# 安装
pip install selenium |
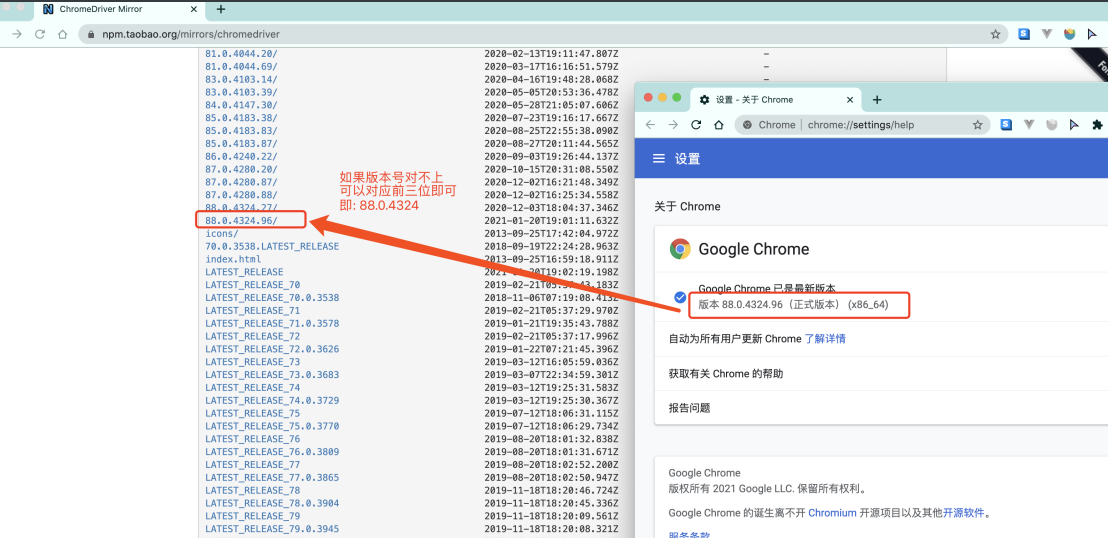
Chrome 驱动地址
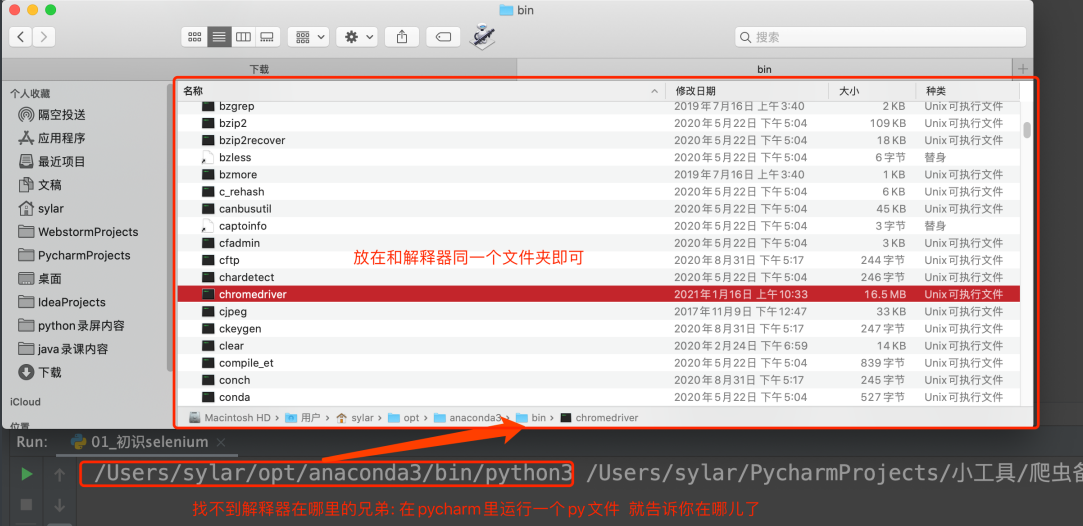
把你下载的浏览器驱动放在程序所在的⽂件夹。或者放到 python 解释器所在的⽂件夹。两种⼆选其⼀
# 操作
# 点击
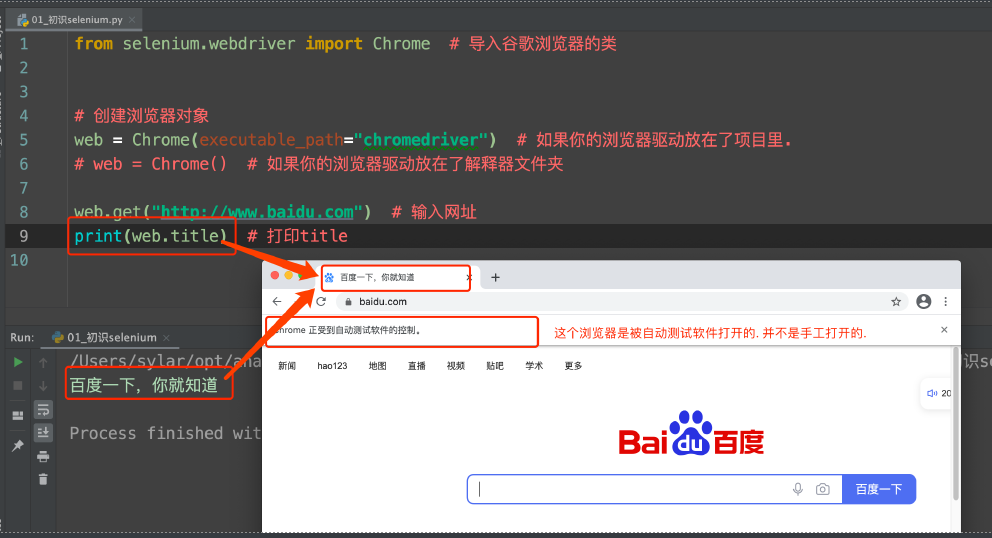
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类 | |
from selenium.webdriver.common.by import By | |
web = Chrome() | |
web.get("http://lagou.com") | |
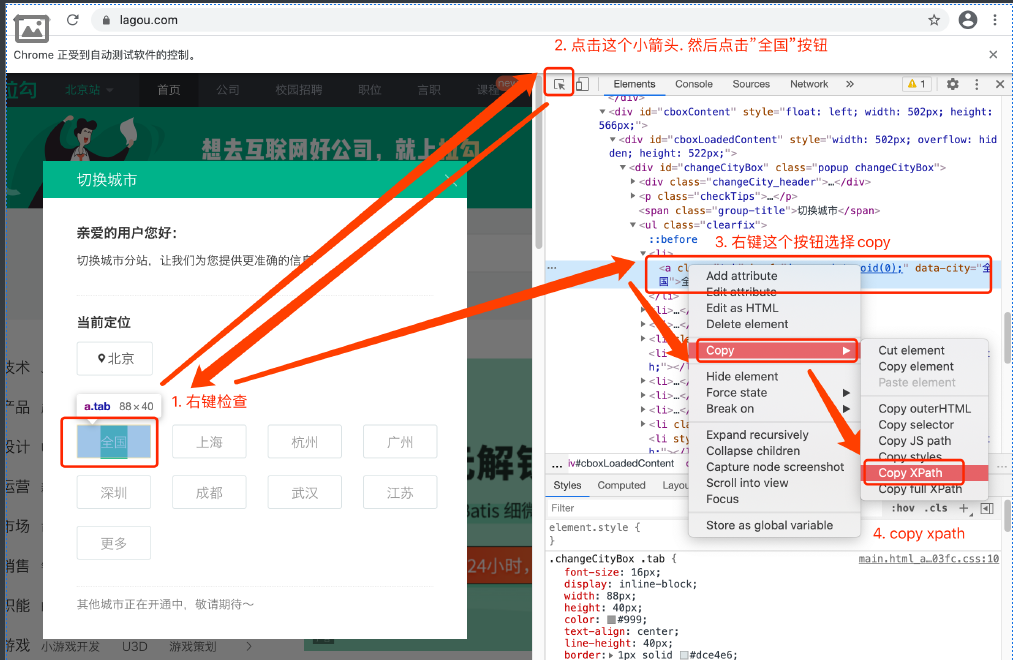
# 找到全国按钮 | |
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
# 点击 | |
btn.click() |
有时上面会出现错误: selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted: Element is not clickable with Selenium and Python ,提示按钮不可点击,此时可以用下面的方式:
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
driver.execute_script("arguments[0].click();", btn) |
# 无头浏览器
在对浏览器对象进行实例化时进行如下修改就行了。
from selenium.webdriver.chrome.options import Options | |
opt = Options() | |
opt.add_argument('--headless') | |
opt.add_argument('--disable-gpu') | |
web = Chrome(options=opt) |
# 搜索
人的过程:找到⽂本框输⼊ "python", 点击 "搜索" 按钮.
