# 环境配置
https://pdos.csail.mit.edu/6.828/2018/tools.html 这里参考的链接中有一个 2018 的标识,是可以替换为 2022 的。但是具体尚未摸索。
# Lab guidance
#include <stdio.h> | |
#include <stdlib.h> | |
void f(void) | |
{ | |
int a[4]; // 这里已经分配了 4 * 4 个字节大小 | |
int *b = malloc(16); | |
int *c; // 指针变量 | |
int i; | |
printf("1: a = %p, b = %p, c = %p\n", a, b, c); | |
c = a; | |
for (i = 0; i < 4; i++) | |
a[i] = 100 + i; | |
// 100 101 102 103 | |
c[0] = 200; | |
// 200 101 102 103 | |
printf("2: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n", | |
a[0], a[1], a[2], a[3]); | |
c[1] = 300; | |
*(c + 2) = 301; | |
// 200 300 301 103 | |
3 [c] = 302; | |
// 200 300 301 302 | |
printf("3: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n", | |
a[0], a[1], a[2], a[3]); | |
c = c + 1; // c = a + 1 | |
*c = 400; | |
// 200 400 301 302 | |
// 400 = 1 1001 0000 301 = 1 0010 1101 | |
printf("4: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n", | |
a[0], a[1], a[2], a[3]); | |
c = (int *)((char *)c + 1); // 没有对齐了,现在 c 指向 a [2] 的第二个字节 | |
*c = 500; // 500 = 0001 1111 0100 | |
// a[1] = 0001 1111 0100 1001 0000 = 128144 | |
//a [3] 的最低一个字节被覆盖为 0 变为 1 0000 0000 | |
printf("5: a[0] = %d, a[1] = %d, a[2] = %d, a[3] = %d\n", | |
a[0], a[1], a[2], a[3]); | |
b = (int *)a + 1; // 加 4 | |
c = (int *)((char *)a + 1); // 加 1 | |
printf("6: a = %p, b = %p, c = %p\n", a, b, c); | |
} | |
int main(int ac, char **av) | |
{ | |
f(); | |
return 0; | |
} |
int *p = (int*)100 |
git 的参考链接:
http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
