# 各层位置关系
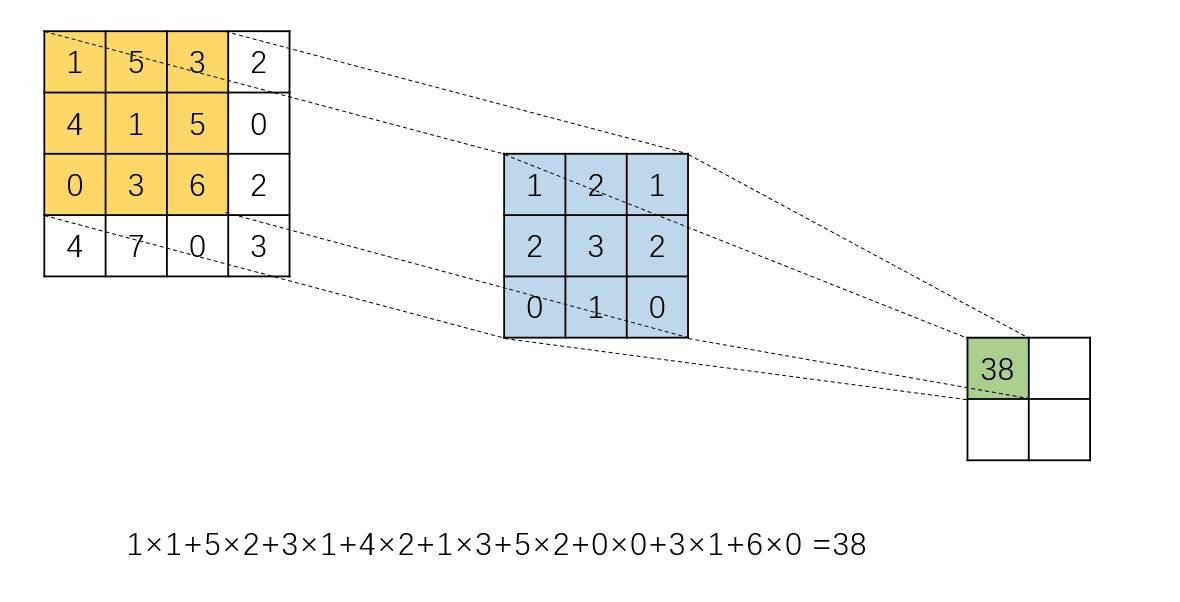
卷积核可以表示成一种特殊的多元线性回归的权重矩阵;由于权重矩阵有大量的参数是一样的,且有大量的 0 ,所以可以把权重矩阵的系数都压缩到一个卷积核中又不损失信息。卷积的这种数学操作的特点又保留了图片的空间信息,所以卷积是一种开销小于全连接层,但效果较好的操作。
所以在神经网络学习参数中,可以把对卷积核的拟合视为一种对神经元权重的拟合,只是神经元之间会以某种方式连接并且共享大量参数。
也可以很自然的推导出,如果没有池化层等非线性操作, 那么多层卷积就等同于一层卷积 ,只靠卷积操作无法拟合任意函数
# softmax
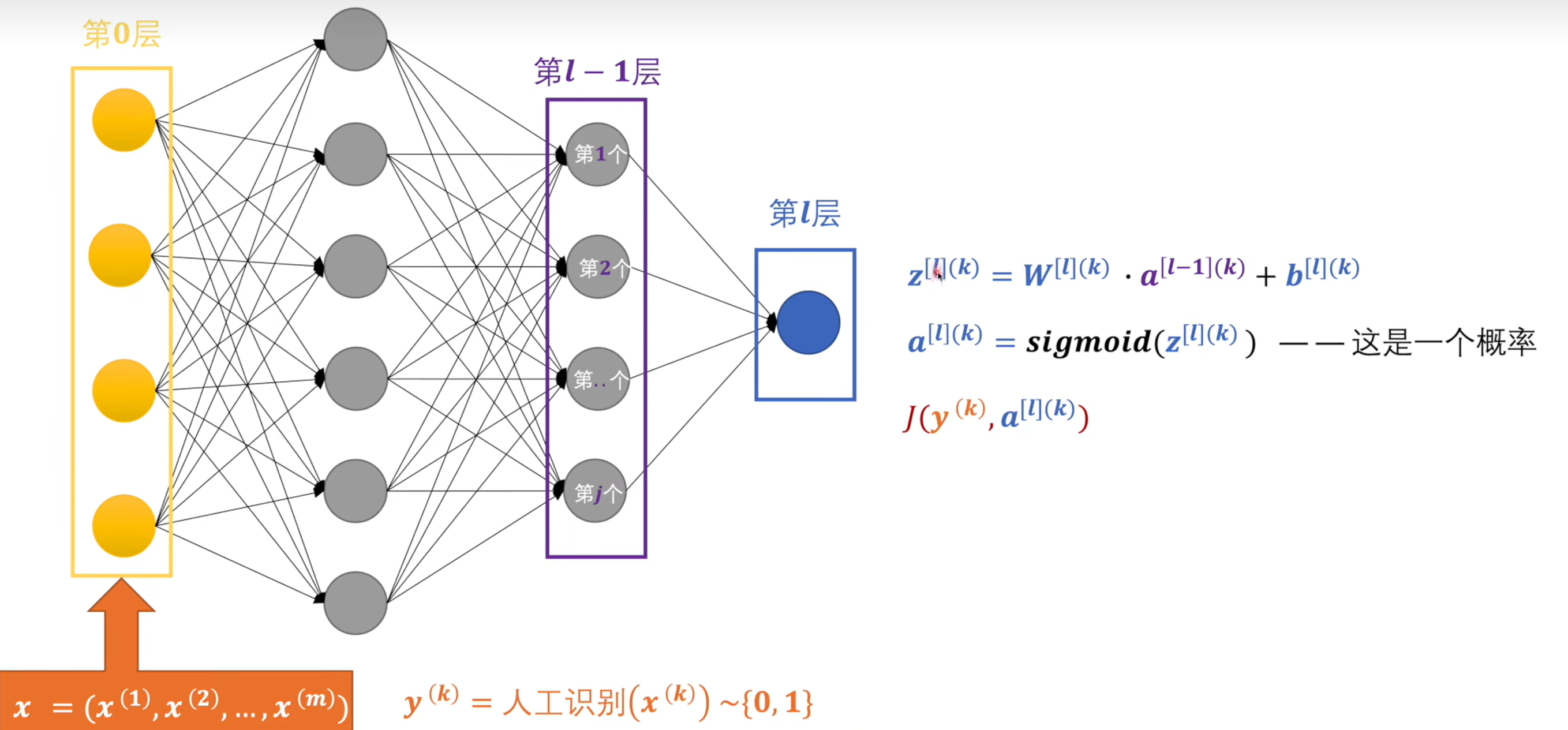
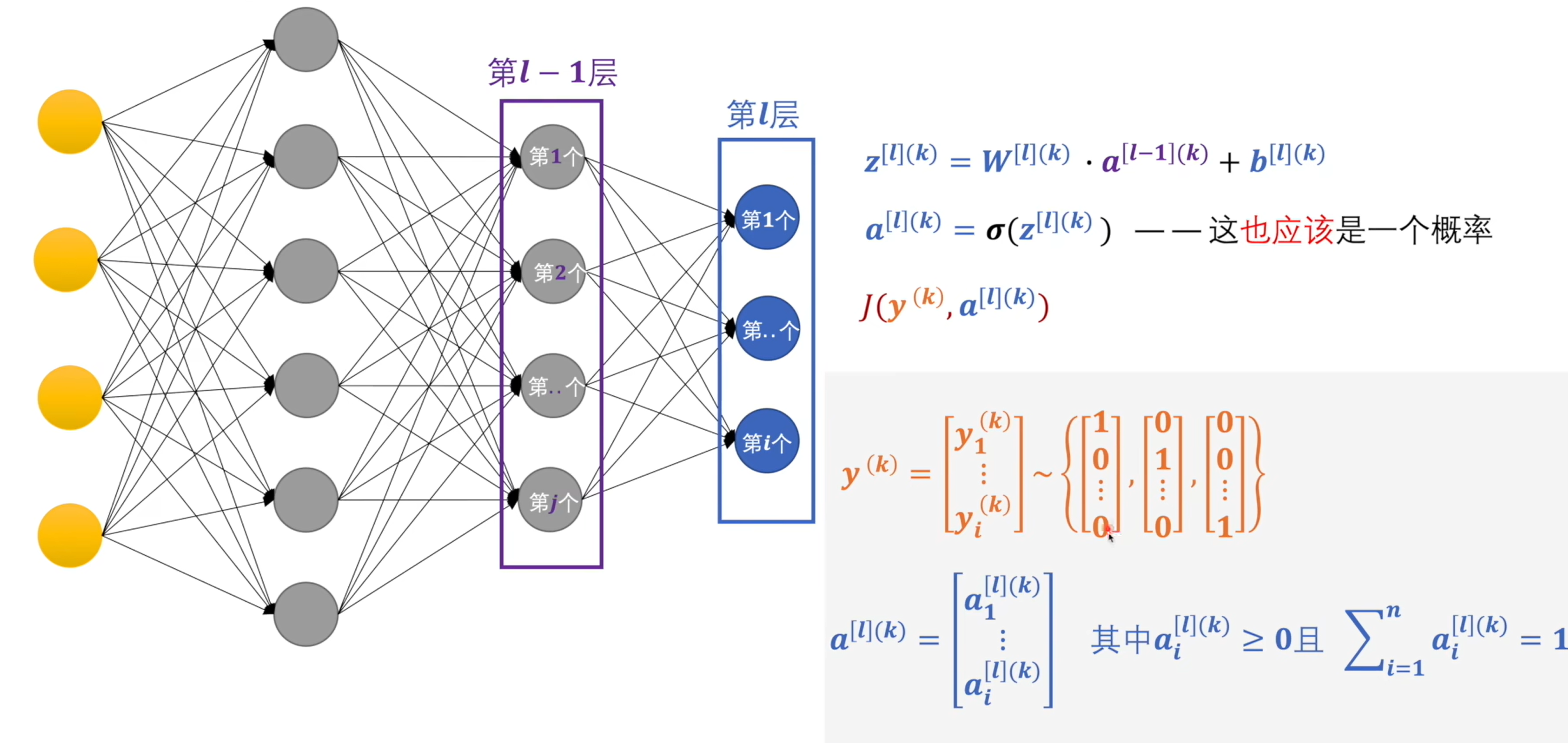
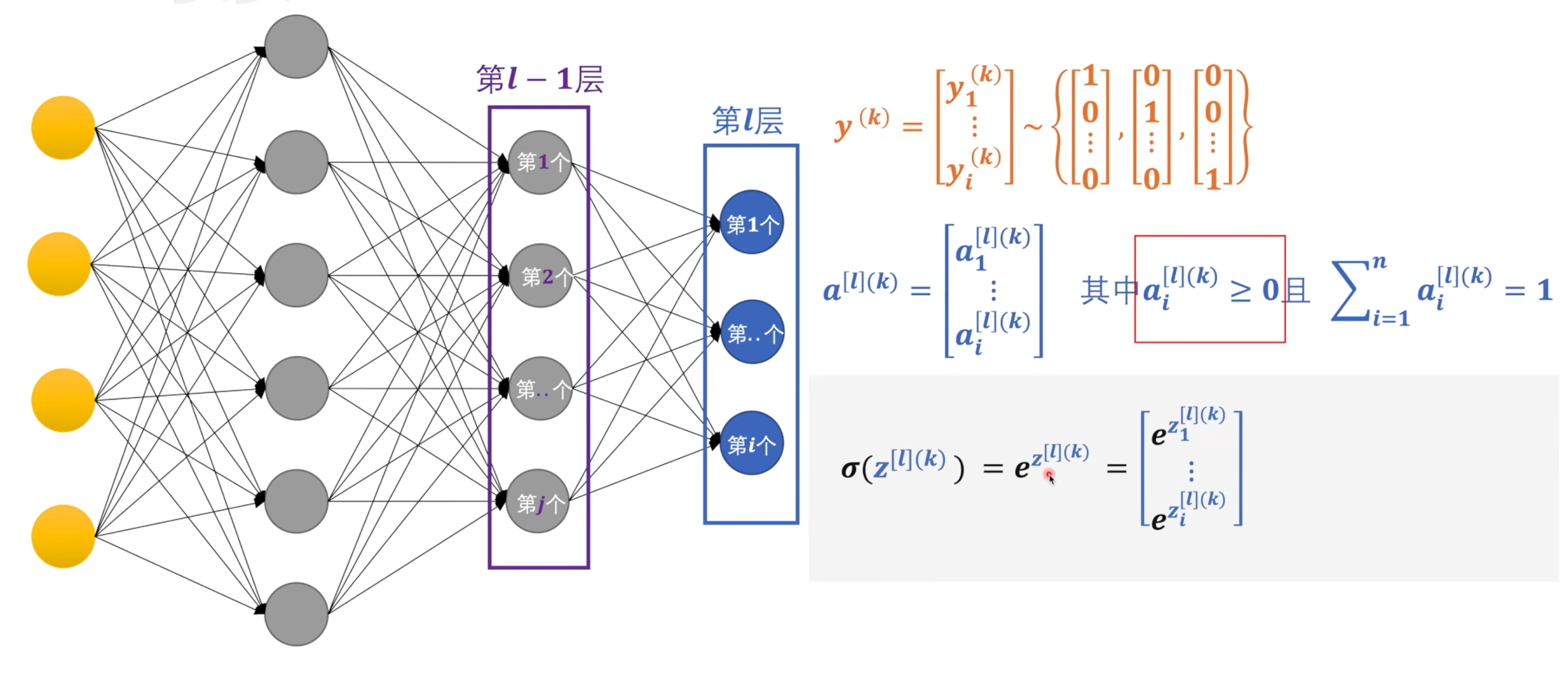
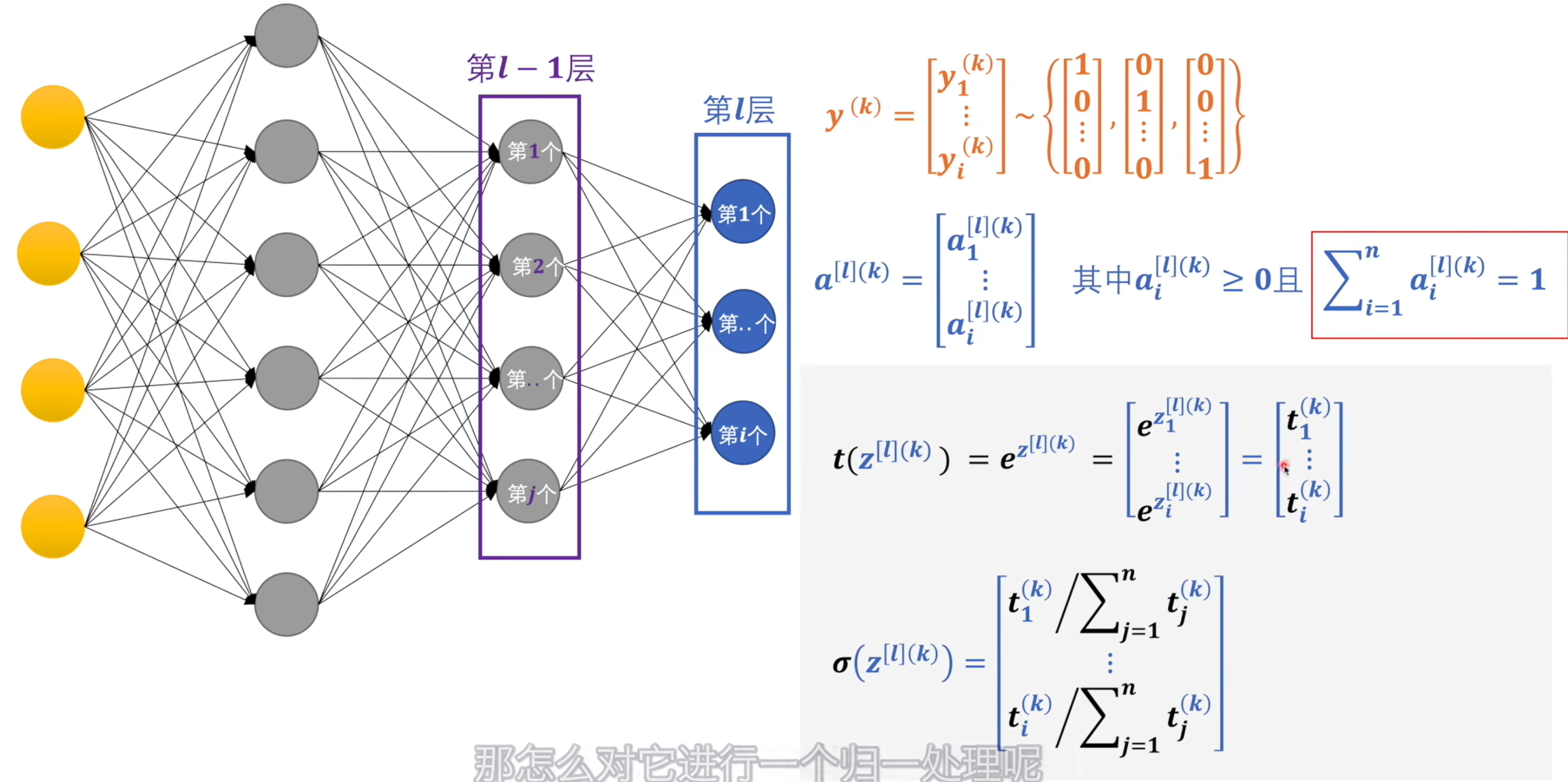
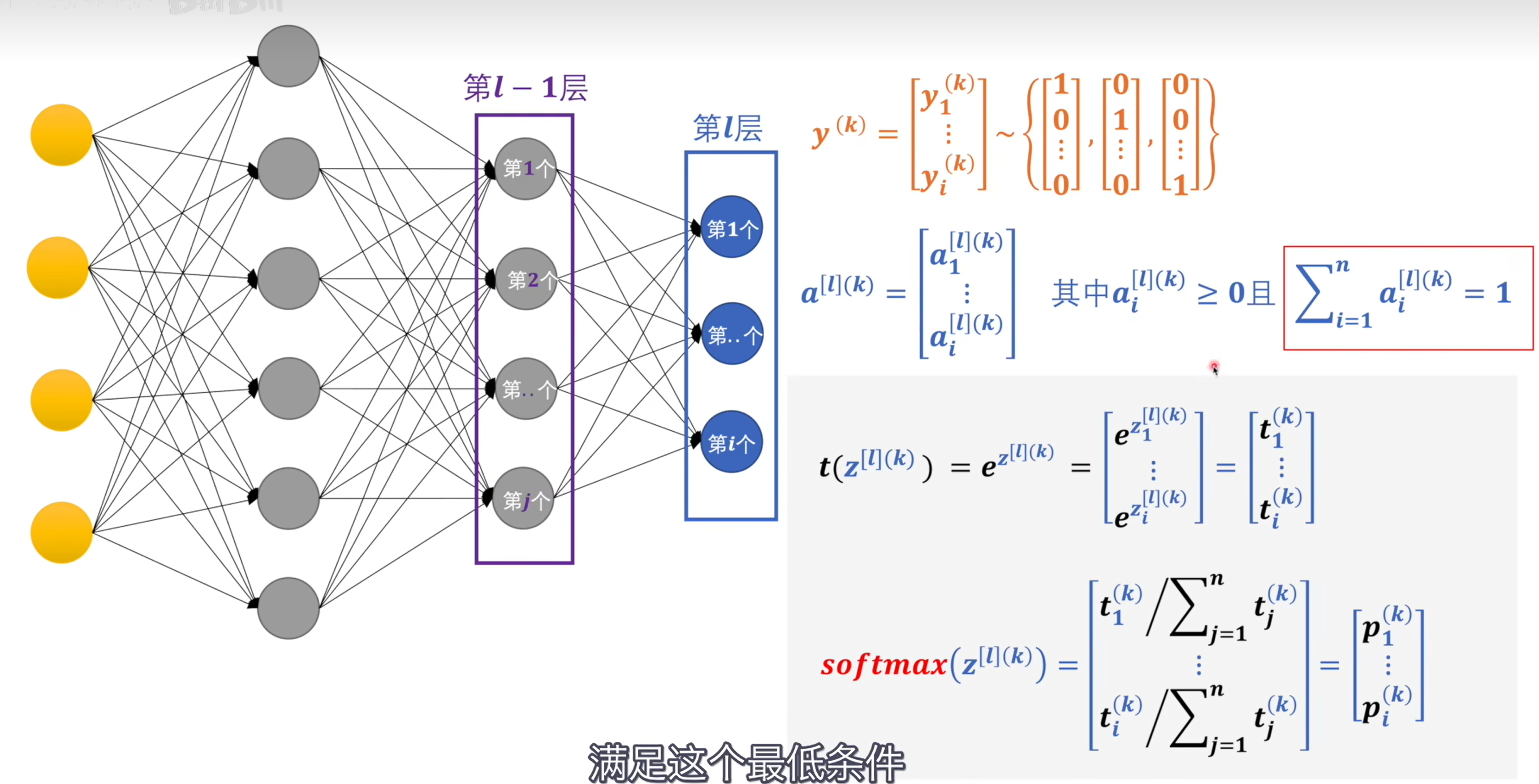
交叉熵:计算出来的概率和标签中的值进行交叉熵运算,数值越大代表两种概率模型的相差大
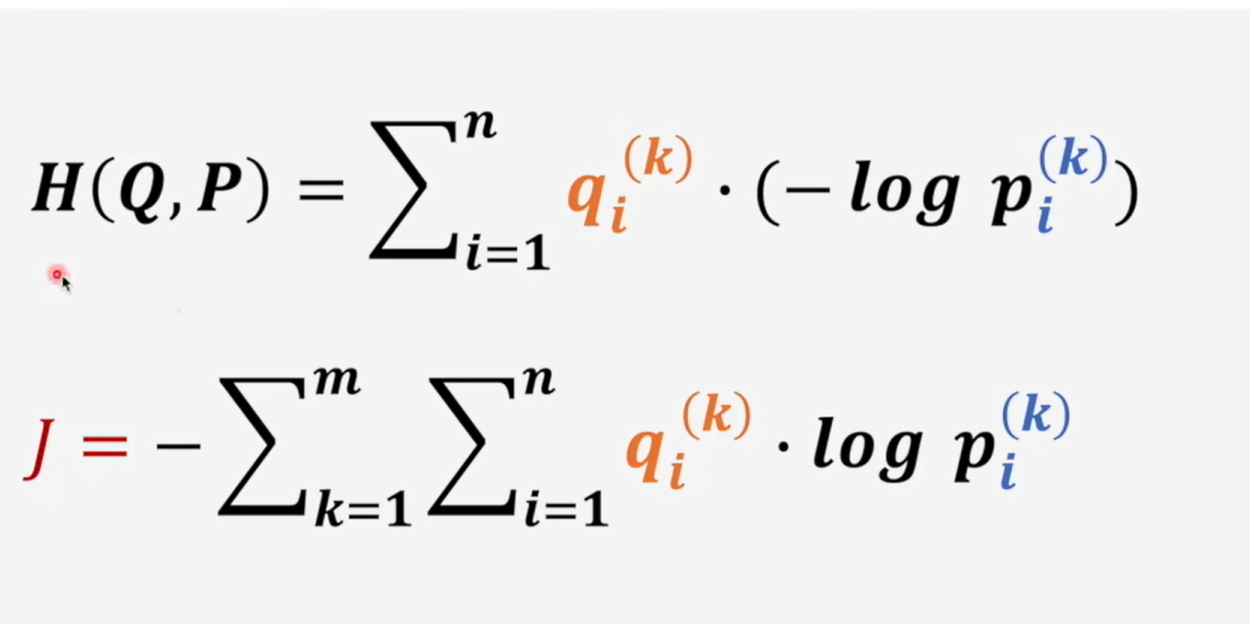
# 交叉熵
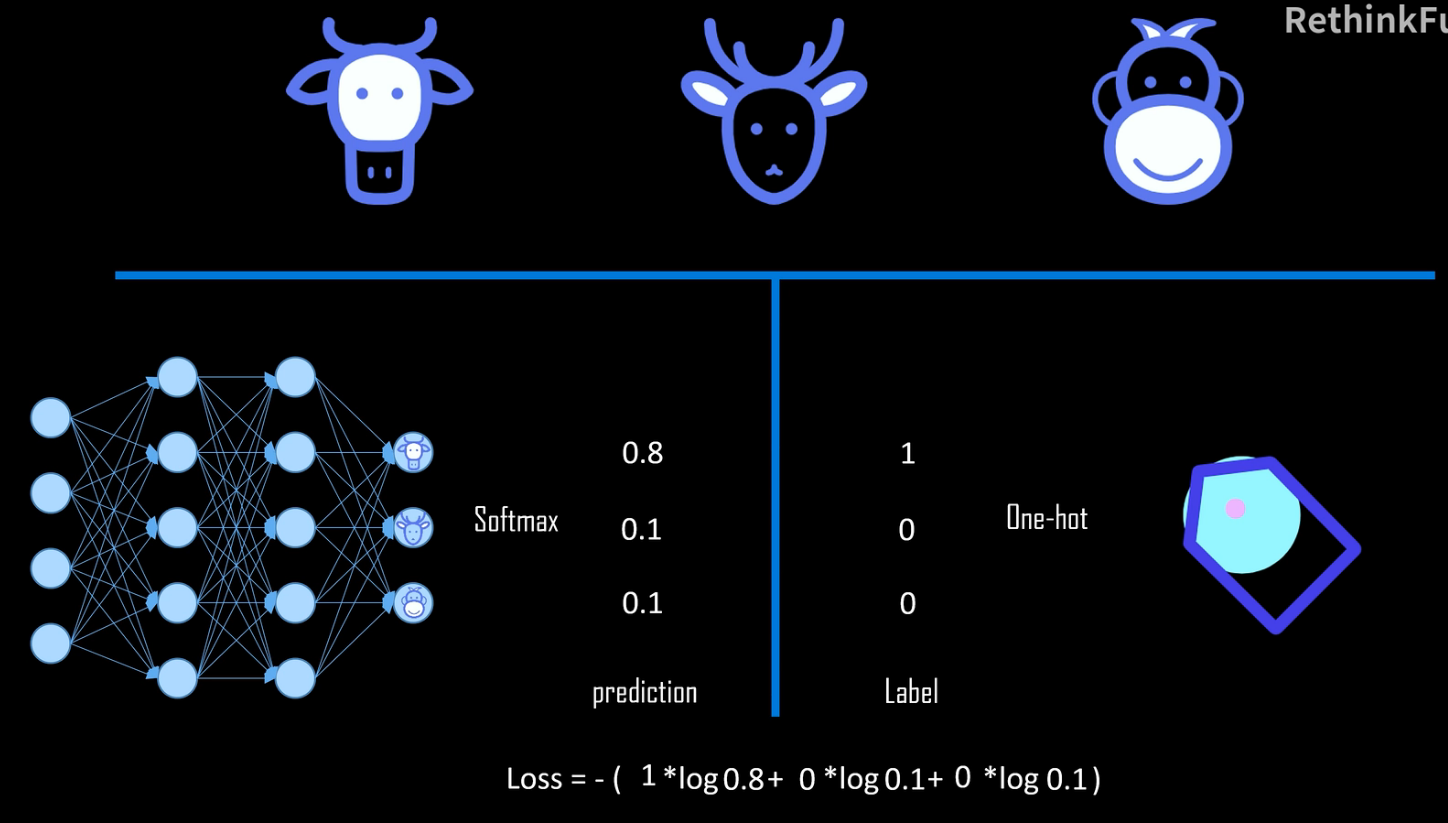
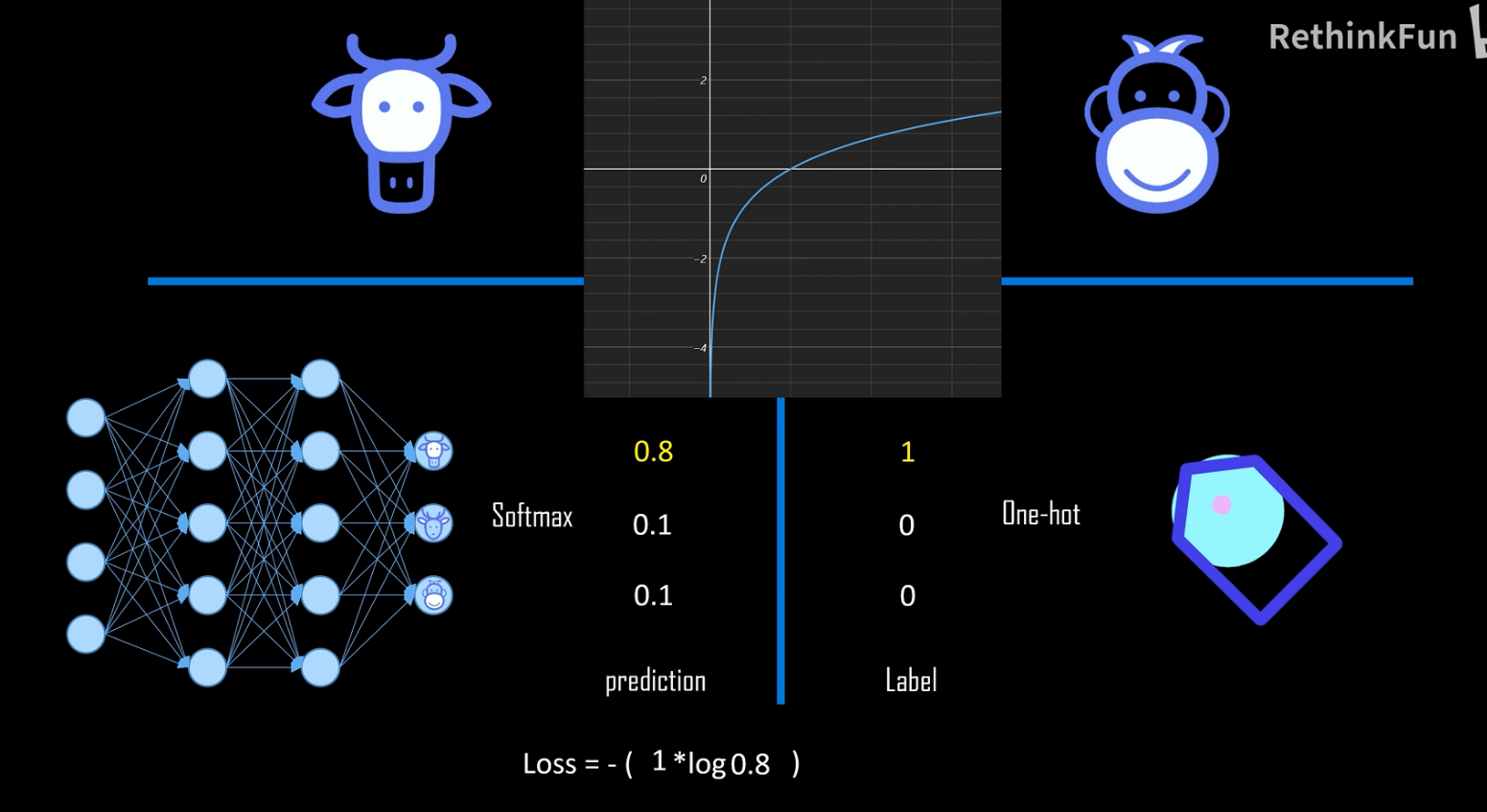
如果某个类别的预测概率为 1,则由对数函数可知,loss 得到的结果为 0
回顾极大似然估计