机器的过程:找到⽂本框输⼊ "python", 点击 "搜索" 按钮.
selenium 最爽的地⽅就是这⾥。⼈是怎么操作的。机器就怎么操作。爽到极点
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类 | |
from selenium.webdriver.common.by import By | |
web = Chrome() | |
web.get("http://lagou.com") | |
# 找到全国按钮 | |
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
# 点击 | |
btn.click() | |
# 找到文本框,输入 python | |
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("python") | |
# 点击搜索按钮 | |
web.find_element(by=By.XPATH, value='//*[@id="search_button"]').click() |
send_keys() 这⾥要说⼀下。如果我们给出的是⼀个字符串。就是输⼊⽂本。但是,如果给出的是⼀个键盘指令,那就按下键盘。⽐如,我想要按回⻋按钮,则上面的搜索改为
from selenium.webdriver.common.keys import Keys | |
# 找到文本框,输入 python | |
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("python", Keys.ENTER) | |
# 不用再点击搜索按钮了 |
# 获取信息
# 一种错误的方式
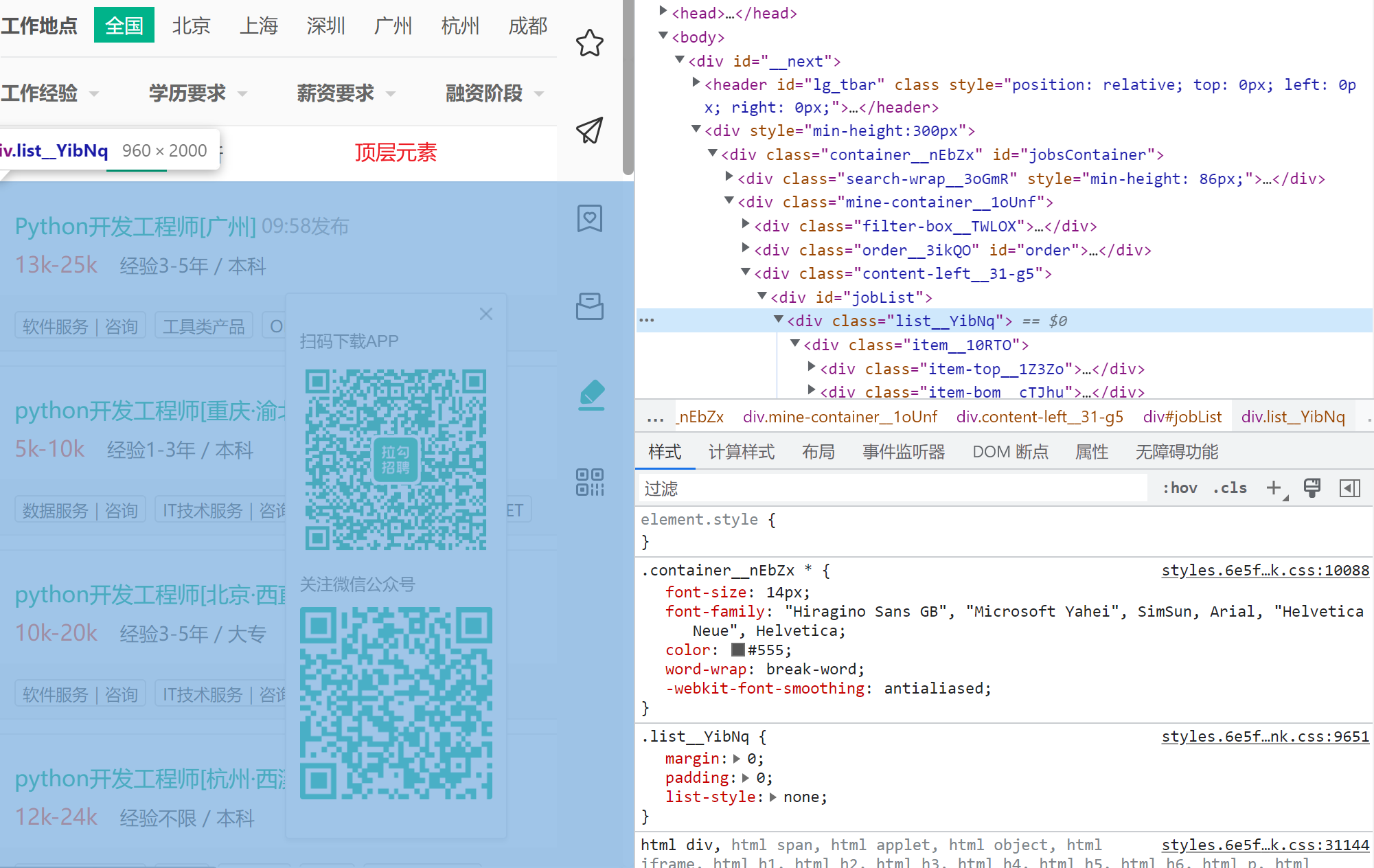
顶层元素,包含的小item的列表
//*[@id="jobList"]/div[1]
每个小item
//*[@id="jobList"]/div[1]/div[1]
//*[@id="jobList"]/div[1]/div[2]
小item中提取信息
职位
//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a
薪资
//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[2]/span
//*[@id="jobList"]/div[1]/div[2]/div[1]/div[1]/div[1]/a
//*[@id="jobList"]/div[1]/div[2]/div[1]/div[1]/div[2]/span
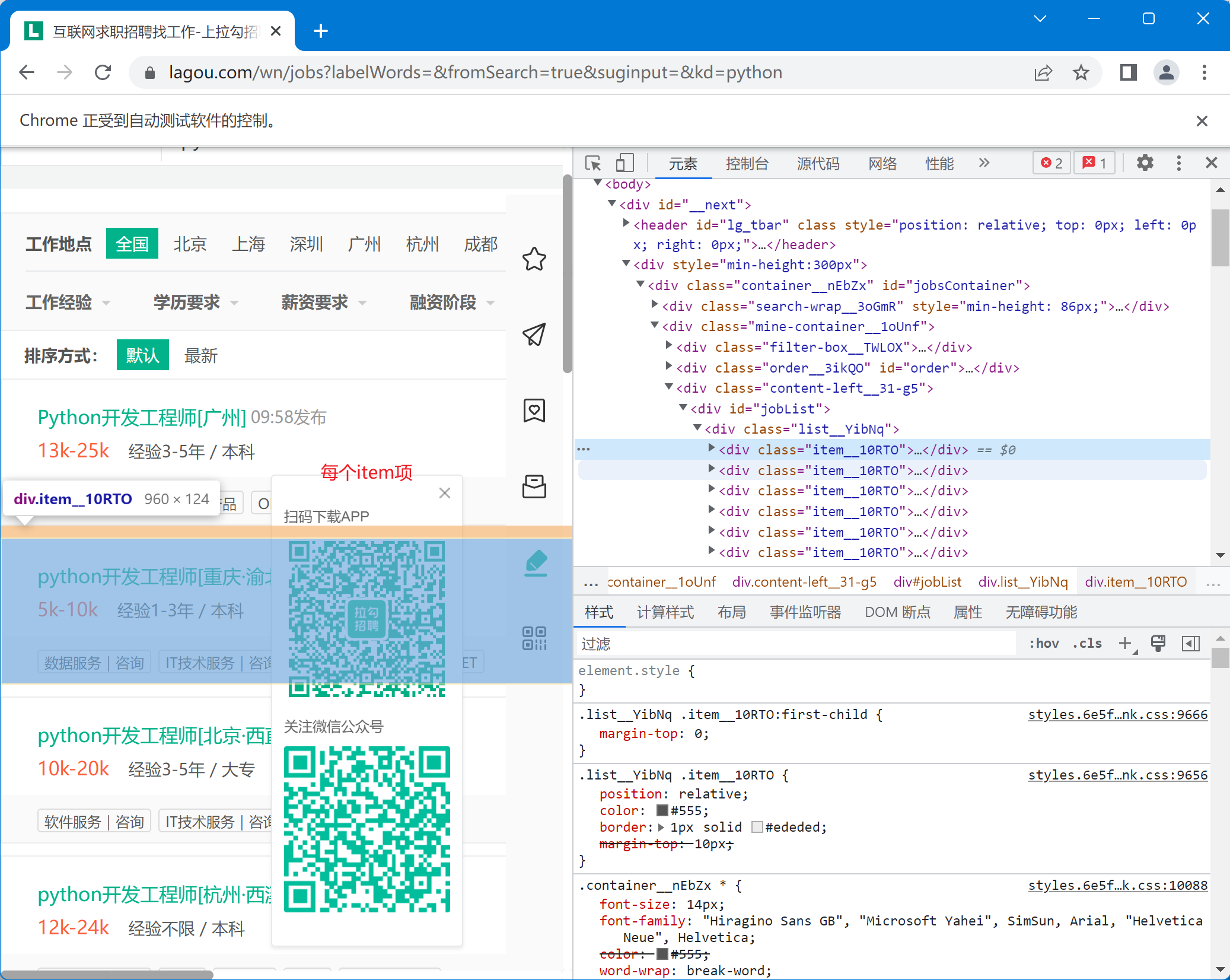
观察它们的 xpath:
顶层元素,包含的小item的列表
//*[@id="jobList"]/div[1]
每个小item
//*[@id="jobList"]/div[1]/div[1]
//*[@id="jobList"]/div[1]/div[2]
ls = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div') |
就能获取到所有 item 组成的列表。
<pre class="vditor-reset" placeholder="" contenteditable="true" spellcheck="false"><p data-block="0"><br class="Apple-interchange-newline"/><img src="https://file+.vscode-resource.vscode-cdn.net/d%3A/Projects/example/source/_posts/tool/ 爬虫 /images/selenium/1662691753092.png" alt="1662691753092"/></p></pre>
item项
//*[@id="jobList"]/div[1]/div[1]
职位
//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a
相对:/div[1]/div[1]/div[1]/a
薪资
