# 问答 Question answering
是时候看问答了!这项任务有多种形式,但我们将在本节中关注的一项称为提取的问答 extractive question answering。问题的答案就在 给定的文档 之中。
我们将使用 SQuAD 数据集 微调一个 BERT 模型,其中包括群众工作者对一组维基百科文章提出的问题。
像 BERT 这样的纯编码器模型往往很擅长提取诸如 “谁发明了 Transformer 架构?” 之类的事实性问题的答案。但在给出诸如 “为什么天空是蓝色的?” 之类的开放式问题时表现不佳。在这些更具挑战性的情况下,T5 和 BART 等编码器 - 解码器模型通常使用以与 文本摘要 非常相似的方式合成信息。如果你对这种类型的生成式问答感兴趣,我们建议您查看我们基于 ELI5 数据集 的 演示。
# 准备数据
最常用作抽取式问答的学术基准的数据集是 SQuAD, 所以这就是我们将在这里使用的。还有一个更难的 SQuAD v2 基准,其中包括没有答案的问题。只要你自己的数据集包含上下文列、问题列和答案列,你就应该能够调整以下步骤。
# SQuAD 数据集
from datasets import load_dataset | |
raw_datasets = load_dataset("squad") |
然后我们可以查看这个对象以,了解有关 SQuAD 数据集的更多信息:
raw_datasets | |
DatasetDict({ | |
train: Dataset({ | |
features: ['id', 'title', 'context', 'question', 'answers'], | |
num_rows: 87599 | |
}) | |
validation: Dataset({ | |
features: ['id', 'title', 'context', 'question', 'answers'], | |
num_rows: 10570 | |
}) | |
}) |
看起来我们拥有所需的 context 、question 和 answers 字段,所以让我们打印训练集的第一个元素:
print("Context: ", raw_datasets["train"][0]["context"]) | |
print("Question: ", raw_datasets["train"][0]["question"]) | |
print("Answer: ", raw_datasets["train"][0]["answers"]) | |
Context: 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.' | |
Question: 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?' | |
Answer: {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]} |
context 和 question 字段使用起来非常简单。但是 answers 字段有点棘手,因为它将字典与两个都是列表的字段组成。这是在评估过程中 squad 指标所期望的格式;如果你使用的是自己的数据, 则不必担心将答案采用相同的格式。text 字段比较明显,而 answer_start 字段包含上下文中每个答案的起始字符索引。
这个起始字符索引 answer_start ,是针对字符而不是 token
在训练期间,只有一种可能的答案。我们可以使用 Dataset.filter() 方法:
raw_datasets["train"].filter(lambda x: len(x["answers"]["text"]) != 1) | |
Dataset({ | |
features: ['id', 'title', 'context', 'question', 'answers'], | |
num_rows: 0 | |
}) |
然而,对于评估,每个样本都有几个可能的答案,它们可能相同或不同:
print(raw_datasets["validation"][0]["answers"]) | |
print(raw_datasets["validation"][2]["answers"]) | |
{'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]} | |