在样本上预测正确的概率,n 为样本量,因为是独立抽样,使用乘积

取对数加负号得到交叉熵损失函数

一个系统的信息熵是对这个系统平均编码的最小长度
# 信息量和信息熵
信息的作用是消除不确定性
信息量:字字珠玑,废话连篇
信息量和它能消除的不确定性有关
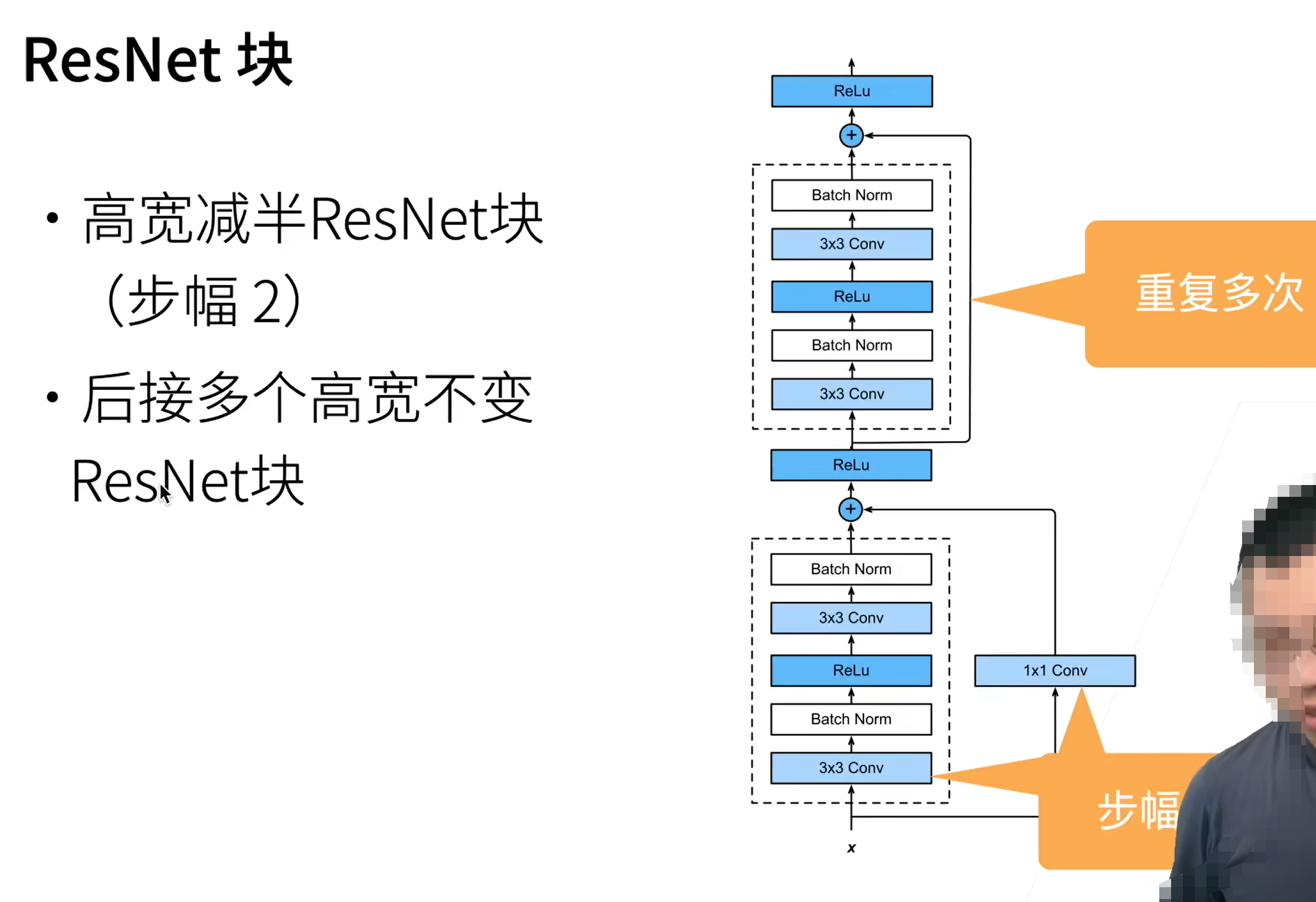
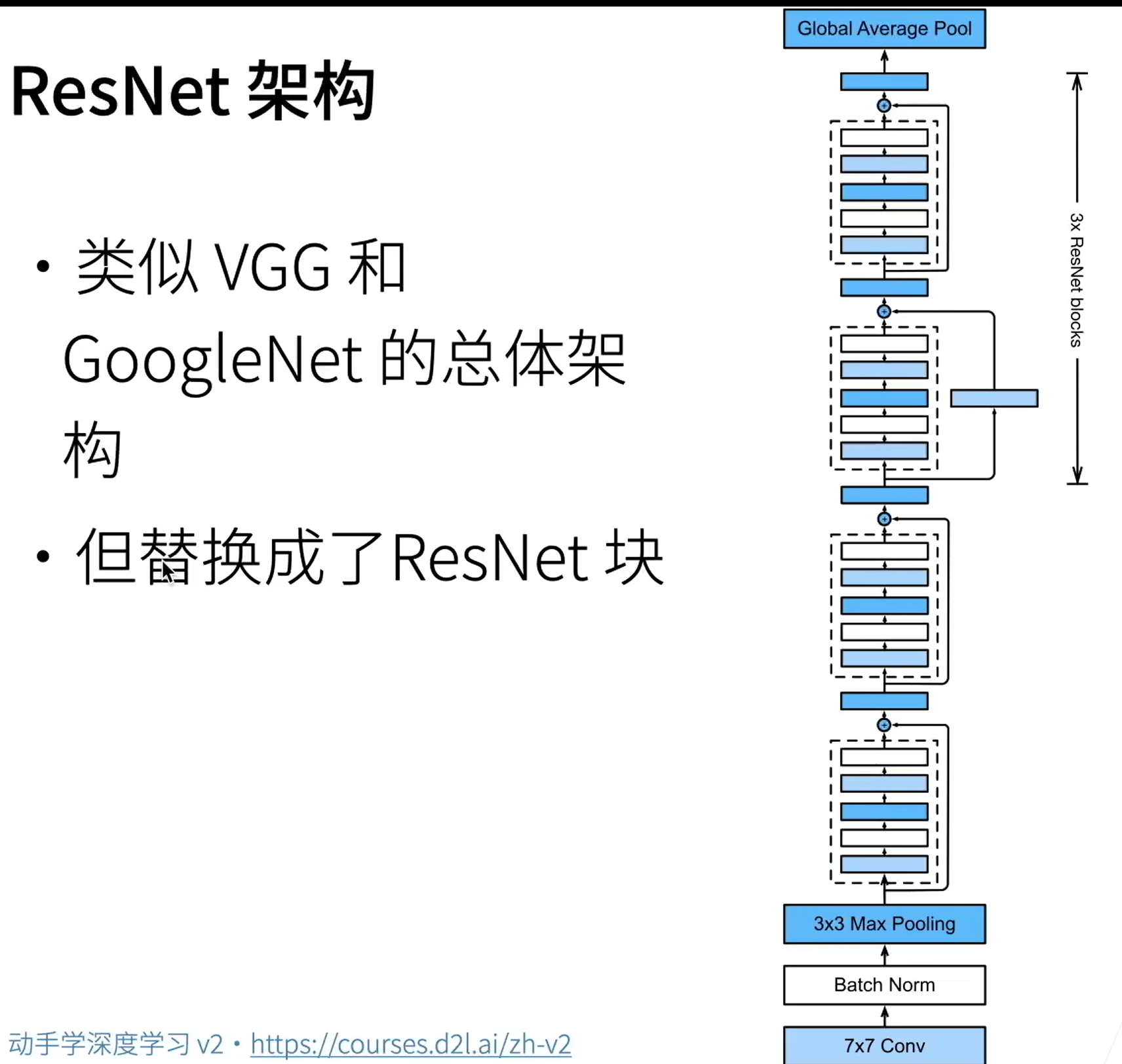
# ResNet
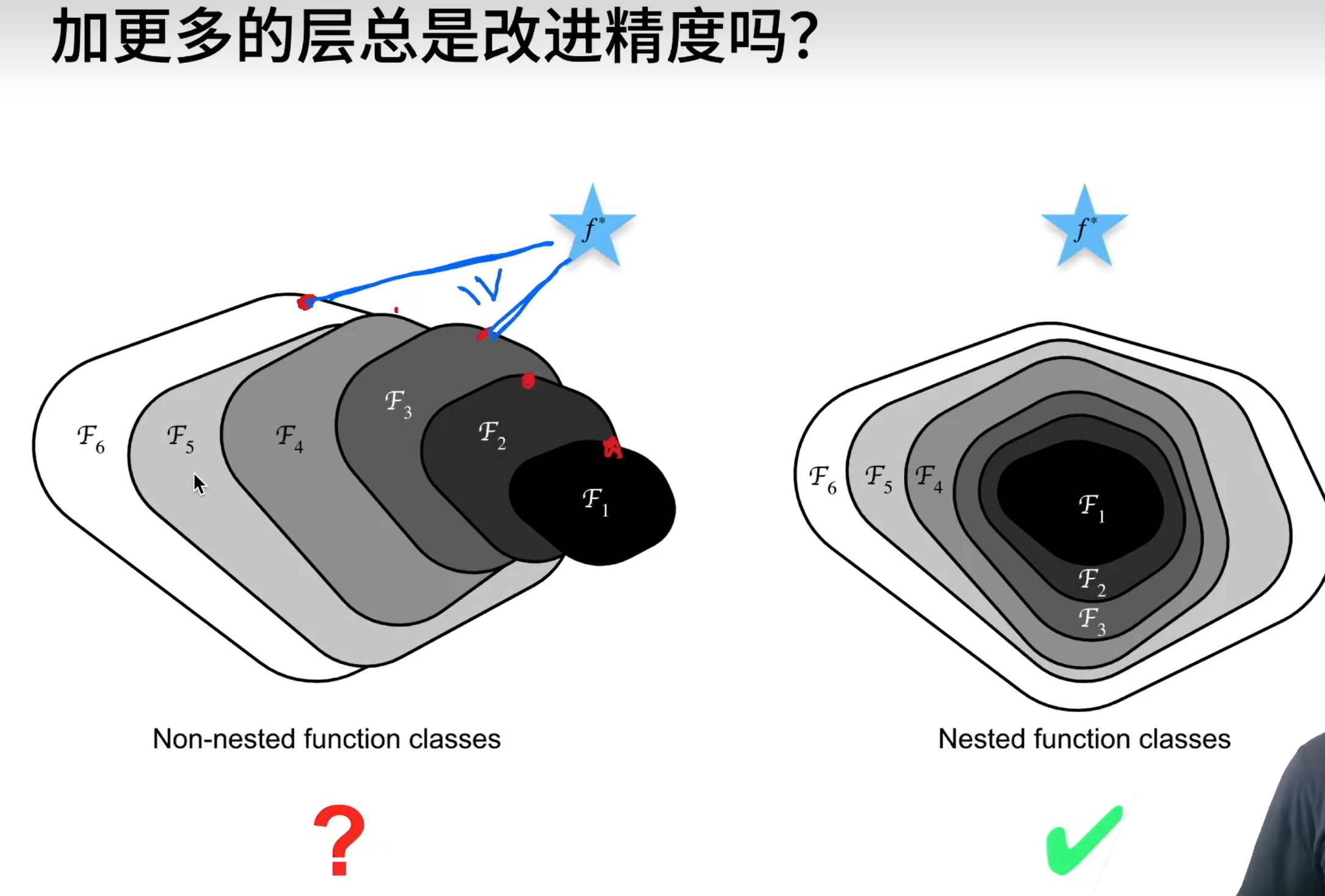
每次更复杂的模型都是包含前面的小模型的
通过相加的形式来增加层数
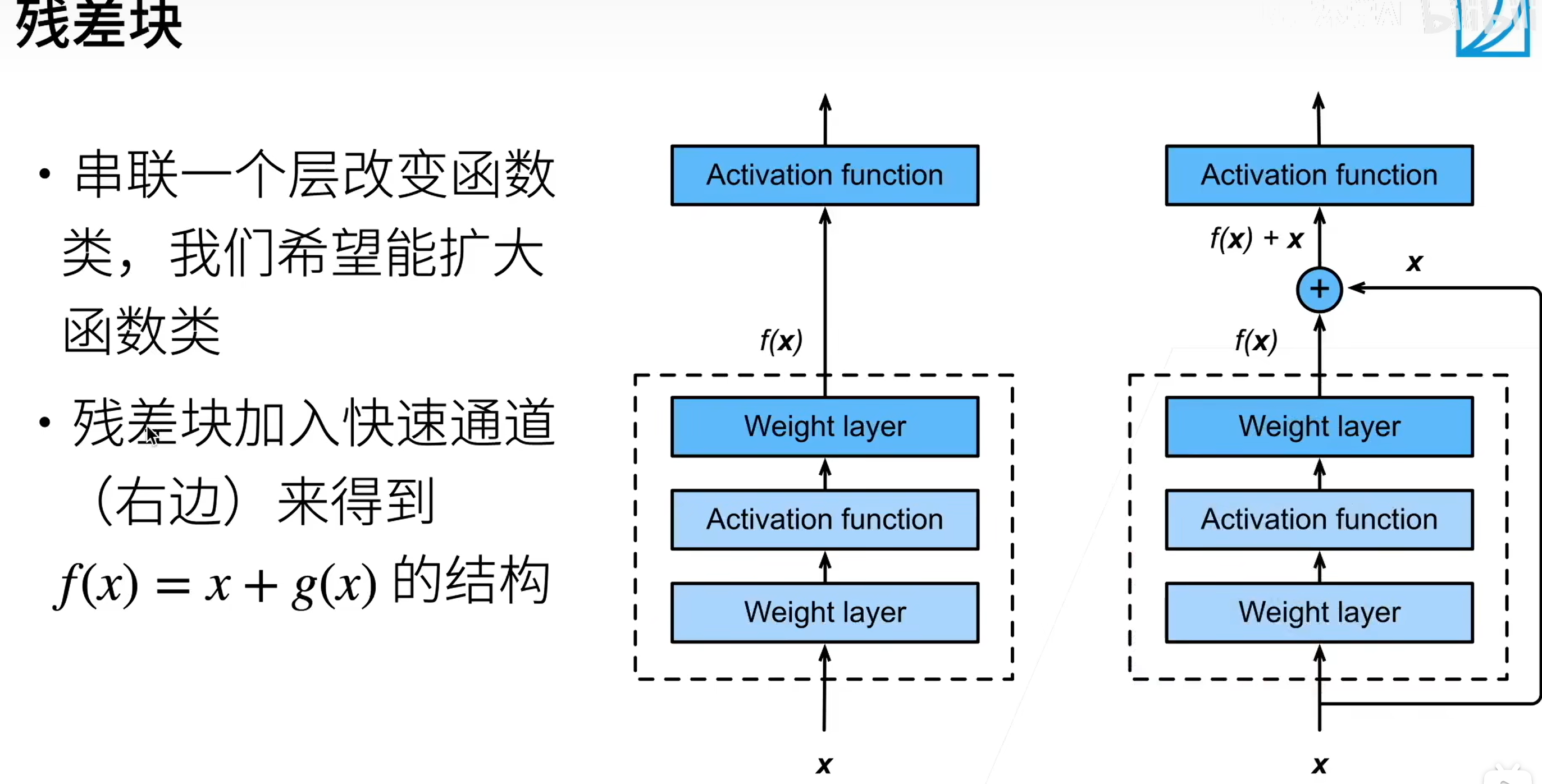
Weight layer 为卷积层
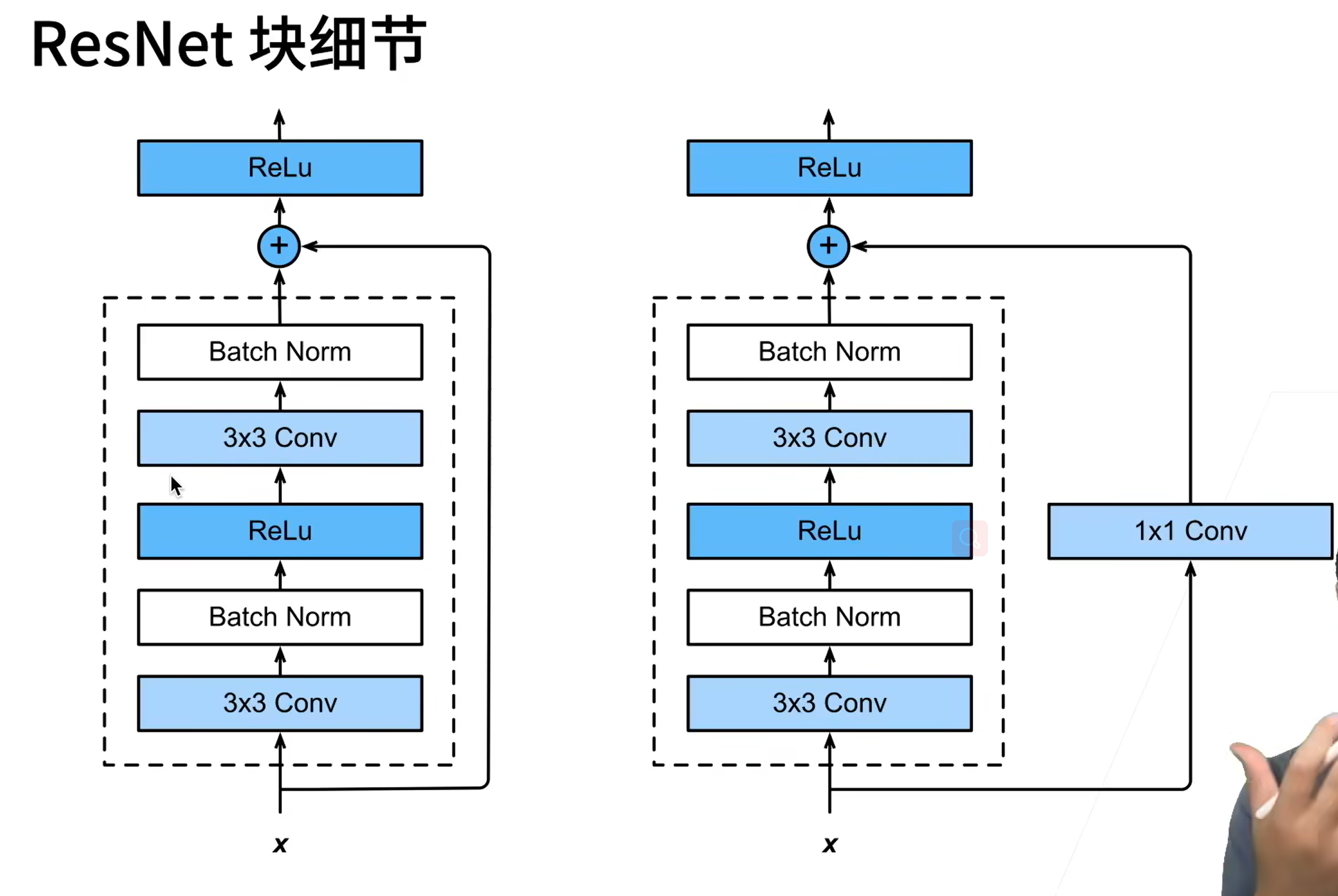
右边的加入 1x1 的卷积层是要将 x 变为合适的通道数才能加得上去。
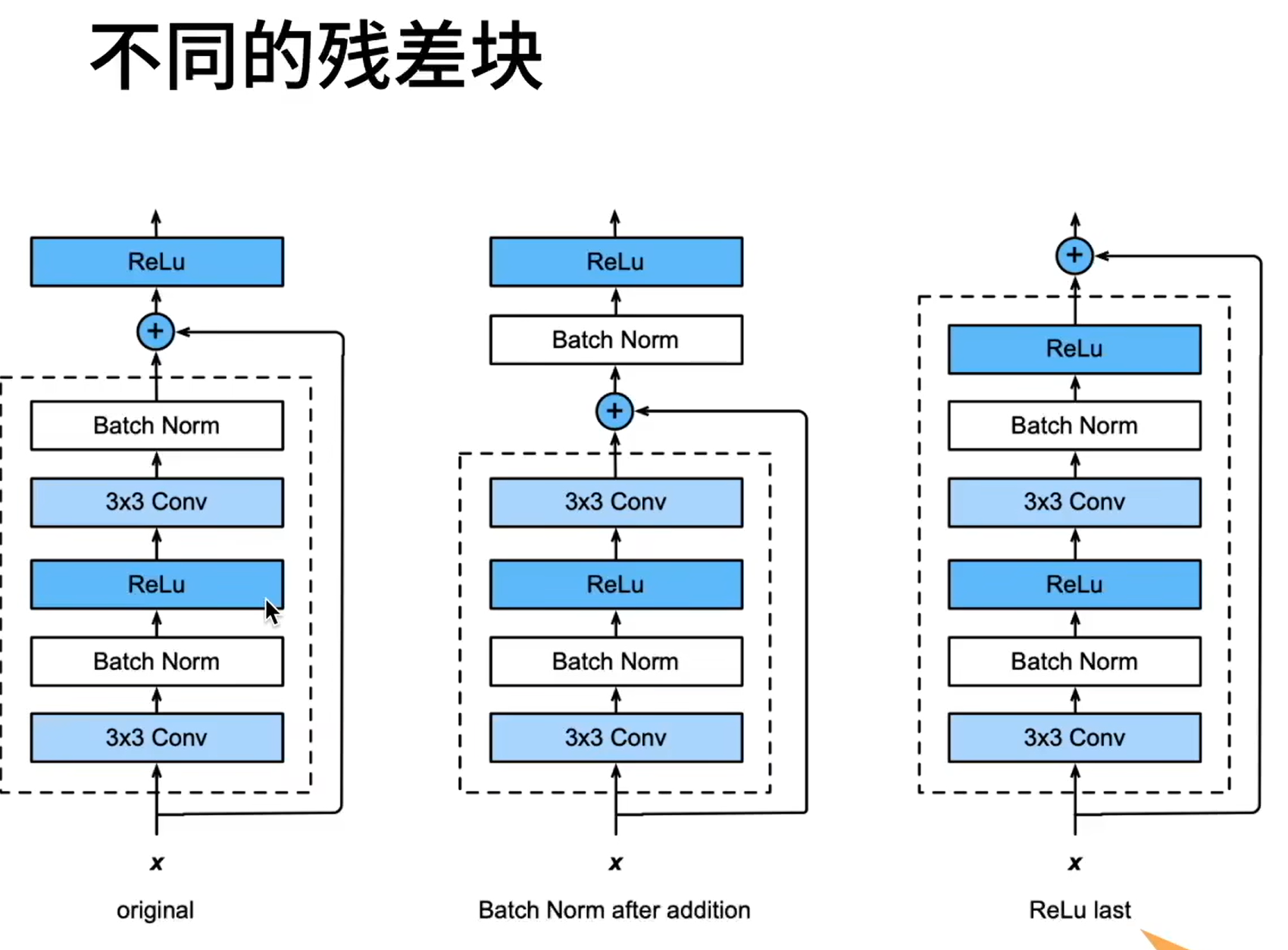
ResNet 最核心的是横着加过去的部分
# 使用 torchvision.models
# 分类模型
from torchvision.io import read_image | |
from torchvision.models import resnet50, ResNet50_Weights | |
# img 即为 tensor 类型了,torch.Size ([3, 1440, 1920]),但是数据的大小是图片自身的,没有归一到 [0,1] 上 | |
img = read_image(r"D:\Projects\pytorch-learn\Test6_mobilenet\images\falari.jpg") | |
# Step 1: Initialize model with the best available weights | |
weights = ResNet50_Weights.DEFAULT # 使用最佳权重 | |
model = resnet50(weights=weights) # 实例化模型,并使用预训练的参数 | |
model.eval() # 设置模型的预测模式,输入数据计算时不会改变梯度等参数 | |
# Step 2: Initialize the inference transforms | |
preprocess = weights.transforms() # 实例化推理变换 | |
# Step 3: Apply inference preprocessing transforms | |
# preprocess (img) # 对图片的 w 和 h 进行变换,使得能够输入网络中进行处理 | |
# unsqueeze (0), 在第一维度处插入一维,因为要向网络中插入 4 维的 | |
batch = preprocess(img).unsqueeze(0) | |