http://eagain.net/articles/git-for-computer-scientists/
You may find that your print statements may produce much output that you would like to search through; one way to do that is to run make qemu inside of script (run man script on your machine), which logs all console output to a file, which you can then search. Don't forget to exit script.
上面说的这个脚本尚没有找到。
gdb 调试:https://pdos.csail.mit.edu/6.828/2019/lec/gdb_slides.pdf
#include <unistd.h> //fork 和 getpid 定义在此头文件中 | |
#include <sys/types.h> //pid_t 定义在此头文件中 | |
#include <stdio.h> | |
int main() | |
{ | |
pid_t pid; | |
// printf("fork!"); | |
printf("fork! \n"); | |
// fflush(0); | |
pid = fork(); | |
if (pid < 0) | |
printf("error in fork!"); | |
else if (pid == 0) | |
printf("i am the child process, my process id is %d\n", getpid()); | |
else | |
{ | |
printf("the child process\'pid is %d\n", pid); // 在这里打印的时候,这里的输出和上面的输出相同 | |
printf("i am the parent process, my process id is %d\n", getpid()); | |
} | |
} |
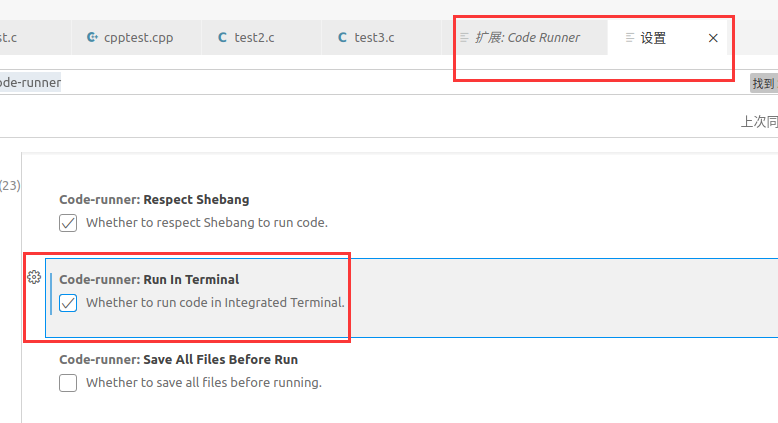
在 vscode 中测试运行的时候,如果使用 Code Runner 插件,该插件会将结果在下边栏的 “输出” 页输出,此输出结果和在终端运行输出的结果不一样,可以将 Code Runner 插件改成在终端输出。
#include <unistd.h> | |
#include <stdio.h> | |
// 下面这三个头文件是用于 wait 的 | |
#include <stdlib.h> | |
#include <sys/types.h> | |
#include <sys/wait.h> | |
int main(void) | |
{ | |
int pid; | |
pid = fork(); | |
if (pid > 0) | |
{ | |
printf("parent: child=%d\n", pid); | |
pid = wait((int *)0); | |
printf("child %d is done\n", pid); | |
} | |
else if (pid == 0) | |
{ | |
printf("child: exiting\n"); | |
exit(0); | |
} | |