{'text': ['Santa Clara, California', "Levi's Stadium", "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California."], 'answer_start': [403, 355, 355]} |
我们不会深入研究评估脚本,因为它都会被一个 Datasets 指标包裹起来,但简短的版本是一些问题有几个可能的答案,这个脚本会将预测的答案与所有的可接受的答案并获得最高分。例如,我们看一下索引 2 处的样本 e:
print(raw_datasets["validation"][2]["context"]) | |
print(raw_datasets["validation"][2]["question"]) | |
'Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi\'s Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.' | |
'Where did Super Bowl 50 take place?' |
我们可以看到,答案确实可以是我们之前看到的三种可能性之一。
# 处理训练数据
让我们从预处理训练数据开始。困难的部分将是为问题的答案生成标签,这将是与上下文中的答案相对应的标记的开始和结束位置。
但是,我们不要超越自己。首先,我们需要使用分词器将输入中的文本转换为模型可以理解的 ID:
from transformers import AutoTokenizer | |
model_checkpoint = "bert-base-cased" | |
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint) |
如前所述,我们将对 BERT 模型进行微调,但你可以使用任何其他模型类型,只要它实现了快速标记器即可。你可以在 this big table 中看到所有快速版本的架构,并检查你正在使用的 tokenizer 对象确实由 🤗 Tokenizers 支持,你可以查看它的 is_fast 属性:
tokenizer.is_fast | |
True |
我们可以将问题和上下文一起传递给我们的标记器,它会正确插入特殊标记以形成如下句子:
[CLS] question [SEP] context [SEP] |
让我们仔细检查一下:
context = raw_datasets["train"][0]["context"] | |
question = raw_datasets["train"][0]["question"] | |
inputs = tokenizer(question, context) | |
tokenizer.decode(inputs["input_ids"]) |
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, ' | |
'the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin ' | |
'Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms ' | |
'upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred ' | |
'Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a ' | |
'replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette ' | |
'Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues ' | |
'and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]' |
然后标签是开始和结束答案的 token 的索引,并且模型的任务是预测输入中每个 token 的开始和结束 logit, 理论标签如下:
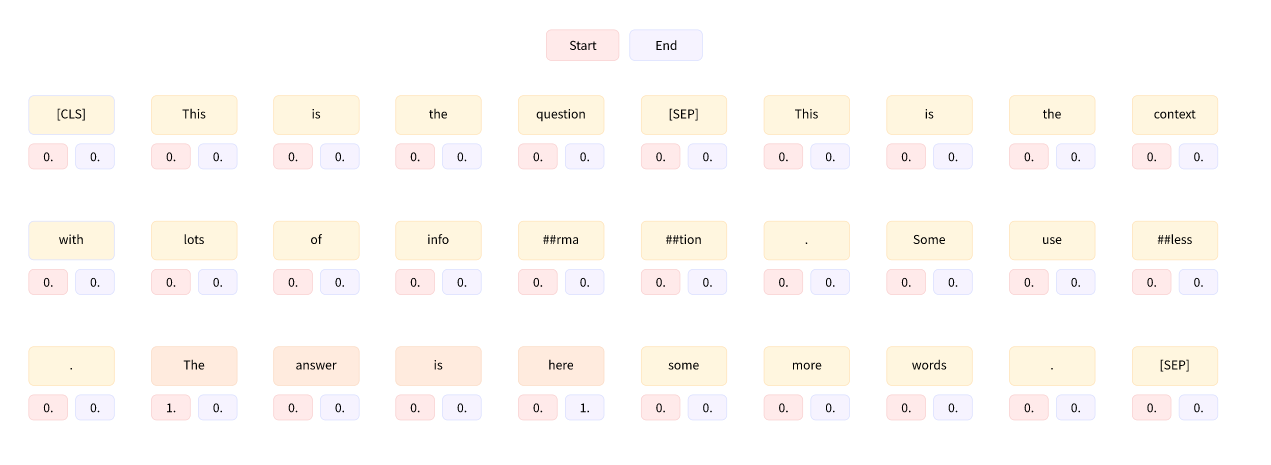
上面图片中每个 token 下面的两个数字应该是分别表示答案是否开始和是否结束