//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[2]/span
相对:./div[1]/div[1]/div[2]/span
ls = web.find_elements_by_xpath('//* | |
[@id="s_position_list"]/ul/li') # ⼀次性提取多个元素⽤ elements | |
for item in ls: | |
name = | |
item.find_element_by_xpath('./div[1]/div[1]/d iv[1]/a/h3').text | |
addr = | |
item.find_element_by_xpath('./div[1]/div[2]/d iv[1]/a').text |
上面的思想是是先获取整个列表,然后再遍历列表从每个列表项中获取信息。
但这样往往在从列表项中提取数据的时候会出现 exception selenium.common.exceptions.StaleElementReferenceException(msg=None, screen=None, stacktrace=None) 的异常
搜到的解释如下:
当一个元素的引用
变旧变旧的意思是这个元素不在出现在页面的 DOM 里
可能出现这个异常的原因包括但不限于: * 你不在同一个页面,或者你获取到元素之后页面被刷新了 * 元素被定位后 被移动了又重新加到屏幕上,这样元素就被重置了。典型的例子是 javascript 框架当值改变,节点就被重建了 * 元素所在的框架或者其他内容被刷新了
我的理解是:selenium 是基于浏览器进行操作,在获取的整个列表的时候,保存的是页面信息(如 url 等)而没有将页面的内容保存下载,当尝试从列表项中提取数据的时候,需要再次从浏览器中请求数据,然而这时浏览器已经刷新了,无法根据先前保存的信息获取数据。
尝试在不同时刻打印获取的相同 xpath 的元素, <selenium.webdriver.remote.webelement.WebElement (session="a2dfac359b19d52406aa9b3300f9c99e", element="b4a5929d-be1e-4448-bdf8-12929e676f09")> ,发现它们的 session 相同,但是 element 不同。
# 循环爬取信息
所以,正确的做法应该是,需要数据时直接基于浏览器对象去获取。
import time | |
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类 | |
from selenium.webdriver.common.by import By | |
from selenium.webdriver.common.keys import Keys | |
web = Chrome() | |
web.get("http://lagou.com") | |
# 找到全国按钮 | |
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
# 点击 | |
btn.click() | |
# 找到文本框,输入 python | |
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("python", Keys.ENTER) | |
ls = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div') | |
# print(len(ls)) | |
# print (ls [0].text) # 打印出来的时候会自动提取文本,不会打印出标签 | |
''' | |
职位 | |
//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a | |
薪资 | |
//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[2]/span | |
''' | |
length = len(ls) | |
time.sleep(1.5) | |
for i in range(length): | |