else | |
{ | |
printf("fork error\n"); | |
} | |
} |
VSCode 中针对 C 语言的代码格式化配置 http://t.csdn.cn/hJW4E
user/sh.c 是 shell 的定义文件,但是感觉会用到编译原理的知识,之后再返回来看。
user/sh.c 151 行 while 循环连续打开三个,返回的 fd 是连续的么?为什么呢?
#include <stdio.h> | |
#include <unistd.h> | |
#include <sys/wait.h> | |
#include <sys/types.h> | |
int main() { | |
close(1); // 当关闭 1 号文件描述符后下面的语句就不能输出了 | |
write(1, "hello\n", 6); | |
return 0; | |
} |
#include <stdio.h> | |
#include <unistd.h> | |
#include <sys/wait.h> | |
#include <sys/types.h> | |
int main() { | |
// char buf[20] = "hello"; | |
// printf("%s\n", buf); | |
//close (1); // 当关闭 1 号文件描述符后下面的语句就不能输出了 | |
// write(1, "hello\n", 6); | |
if (fork() == 0) { | |
close(1); | |
write(1, "hello ", 6); | |
} | |
else { | |
wait(0); | |
write(1, "world\n", 6); | |
} | |
return 0; | |
} |
在上面的代码中,尽管在子进程中将 1 号文件描述符给关闭了,但是在父进程中仍能够正常输出。是不是两个进程的 1 号文件描述符对应的是两个表。
感觉不对,标准输出对应的表还在,关闭之后应该是那个进程的那个号不再指向此表了。
书上的代码好像不是 c 语言的标准代码,还是说,这是在 xv6 下运行的代码。
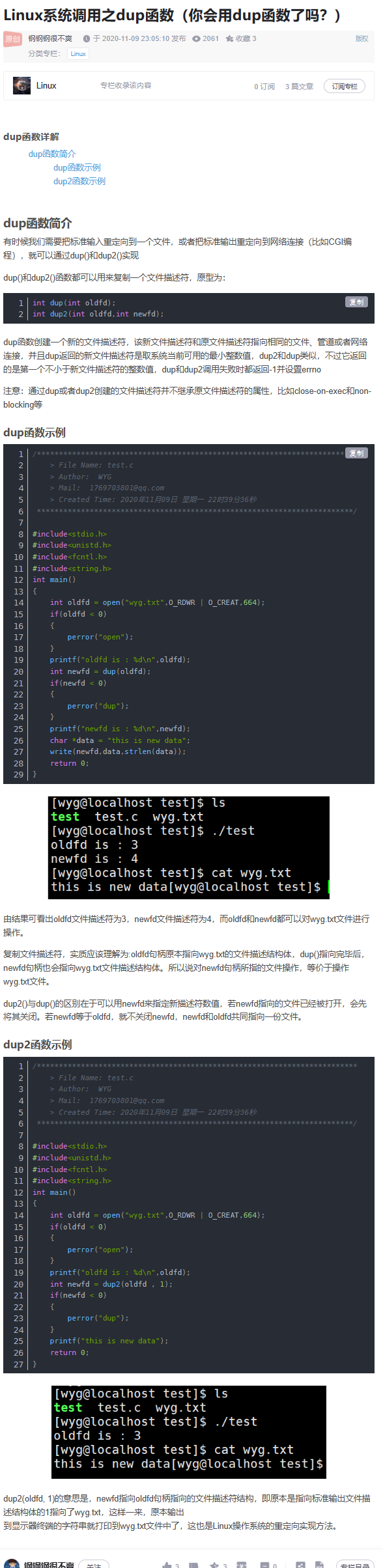
# Linux 系统调用之 dup 函数
函数定义在 #include <unistd.h> 头文件中
http://t.csdn.cn/4xO0G
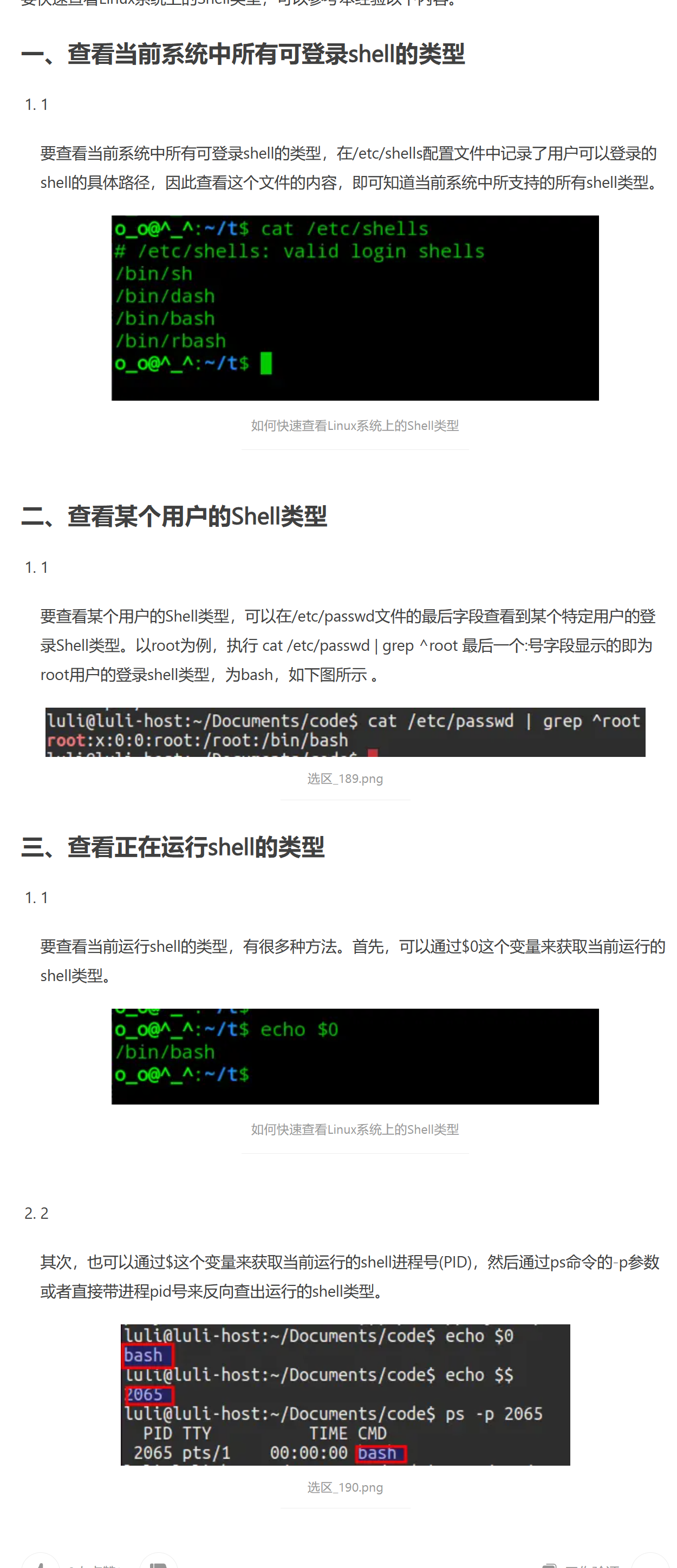
# ubuntu 所有用户
以及查看当前登录
w
who
users
查看系统中所有用户:
grep bash /etc/passwd
或者:
cat /etc/passwd | cut -f 1 -d:
# cat t.txt 时权限不够
如果是自行创建的 txt 文件可以 cat,但是如果此 txt 文件是由 C 程序创建并写入的话,在 cat 的时候就会出现权限不够的情况。
可以执行 chmod 777 filename 命令,之后即使删除此文件,然后再运行程序生成此名字的文件,仍然可以正常 cat,在 vscode 下可以正常查看了。
# fopen 和 open 的区别
# wait
#include<stdio.h> | |
#include<unistd.h> | |
#include<fcntl.h> | |
#include<string.h> | |
#include <sys/wait.h> | |