在这种情况下,上下文不会太长,但是数据集中的一些示例的上下文很长,会超过我们设置的最大长度 (在这种情况下为 384)。正如我们在 第六章 中所看到的,当我们探索 question-answering 管道的内部结构时,我们将通过从我们的数据集的一个样本中创建几个训练特征来处理长上下文,它们之间有一个滑动窗口。
要使用当前示例查看其工作原理,我们可以将长度限制为 100, 并使用 50 个标记的滑动窗口。提醒一下,我们使用:
max_length设置最大长度 (此处为 100)truncation="only_second"用于当带有上下文的问题太长时,截断上下文 t (位于第二个位置)stride设置两个连续块之间的重叠标记数 (这里为 50)return_overflowing_tokens=True让标记器知道我们想要溢出的标记
inputs = tokenizer( | |
question, | |
context, | |
max_length=100, | |
truncation="only_second", | |
stride=50, | |
return_overflowing_tokens=True, | |
) | |
inputs.keys() | |
# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'overflow_to_sample_mapping']) | |
for ids in inputs["input_ids"]: | |
print(tokenizer.decode(ids)) |
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basi [SEP]' | |
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin [SEP]' | |
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 [SEP]' | |
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP]. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]' |
如我们所见,我们的示例被分成四个输入,每个输入都包含问题和上下文的一部分。 请注意,问题的答案 (“Bernadette Soubirous”) 仅出现在第三个也是最后一个输入中,因此通过以这种方式处理长上下文,我们将创建一些答案不包含在上下文中的训练示例。对于这些示例,标签将是 start_position = end_position = 0 (所以我们预测 [CLS] 标记)。我们还将在答案被截断的不幸情况下设置这些标签,以便我们只有它的开始 (或结束)。对于答案完全在上下文中的示例,标签将是答案开始的标记的索引和答案结束的标记的索引。
数据集为我们提供了上下文中答案的开始字符,通过添加答案的长度,我们可以找到上下文中的结束字符。要将它们映射到令牌索引,我们将需要使用我们在 第六章 中研究的偏移映射。我们可以让标记器通过传递 return_offsets_mapping=True 来返回这些值:
inputs = tokenizer( | |
question, | |
context, | |
max_length=100, | |
truncation="only_second", | |
stride=50, | |
return_overflowing_tokens=True, | |
return_offsets_mapping=True, | |
) | |
inputs.keys() |
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping']) |
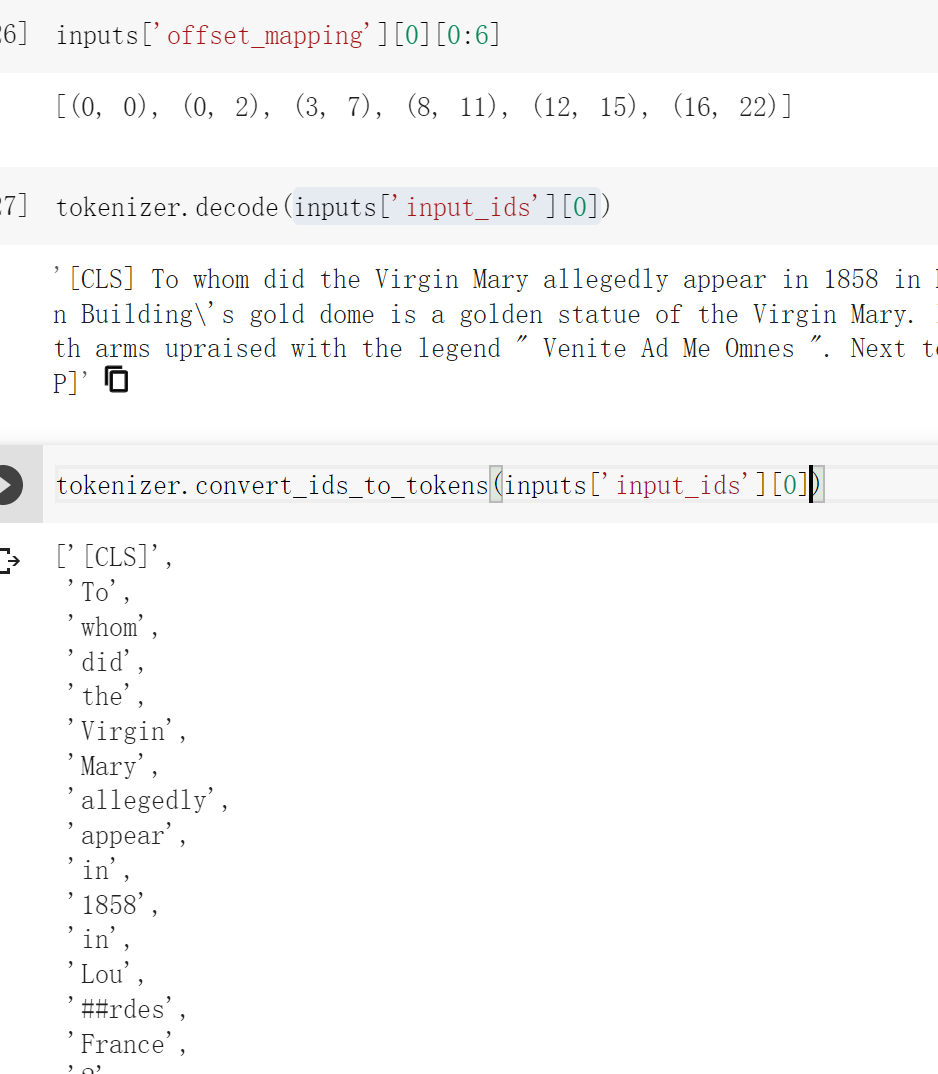
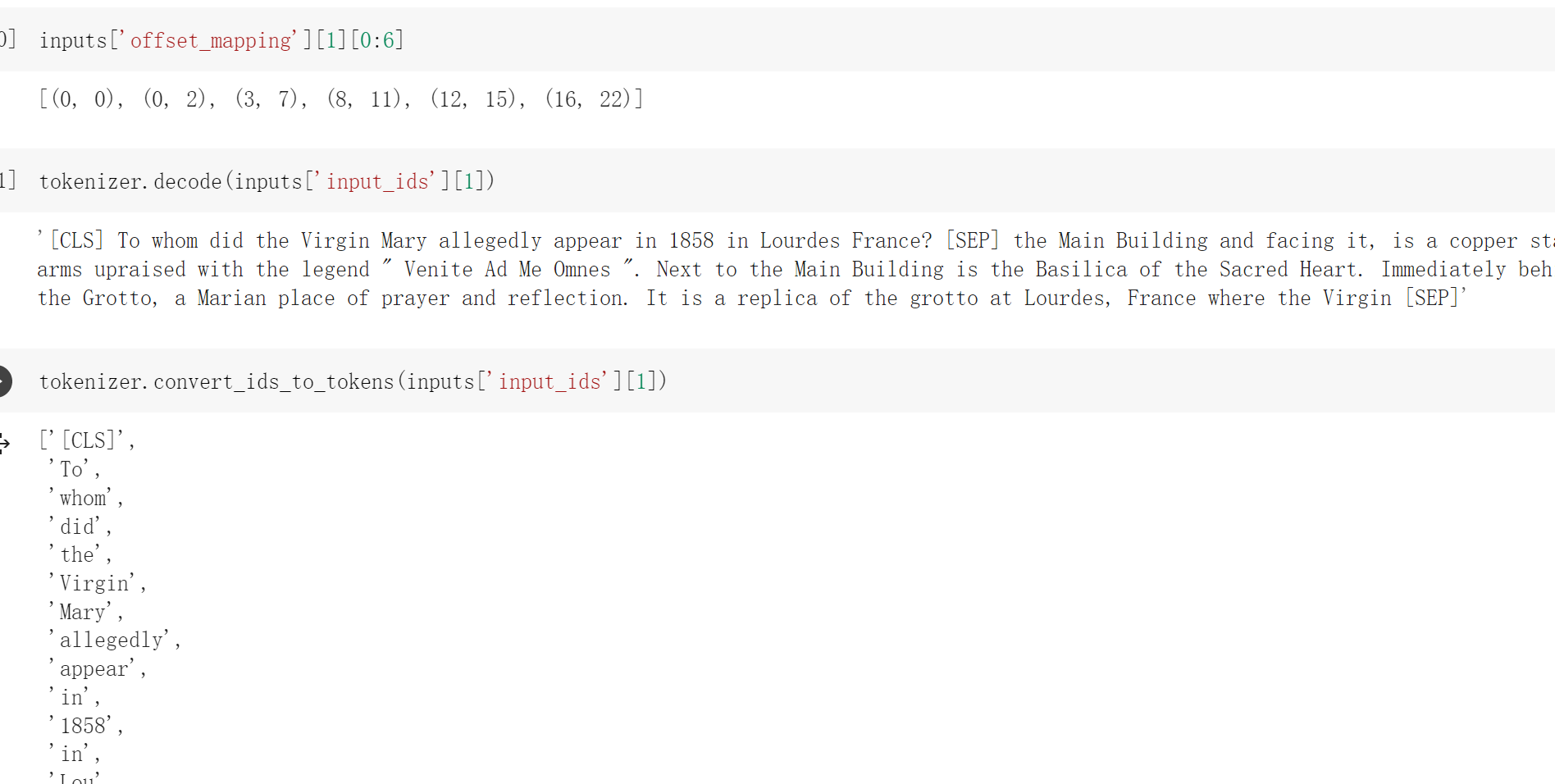
从上面的截图中看出 offset_mapping 得到的是将 token 无空格的连接起来之后的 token 的索引。