# 分析每个数据的 xpath 特点,使用格式字符串 | |
work = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i+1}]/div[1]/div[1]/div[1]/a').text | |
salary = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i+1}]/div[1]/div[1]/div[2]/span').text | |
print(work, " ", salary) |
# 多窗口调度
在一个网站上的信息不够全⾯。我们希望得到的不仅仅是⼀个岗位名称和公司名称,我更想知道更加详细的职位描述以及岗位要求.
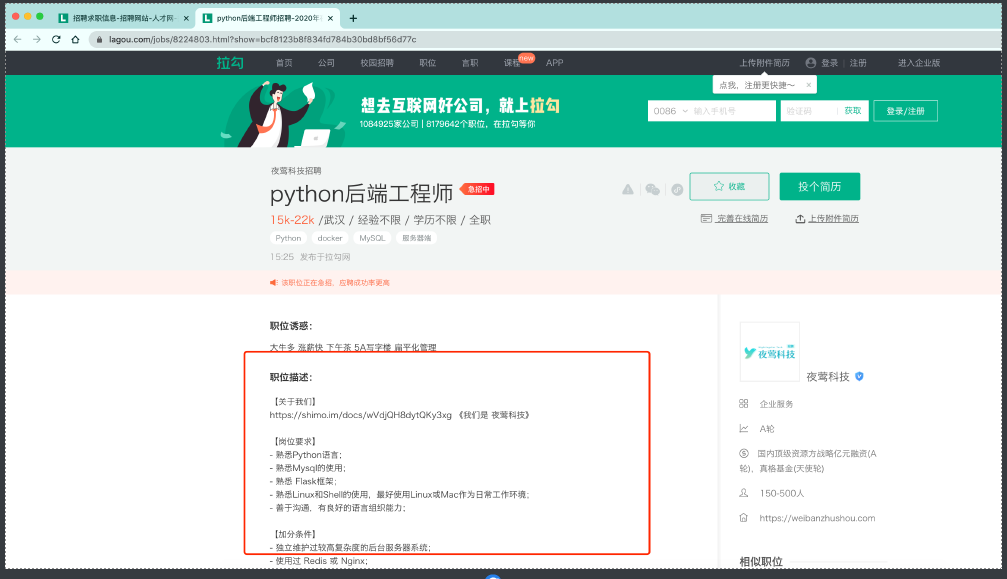
现在搜索页面点击进入详情页,然后切换窗口,爬取相应信息之后,关闭详情页窗口再返回主页面。循环操作。
import time | |
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类 | |
from selenium.webdriver.common.by import By | |
from selenium.webdriver.common.keys import Keys | |
web = Chrome() | |
web.set_window_size(800, 800) | |
web.get("http://lagou.com") | |
# 找到全国按钮 | |
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
# 点击 | |
btn.click() | |
# 找到文本框,输入 python | |
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("python", Keys.ENTER) | |
ls = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div') | |
''' | |
//*[@id="jobList"]/div[1]/div[1] | |
//*[@id="jobList"]/div[1]/div[3] | |
f'//*[@id="jobList"]/div[1]/div[{i}]' | |
''' | |
for i in range(len(ls)): | |
btn = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]') | |
btn.click() | |
web.switch_to.window(web.window_handles[-1]) # 跳转到最后一个窗口 | |
detail = web.find_element(by=By.XPATH, value='//*[@id="job_detail"]/dd[2]/div').text | |
print(detail) | |
time.sleep(2) | |
web.close() # 关闭窗口 | |
web.switch_to.window(web.window_handles[0]) # 返回第一个窗口 | |
pro = web.find_element(by=By.XPATH, value='//*[@id="order"]/div/div[1]').text | |
print('返回了 ', pro) | |
# break |
下面的代码是切换 iframe 的,但是实际测试的时候发现有问题。
iframe = web.find_element(by=By.XPATH, value='//*[@id="vodplay"]') | |
# print(iframe) | |
web.switch_to.frame(iframe) |
import time | |
import pandas as pd | |
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类 | |
from selenium.webdriver.common.by import By | |
from selenium.webdriver.common.keys import Keys | |
