# 1 ~

需求分析阶段的任务是对现实世界要处理的对象(组织、部门和企业等)进行详细调查,在了解现行系统的概况,确定新系统功能的过程中收集支持系统目标的基础数据及处理方法。需求分析是在用户调查的基础上,通过分析,逐步明确用户对系统的需求,包括数据需求和围绕这些数据的业务处理需求,以及对数据安全性和完整性方面的要求。在需求分析阶段应完成的文档是数据字典和数据流图。

数据库设计分为用户需求分析、概念设计、逻辑设计和物理设计 4 个主要阶段。将抽象的概念模型转化为与选用的 DBMS 产品所支持的数据模型相符合的逻辑模型,它是物理设计的基础。包括模式初始设计、子模式设计、应用程序设计、模式评价以及模式求精。
逻辑设计阶段的任务是将概念模型设计阶段得到的基本 E-R 图转换为与选用的 DBMS 产品所支持的数据模型相符合的逻辑结构。如采用基于 E-R 模型的数据库设计方法,该阶段就是将所设计的 E-R 模型转换为某个 DBMS 所支持的数据模型;如采用用户视图法,则应进行模式的规范化,列出所有的关键字以及用数据结构图描述表集合中的约束与联系,汇总各用户视图的设计结果,将所有的用户视图合成一个复杂的数据库系统。

供应关系中,有属性:项目号,零件号,供应商号。这些属于分别来自供应商、项目、零件这三个关系,并且,一个供应商可以向多个项目供应零件,一个供应商可以供应多种零件,一个项目可以由多个供应商供应零件,一个项目可以使用多种零件,而一种零件可以由多个不同供应商来提供,一种零件可用于不同项目。这说明供应关系涉及 3 个实体,这 3 个实体之间的关系是 k:n:m。

数据库设计主要分为用户需求分析、概念结构、逻辑结构和物理结构设计四个阶段。其中,在用户需求分析阶段中,数据库设计人员采用一定的辅助工具对应用对象的功能、性能、限制等要求所进行的科学分析,并形成需求说明文档、数据字典和数据流程图。用户需求分析阶段形成的相关文档用以作为概念结构设计的设计依据。

由关系模式 R 的函数依赖集 F={A→B,B→C} 可以得出 A→C,存在传递依赖,但不存在非主属性对码的部分函数依赖,故 R 为 2NF。又由于分解后的关系模式 R1 的函数依赖集 F1={A→B},关系模式 R2 的函数依赖集 F2={A→C},因此 R1、R2 分别达到了 3NF。
未知上面的怎么做
# 10 ~ 19

从题目的描述 " 若一个工程项目可以有多个员工参加,每个员工可以参加多个项目” 可以得知,项目和员工的关系是 n:m。

数据库设计主要分为用户需求分析、概念结构、逻辑结构和物理结构设计四个阶段。其中,在用户需求分析阶段中,数据库设计人员采用一定的辅助工具对应用对象的功能、性能、限制等要求所进行的科学分析,并形成需求说明文档、数据字典和数据流程图。
用户需求分析阶段形成的相关文档用以作为概念结构设计的设计依据。

因为 F=F1∪F2,所以分解 p 保持函数依赖。又由于关系模式 R(U,F)的一个分解 p={R1(U1,F1),R2(U2,F2)} 具有无损连接的充分必要的条件是:U1∩U2→U1-U2∈F + 或 U1∩U2→U2-U1∈F+。分解 p 是否无损连接分析如下: ∵AB∩AC=A,AB-AC=B,AC-AB=C ∴A→B∈F+,A→C∈F+ ∴根据无损连接的充分必要的条件可知 p 为无损连接。

自然连接 R ▷◁ S 是指 R 与 S 关系中相同属性列名的等值连接运算后,再去掉右边重复的属性列名 S.B、S.C,所以经 R ▷◁ S 运算后的属性列名为:R.A、R.B、R.C、R.D、S.E 和 S.F,共有 6 个属性列。

分片透明是指用户或应用程序不需要知道逻辑上访问的表具体是怎么分块存储的。复制透明是指采用复制技术的分布方法,用户不需要知道数据是复制到哪些节点,如何复制的位置透明是指用户无须知道数据存放的物理位置,逻辑透明,即局部数据模型透明,是指用户或应用程序无须知道局部场地使用的是哪种数据模型。

给定一个关系模式 R(U,F),U = {A1,A2,...,An},F 是 R 的函数依赖集,
则 X 必为 R 的唯一候选关键字。对于试题 7.
所以 AB 非候选关键字;
所以 DE 非候选关键字;
所以 CE 为候选关键字;所以 DB 非候选关键字。
根据无损连接的判定算法,对于 AB 的构造初始的判定表如下:
由于 A→B,DE→B,CB→E,E→A,B→D 的决定因素中没有两行是相同的,因此 AB 是有损连接的。
对 DE 构造初始的判定表如下:

由于 A→B,DE→B,CB→E,E→A,B→D 的决定因素中没有两行是相同的,因此 DE 是有损连接的。
对 CE 构造初始的判定表如下:
由于 A→B,属性 A 的第 1 行和第 3 行相同,可以将第 1 行 b12 改为 a2; 又由于 B→D,属性 B 的第 1 行和第 3 行相同,而属性 D 第 1 行 b14 和第 3 行 b34 没有一行为 a4,因此改为同一符号,即取行号值最小的 b14。修改后的判定表如下: 反复检查函数依赖集 F,无法修改上表,所以 CE 是有损连接的。对 DB 构造初始的判定表如下: 由于 A→B,属性 A 的第 1 行和第 3 行相同,可以将第 3 行 b32 改为 a2; E→A,属性 E 的第 2 行和第 3 行相同,可以将属性 A 第 2 行 b21 改为 a1; AC→E,属性 E 的第 2 行和第 3 行相同,可以将属性 E 第 1 行 b15 改为 a5; B→D,属性 B 的第 1 行和第 3 行相同,属性 D 第 1 行 b14 和第 3 行 b34 没有一行为 a4,因此改为同一符号,即取行号值最小的 b14。修改后的判定表如下: 由于 E→D,属性 E 的第 1~3 行相同。可以将属性 D 第 1 行 b14 和第 3 行 b34 改为 a4,修改后的判定表如下: 由于上表第一行全为 a,故分解无损。 现在分析该分解是否保持函数依赖。若分解保持函数依赖,那么分解的子模式的函数依赖集 (根据 Armstrong 公理,系统传递依赖,E→A,A→B,B→D,所以 E→D),等价,即

SQL 查询是数据库中非常重要的内容。该 SQL 查询要求对查询结果进行分组,即具有相同名称的产品的元组为一组,然后计算每组的库存数量。

在实体转关系模式过程中,存在 3 种类型的联系,他们的处理方式如下:
1:1 联系:在两个关系模式中的任意一个模式中,加入另一个模式的键和联系类型的属性;
1:n 联系:在 n 端实体类型对应的关系模式中加入 1 端实体类型的键和联系类型的属性;
m:n 联系:将联系类型也转换成关系模式,属性为两端实体类型的键加上联系类型的属性。试题中是 m:n 联系,所以需要把联系单独转成一个关系模式。
# 26 ~ 48

题目要求 “查询选修了 1 号课程的学生学号和姓名”,因此先进行 S 与 SC 关系的自然连接,即选取 S. 学号 = SC. 学号的元组并去掉右边的重复属性 “学号”,生成的新关系为(学号,姓名,年龄,入学时间,联系方式,课程号,成绩),共有 7 个属性列。
是错误的,因为自然连接后的第 6 个属性为课程号,其选取运算
的实际含义为 “学号 = 课程号” 同时 “成绩 = 1”,与题意不符。
是正确的,因为该关系表达式的含义为:进行 S 与 SC 关系的自然连接,选取 S. 学号 = sc. 学号的元组并去掉右边的重复属性 “学号”,再选取 “课程号 = 1” 的元组,最后进行学号、姓名和成绩的投影运算。
(未解决)
零件 P 关系中的(商品代码,供应商)可决定的零件 P 关系的所有属性,所以零件 P 关系的主键为(商品代码,供应商); 又因为,根据题意(商品代码,供应商)一商品名称,而商品代码一商品名称,供应商一联系方式,可以得出商品名称和联系方式都部分依赖于码,所以,该关系模式属于 1NF。
关系模式 P 属于 INF,1NF 存在冗余度大、修改操作的不一致性、插入异常和删除异常四个问题。所以需要对模式分解,其中选项 A、选项 B 和选项 C 的分解是有损且不保持函数依赖。例如,选项 A 中的分解 P1 的函数依赖集 F1=0,分解 P2 的函数依赖集 F2=0,丢失了 F 中的函数依赖,即不保持函数依赖。

要求 “查询开发部的负责人姓名、年龄” 的关系代数表达式,选项 B 是先进行 δ2=' 开发部(DEP)运算,即在 DEP 关系中选择部门名 Dname=‘开发部’的元组;然后将 EMP 关系与其进行 EMP.DepID=DEP.DepID 的自然连接,并去掉右边的重复属性 “DEP.DepID”,自然连接后的属性列为(EmpID,Ename,sex,age,tel,DepID,Dname,Dtel,DEmpID);再此基础上进行 δ1=9 运算,即进行员工号 EmpID 等于部门负责人号 DEmpID 的选取运算;最后进行属性列 2(Ename)和属性列 4(age)的投影运算。