# Step 4: Use the model and print the predicted category | |
# model (batch) 得到 torch.Size ([1, 1000]) | |
# squeeze (0) 去掉第一维 | |
prediction = model(batch).squeeze(0).softmax(0) | |
class_id = prediction.argmax().item() # argmax () 返回的是 Tensor,使用 item () 取出其中的值 | |
score = prediction[class_id].item() | |
category_name = weights.meta["categories"][class_id] # 获得分类的名字 | |
print(f"{category_name}: {100 * score:.1f}%") |
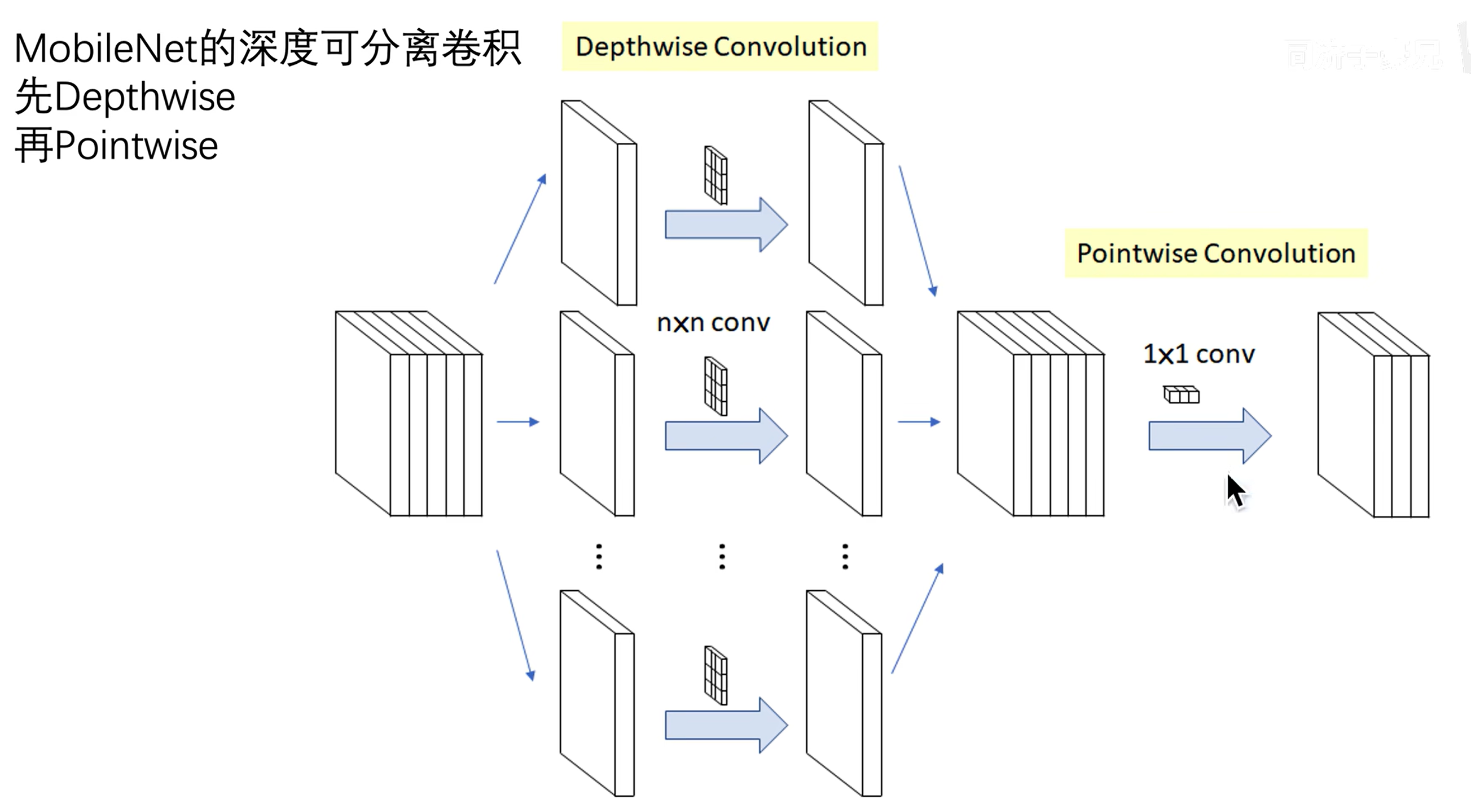
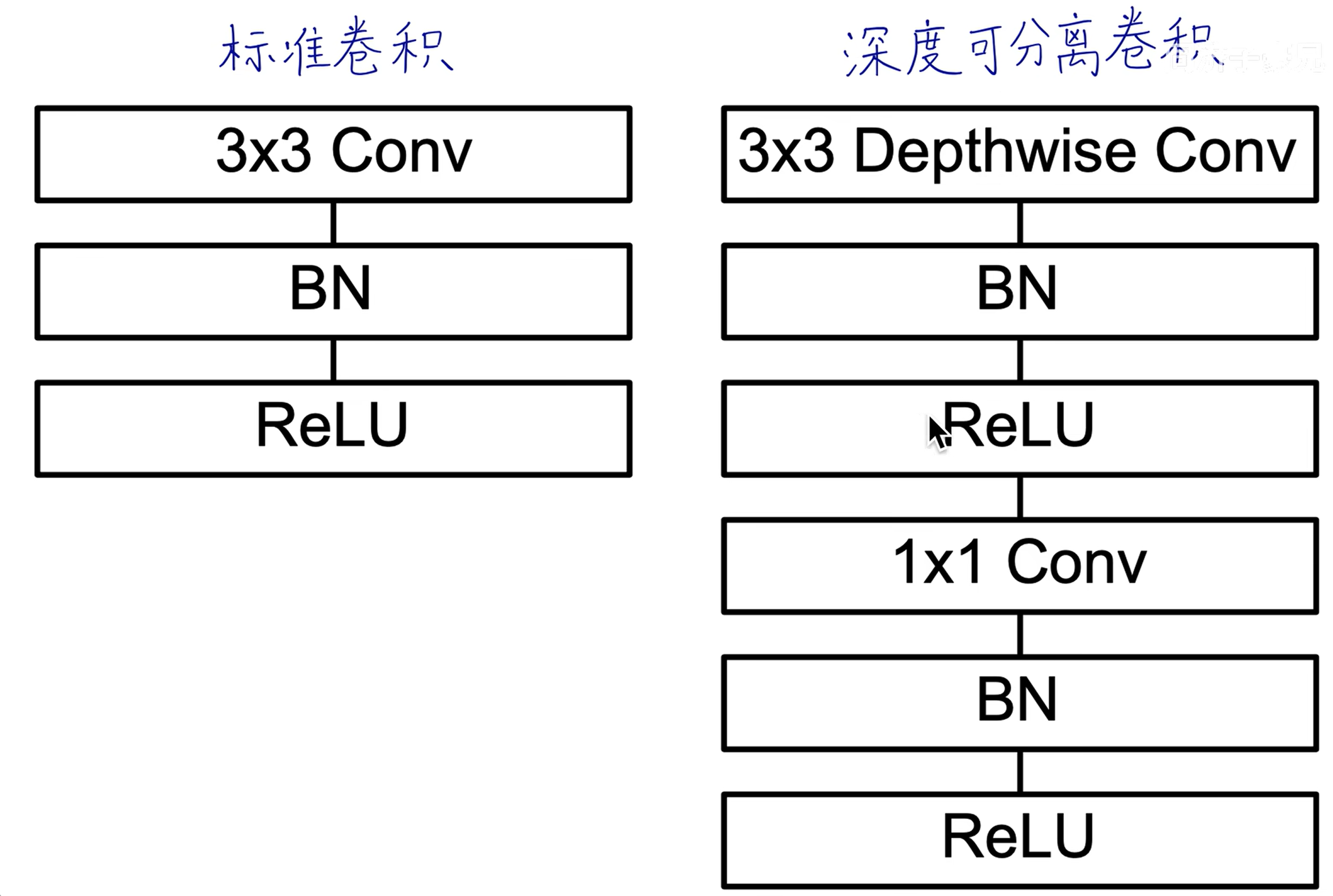
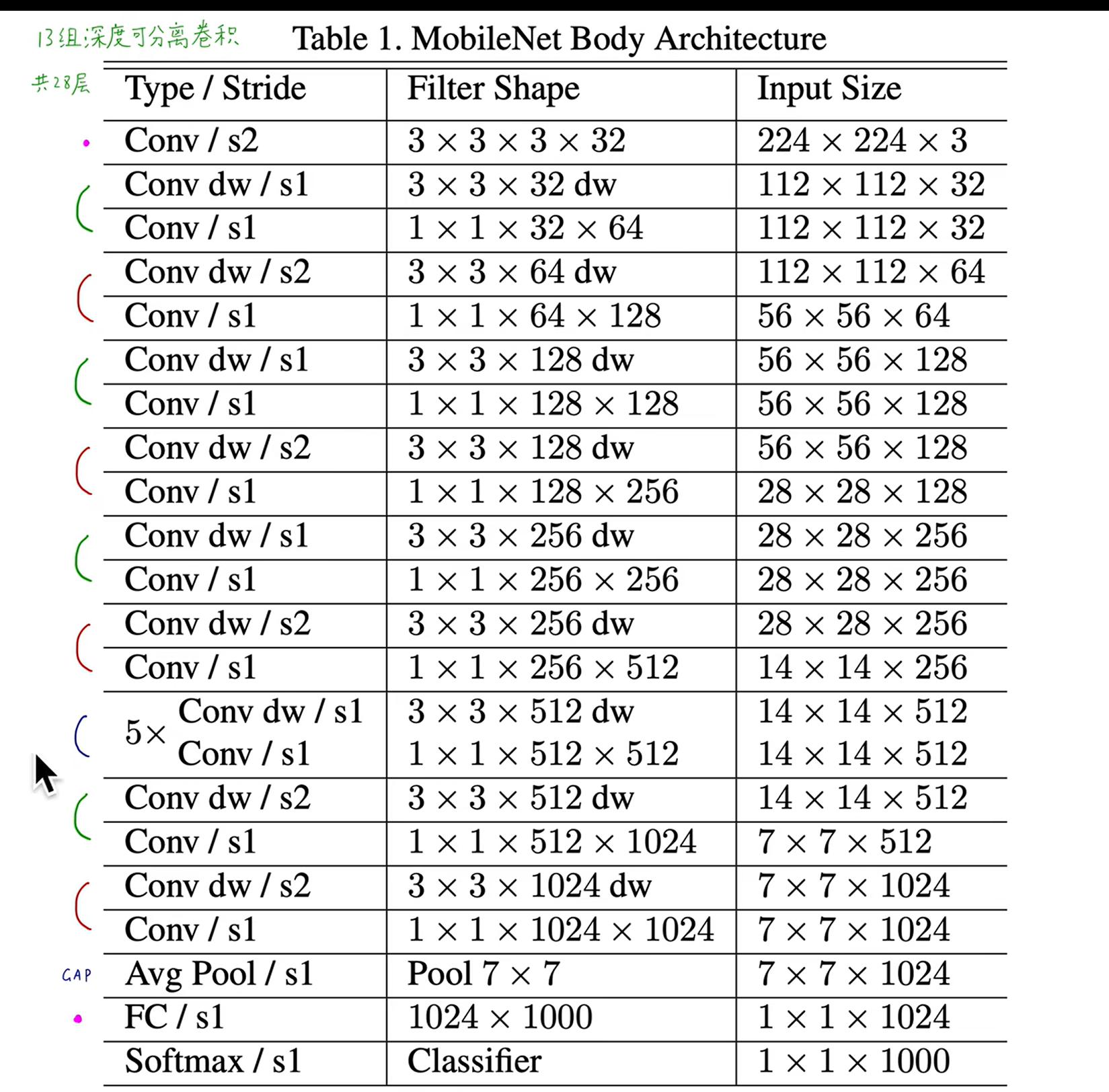
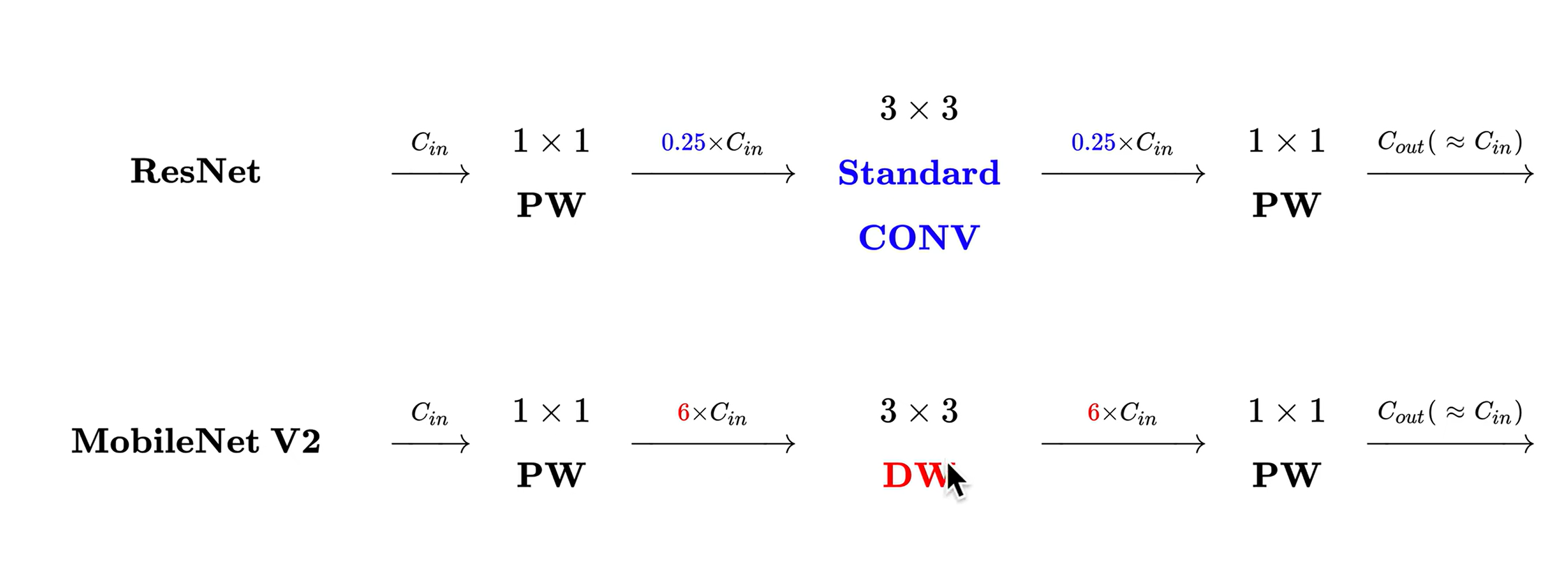
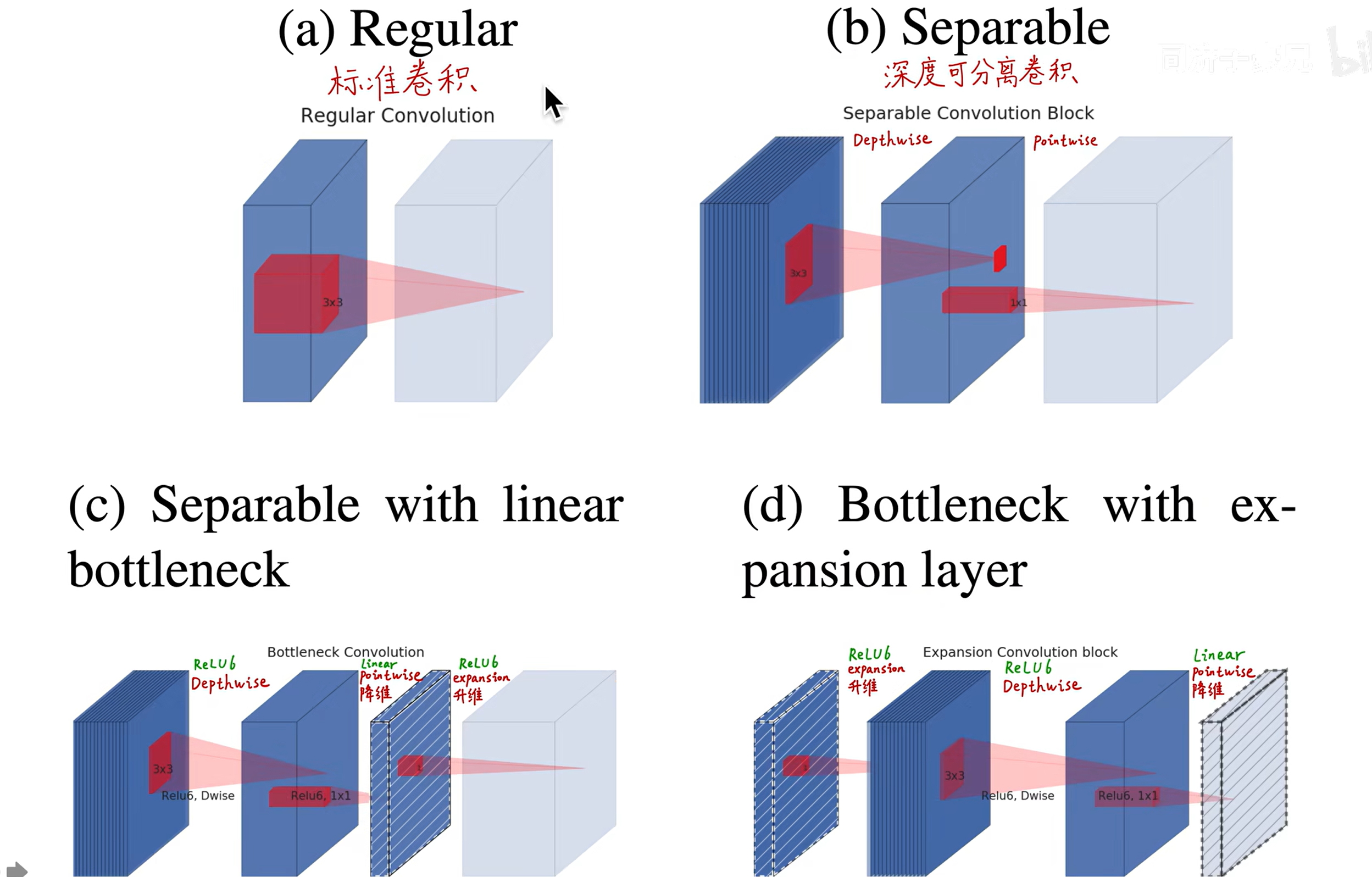
# MobileNet v1
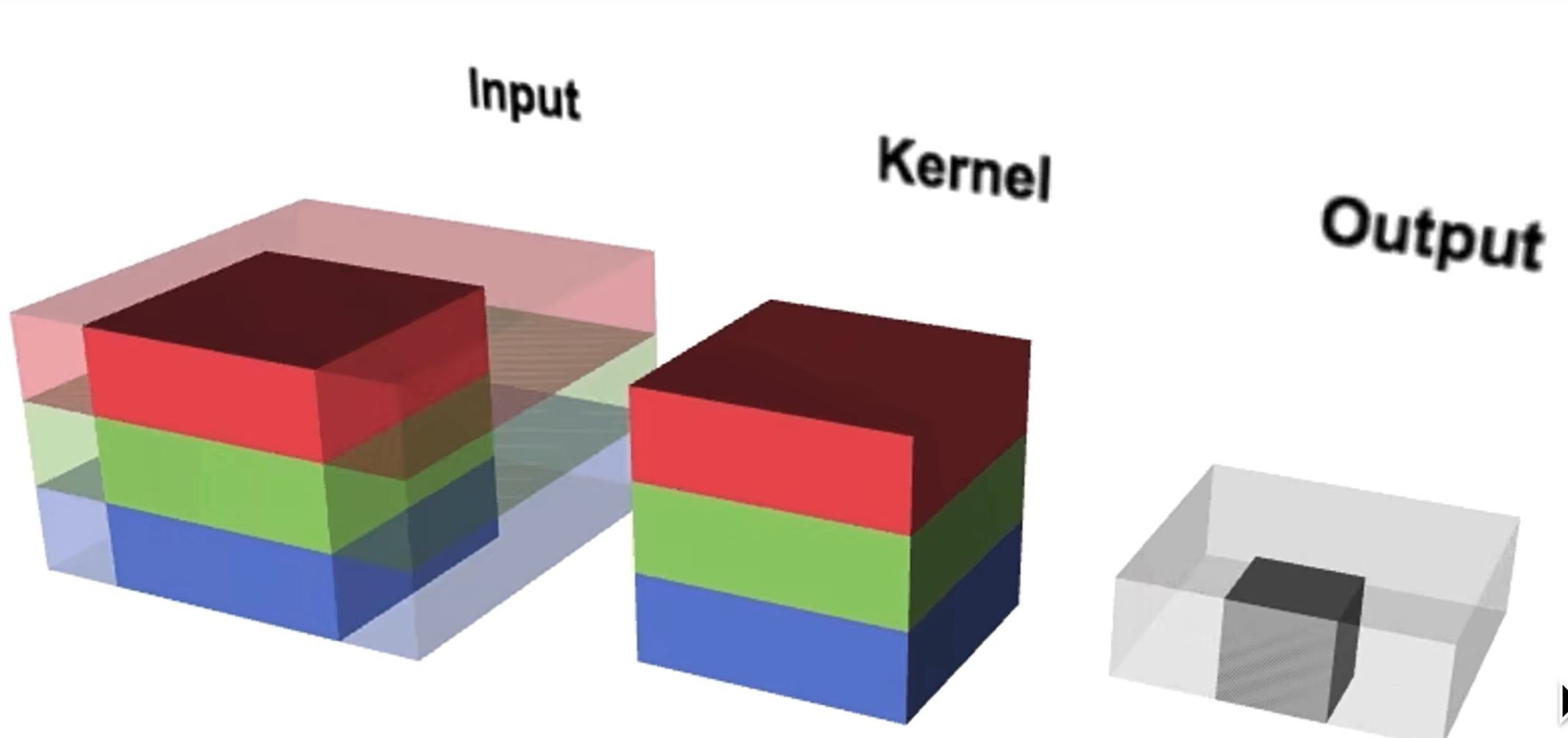
# 传统卷积
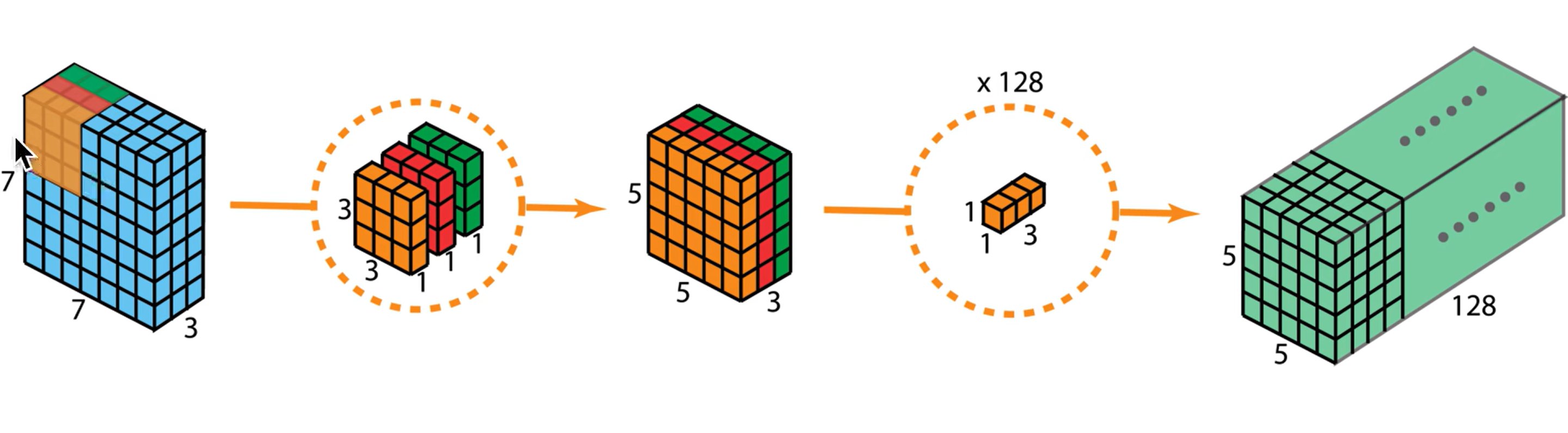
传统的卷积:一个卷积核生成一个 feature map(二维),
卷积核的深度和图像的通道数相同,相乘再相加。
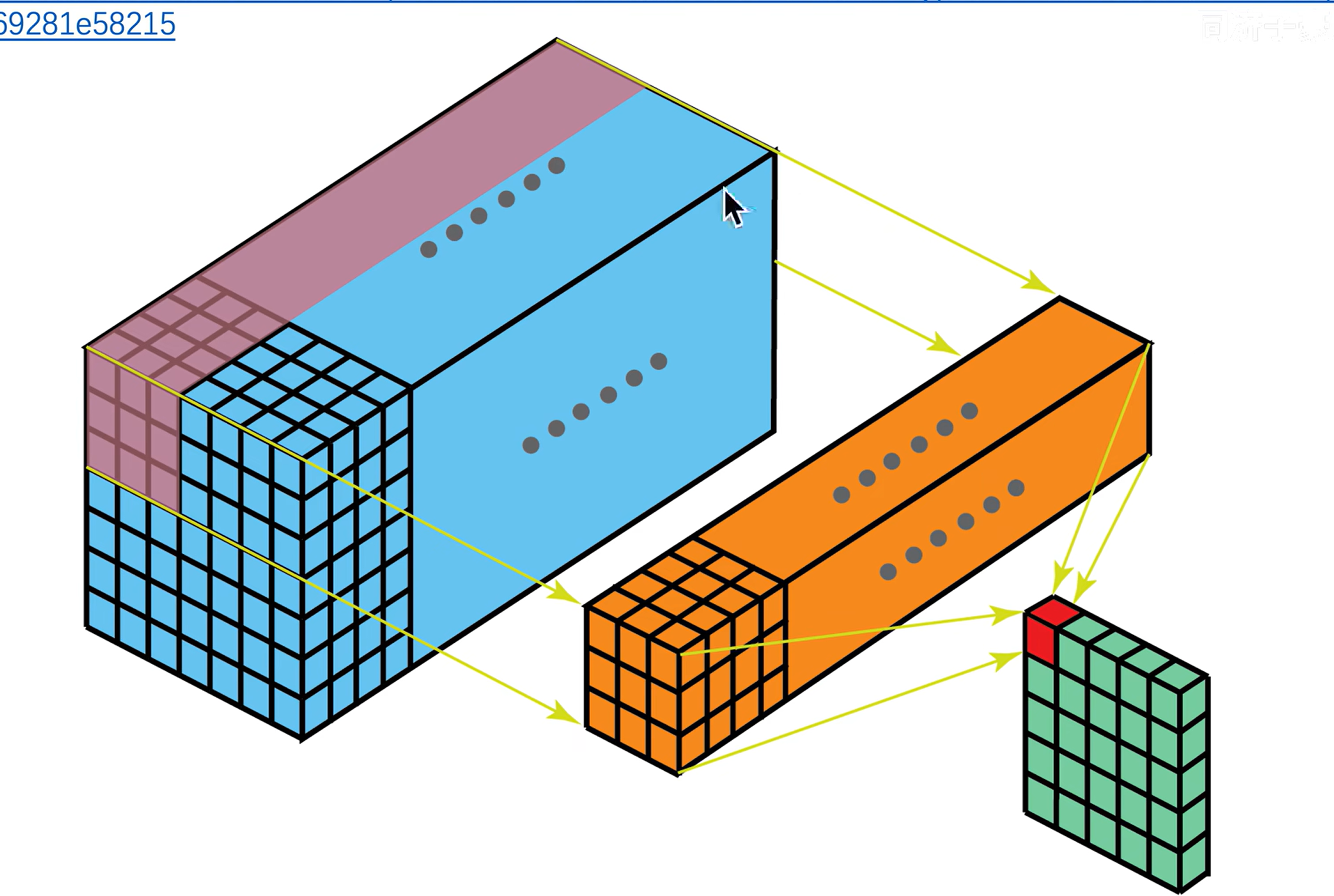
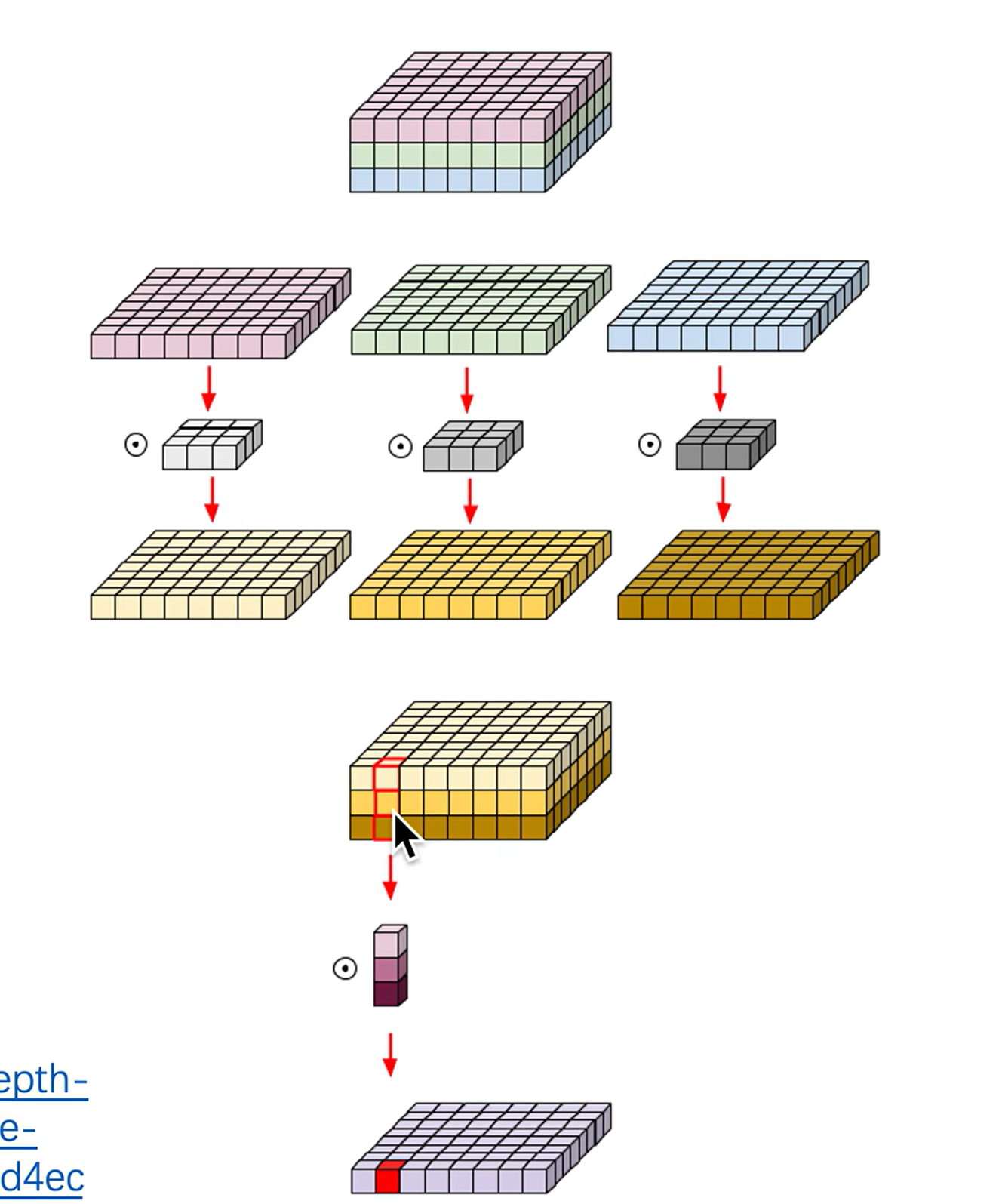
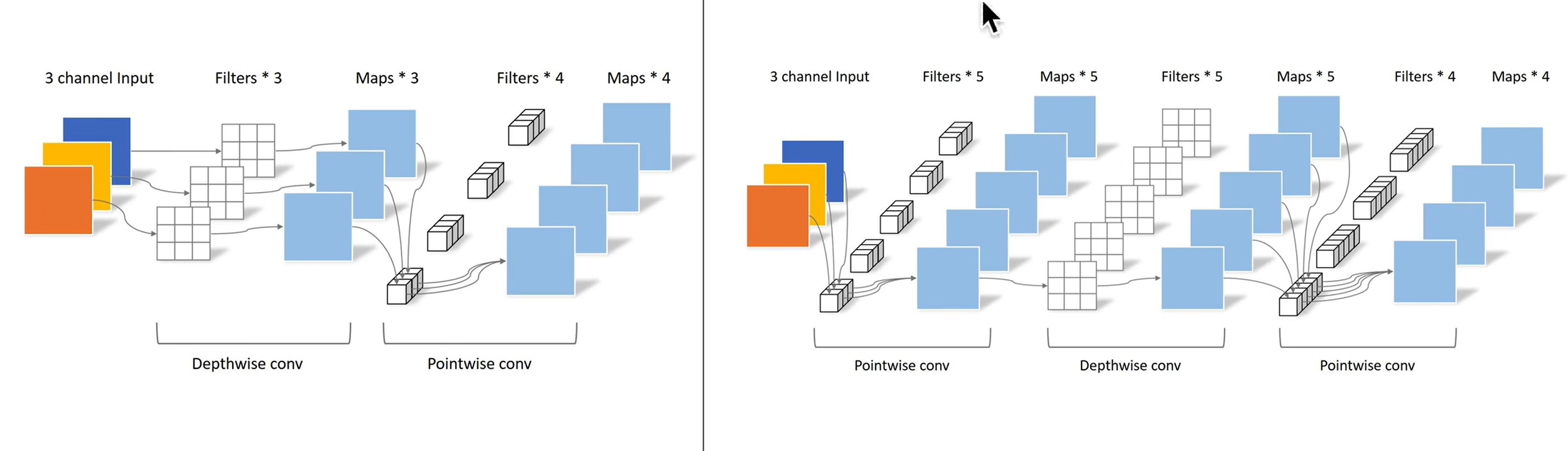
# 深度可分离卷积
每一个通道用单独的卷积核(二维)进行处理,此时无法再捕捉跨通道的信息了。所以再使用 1x1 的卷积核处理跨通道的信息。
DW:处理长宽方向的信息
PW:处理跨通道的信息
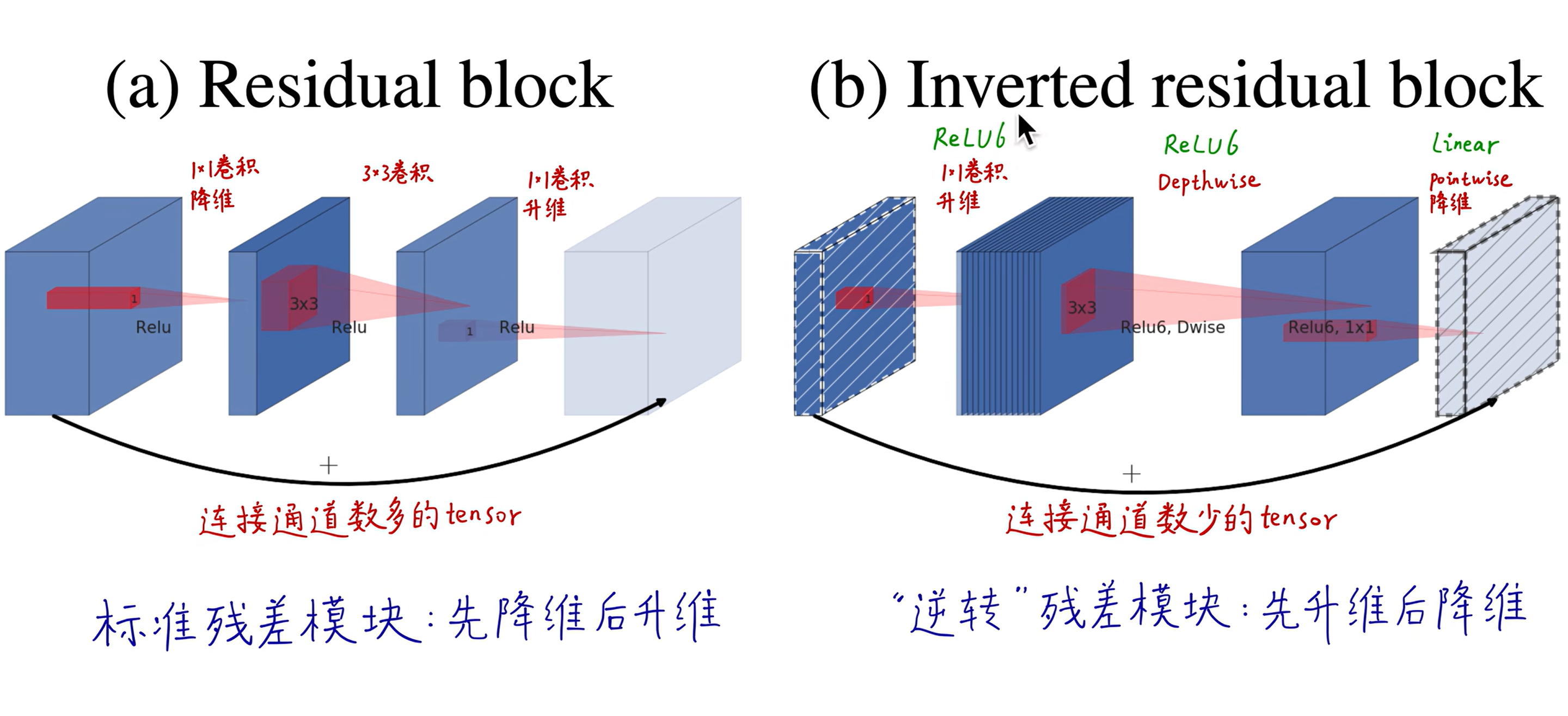
# Mobile Net v2
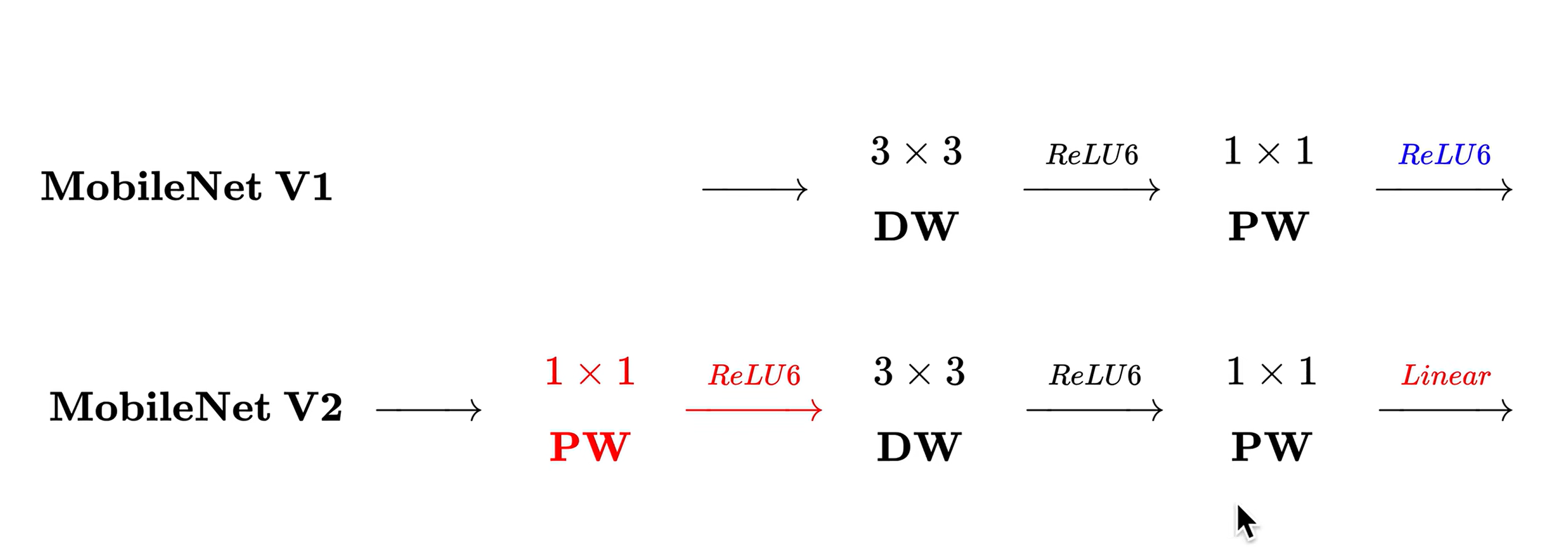
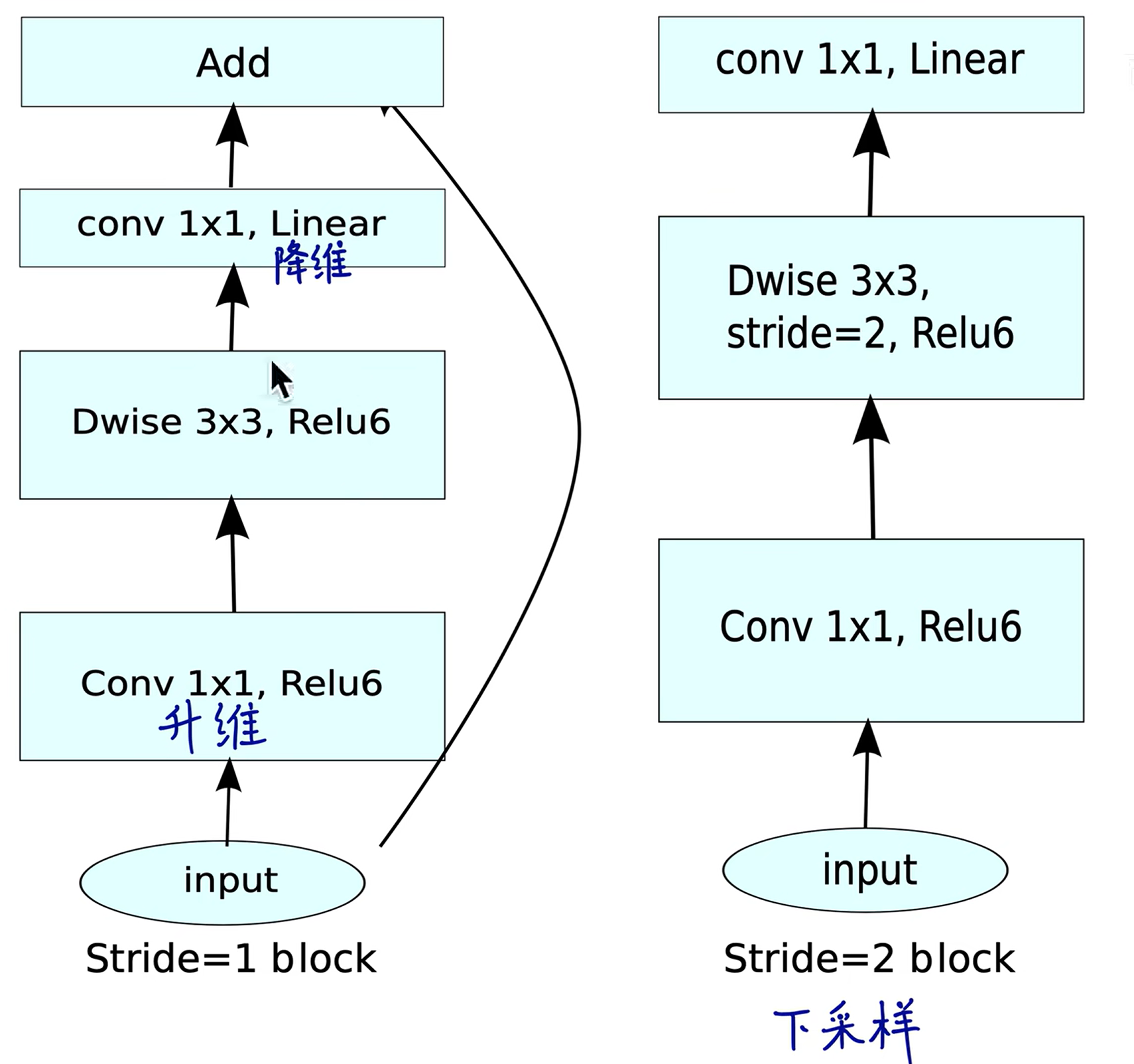 short cut 连接为残差连接,左边连接的是两个低维的
short cut 连接为残差连接,左边连接的是两个低维的
因为使用了下采样,导致,所以不用残差连接了