web = Chrome() | |
web.set_window_size(800, 800) | |
web.get("http://lagou.com") | |
# 找到全国按钮 | |
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
# 点击 | |
btn.click() | |
# 找到文本框,输入 python | |
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("python", Keys.ENTER) | |
ls = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div') | |
''' | |
//*[@id="jobList"]/div[1]/div[1] | |
//*[@id="jobList"]/div[1]/div[3] | |
f'//*[@id="jobList"]/div[1]/div[{i}]' | |
''' | |
df = pd.DataFrame(columns=['name', 'salary', 'detail']) | |
for i in range(len(ls) - 1): | |
time.sleep(0.5) | |
''' | |
name: //*[@id="jobList"]/div[1]/div[2]/div[1]/div[1]/div[1]/a | |
//*[@id="jobList"]/div[1]/div[3]/div[1]/div[1]/div[1]/a | |
f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[1]/a' | |
salary: //*[@id="jobList"]/div[1]/div[2]/div[1]/div[1]/div[2]/span | |
//*[@id="jobList"]/div[1]/div[3]/div[1]/div[1]/div[2]/span | |
f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[2]/span' | |
''' | |
name = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[1]/a').text | |
salary = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[2]/span').text | |
print(name, ' ', salary) | |
# 跳转窗口 | |
btn = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]') | |
btn.click() | |
web.switch_to.window(web.window_handles[-1]) # 跳转到最后一个窗口 | |
time.sleep(0.8) | |
detail = web.find_element(by=By.XPATH, value='//*[@id="job_detail"]/dd[2]/div').text | |
print(detail) | |
df.append({'name':name, 'salary': salary, 'detail': detail}, ignore_index=True) | |
# time.sleep(2) | |
web.close() # 关闭窗口 | |
web.switch_to.window(web.window_handles[0]) # 返回第一个窗口 | |
pro = web.find_element(by=By.XPATH, value='//*[@id="order"]/div/div[1]').text | |
print('返回了 ', pro) | |
# break | |
df.to_excel("out.xlsx", sheet_name="test") | |
''' | |
//*[@id="container"]/div[1] | |