如我们所见,我们取回了通常的输入 ID、令牌类型 ID 和注意掩码,以及我们需要的偏移映射和一个额外的键, overflow_to_sample_mapping 。当我们同时标记多个文本时,相应的值将对我们有用 (我们应该这样做以受益于我们的标记器由 Rust 支持的事实)。由于一个样本可以提供多个特征,因此它将每个特征映射到其来源的示例。因为这里我们只标记了一个例子,我们得到一个 0 的列表:
inputs["overflow_to_sample_mapping"] | |
[0, 0, 0, 0] |
但是,如果我们标记更多示例,这将变得更加有用:
inputs = tokenizer( | |
raw_datasets["train"][2:6]["question"], | |
raw_datasets["train"][2:6]["context"], | |
max_length=100, | |
truncation="only_second", | |
stride=50, | |
return_overflowing_tokens=True, | |
return_offsets_mapping=True, | |
) | |
print(f"The 4 examples gave {len(inputs['input_ids'])} features.") | |
print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.") |
'The 4 examples gave 19 features.' | |
'Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].' |
正如我们所看到的,前三个示例 (在训练集中的索引 2、3 和 4 处) 每个都给出了四个特征,最后一个示例 (在训练集中的索引 5 处) 给出了 7 个特征。
此信息将有助于将我们获得的每个特征映射到其相应的标签。如前所述,这些标签是:
(0, 0)如果答案不在上下文的相应范围内(start_position, end_position)如果答案在上下文的相应范围内,则 start_position 是答案开头的标记索引 (在输入 ID 中), 并且 end_position 是答案结束的标记的索引 (在输入 ID 中)。
上面的输入 ID 是什么
为了确定是哪种情况以及标记的位置,以及 (如果相关的话) 标记的位置,我们首先在输入 ID 中找到开始和结束上下文的索引。我们可以使用标记类型 ID 来执行此操作,但由于这些 ID 不一定存在于所有模型中 (例如,DistilBERT 不需要它们), 我们将改为使用我们的标记器返回的 BatchEncoding 的 sequence_ids () 方法。
一旦我们有了这些标记索引,我们就会查看相应的偏移量,它们是两个整数的元组,表示原始上下文中的字符范围。因此,我们可以检测此特征中的上下文块是在答案之后开始还是在答案开始之前结束 (在这种情况下,标签是 (0, 0))。如果不是这样,我们循环查找答案的第一个和最后一个标记:
answers = raw_datasets["train"][2:6]["answers"] | |
start_positions = [] | |
end_positions = [] | |
for i, offset in enumerate(inputs["offset_mapping"]): | |
sample_idx = inputs["overflow_to_sample_mapping"][i] | |
answer = answers[sample_idx] | |
start_char = answer["answer_start"][0] | |
end_char = answer["answer_start"][0] + len(answer["text"][0]) | |
sequence_ids = inputs.sequence_ids(i) | |
# Find the start and end of the context | |
idx = 0 | |
while sequence_ids[idx] != 1: | |
idx += 1 | |
context_start = idx | |
while sequence_ids[idx] == 1: | |
idx += 1 | |
context_end = idx - 1 | |