在降维时用的线性激活函数
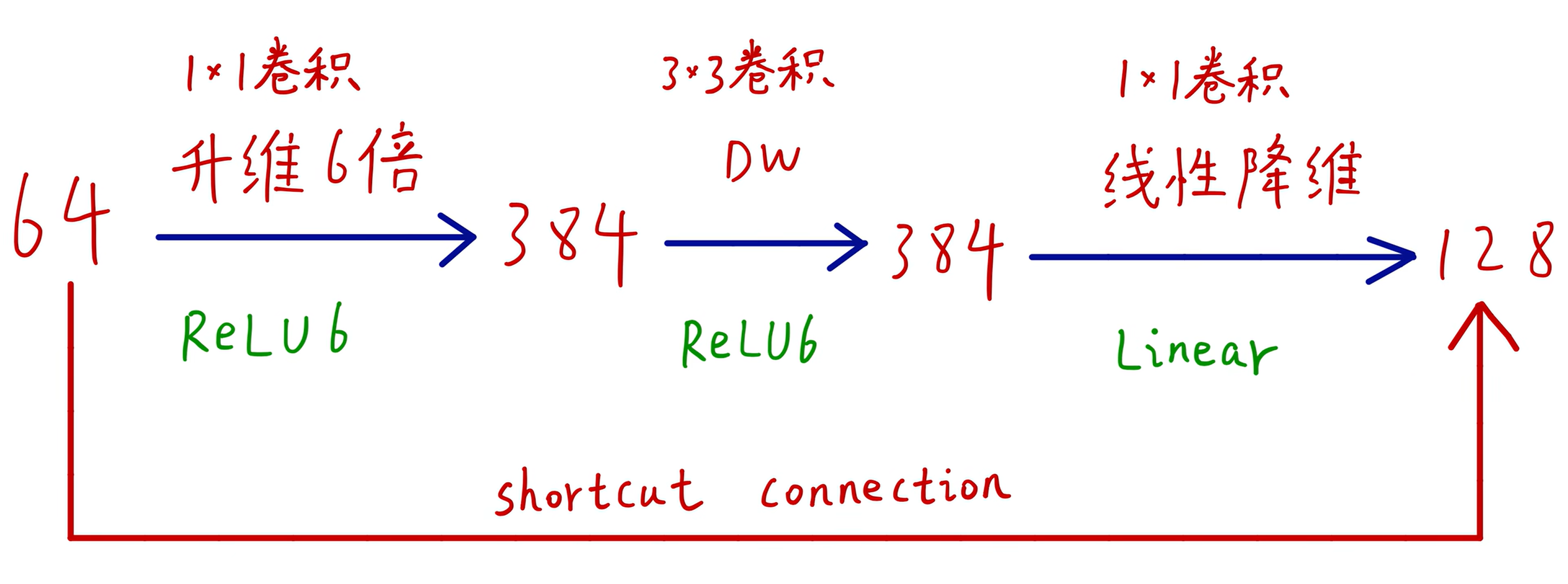
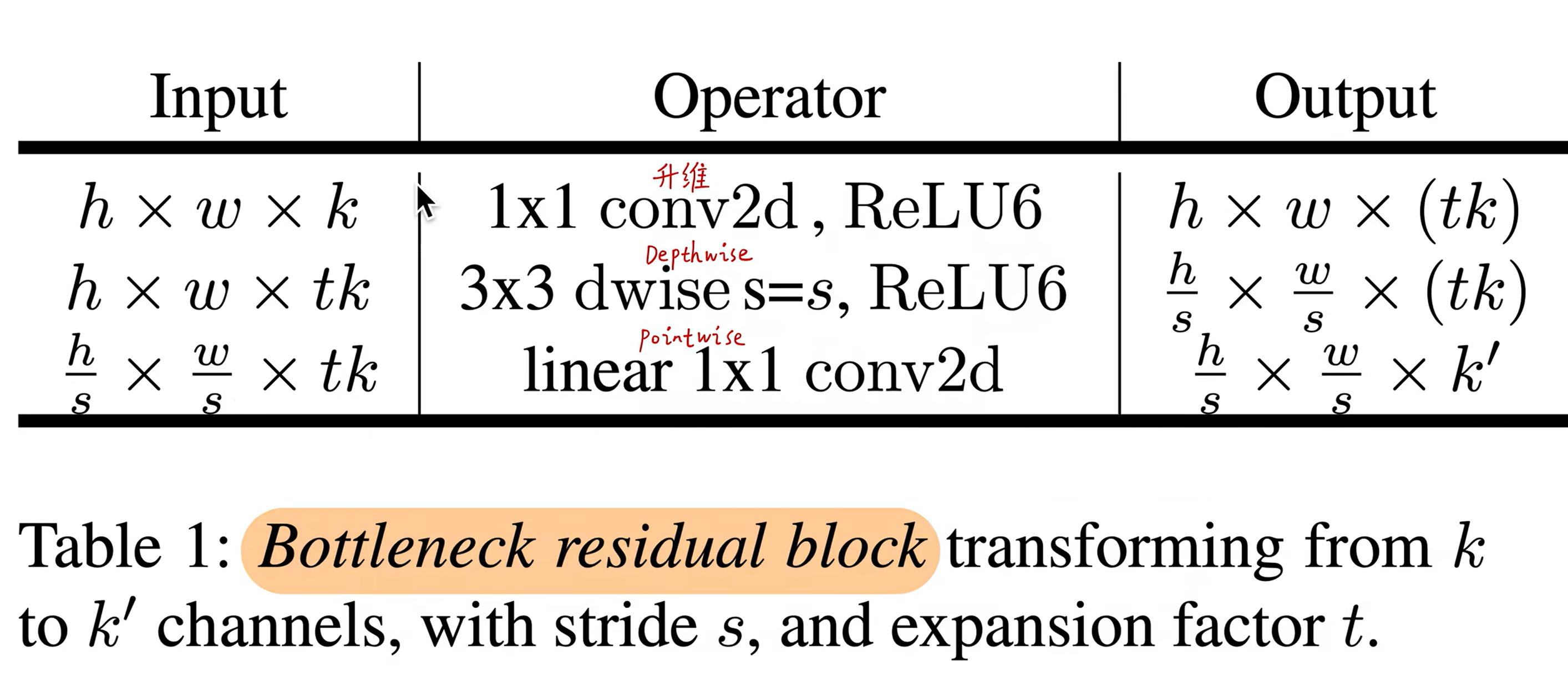

