# mapreduce
mapreduce 详解: https://zhuanlan.zhihu.com/p/82399103
为什么需要 combine 和 shuttle,在 map 之后难道不是一个整体么?
combine 是针对一个 source 文件的
shuffle 是针对 combine 之后的
shuffle 是将数据进行均匀分布,他这里是根据首字符进行分类的,但是这样能不能达到均匀呢?首字符在这里有起到排序的作用么,排序可以增强效果么?
在不同的 source 间
各个部分的作用:
# map:
一个 map 对单个 source 进行操作,因此 9 个 source 对应 9 个 map,作用是遍历每个单词,生成 <单词, 1> 这样的对
因此就存在着 同一个单词 有多个这样的对
可以进行排序,方便查看结果
# combine:
对 map 产生的 <单词, 1> 文件进行统计操作,结果是生成 <单词, 单词数量> 的文件,这里的单词操作范围仍仅限在一个 source 文件中,因此统计的单词数量是 source 中的单词数量
结果是每个单词仅有一个这样子的对
可以进行排序,方便查看结果
# shuffle
对上面 combine 生成的 9 个文件按照单词首字母进行分类整理,生成 3 个文件,这样每个文件中也是 <单词, 单词数量>
因此每个文件中,每个单词也可能对应多个 <单词, 单词数量>
# reduce
对 shuffle 生成的三个文件分别进行单词数量的统计,结果是生成 <单词, 单词数量> 的文件
结果是每个单词仅有一个这样子的对
# outresult
对 reduce 生成的三个文件合并成一个,每个单词只对应一个 <单词, 单词数量>
计算线程运行时间 这个代码中还没有
# PageRank
https://www.bilibili.com/video/BV1m4411P76G?p=3&spm_id_from=pageDriver&vd_source=1c562831fab1cb4101e5b95d41c170e0

根据 PageRank 公式,一个节点的 pr 值是由指向它的节点的 pr 值贡献的,所以,一个 pr 值比较大的节点指向的节点的 pr 也应该比较大。
同时除以出链数,意味着少、精
pr 值的初始化,循环求取
deadend 是指一个节点没有任何出链,在概率转移矩阵中表现为一列均为 0
误差怎么计算:相邻两次的差的和,衡量是否达到稳定了

https://blog.csdn.net/skysenlin/article/details/110094892?ops_request_misc=%7B%22request%5Fid%22%3A%22166908888516800182185587%22%2C%22scm%22%3A%2220140713.130102334..%22%7D&request_id=166908888516800182185587&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-110094892-null-null.142v66control,201v3control,213v2t3_esquery_v3&utm_term=PageRank&spm=1018.2226.3001.4187
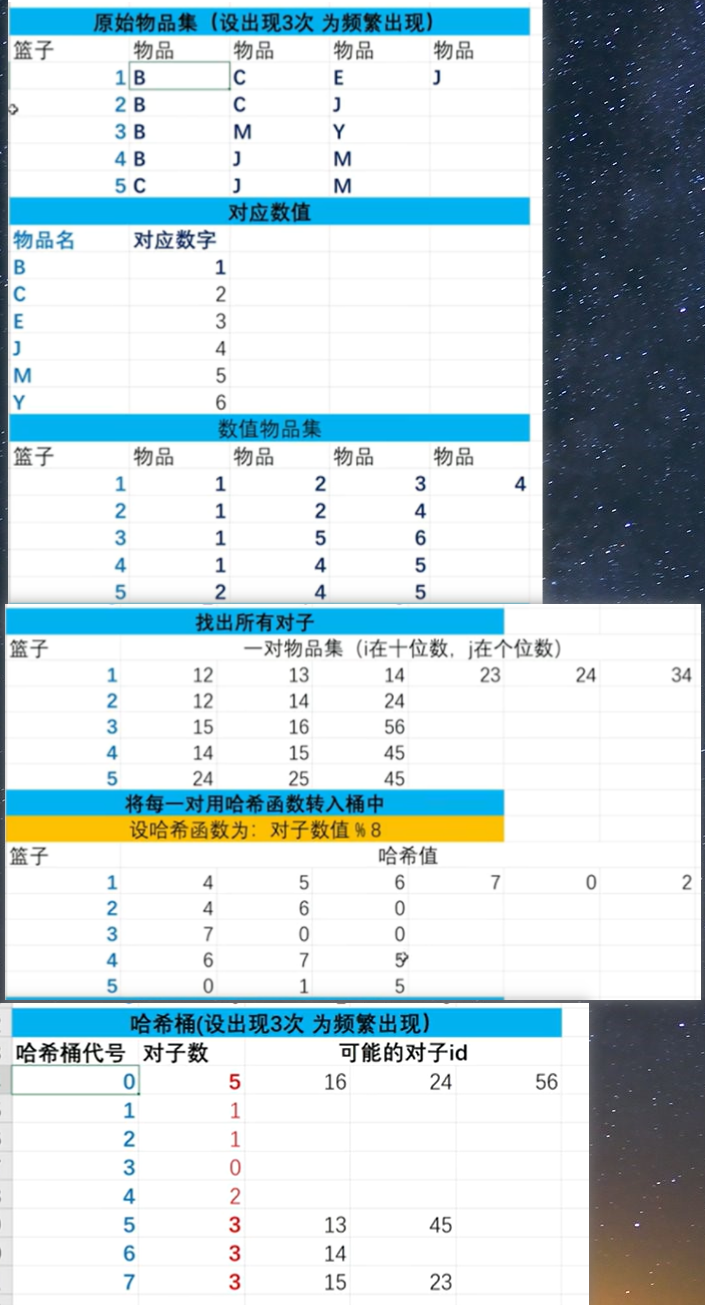
# 实验三 apriori
# 基础
参考视频