# If the answer is not fully inside the context, label is (0, 0) | |
if offset[context_start][0] > start_char or offset[context_end][1] < end_char: | |
start_positions.append(0) | |
end_positions.append(0) | |
else: | |
# Otherwise it's the start and end token positions | |
idx = context_start | |
while idx <= context_end and offset[idx][0] <= start_char: | |
idx += 1 | |
start_positions.append(idx - 1) | |
idx = context_end | |
while idx >= context_start and offset[idx][1] >= end_char: | |
idx -= 1 | |
end_positions.append(idx + 1) | |
start_positions, end_positions |
([83, 51, 19, 0, 0, 64, 27, 0, 34, 0, 0, 0, 67, 34, 0, 0, 0, 0, 0], | |
[85, 53, 21, 0, 0, 70, 33, 0, 40, 0, 0, 0, 68, 35, 0, 0, 0, 0, 0]) |
让我们看一些结果来验证我们的方法是否正确。对于我们发现的第一个特征,我们将 (83, 85) 作为标签,让我们将理论答案与从 83 到 85 (包括) 的标记解码范围进行比较:
idx = 0 | |
sample_idx = inputs["overflow_to_sample_mapping"][idx] | |
answer = answers[sample_idx]["text"][0] | |
start = start_positions[idx] | |
end = end_positions[idx] | |
labeled_answer = tokenizer.decode(inputs["input_ids"][idx][start : end + 1]) | |
print(f"Theoretical answer: {answer}, labels give: {labeled_answer}") |
'Theoretical answer: the Main Building, labels give: the Main Building' |
所以这是一场比赛!现在让我们检查索引 4, 我们将标签设置为 (0, 0), 这意味着答案不在该功能的上下文块中
idx = 4 | |
sample_idx = inputs["overflow_to_sample_mapping"][idx] | |
answer = answers[sample_idx]["text"][0] | |
decoded_example = tokenizer.decode(inputs["input_ids"][idx]) | |
print(f"Theoretical answer: {answer}, decoded example: {decoded_example}") |
'Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]' |
事实上,我们在上下文中看不到答案。
现在我们已经逐步了解了如何预处理我们的训练数据,我们可以将其分组到一个函数中,我们将应用于整个训练数据集。我们会将每个特征填充到我们设置的最大长度,因为大多数上下文会很长 (并且相应的样本将被分成几个特征), 所以在这里应用动态填充没有真正的好处:
max_length = 384 | |
stride = 128 | |
def preprocess_training_examples(examples): | |
questions = [q.strip() for q in examples["question"]] | |
inputs = tokenizer( | |
questions, | |
examples["context"], | |
max_length=max_length, | |
truncation="only_second", | |
stride=stride, | |