#include <sys/types.h> | |
#include <stdlib.h> | |
int main() | |
{ | |
int pid; | |
if((pid = fork()) == 0){ | |
printf("this is child process 1\n"); | |
exit(0); | |
} | |
if((pid = fork()) == 0){ | |
printf("this is child process 2\n"); | |
exit(0); | |
} | |
wait(0); | |
wait(0); | |
printf("this is the parent process\n"); | |
return 0; | |
} |
在父进程中调用 wait,假设有两个子进程在运行,只要某一个子进程运行完毕,wait 就会返回。所以,如果需要父进程等待两个子进程都完成再继续执行,需要使用两个 wait。
user/sh.c 100 行处,总感觉有问题,这里的执行并不只是一个父进程下挂两个子进程,其中的一个子进程下还会再挂一个子进程(称为孙进程),此孙进程和另一个子进程的工作是重复的。奥,但是如果在 runcmd 中实现了类似 exit 或者 return 的函数返回,就正确了,应该如此。
case PIPE: | |
pcmd = (struct pipecmd*)cmd; | |
if(pipe(p) < 0) | |
panic("pipe"); | |
if(fork1() == 0){ | |
close(1); | |
dup(p[1]); | |
close(p[0]); | |
close(p[1]); | |
runcmd(pcmd->left); | |
} | |
if(fork1() == 0){ | |
close(0); | |
dup(p[0]); | |
close(p[0]); | |
close(p[1]); | |
runcmd(pcmd->right); | |
} | |
close(p[0]); | |
close(p[1]); | |
wait(0); | |
wait(0); | |
break; |
# panic
# 1.4 最后两段
用户级程序,意味着普通用户可以通过用户命令来调用。
# main 函数和其他函数调用
user/rm.c、user/echo.c 中都是有一个 main 函数的,也有 c 文件是普通函数的定义文件,在文件中写的 main 函数是怎么执行的呢?
# makefile
# 参考的教程
一文入门 Makefile - 程序员良许的文章 - 知乎
https://zhuanlan.zhihu.com/p/56489231



在上面的换行中,执行顺序可以理解为,先在 makefile 中进行变量的展开替换,然后再在一个 shell 窗口中执行命令。
因此,由于这些命令是在一行上的,如果需要设置不回显命令,只能在第一条命令前面加 @ 。
阮一峰:
https://www.ruanyifeng.com/blog/2015/02/make.html
# 通配符和模式匹配的区别
fool:t/*.txt | |
@echo hello world | |
@echo $^ |
当 t/*.txt 匹配到多个文件的时候, $< 仅表示第一个文件, $^ 才表示所有的文件,即这俩的解析是针对匹配完成后的字符串列表进行的。
模式规则讲得有点奇怪,在目标名中需要有 %,可以目标如果没有生成前,怎么匹配呢?
