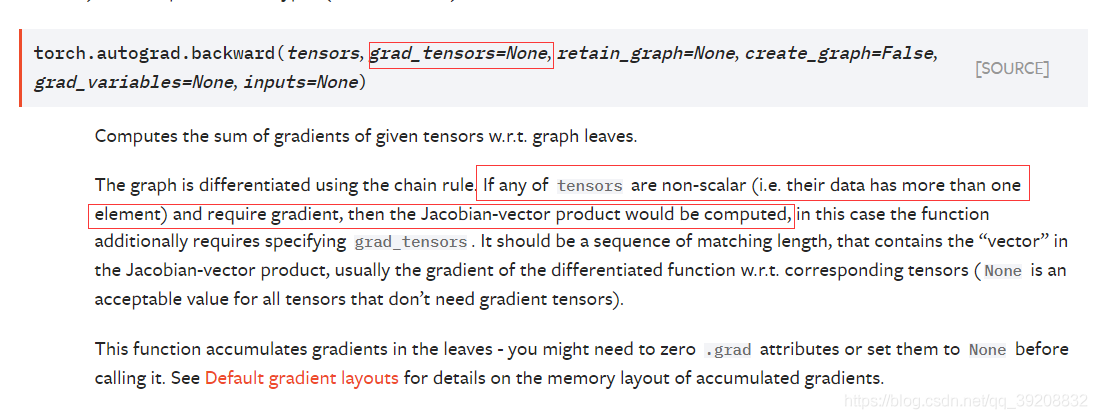
也就是对于矩阵求导来说,需要一个额外的参数矩阵和需要求导的矩阵做点乘。 一般点乘的矩为全 1 的对应形状的矩阵。 也就是乘以全 1 的矩阵,等价于 sum ().
参考
Pytorch autograd, backward 详解
也就是 比如
x = torch.tensor([2., 1.], requires_grad=True) | |
y = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True) | |
z = torch.mm(x.view(1, 2), y) | |
print(f"z:{z}") | |
z.backward(torch.Tensor([[1., 0]]), retain_graph=True) | |
print(f"x.grad: {x.grad}") | |
print(f"y.grad: {y.grad}") | |
>>> z:tensor([[5., 8.]], grad_fn=<MmBackward>) | |
x.grad: tensor([[1., 3.]]) | |
y.grad: tensor([[2., 0.], | |
[1., 0.]]) |
结果解释如下:
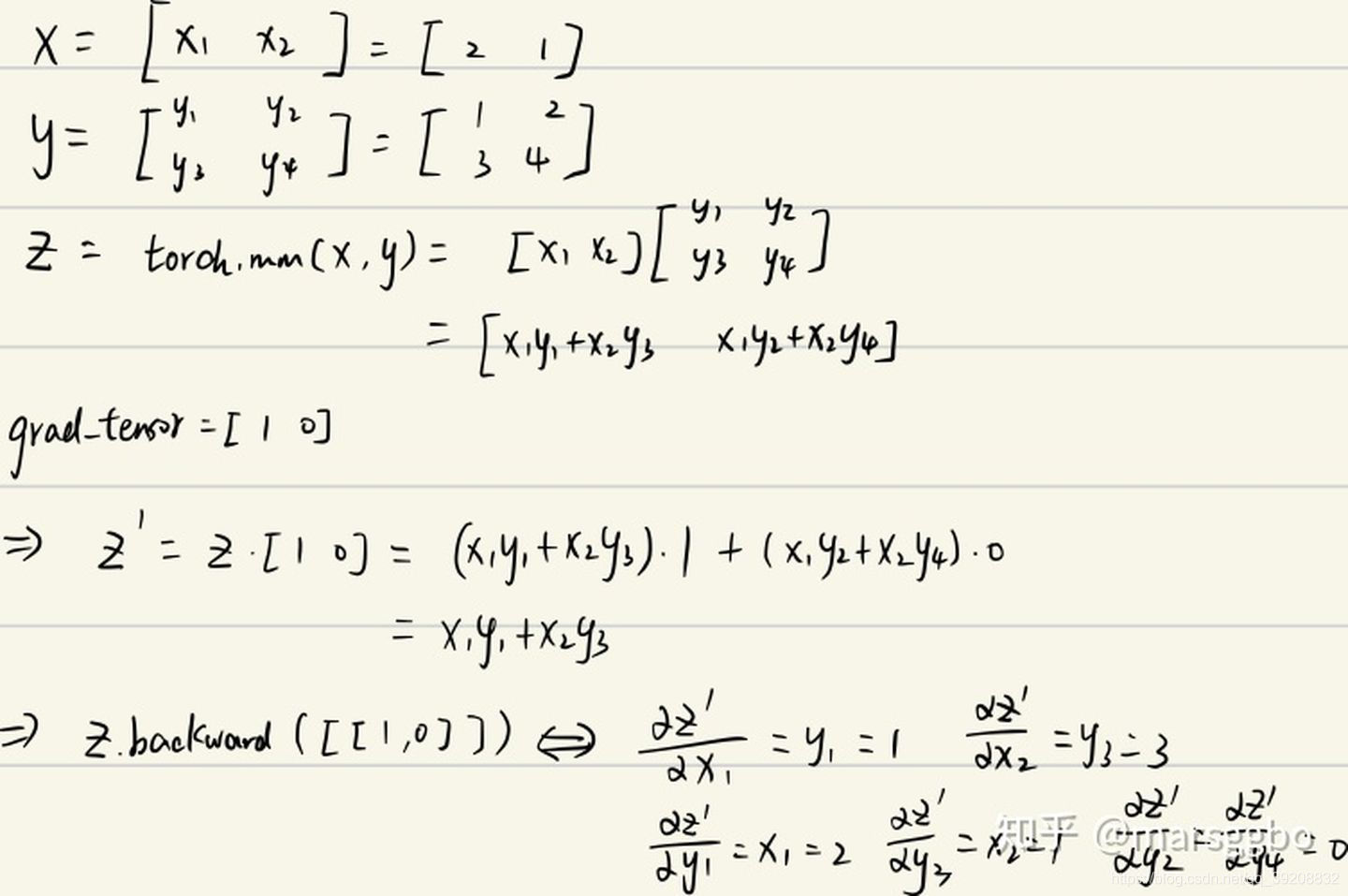
这里并没使用全为 1 的矩阵, 因此 grad_tensors 如果自定义,会产生对应自定义产生的结果。 一般来说都定义为全 1 的矩阵。(可以看作等价与 sum ())
# data.norm()
在 PyTorch 的官方文档中,有这段代码:
x = torch.randn(3, requires_grad=True) | |
print(x) | |
y = x * 2 | |
while y.data.norm() < 1000: | |
y = y * 2 | |
print(y) |
如图: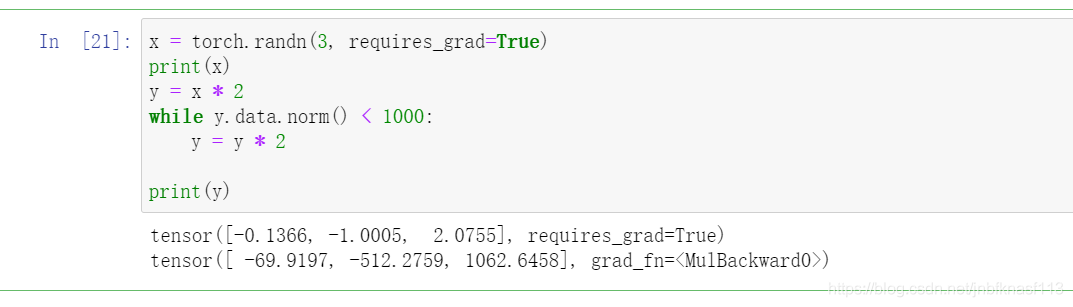
其中