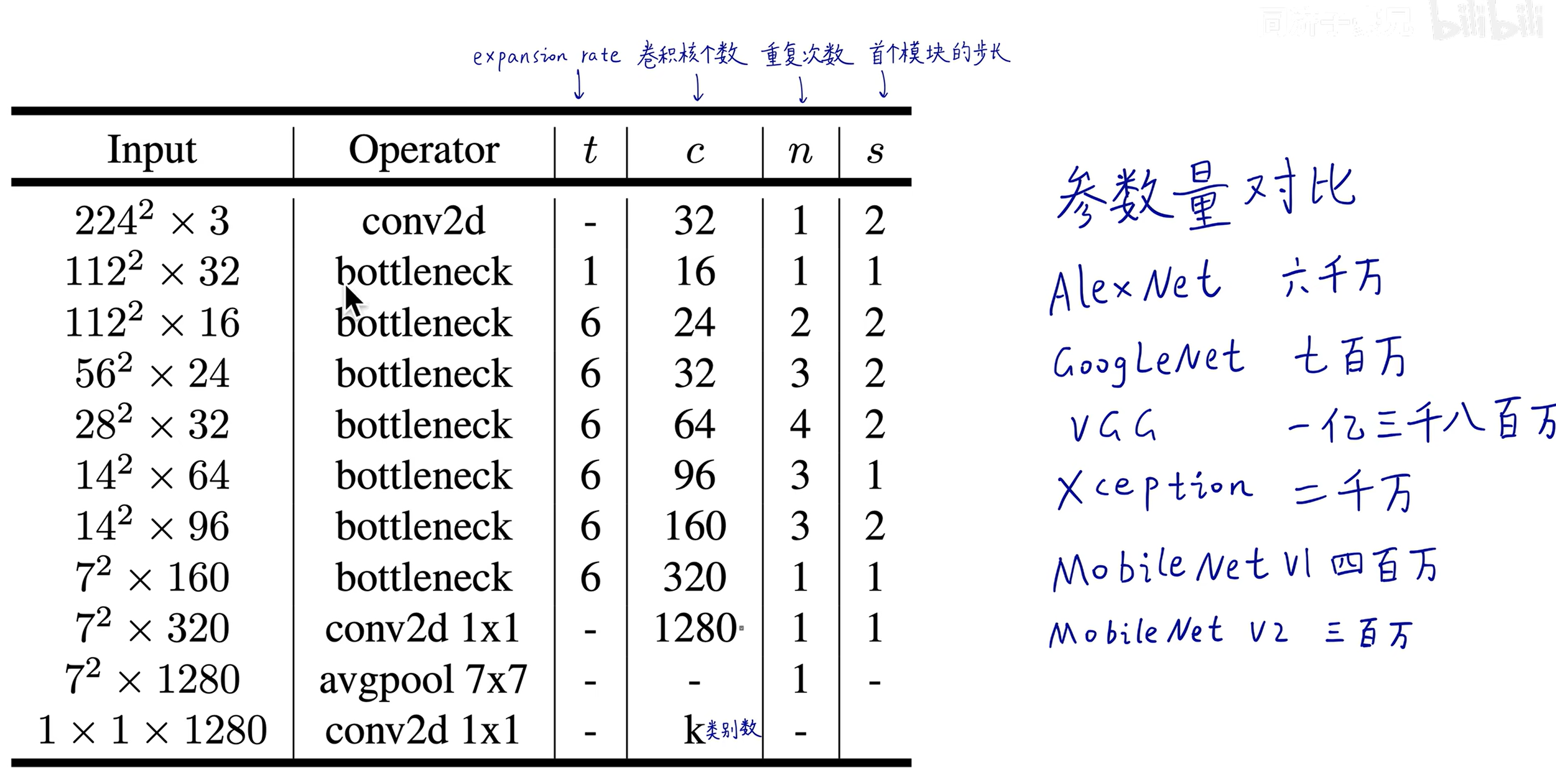
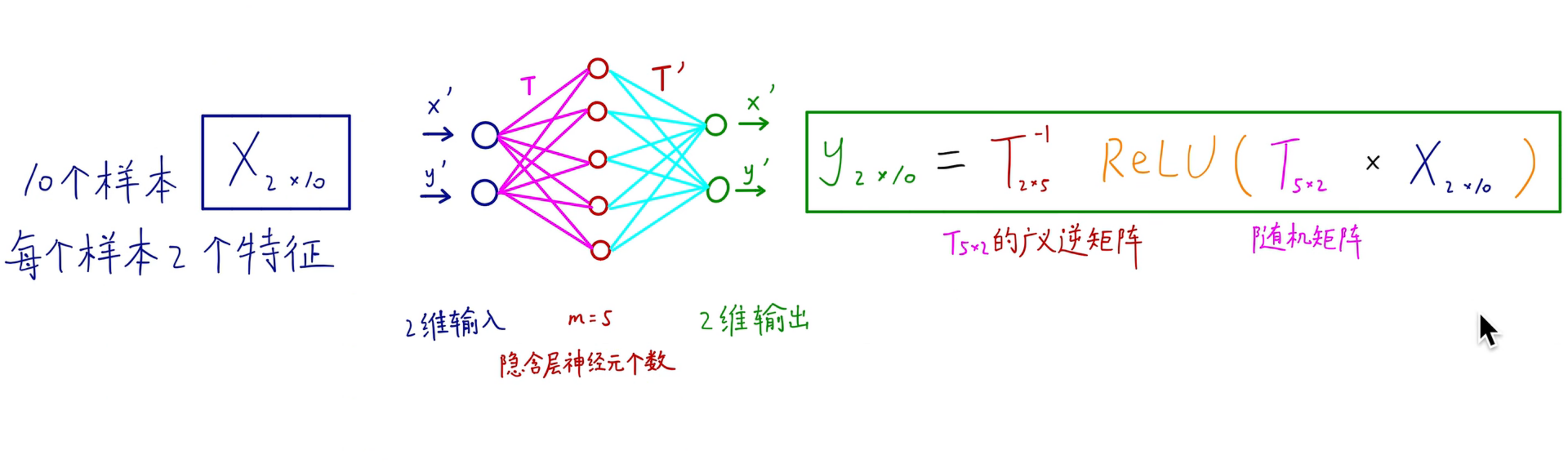
# 升维的数学原理