参考 http://t.csdn.cn/TYRnV

all: $(subst .txt,.k, $(wildcard t/*.txt)) | |
%.k:%.txt | |
@echo $< $@ |
在上面中,wildcard 需要指定文件夹路径,如果是 $(wildcard *.txt) ,得到的是当前文件夹下的 txt 文件,不能得到子文件夹 t 下的 txt 文件。
但是 % 是能够匹配路径符号的 / 的,所以 a.txt 和 t/a.txt 都能够被 %.txt 匹配
# 变量
文本字符串
# = := ?= += 的使用及区别

http://t.csdn.cn/z4Dmv
b := $akkk
a = jjj
hello:hello.c
$(CXX) $^ -o $@
foo:
@echo $b
当使用 := 时,是原地展开的,当使用的变量之后变化了,它的文本字符串值是不会变化的。
bar = | |
foo = $(bar) | |
ifdef bar | |
frobozz = yes | |
else | |
frobozz = no | |
endif | |
bar ?= hello | |
fool: | |
@echo $(bar) | |
@echo $(frobozz) | |
clean: | |
rm -f hello |
上面的代码中,bar 不会被赋值为 hello,所以结果输出空行和 no。
# $
http://t.csdn.cn/kz3Jy

a = hello | |
c = world | |
b := $akkk | |
a = jjj | |
foo: | |
@b=2;\ | |
echo $${b};\ | |
# echo $$b;\ | |
echo $b;\ | |
clean: | |
rm -f hello |
有时候直接 $变量名 时,美元符号和变量名的第一个字符结合在一起可能会有特殊含义,比如 $f ,所以最好还是 $(变量名)
U=user | |
UPROGS=\ | |
$U/_cat\ | |
$U/_echo\ | |
fool: | |
@echo $(UPROGS) | |
clean: | |
rm -f hello |
应该是当变量名称只有一个字符时,可以省略括号,多于一个字符时不能省略。
# filter
http://t.csdn.cn/IjKiZ

# ifdef 和 ifeq
当 makefile 的变量定义为空值时,ifdef 返回的是 false。
没有定义过变量或者变量用 = 初始定义赋值为空值,ifndef 返回 true。
bar = | |
foo = $(bar) |
类似上面的,对 foo 的 ifndef 返回 true。
在条件中不可以使用自动变量,只有在执行 makefile 时自动变量才可用,但是在解析条件时自动变量是不可用的。
参考文档:
https://www.gnu.org/software/make/manual/html_node/Conditional-Syntax.html
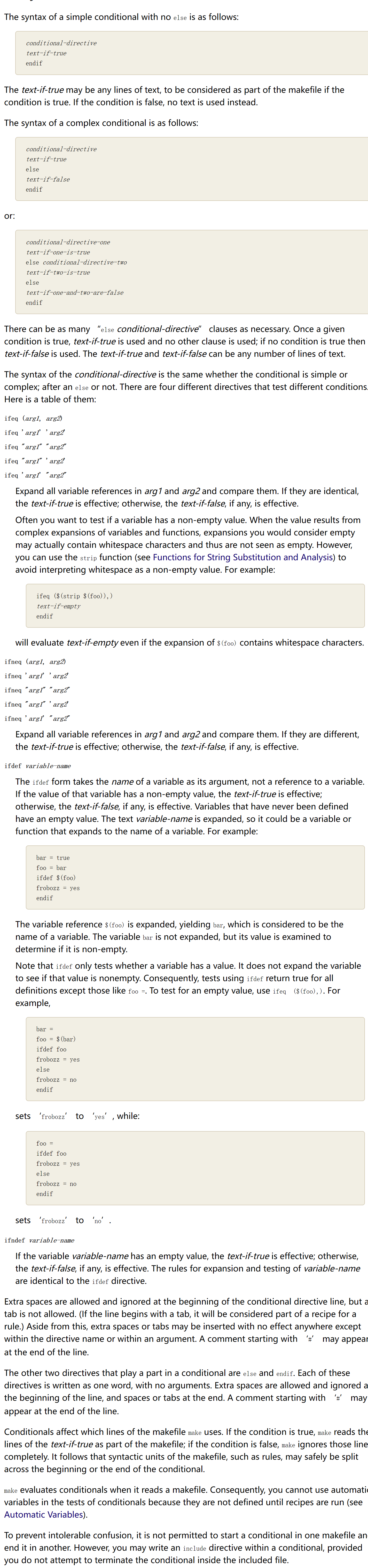
# include
# 输出重定向问题
不能使用 make foo > t.txt 将输出重定向到 txt 文件的,因为在命令行输出的结果不是 make 的,而是 makefile 中的命令在 shell 中执行中输出的。
# rm touch
命令后可以接由空格分隔的多个文件
# shell 教程
# 查看运行 shell 的程序
https://www.jianshu.com/p/582ec50ce6c3