y.data.norm() |
不明白它到底是计算了什么。所以我进行了以下测试。
首先,它对张量 y 每个元素进行平方,然后对它们求和,最后取平方根。 这些操作计算就是所谓的 L2 或欧几里德范数 。
#
https://blog.csdn.net/m0_51499154/article/details/120365329
在 PyTorch 中神经网络一节中有:
import torch | |
import torch.nn as nn | |
import torch.nn.functional as F | |
class Net(nn.Module): | |
def __init__(self): | |
super(Net, self).__init__() | |
# 1 input image channel, 6 output channels, 5x5 square convolution | |
# kernel | |
self.conv1 = nn.Conv2d(1, 6, 5) | |
self.conv2 = nn.Conv2d(6, 16, 5) | |
# an affine operation: y = Wx + b | |
self.fc1 = nn.Linear(16 * 5 * 5, 120) | |
self.fc2 = nn.Linear(120, 84) | |
self.fc3 = nn.Linear(84, 10) |
中 self.fc1 = nn.Linear (16 * 5 * 5, 120),因为 1655 恰好与卷积核的参数数目相等,故很容易被误解为参数数目,其实这里代表的是输入,至于为什么是 1655,我们看该章节中给出的例子:
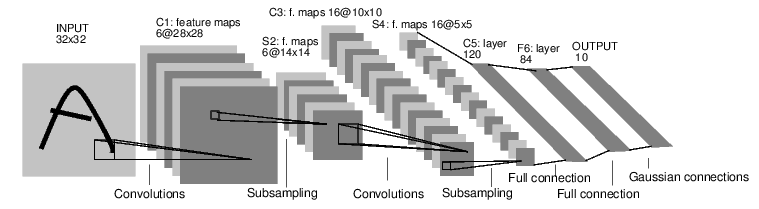
在给出的例子中,一开始的 input 是 32*32,经过两次卷积池化之后的大小就是 16(卷积核)5(宽)5(高),然后再把它通过 view 后。全部输入到第一个全连接层的时候,input 大小就是 1655。
PS: 如若文中有理解有误,欢迎大家批评指正。