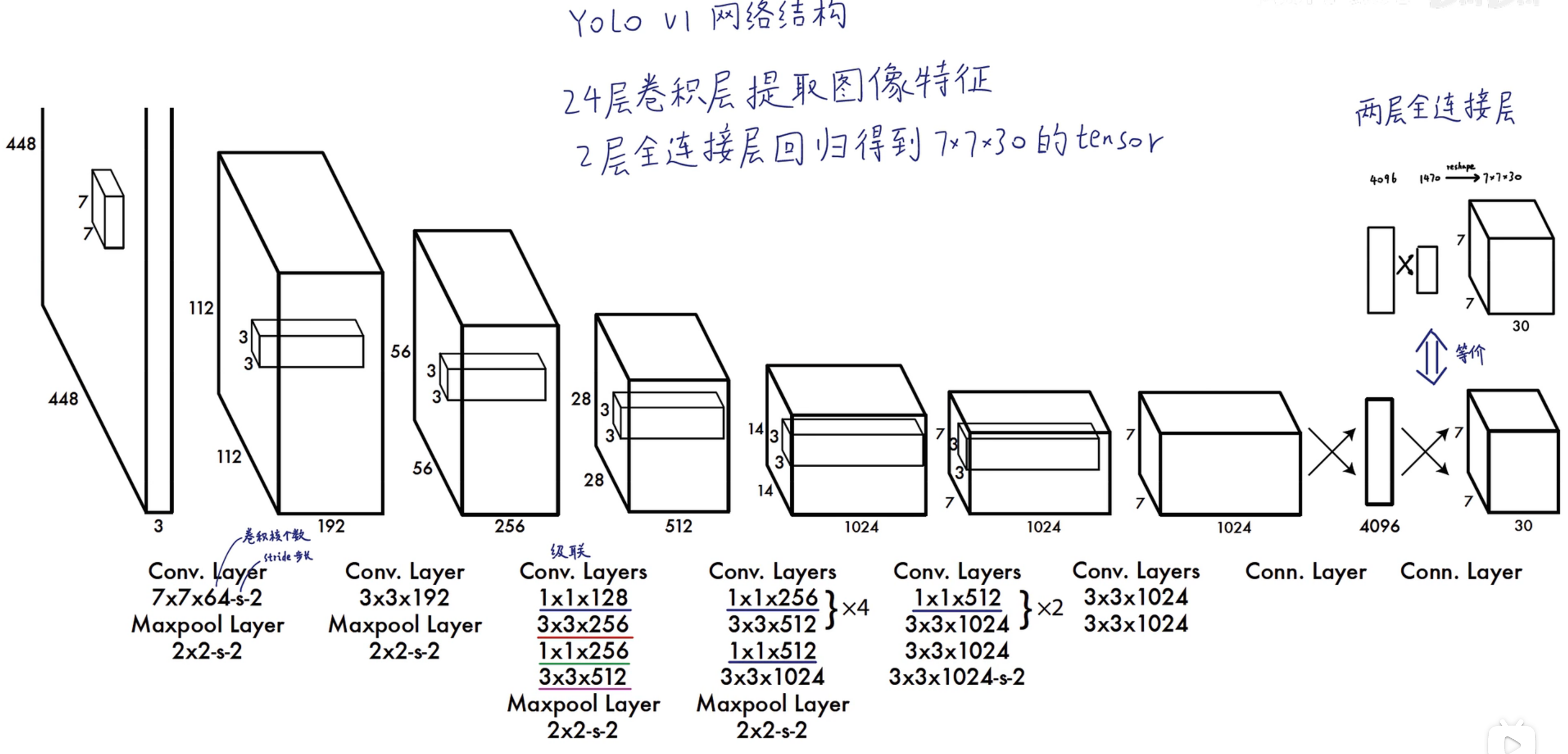
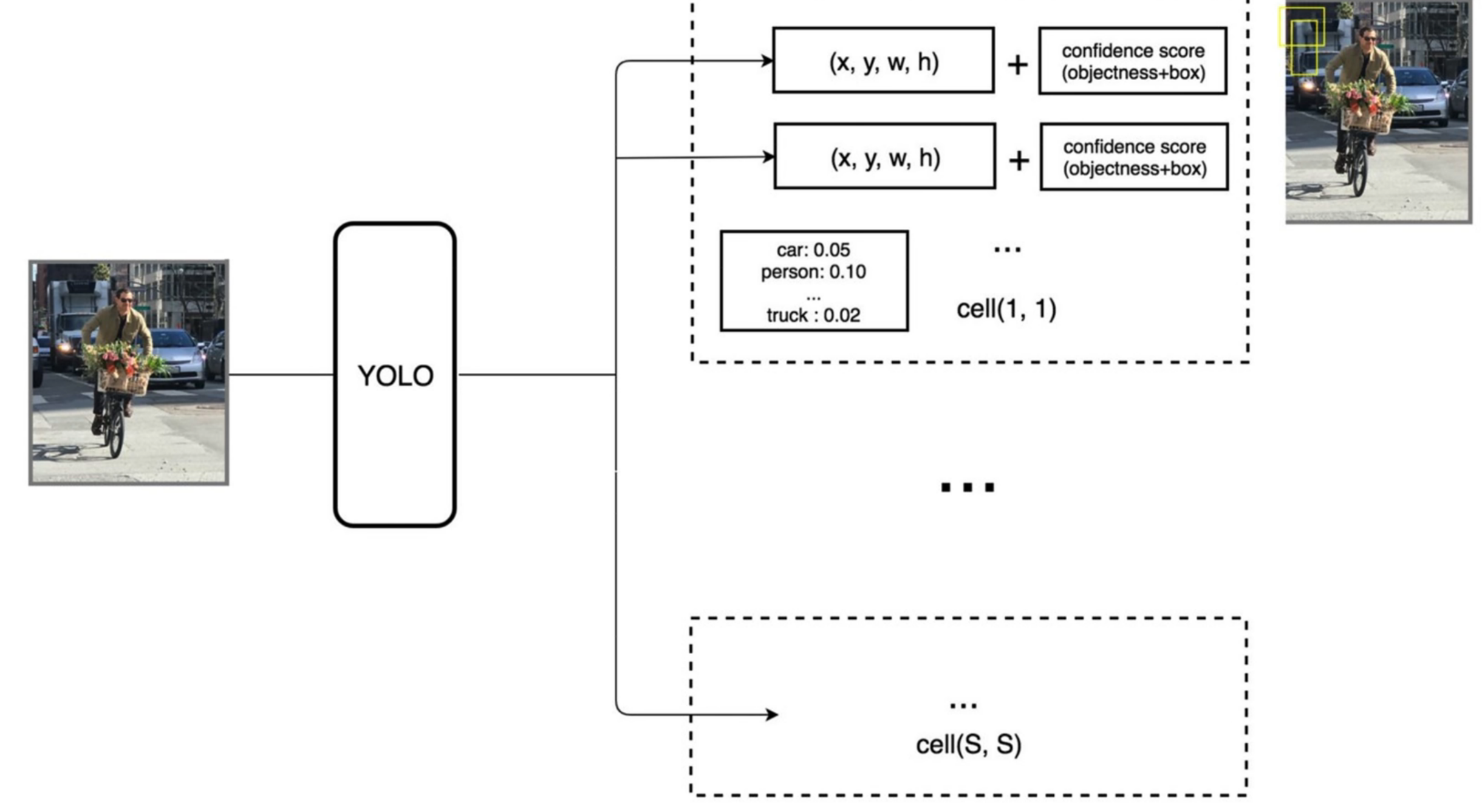
# yolov1
# 预测阶段
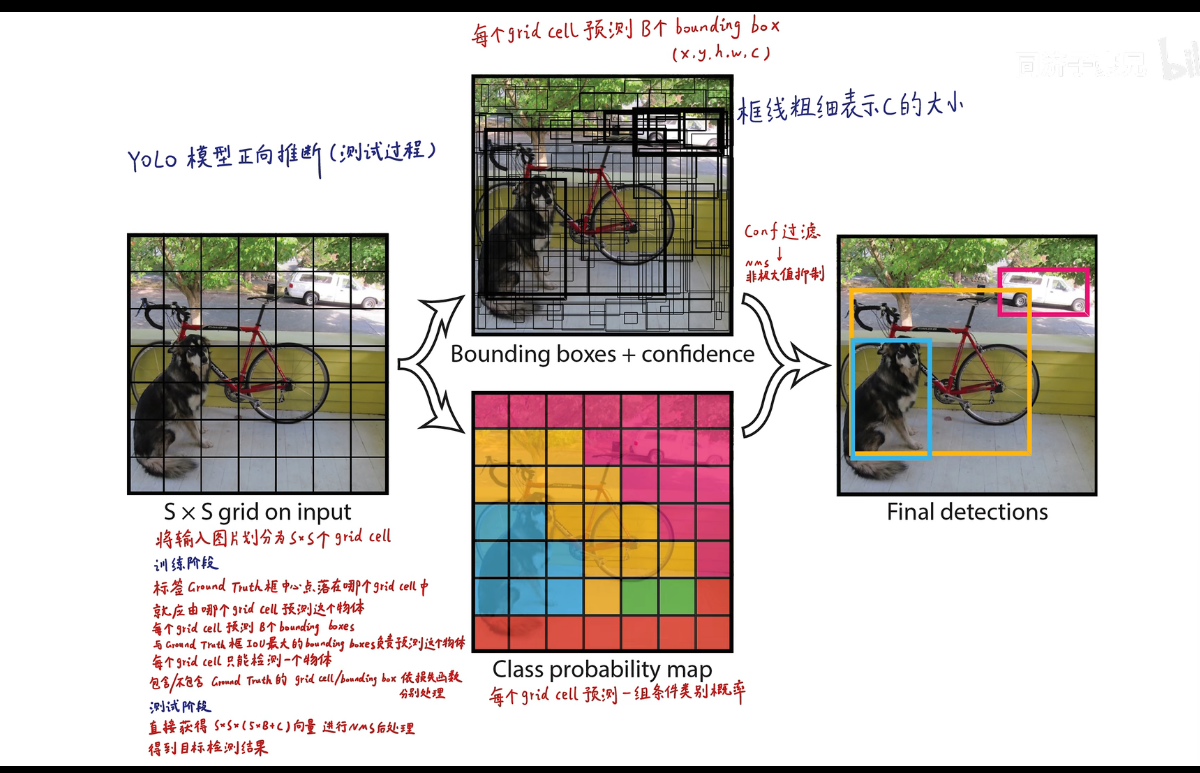
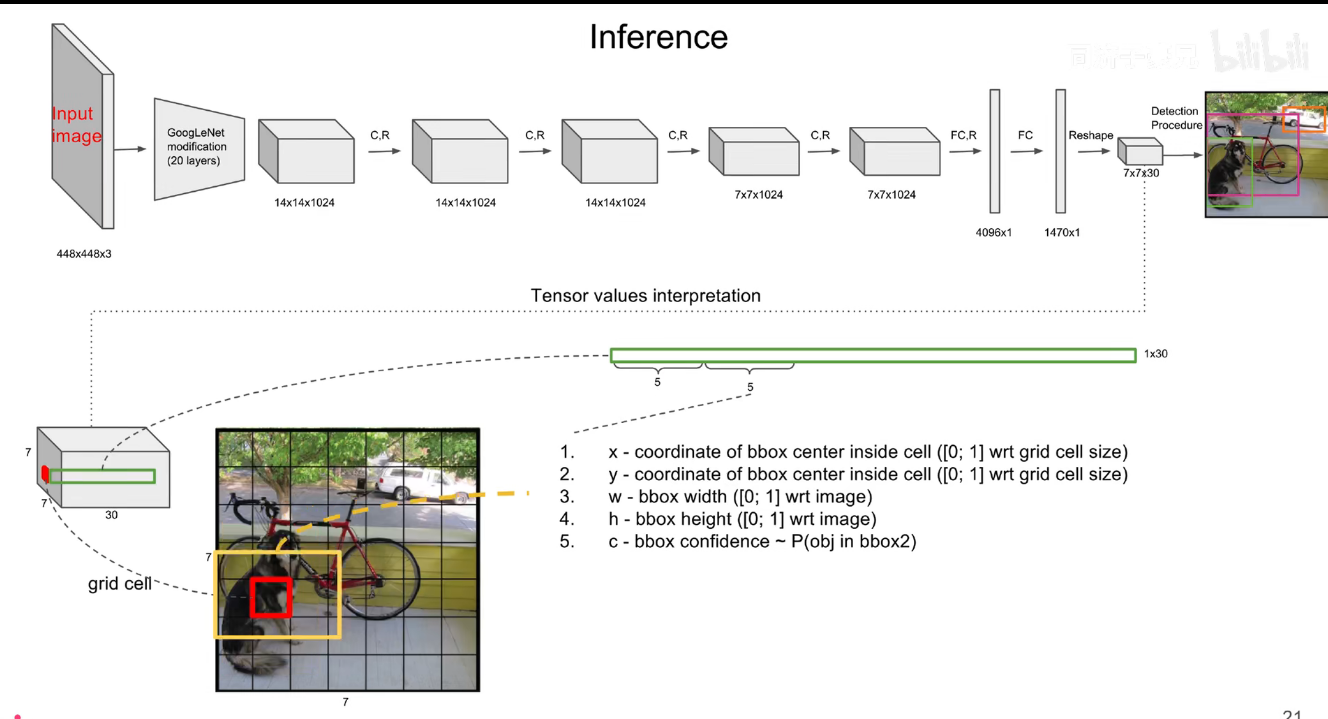
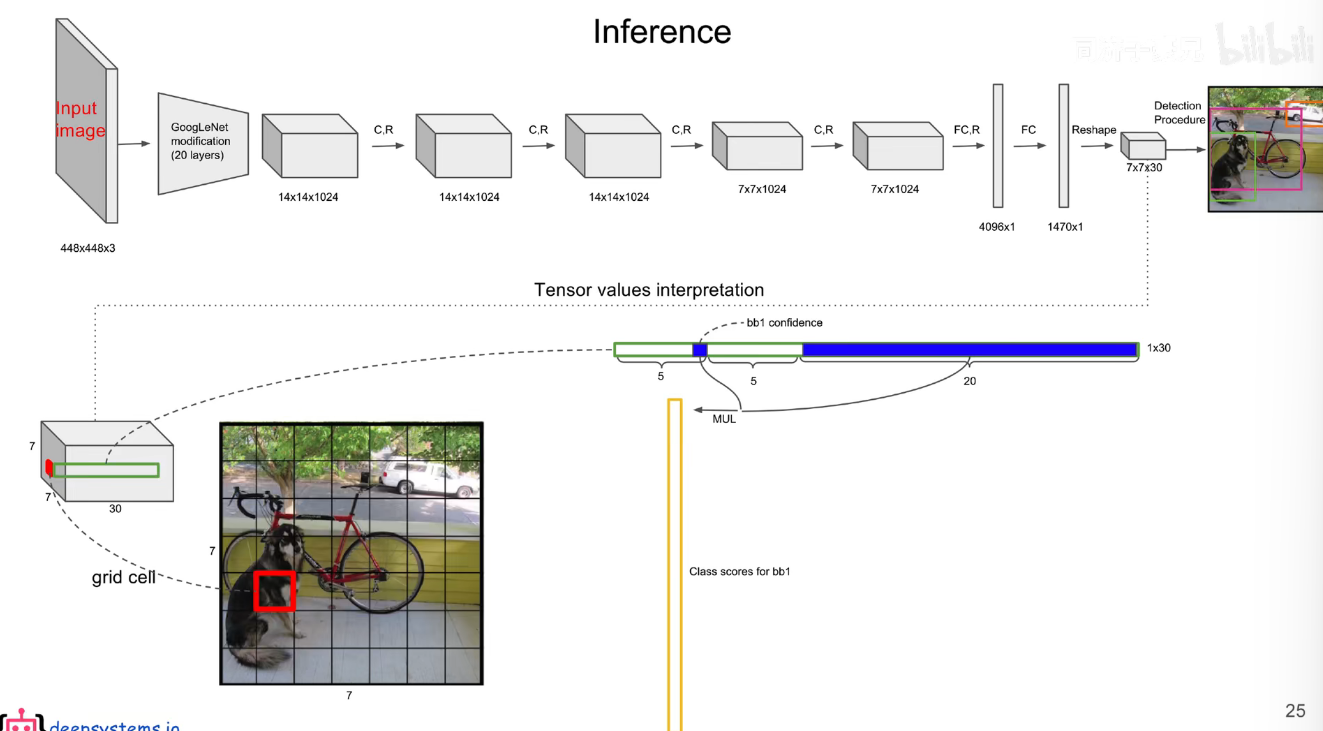
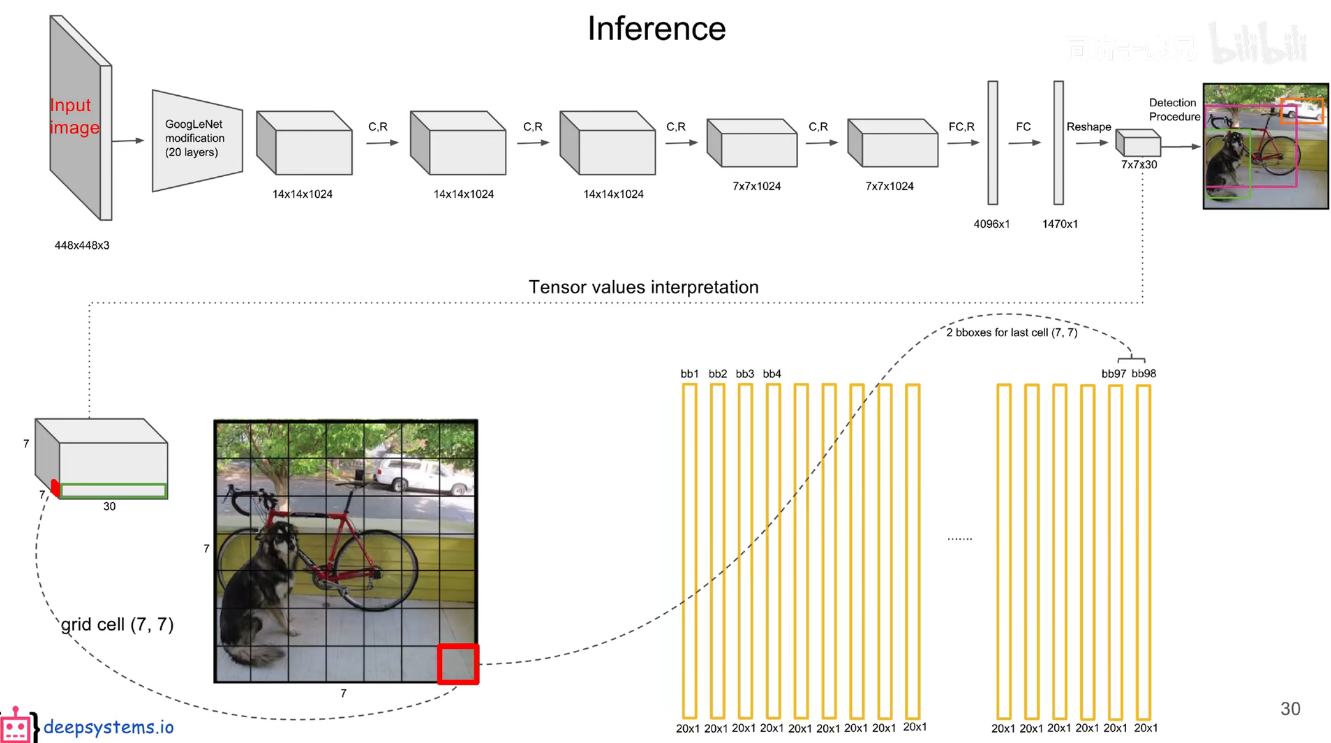
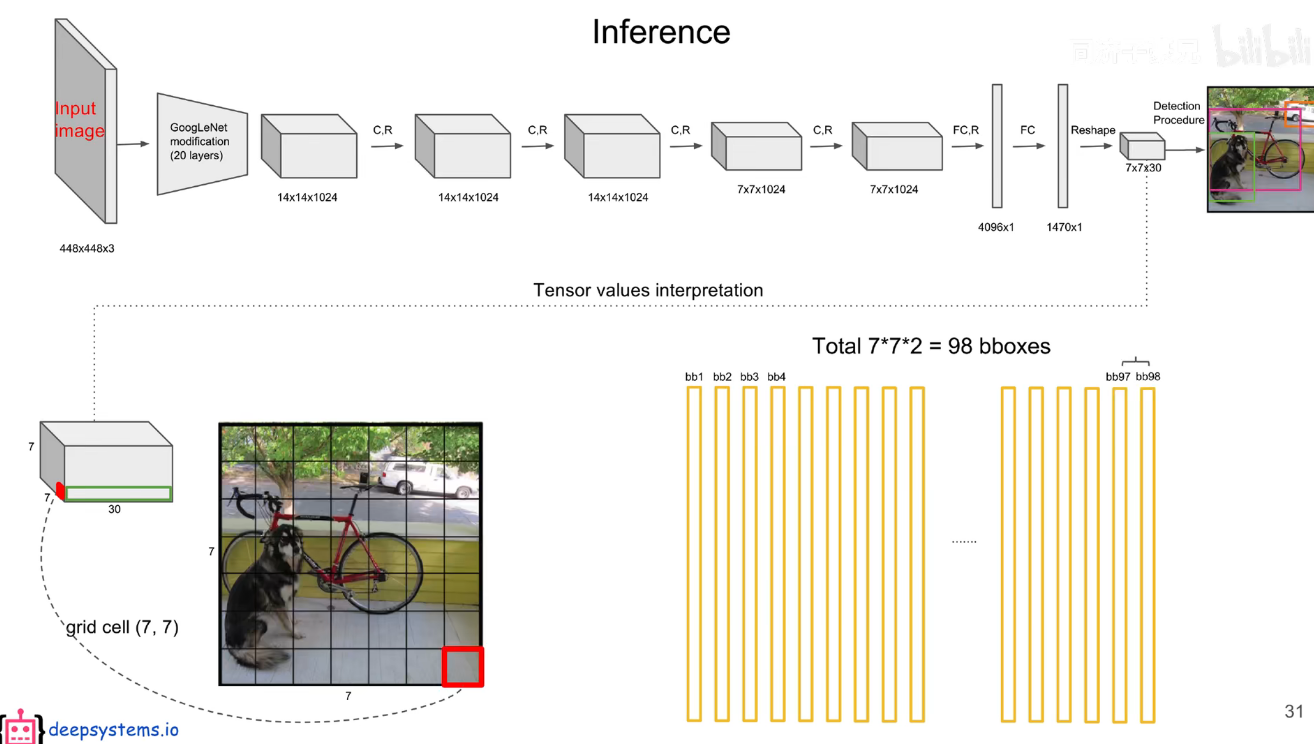
最后的 7x7x30 的张量中,包含了所有预测框的坐标,置信度和类别结果。只要解析这个张量就可以获得结果了。
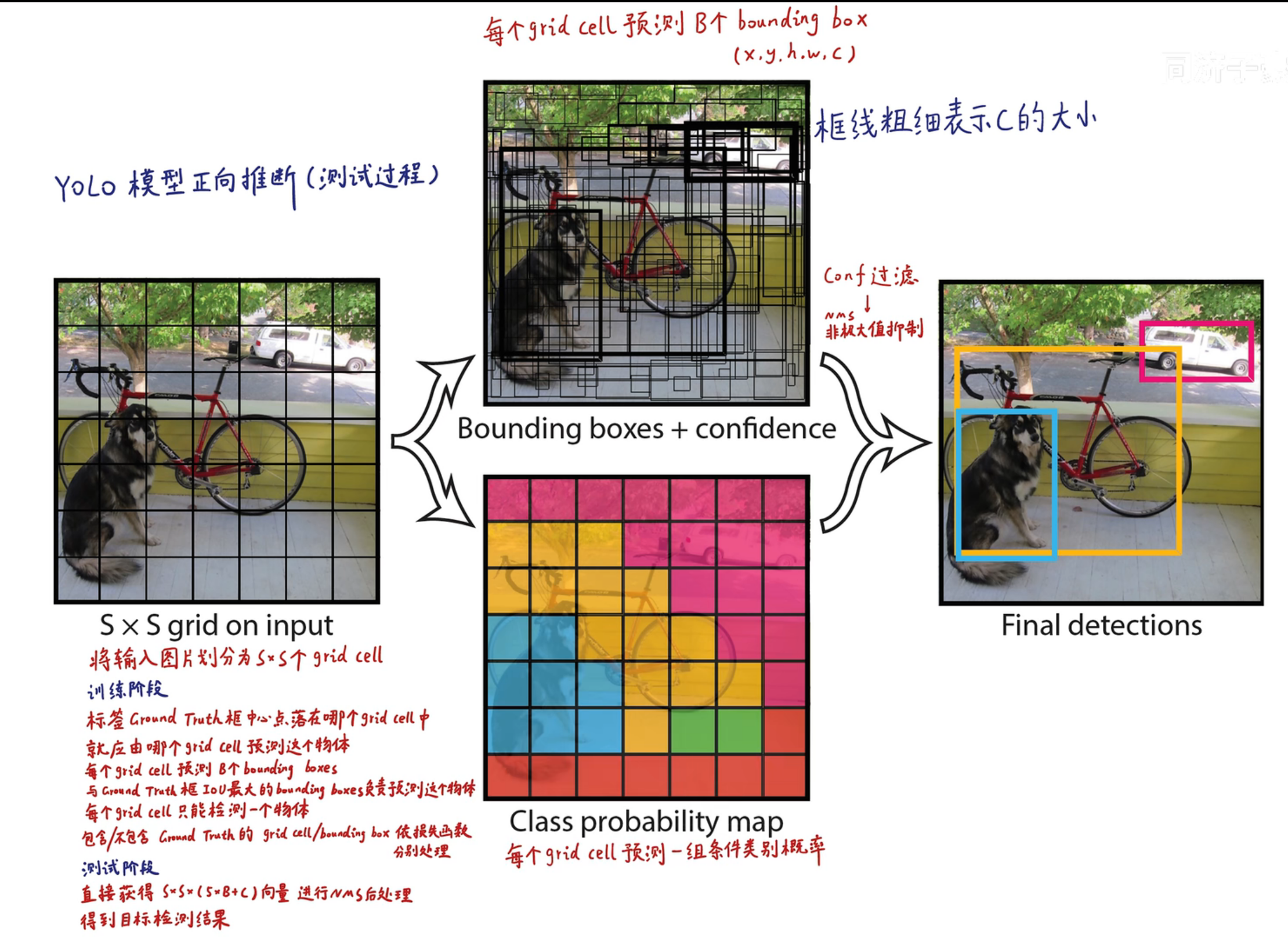
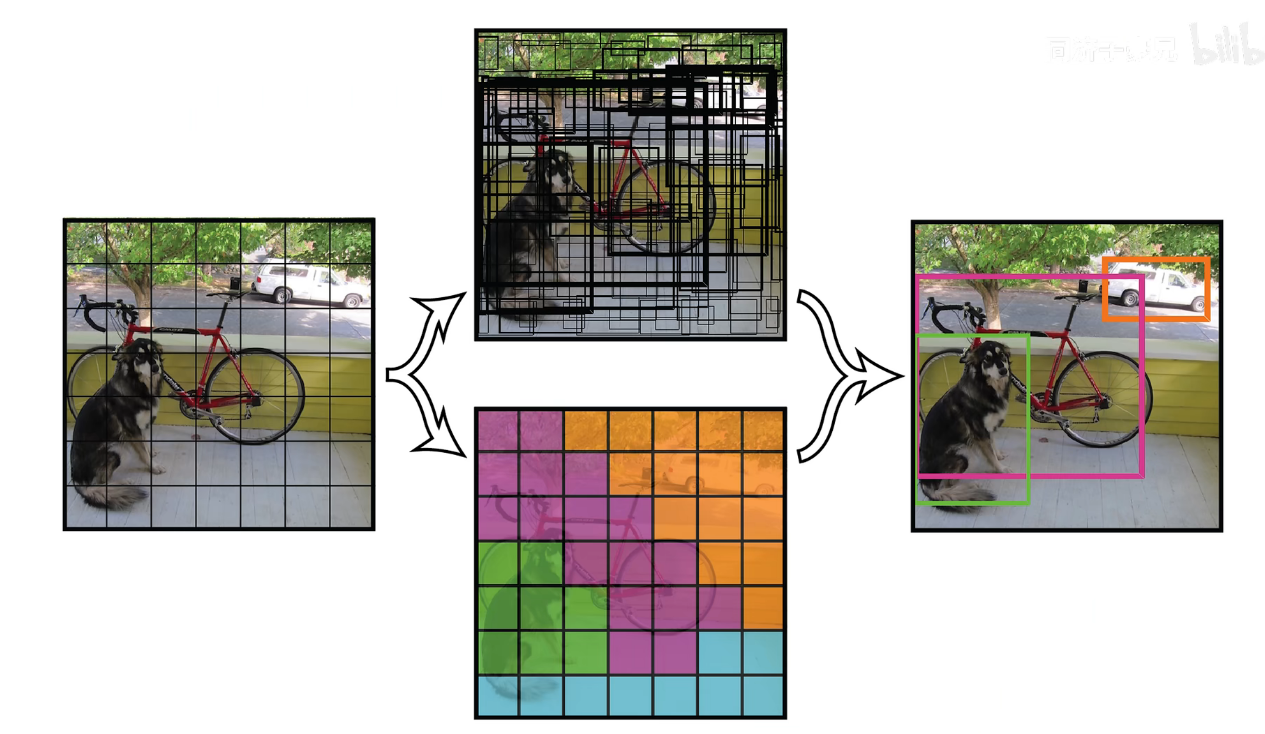
在 yolov1 中 s=7,bounding box 为预测框,只要预测框的中心点落在 grid cell 里,那么久说明这个 bounding box 是有这个 grid cell 生成的。
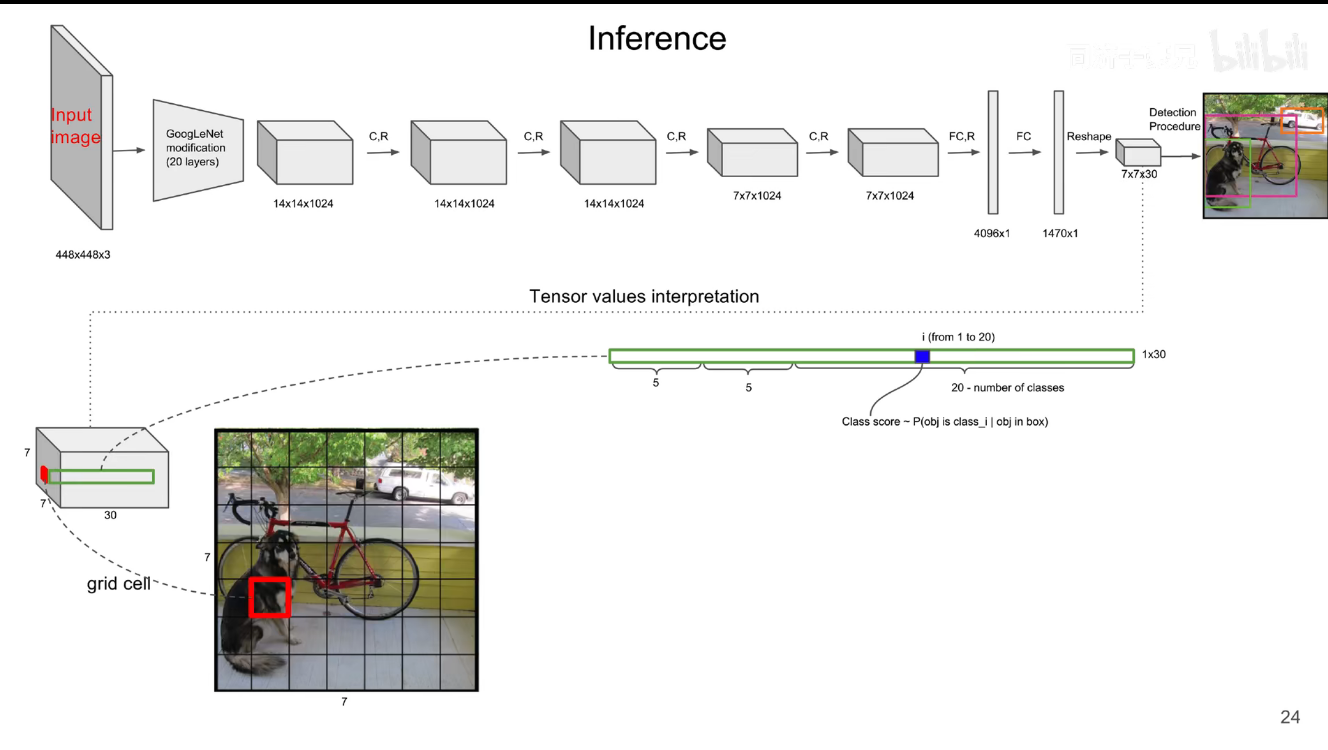
每个 bounding box 的置信度 * 类别的条件概率就能获得 bounding box 各类别的概率。