return_overflowing_tokens=True, | |
return_offsets_mapping=True, | |
padding="max_length", | |
) | |
offset_mapping = inputs.pop("offset_mapping") | |
sample_map = inputs.pop("overflow_to_sample_mapping") | |
answers = examples["answers"] | |
start_positions = [] | |
end_positions = [] | |
for i, offset in enumerate(offset_mapping): | |
sample_idx = sample_map[i] | |
answer = answers[sample_idx] | |
start_char = answer["answer_start"][0] | |
end_char = answer["answer_start"][0] + len(answer["text"][0]) | |
sequence_ids = inputs.sequence_ids(i) | |
# Find the start and end of the context | |
idx = 0 | |
while sequence_ids[idx] != 1: | |
idx += 1 | |
context_start = idx | |
while sequence_ids[idx] == 1: | |
idx += 1 | |
context_end = idx - 1 | |
# If the answer is not fully inside the context, label is (0, 0) | |
if offset[context_start][0] > start_char or offset[context_end][1] < end_char: | |
start_positions.append(0) | |
end_positions.append(0) | |
else: | |
# Otherwise it's the start and end token positions | |
idx = context_start | |
while idx <= context_end and offset[idx][0] <= start_char: | |
idx += 1 | |
start_positions.append(idx - 1) | |
idx = context_end | |
while idx >= context_start and offset[idx][1] >= end_char: | |
idx -= 1 | |
end_positions.append(idx + 1) | |
inputs["start_positions"] = start_positions | |
inputs["end_positions"] = end_positions | |
return inputs |
请注意,我们定义了两个常数来确定使用的最大长度以及滑动窗口的长度,并且我们在标记化之前添加了一点清理: SQuAD 数据集中的一些问题在开头有额外的空格,并且不添加任何内容的结尾 (如果你使用像 RoBERTa 这样的模型,则在标记化时会占用空间), 因此我们删除了那些额外的空格。
为了将此函数应用于整个训练集,我们使用 Dataset.map () 方法与 batched=True 标志。这是必要的,因为我们正在更改数据集的长度 (因为一个示例可以提供多个训练特征):
train_dataset = raw_datasets["train"].map( | |
preprocess_training_examples, | |
batched=True, | |
remove_columns=raw_datasets["train"].column_names, | |
) | |
len(raw_datasets["train"]), len(train_dataset) |
(87599, 88729) |
正如我们所见,预处理增加了大约 1,000 个特征。我们的训练集现在可以使用了 — 让我们深入研究验证集的预处理!