//*[@id="job_detail"]/dd[2]/div | |
''' |
# 验证方式的解决
在 selenium 的代码的需要验证部分嵌入 time.sleep() ,设置休眠时间,此时进行人为登录验证,在登录之后再进行自动化。
但是这时就无法进行无头浏览器操作了。
# 举例
爬取拉勾网的 python 下的职业招聘信息,同时使用 pandas 进行数据存储
import time | |
import pandas as pd | |
from selenium.webdriver import Chrome # 导⼊⾕歌浏览器的类 | |
from selenium.webdriver.common.by import By | |
from selenium.webdriver.common.keys import Keys | |
from selenium import webdriver | |
web = Chrome() | |
web.set_window_size(700, 700) | |
web.implicitly_wait(20) | |
url = 'https://www.lagou.com/' | |
web.get(url) | |
# 登录 | |
# 找到全国按钮 | |
btn = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/p[1]/a') | |
# 点击 | |
btn.click() | |
web.find_element(by=By.XPATH, value='//*[@id="lg_tbar"]/div[1]/div[2]/ul/li[1]/a').click() | |
web.find_element(by=By.XPATH, | |
value='/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div/div[2]/div[3]/div').click() | |
# 输入账号和密码 | |
web.find_element(by=By.XPATH, | |
value='/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div/div[1]/div[1]/input').send_keys( | |
'13659722913') | |
web.find_element(by=By.XPATH, | |
value='/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div/div[1]/div[2]/input').send_keys( | |
'!JUNyuan031517') | |
web.find_element(by=By.XPATH, | |
value='/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[3]/div[2]/div[2]/div').click() | |
web.find_element(by=By.XPATH, value='/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[2]/button').click() | |
# 人工验证 | |
print('开始人工验证') | |
time.sleep(13) | |
print('人工验证完毕') | |
# 找到文本框,输入 python | |
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("python", Keys.ENTER) | |
ls = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div') | |
print('一页的信息个数是:', len(ls)) | |
''' | |
//*[@id="jobList"]/div[1]/div[1] | |
//*[@id="jobList"]/div[1]/div[3] | |
f'//*[@id="jobList"]/div[1]/div[{i}]' | |
''' | |