由于自然连接 R ▷◁ S 是指 R 与 S 关系中相同属性列名的等值连接,故需要用条件 “WHERE R.B=S.B AND R.O=S.C” 来限定;又由于经自然连接 R ▷◁ S 运算后,去掉了右边重复的属性列名 S.B、S.C,使得第三列属性列名和第六列属性列名分别为 R.C、S.F,所以选取运算 σ3<6 需要用条件 “WHERE R.C<S.F" 来限定。

关系代数表达式 π1.4(σ3=6(R×S))中,R×S 的 6 个属性列为:R.A、R.B、R.C、R.D、S.C 和 S.D,σ3=6(R×S)表示 R 与 S 关系进行笛卡儿积运算后,选取第三个属性 R.C 等于第六个属性 S.D 的元组;π1.4(σ3=6(R×S))表示从 σ3=6(R×S)的结果中投影第一个和第四个属性列,即投影 R.A 和 R.D 属性列。

数据仓库 4 大特点:
面向主题:数据按主题组织。
集成的:消除了源数据中的不一致性,提供整个企业的一致性全局信息。
相对稳定的(非易失的):主要进行查询操作,只有少量的修改和删除操作(或是不删除)。
反映历史变化(随着时间变化):记录了企业从过去某一时刻到当前各个阶段的信息,可对发展历程和未来趋势做定量分析和预测。

自然连接 R⋈S 是指 R 与 S 关系中相同属性列名经过等值连接运算后,再去掉右边重复的属性列名 S.D、S.E,所以经 R⋈S 运算后的属性列名为:R.A、R.B、R.C、R.D、R.E、S.F 和 S.G,共有 7 个属性列。经过投影运算后的属性列名为:R.A、R.B、R.D、S.F,共有 4 个属性列。

显然 A1A5 为关系模式 R 的码,因为 A1A5 仅出现在函数依赖集 F 左部的属性,所以 A1A5 必为 R 的任一候选码的成员。又因为 A1A5 的闭包等于 U,则 A1A5 必为 R 的唯一候选码。
若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为(超级码)候选码。

根据题意,F= {A1→A2A5,A2→A3A4,A3→A2},不难得出属性 A1 决定全属性,所以 A1 为候选关键字。 由于 A2→A3A4(已知),可以得出 A2→A3A2→A4(分解率);又因为 A3→A2(已知)A2→A4,可以得出 A3→A4(传递率),A3→A2A4(合并率)。

根据题意,对于非主属性 A2、A3 和 A4 是部分函数依赖于码 A1A5,所以 R 属于 1NF。
将 A1 A5 A6 拿出来新建一个表,剩下的表为 A1 A2 A3 A4,这样就是 2NF 了

根据题意,F= {A1→A2A5,A2→A3A4,A3→A2},不难得出属性 A1 决定全属性,所以 A1 为候选关键字。
由于 A2→A3A4(已知),可以得出 A2→A3A2→A4(分解率);又因为 A3→A2(已知)A2→A4,可以得出 A3→A4(传递率),A3→A2A4(合并率)。
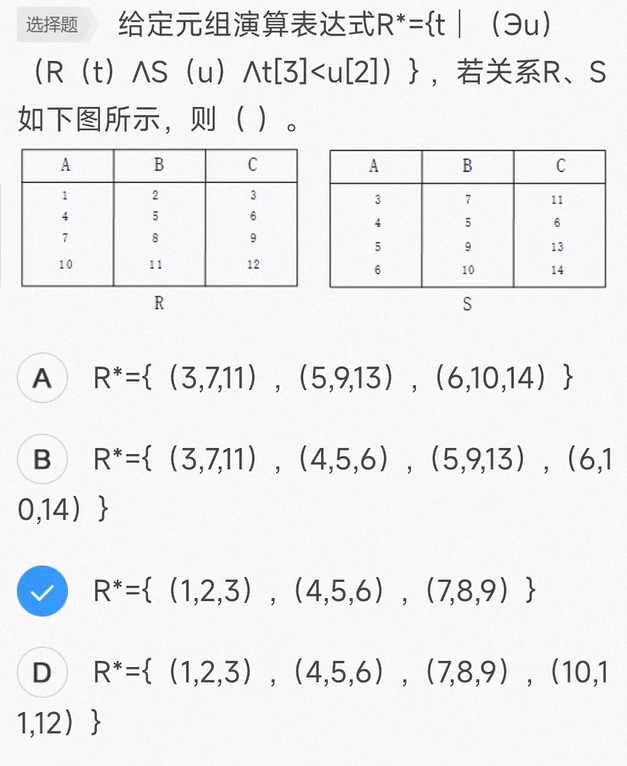
R*={t│(Эu)(R(t)∧S(u)∧t [3]<u [2])} 的含义为:新生成的关系 R * 中的元组来自关系 R, 但该元组的第三个分量值必须小于关系 S 中某个元组的第二个分量值。显然查询结果只有 R 关系的第一个、第二个和第三个元组满足条件。
在上面的解释中,R 元组的第三个分量值必须小于关系 S 中某个元组(找得到一个元组即可)的第二个分量值