在 map 的时候使用 batched=True ,那么传入函数中的 example 是不是就是好几条数据,怎么验证呢?
是的,直接在函数中打印即可。
# 处理验证数据
预处理验证数据会稍微容易一些,因为我们不需要生成标签 (除非我们想计算验证损失,但这个数字并不能真正帮助我们理解模型有多好)。真正的乐趣是将模型的预测解释为原始上下文的跨度。为此,我们只需要存储偏移映射和某种方式来将每个创建的特征与它来自的原始示例相匹配。由于原始数据集中有一个 ID 列,我们将使用该 ID。
我们将在这里添加的唯一内容是对偏移映射的一点点清理。它们将包含问题和上下文的偏移量,但是一旦我们进入后处理阶段,我们将无法知道输入 ID 的哪一部分对应于上下文以及哪一部分是问题 (我们使用的 sequence_ids () 方法仅可用于标记器的输出)。因此,我们将与问题对应的偏移量设置为 None:
# 使用 Trainer API 微调模型
# 使用 Trainer 的完整代码
from datasets import load_dataset | |
raw_datasets = load_dataset("squad") | |
raw_datasets["train"].filter(lambda x: len(x["answers"]["text"]) != 1) | |
# 处理训练数据 | |
from transformers import AutoTokenizer | |
model_checkpoint = "bert-base-cased" | |
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint) | |
max_length = 384 | |
stride = 128 | |
def preprocess_training_examples(examples): | |
questions = [q.strip() for q in examples["question"]] | |
inputs = tokenizer( | |
questions, | |
examples["context"], | |
max_length=max_length, | |
truncation="only_second", | |
stride=stride, | |
return_overflowing_tokens=True, | |
return_offsets_mapping=True, | |
padding="max_length", | |
) | |
offset_mapping = inputs.pop("offset_mapping") | |
sample_map = inputs.pop("overflow_to_sample_mapping") | |
answers = examples["answers"] | |
start_positions = [] | |
end_positions = [] | |
for i, offset in enumerate(offset_mapping): | |
sample_idx = sample_map[i] | |
answer = answers[sample_idx] | |
start_char = answer["answer_start"][0] | |
end_char = answer["answer_start"][0] + len(answer["text"][0]) | |
sequence_ids = inputs.sequence_ids(i) | |
# Find the start and end of the context | |
idx = 0 | |
while sequence_ids[idx] != 1: | |
idx += 1 | |
context_start = idx | |
while sequence_ids[idx] == 1: | |
idx += 1 | |
context_end = idx - 1 | |
# If the answer is not fully inside the context, label is (0, 0) | |
if offset[context_start][0] > start_char or offset[context_end][1] < end_char: | |
start_positions.append(0) | |
end_positions.append(0) | |
else: | |
# Otherwise it's the start and end token positions | |
idx = context_start | |
while idx <= context_end and offset[idx][0] <= start_char: | |
idx += 1 | |
start_positions.append(idx - 1) | |
idx = context_end | |
while idx >= context_start and offset[idx][1] >= end_char: | |
idx -= 1 | |
end_positions.append(idx + 1) | |
inputs["start_positions"] = start_positions | |
inputs["end_positions"] = end_positions | |
return inputs | |
train_dataset = raw_datasets["train"].map( | |
preprocess_training_examples, | |
batched=True, | |
remove_columns=raw_datasets["train"].column_names, | |
) | |
# 处理验证数据 | |
def preprocess_validation_examples(examples): | |
questions = [q.strip() for q in examples["question"]] | |
inputs = tokenizer( | |
questions, | |
examples["context"], | |
max_length=max_length, | |
truncation="only_second", | |
stride=stride, | |
return_overflowing_tokens=True, | |
return_offsets_mapping=True, | |
padding="max_length", | |
) | |
sample_map = inputs.pop("overflow_to_sample_mapping") | |
example_ids = [] | |