df = pd.DataFrame(columns=['name', 'salary', 'detail']) | |
# 此时进入爬取的主页面,准备爬取 20 页 | |
for j in range(20): | |
print(f'进行第{j+1}页信息的爬取') | |
# 进行此页的信息爬取 | |
for i in range(len(ls) - 1): | |
print(f' 进行第{j + 1}页第{i + 1}个信息的爬取') | |
time.sleep(0.5) | |
''' | |
name: //*[@id="jobList"]/div[1]/div[2]/div[1]/div[1]/div[1]/a | |
//*[@id="jobList"]/div[1]/div[3]/div[1]/div[1]/div[1]/a | |
f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[1]/a' | |
salary: //*[@id="jobList"]/div[1]/div[2]/div[1]/div[1]/div[2]/span | |
//*[@id="jobList"]/div[1]/div[3]/div[1]/div[1]/div[2]/span | |
f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[2]/span' | |
''' | |
name = web.find_element(by=By.XPATH, | |
value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[1]/a').text | |
salary = web.find_element(by=By.XPATH, | |
value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[2]/span').text | |
print(name, ' ', salary) | |
# 跳转窗口 | |
# //*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a | |
btn = web.find_element(by=By.XPATH, value=f'//*[@id="jobList"]/div[1]/div[{i + 1}]/div[1]/div[1]/div[1]/a') | |
web.execute_script("arguments[0].click();", btn) | |
web.switch_to.window(web.window_handles[-1]) # 跳转到最后一个窗口 | |
time.sleep(1) | |
detail = web.find_element(by=By.XPATH, value='//*[@id="job_detail"]/dd[2]/div').text | |
print(detail) | |
df = df.append({'name': name, 'salary': salary, 'detail': detail}, ignore_index=True) | |
# time.sleep(2) | |
web.close() # 关闭窗口 | |
web.switch_to.window(web.window_handles[0]) # 返回第一个窗口 | |
pro = web.find_element(by=By.XPATH, value='//*[@id="order"]/div/div[1]').text | |
print('返回了 ', pro) | |
if i == 5: | |
break | |
# 点击进入下一页 | |
time.sleep(0.5) | |
btn = web.find_element(by=By.XPATH, value='//*[@id="jobList"]/div[3]/ul/li[9]/a') | |
web.execute_script("arguments[0].click();", btn) | |
df.to_excel("out.xlsx", sheet_name="test") | |
print(df) |