数据的转储分为静态转储和动态转储、海量转储和增量转储。 ①静态转储和动态转储。静态转储是指在转储期间不允许对数据库进行任何存取、修改操作;动态转储是在转储期间允许对数据库进行存取、修改操作,故转储和用户事务可并发执行。 ②海量转储和增量转储。海量转储是指每次转储全部数据;增量转储是指每次只转储上次转储后更新过的数据。 综上所述,假设系统中有运行的事务,若要转储全部数据库应采用动态全局转储方式。

加锁阶段和解锁阶段也称为扩展阶段和收缩阶段,是传统集中式数据库的两阶段提交协议。获取阶段和运行阶段是与开发数据库应用过程相关的阶段。表决阶段和执行阶段是分布式数据库的两阶段提交协议。

数据挖掘是从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程,数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等等。并非所有的信息发现任务都被视为数据挖掘。例如,使用数据库管理系统查找个别的记录,或通过因特网的搜索引擎查找特定的 Web 页面,则是信息检索领域的任务。虽然这些任务是重要的,可能涉及使用复杂的算法和数据结构,但是它们主要依赖传统的计算机科学技术和数据的明显特征来创建索引结构,从而有效地组织和检索信息。

企业战略数据模型可分为数据库模型和数据仓库模型,数据库模型用来描述日常事务处理中的数据及其关系;数据仓库模型则描述企业髙层管理决策者所需信息及其关系。在企业信息化过程中,数据库模型是基础,一个好的数据库模型应该客观地反映企业生产经营的内在联系。

数据分割和数据复制是数据分布的两种重要方式。数据分割有垂直分割和水平分割两种模式,前者是将表中不同字段的数据存储到不同的服务器上;后者是将表中不同行的数据存储到不同的服务器上。数据复制是为了提升数据访问效率而采用的一种增加数据冗余的方法,它将数据的多个副本存储到不同的服务器上,由 RDBMS 负责维护数据的一致性。


在数据库系统中,“事务” 是访问并可能更新各种数据项的一个程序执行单元。为了保证数据完整性,要求数据库系统维护事务的原子性、一致性、隔离性和持久性。
题干中第 1 个架构设计场景描述了数据库设计中为了实现原子性和持久性的最为简单的策略:“影子拷贝”。该策略假设在某一个时刻只有一个活动的事务,首先对数据库做副本(称为影子副本),并在磁盘上维护一个 dp_pointer 指针,指向数据库的当前副本。对于要执行写操作的数据项,数据库系统在磁盘上维护数据库的一个副本,所有的写操作都在数据库副本上执行,而保持原始数据库不变,如果在任一时刻操作不得不中止, 系统仅需要删除新副本,原数据库副本没有受到任何影响。
题干中的第 2 个架构设计场景主要考查考生对事务一致性实现机制的理解。事务的一致性要求在没有其他事务并发执行的情况下,事务的执行应该保证数据库的一致性。数据库系统通常采用完整性约束检查机制保证单个事务的一致性。
题干中的第 3 个架构设计场景主要考查数据库的锁协议。两阶段锁协议是实现事务隔离性的常见方案,该协议通过定义锁的增长和收缩两个阶段约束事务的加锁和解锁过程,能够保证事务的串行化执行,但由于事务不能一次得到所有需要的锁,因此该协议会可能会导致死锁。
题干中的第 4 个架构设计场景主要考查数据库的恢复机制,主要描述了基于日志的延迟修改技术(deferred-modification technique)的设计与恢复过程。该技术通过在日志中记录所有对数据库的修改操作,将一个事务的所有写操作延迟到事务提交后才执行, 日志中需要记录 “事务开始” 和 “事务提交” 时间,还需要记录数据项被事务修改后的新值,无需记录数据项被事务修改前的原始值。当系统发生故障时,如果某个事务已经开始,但没有提交,则该事务对数据项的修改尚未体现在数据库中,因此无需做任何恢复动作。