有方向性 尿布 -> 啤酒
C1 为 candidate,候选,类似于集合,
在 filter 的时候需要扫描原数据集,因为要获得每个候选集的支持度
# pcy
参考视频
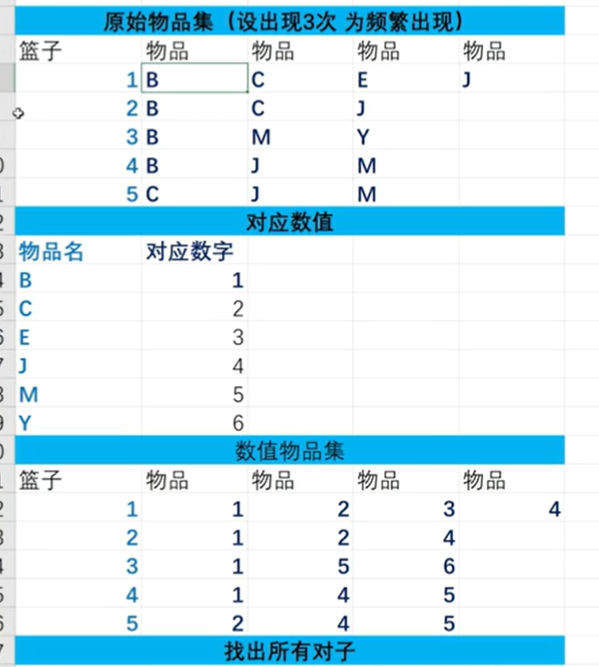
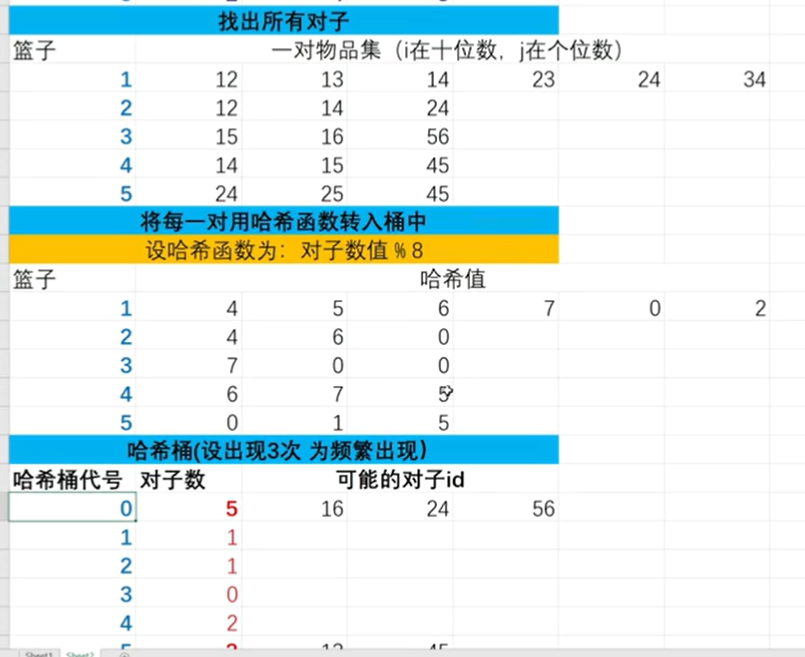
整体图片
# k-means
参考视频
# 推荐系统
关键词:
- User-User 的协同过滤算法
- minhash 算法对效用矩阵进行降维处理
UserCF 中 每个词代表的是什么?
协同过滤参考视频: https://www.bilibili.com/video/BV1yh411U7wy/?spm_id_from=333.337.search-card.all.click&vd_source=1c562831fab1cb4101e5b95d41c170e0
皮尔逊相关系数: https://blog.csdn.net/sujinhehehe/article/details/83380303
minhash 算法:https://zhuanlan.zhihu.com/p/82162303
jaccard 相似度:https://blog.csdn.net/u012836354/article/details/79103099
效用矩阵是从哪里得到的
pandas 数据透视表 pd.pivot_table ():https://blog.csdn.net/qq_36495431/article/details/81123240
tf-idf: 当一个关键词在文章中出现的频率较高时,说明此关键词在文章中的重要性比较高,但是当它在整个词库中出现的频率较高时,它的重要性又会下降
https://zhuanlan.zhihu.com/p/396332074
sklearn-TfidfVectorizer:https://zhuanlan.zhihu.com/p/67883024
CountVectorizer: https://blog.csdn.net/qq_43840793/article/details/115960115
# 基于用户的哈希签名的长度的影响
# 基于内容