在假设包含猫的时候是猫的概率... 所以是条件概率,所以每个 bounding box 的置信度 * 类别的条件概率就能获得 bounding box 各类别的概率。




上图中的下面的两个框的置信度就比较低
下面展示了条件概率最高的那些类别所占有的框

选择概率高的,每个 grid cell 只能有一个类别,即只能预测出一个物体。这也是 yolov1 小目标和密集目标识别性能差的原因。
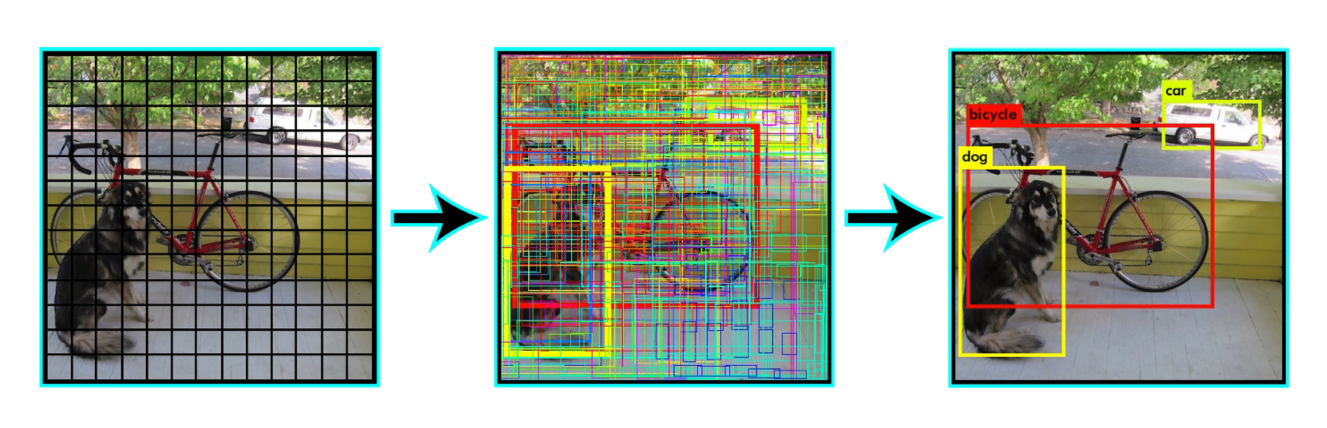
# 预测阶段 后处理

把预测框筛选、过滤,把重复的预测框只保留一个,过滤掉低置信度的框,
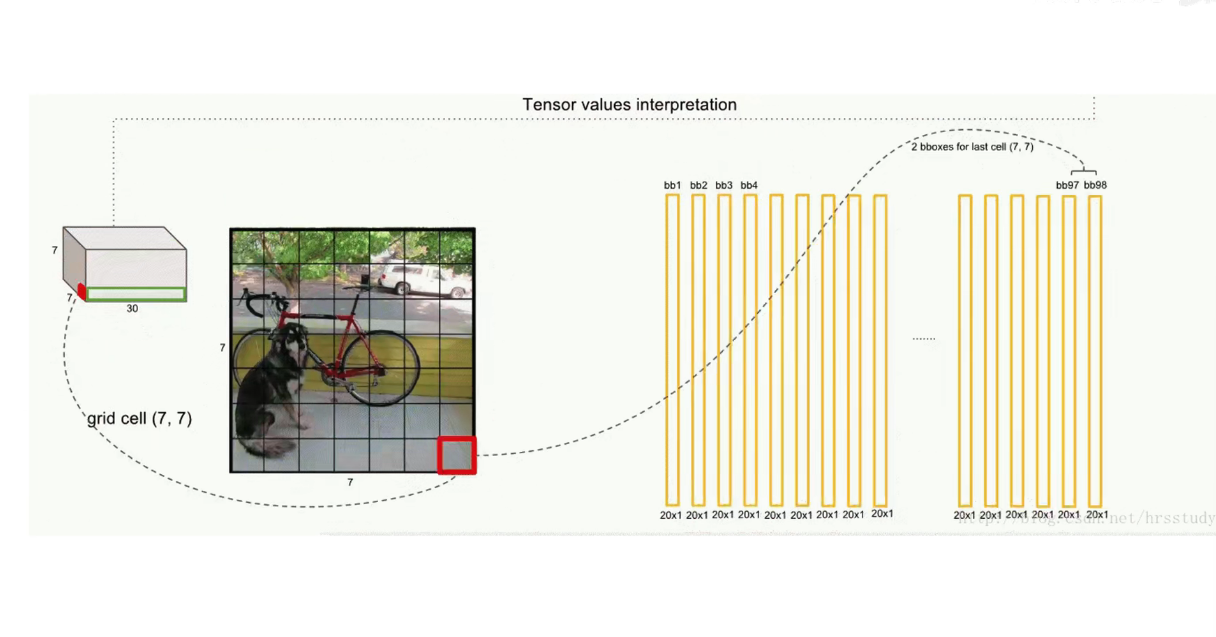
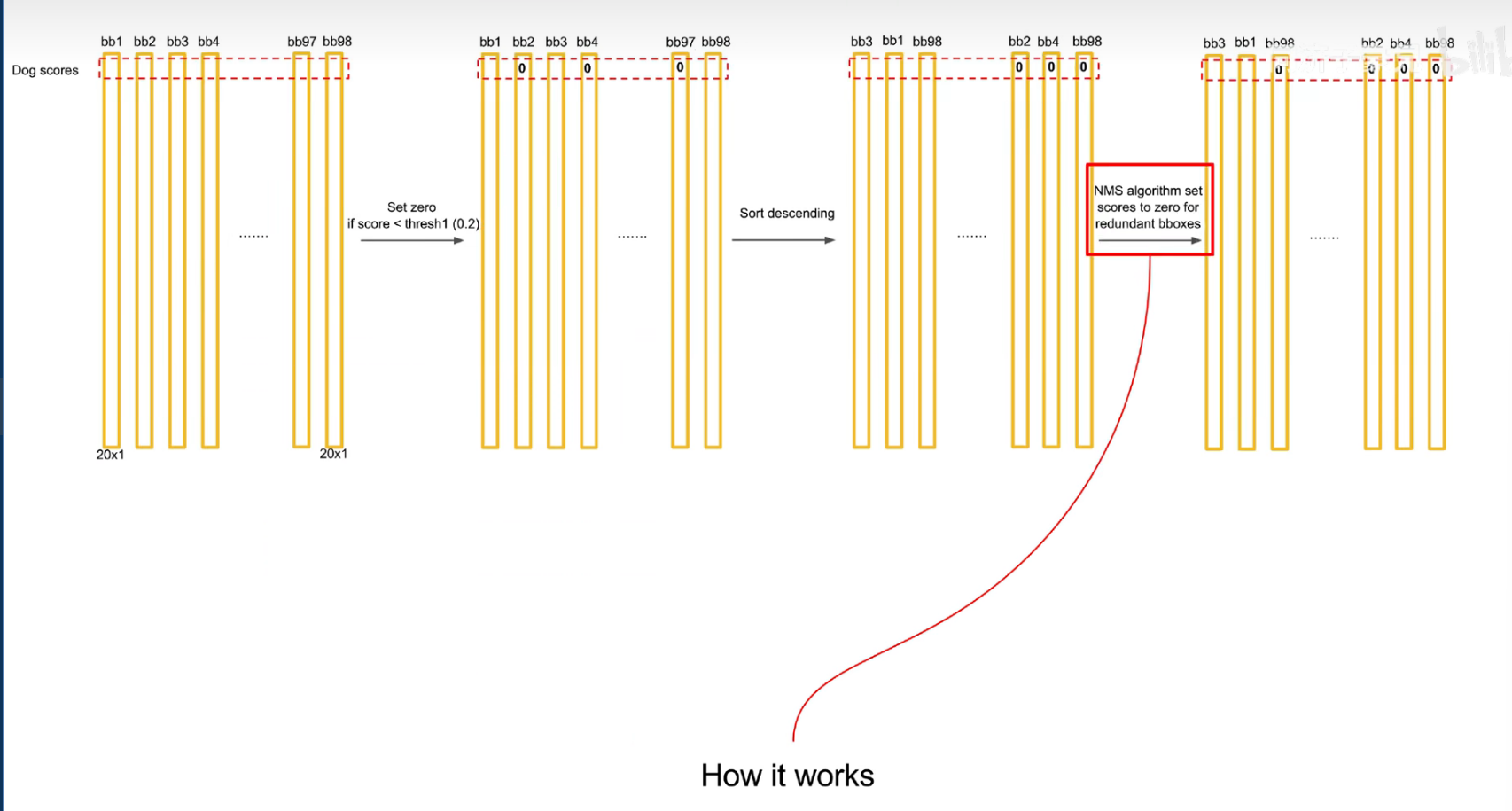
先按置信度大小进行排序

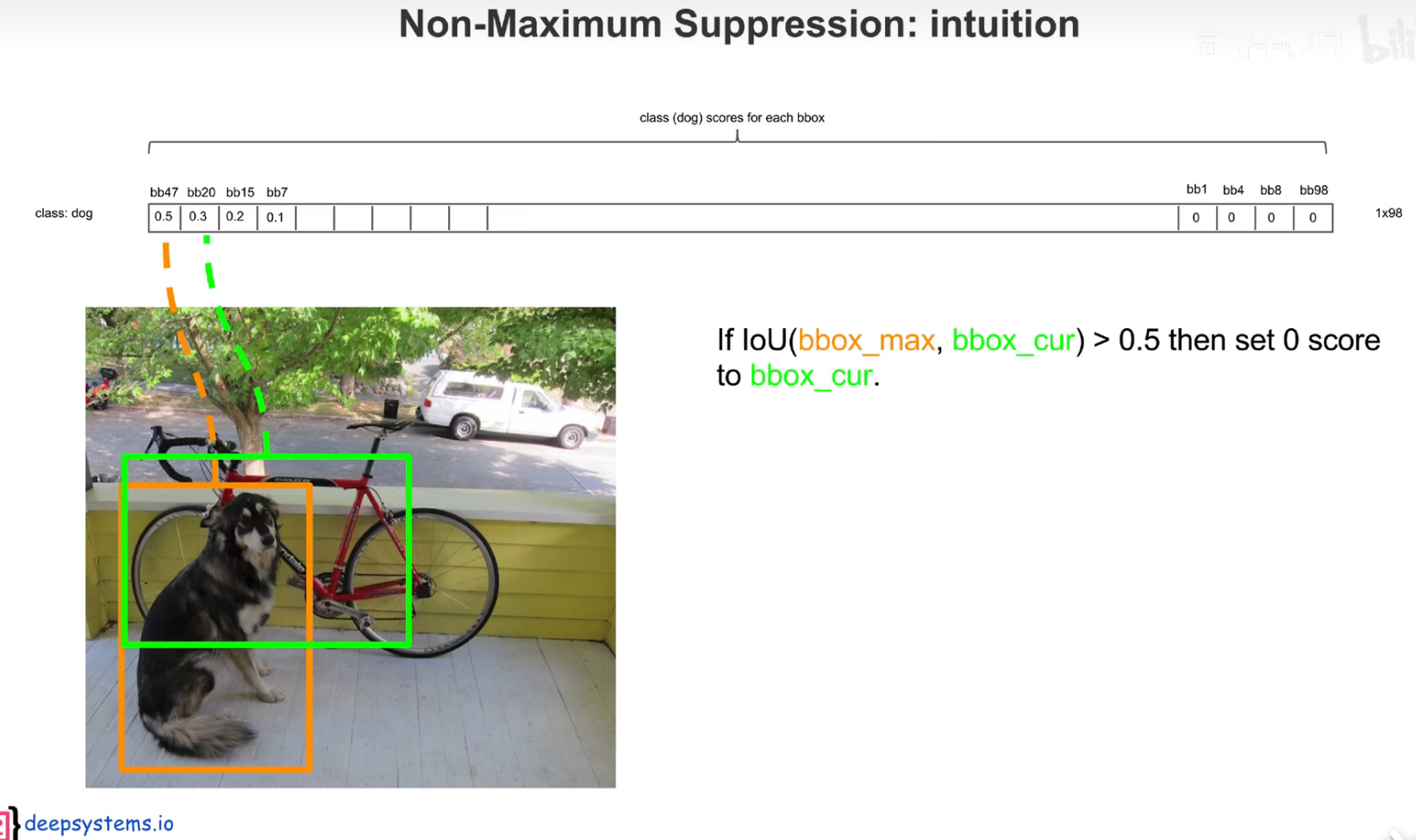

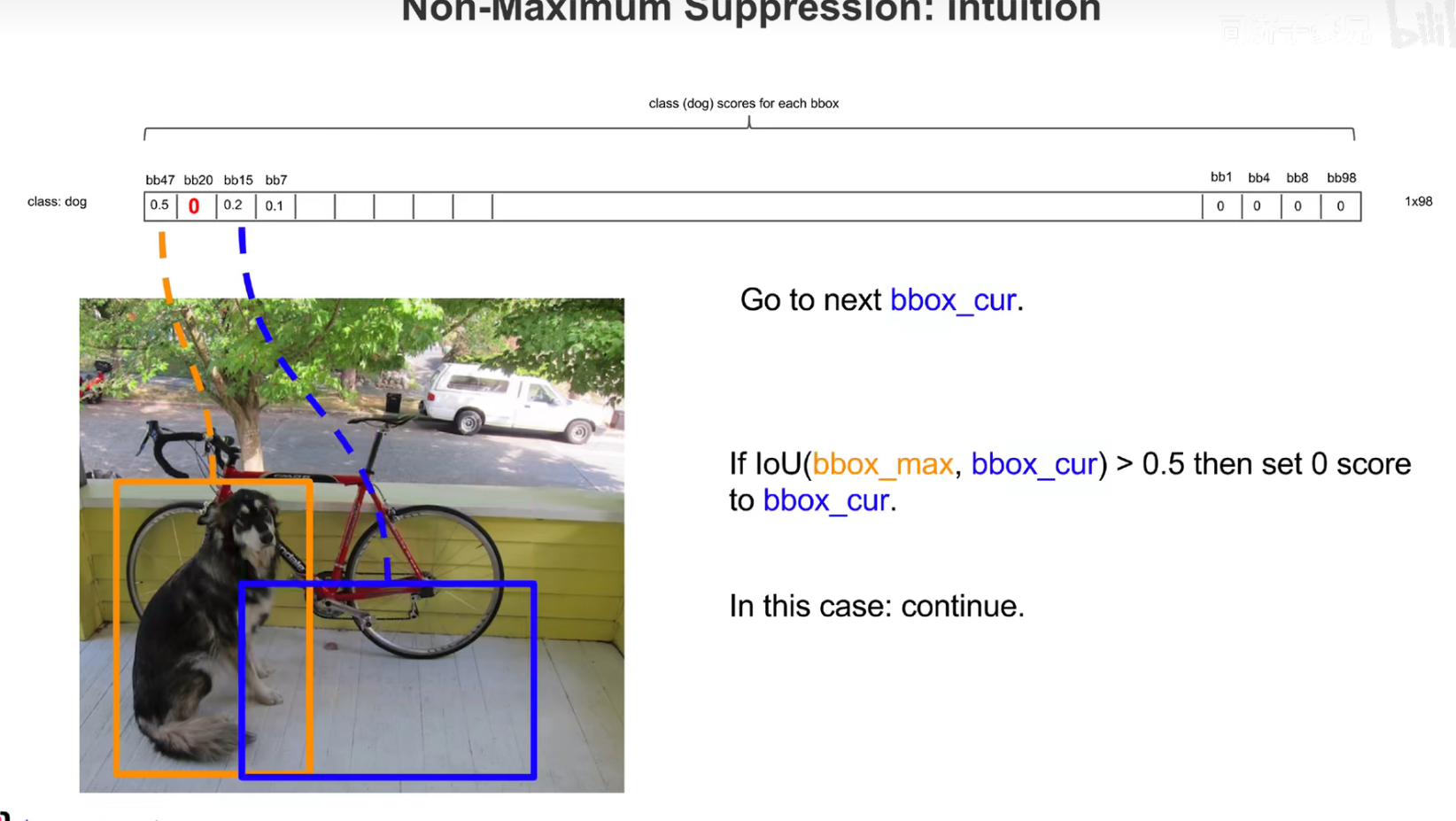
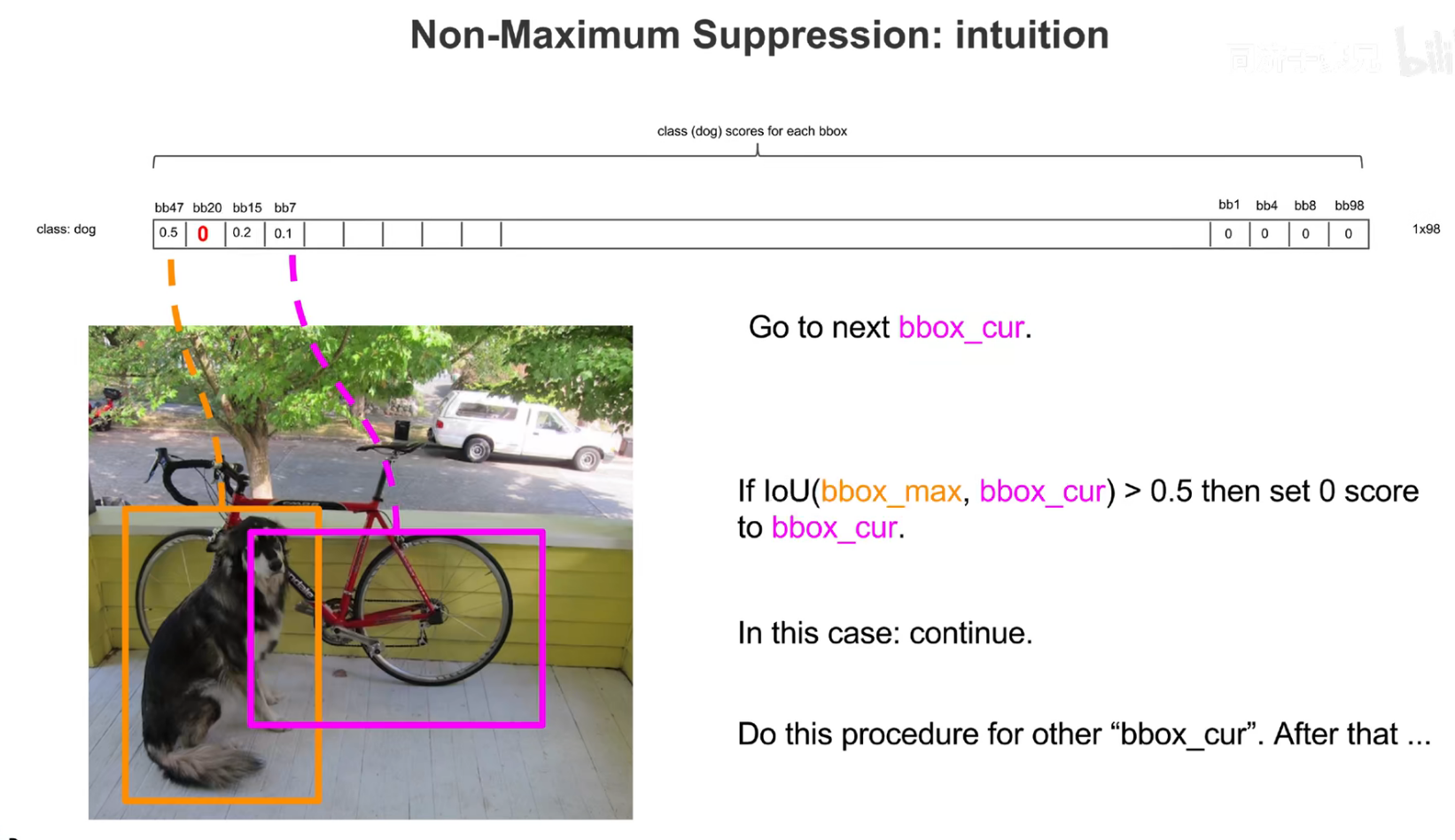
交并比大于一定的阈值,认为是在识别同一个物体。