for i in range(len(inputs["input_ids"])): | |
sample_idx = sample_map[i] | |
example_ids.append(examples["id"][sample_idx]) | |
sequence_ids = inputs.sequence_ids(i) | |
offset = inputs["offset_mapping"][i] | |
inputs["offset_mapping"][i] = [ | |
o if sequence_ids[k] == 1 else None for k, o in enumerate(offset) | |
] | |
inputs["example_id"] = example_ids | |
return inputs | |
validation_dataset = raw_datasets["validation"].map( | |
preprocess_validation_examples, | |
batched=True, | |
remove_columns=raw_datasets["validation"].column_names, | |
) | |
from datasets import load_metric | |
metric = load_metric("squad") | |
from tqdm.auto import tqdm | |
def compute_metrics(start_logits, end_logits, features, examples): | |
example_to_features = collections.defaultdict(list) | |
for idx, feature in enumerate(features): | |
example_to_features[feature["example_id"]].append(idx) | |
predicted_answers = [] | |
for example in tqdm(examples): | |
example_id = example["id"] | |
context = example["context"] | |
answers = [] | |
# Loop through all features associated with that example | |
for feature_index in example_to_features[example_id]: | |
start_logit = start_logits[feature_index] | |
end_logit = end_logits[feature_index] | |
offsets = features[feature_index]["offset_mapping"] | |
start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist() | |
end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist() | |
for start_index in start_indexes: | |
for end_index in end_indexes: | |
# Skip answers that are not fully in the context | |
if offsets[start_index] is None or offsets[end_index] is None: | |
continue | |
# Skip answers with a length that is either < 0 or > max_answer_length | |
if ( | |
end_index < start_index | |
or end_index - start_index + 1 > max_answer_length | |
): | |
continue | |
answer = { | |
"text": context[offsets[start_index][0] : offsets[end_index][1]], | |
"logit_score": start_logit[start_index] + end_logit[end_index], | |
} | |
answers.append(answer) | |
# Select the answer with the best score | |
if len(answers) > 0: | |
best_answer = max(answers, key=lambda x: x["logit_score"]) | |
predicted_answers.append( | |
{"id": example_id, "prediction_text": best_answer["text"]} | |
) | |
else: | |
predicted_answers.append({"id": example_id, "prediction_text": ""}) | |
theoretical_answers = [{"id": ex["id"], "answers": ex["answers"]} for ex in examples] | |
return metric.compute(predictions=predicted_answers, references=theoretical_answers) | |
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint) | |
from transformers import TrainingArguments | |
args = TrainingArguments( | |
"bert-finetuned-squad", | |
evaluation_strategy="no", | |
save_strategy="epoch", | |
learning_rate=2e-5, | |
num_train_epochs=3, | |
weight_decay=0.01, | |
fp16=True, | |
push_to_hub=True, | |
) | |
from transformers import Trainer | |
trainer = Trainer( | |
model=model, | |
args=args, | |
train_dataset=train_dataset, | |
eval_dataset=validation_dataset, | |
tokenizer=tokenizer, | |
) | |
trainer.train() |