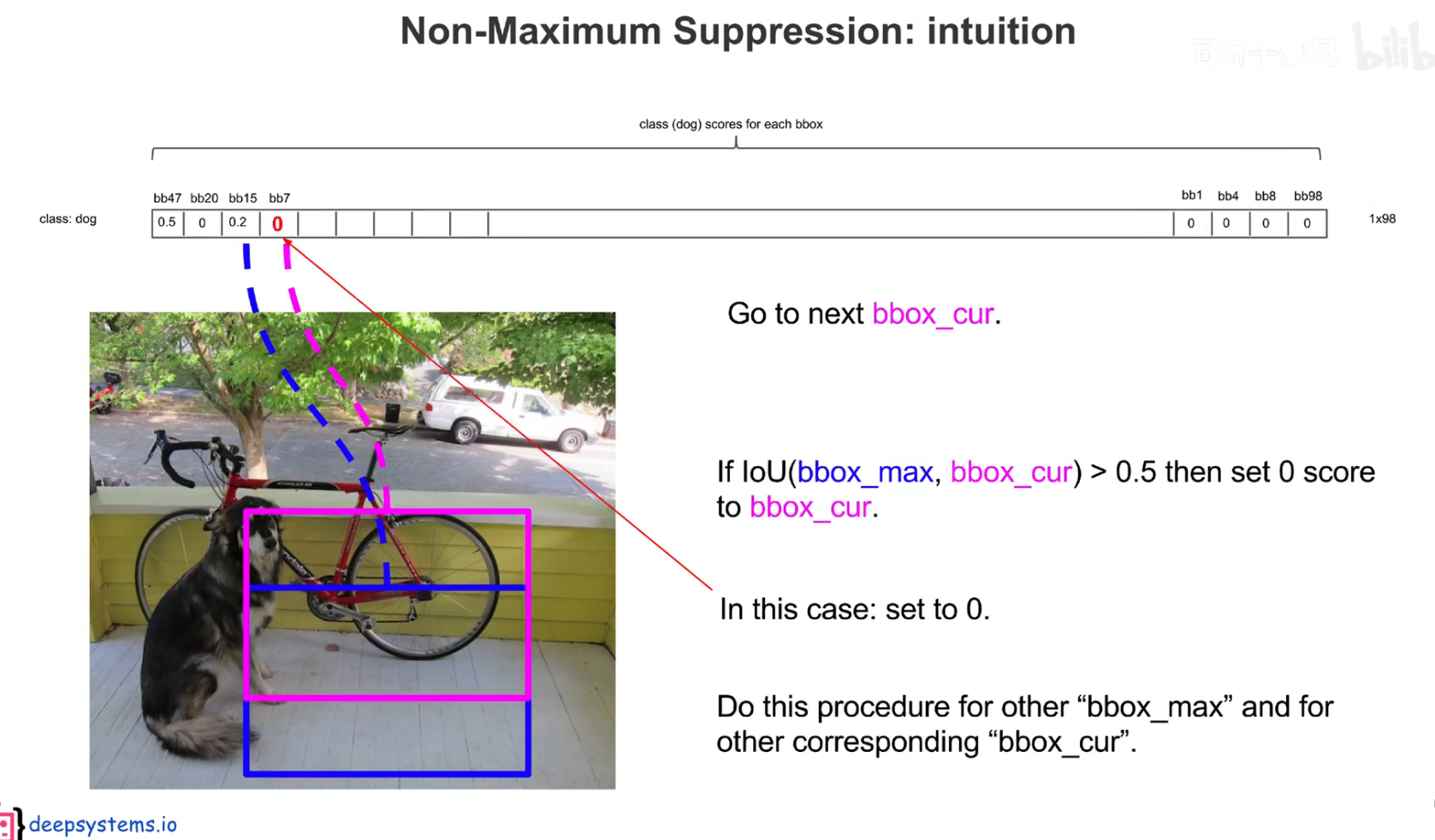

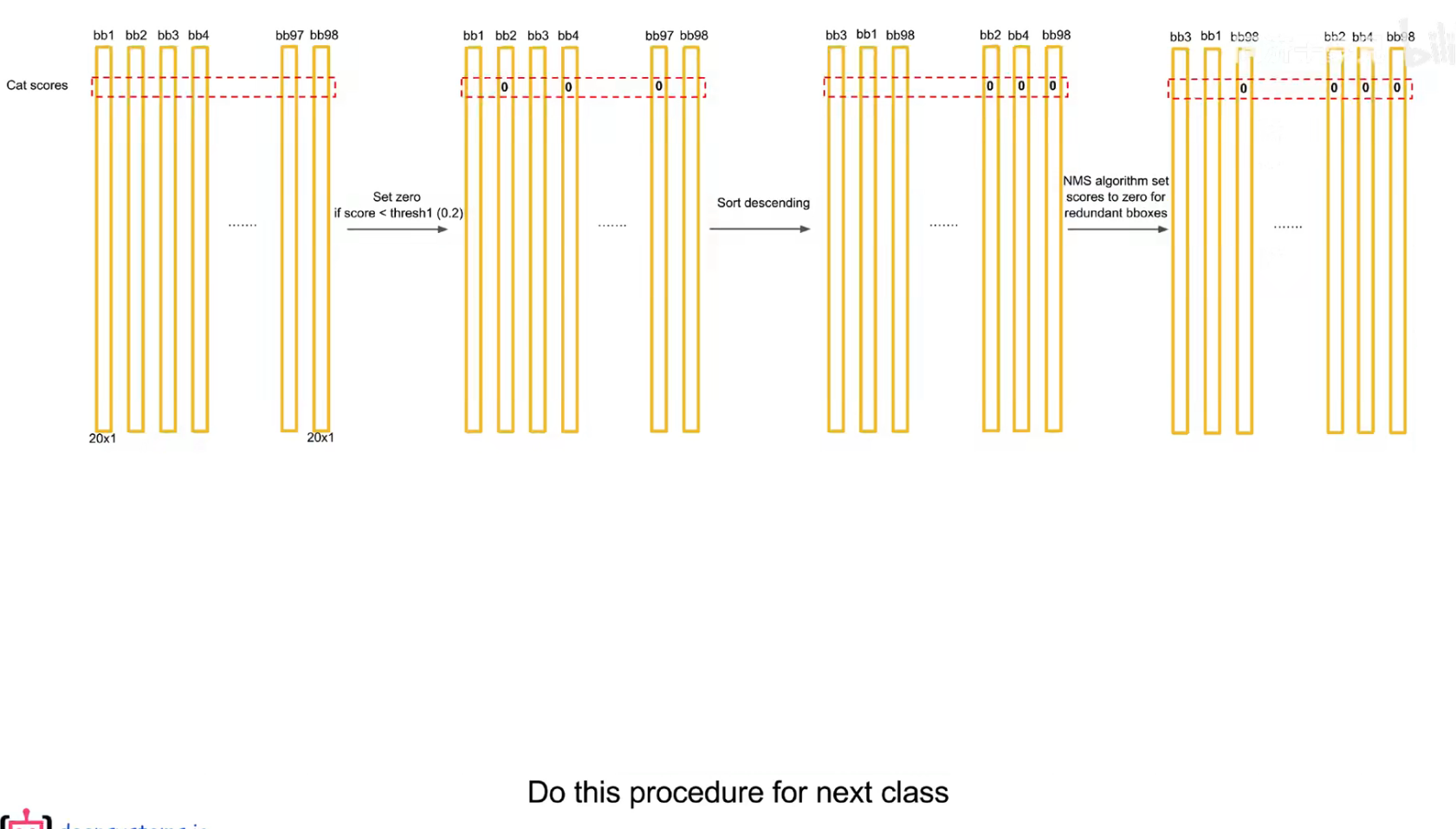
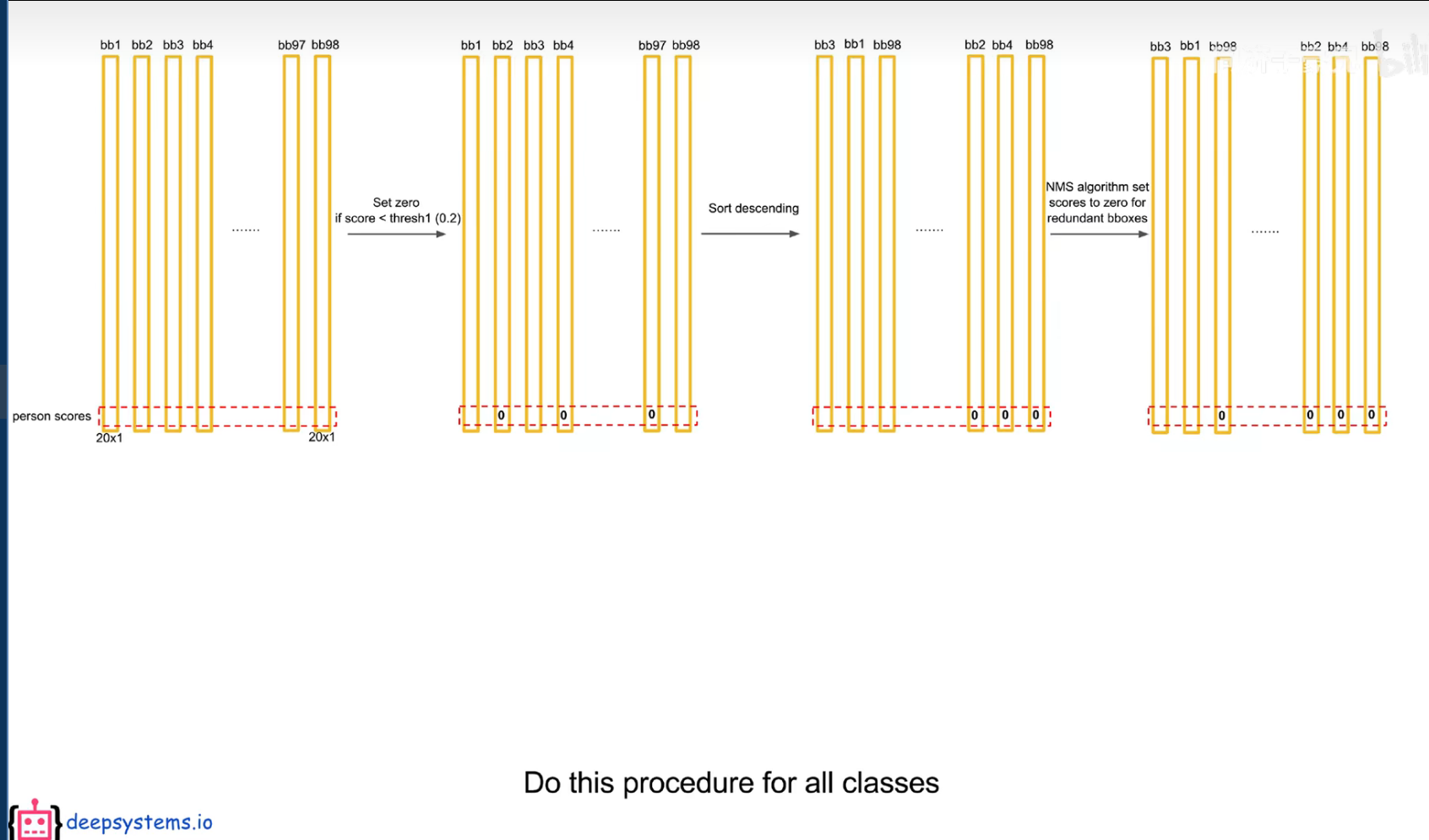
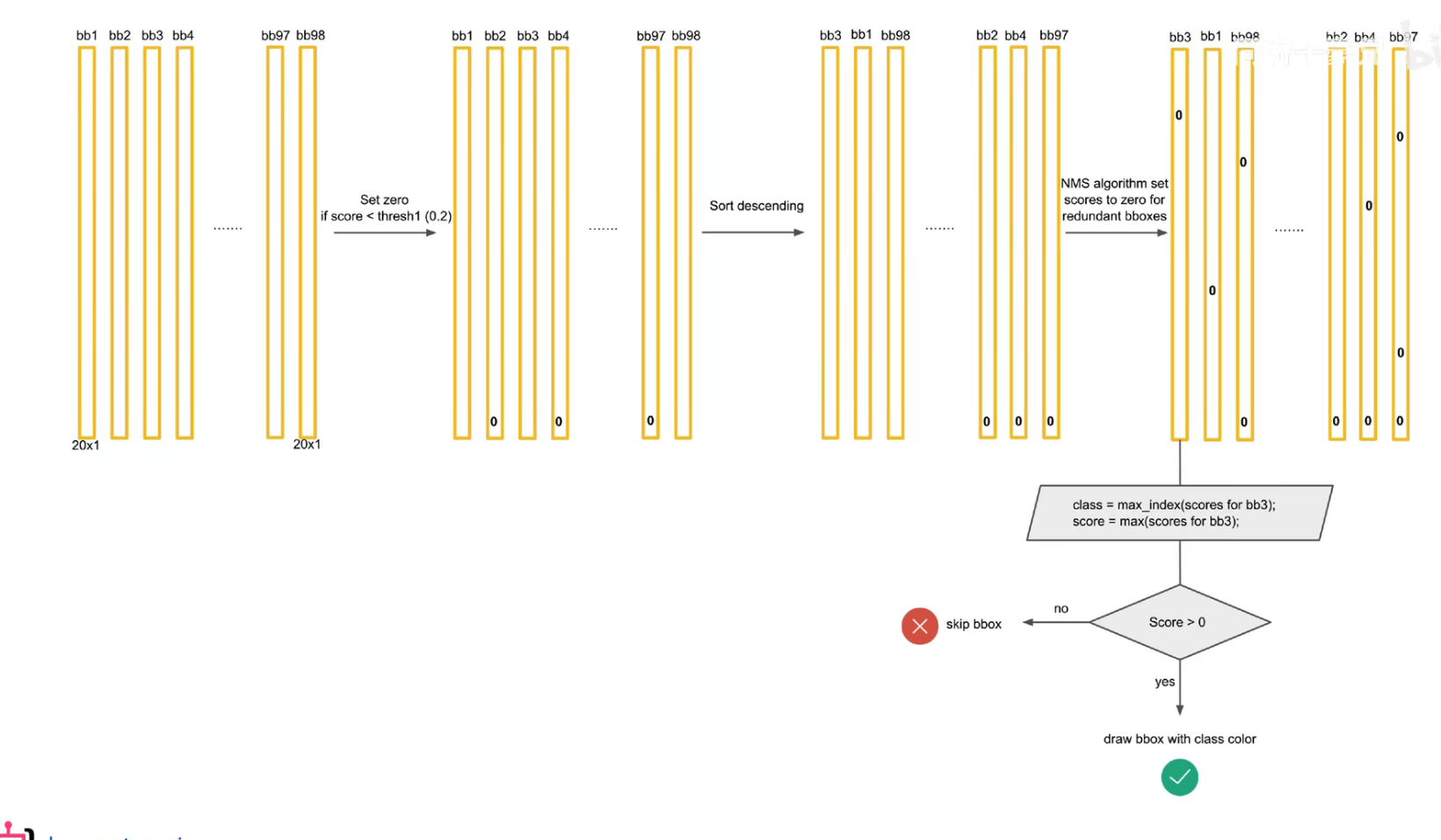
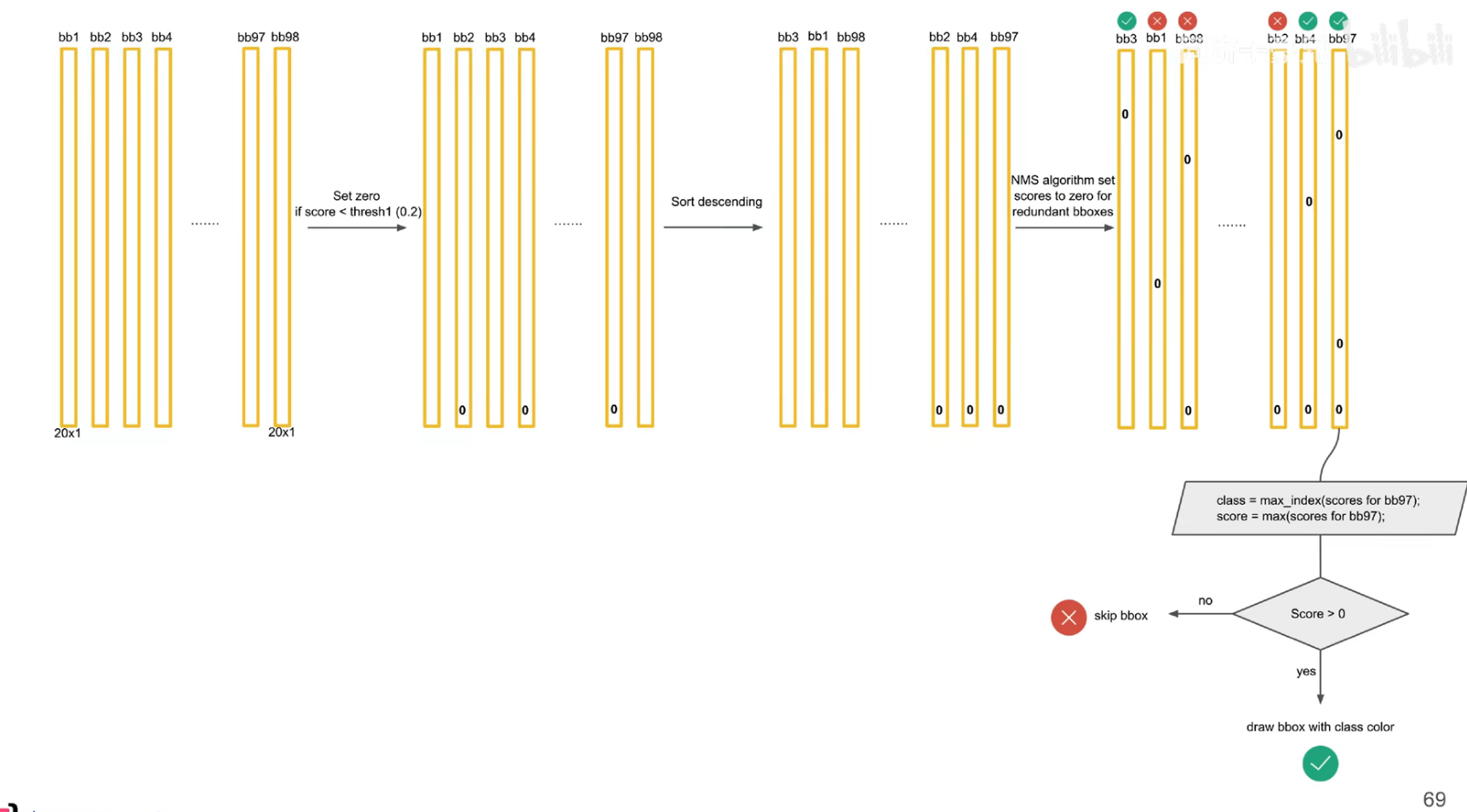
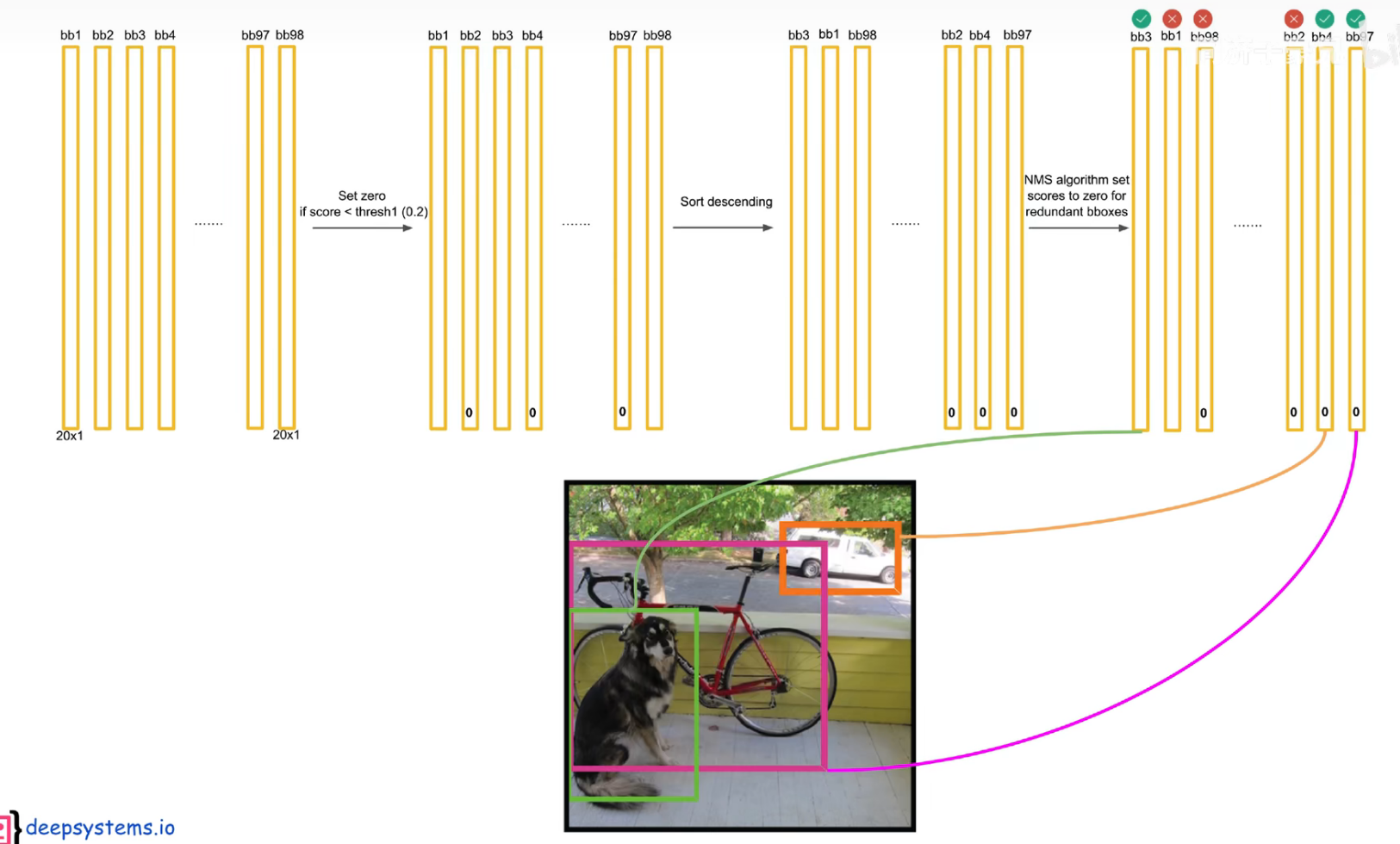
注意:后处理只是针对预测阶段,在训练阶段是不需要进行 nms 的,因为每个框都要在损失函数中占据一席之地
# 训练阶段(反向传播)

在训练集上,已经标注出绿框,而算法就是让预测结果尽量拟合绿框,使得损失函数最小化。而绿框的中心点落在哪个 grid cell 中,就应该由这个 grid cell 预测出来的 bounding box 拟合这个绿框,且类别也要相同(预测的概率最大)。

每个 grid cell 都预测出两个 bounding box,由和绿框 IOU 较大的负责拟合。另外的框就打入冷宫了。
损失函数的设计是让负责拟合物体的预测框和物体真正的框尽可能重合。


如果没有中心点落入 grid cell 中,则它预测出的两个框都被打入冷宫。让它们的置信度越小越好。
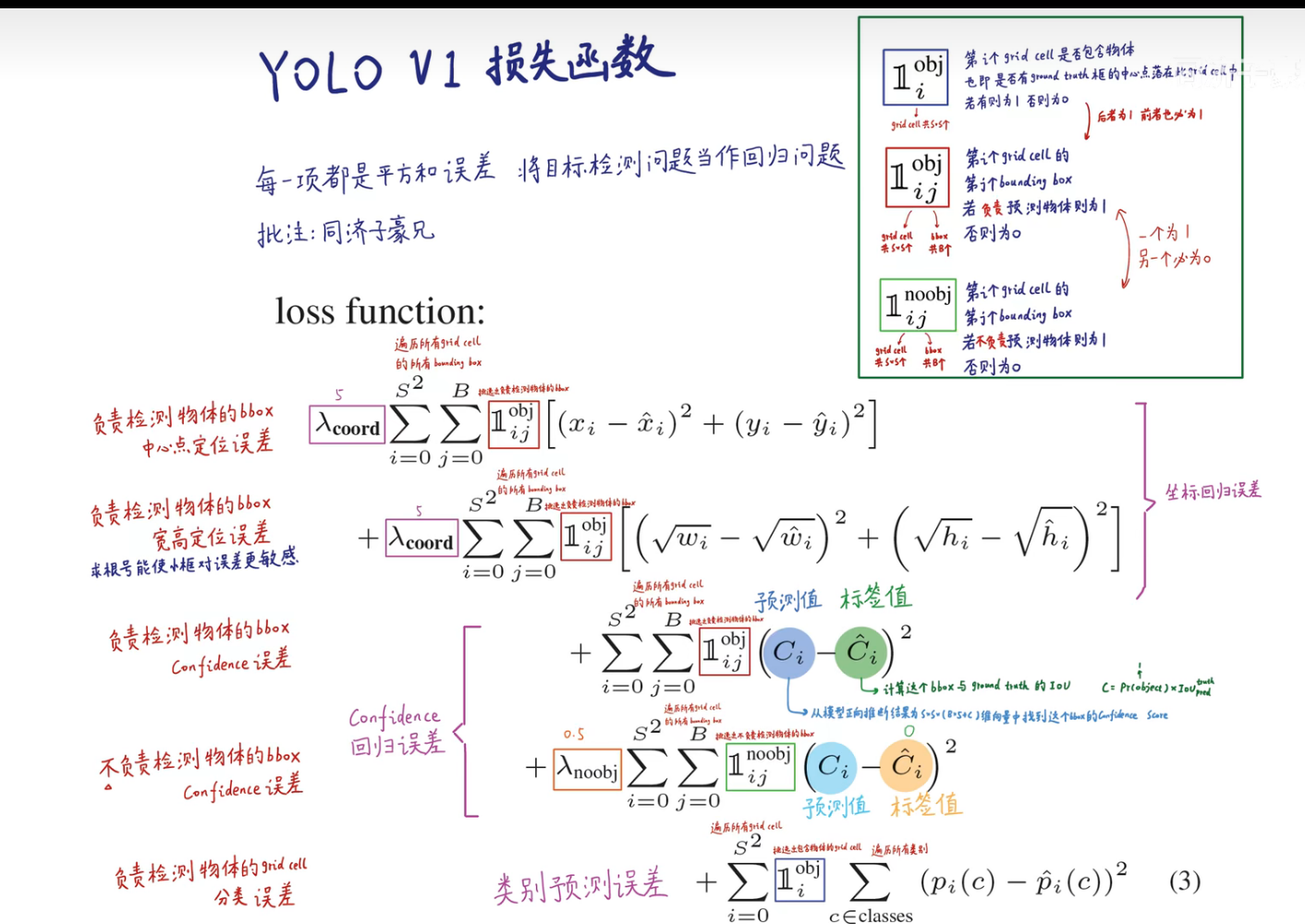
把目标检测问题当做回归问题解决。