下面仅进行功能性介绍,具体设计待与团队成员商讨
# 用户的数据结构
- id(数据库自动生成,注册时不需要用户填写)
- 用户名
- 密码
- 邮箱
# 登录界面
# 功能
提供账号和密码登录和人脸登录两种,其中人脸登录仅在用户事先注册并录入人脸后后才能使用
提供注册
记录全局用户信息,其中 id 作为主要标识,当要向后端请求数据的使用 id,其他信息肯定也会在某些地方用得到
注册成功不用生成 token,登录才用
# 登录界面
sign-up-form 和 sign-in-form 是在子组件的登录和注册表单中定义的类名,但是样式却是在使用它们的父组件中才定义
在 vue 中,如果在子组件的标签中本身就有类名,则用到父组件中的时候,该类名是不会被去除的。vue 文件中使用的 <style scoped lang="less"> 是使得样式仅作用在本 vue 文件,如果在父 vue 文件中使用到了子组件的类名定义样式,最终该样式是可以作用到显示出来的网页上的。
类选择器和 id 选择器是可以在父子选择器中用的(空格隔开),因此我只需要对子组件进行
如果在子组件中使用了一个 div 包裹了所有其他的标签,即根标签只有一个 div(假设该组件的名字是 One),在父组件中使用 <One id="testdiv"></One> ,那么这个 id="testdiv" 最终作用到 One 组件的最外层的 div 上,该 div 的子标签不具有 id="testdiv"
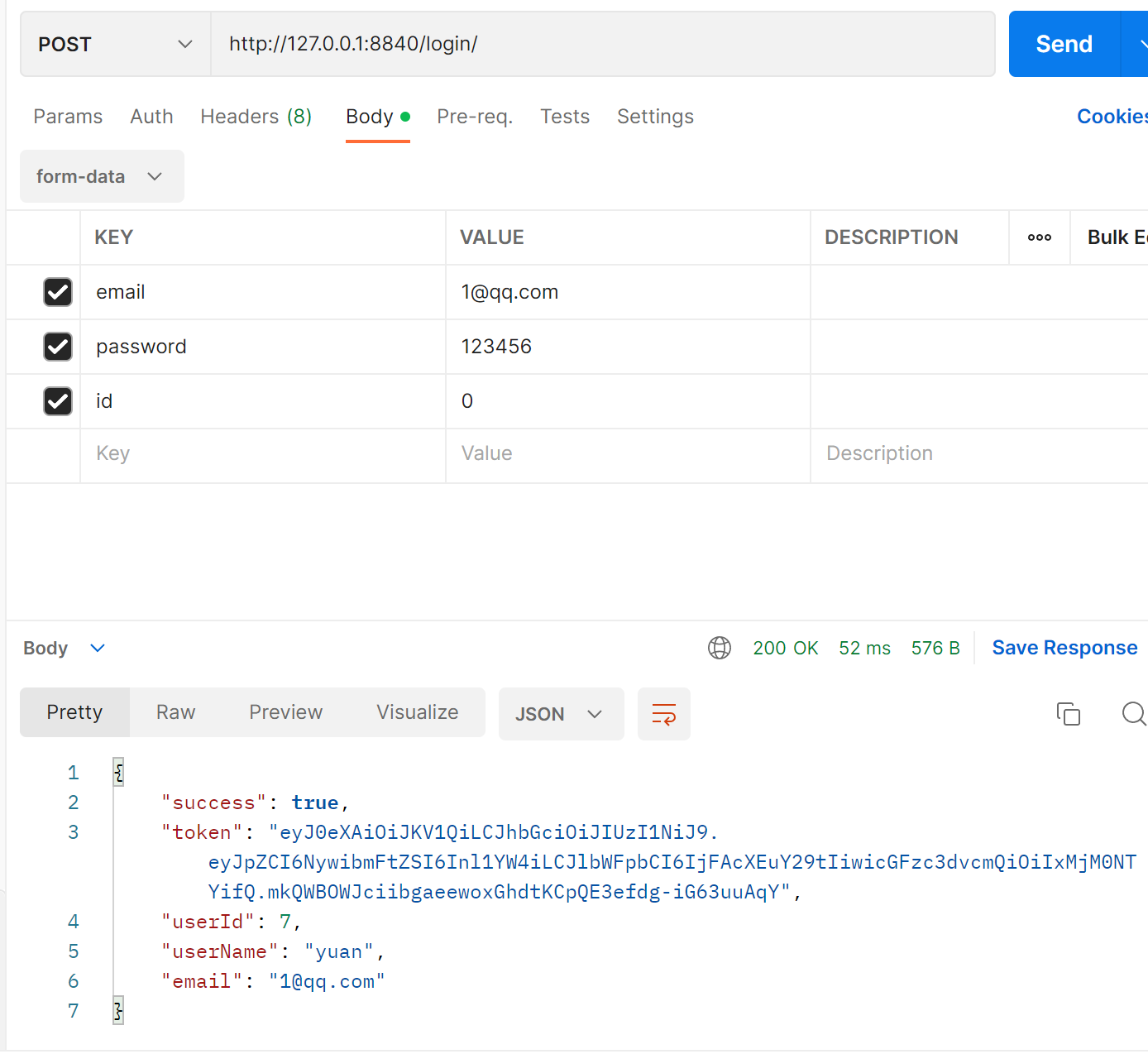

从 postman 中发送数据,在 django 中拿到的数据类型是 str
# 技术点
设置 vue 路由守卫,只有登录之后才能访问,否则不能进入主页面。(采用 jwt)
在全局 state 中设置一个保存用户信息的 cookie,
在路由守卫守卫中获取浏览器的 token 值,如果有的话,同时取出该用户的信息填入上述的全局用户信息中;如果没有的话,再跳转到登录界面
在密码登录时,在 vue 中先进行基本的数据合法检查,之后再用 axios 发送到 django 后端查找数据库中是否存在该用户
登录和注册使用的都是 post 方法,登录成功返回 post
对于表和视图函数
登录和注册使用的都是同一个表,以为需要验证的数据字段的个数不一样,因此使用两个序列化器
用户登录分为邮箱密码登录和人脸登录两种,前者属于表单登录,使用 post 方法;后者使用 get 登录,向后端传递图片的 base64、关键点坐标和框的坐标
人脸登录和账号登录都使用 post 发送数据,数据中另外加一个标识符,根据标识符使用不同的处理方式,另外还有人脸录入的功能,md,再使用一个标识符
- 账号登录
- 账号注册
- 人脸登录
- 人脸录入
应该在路由守卫中获取 token,并向后端发送请求查看此 token 是否有效,如果都可以,则跳过登录界面;如果有不行的,则移除 token 并跳转到登录界面
对于人脸录入,向后端发送的信息包括
- 操作符 id
- 用户 id
- 图片宽度
- 图片高度
- 关键点坐标
- 检测框位置
- 图片的 base64
在测试过程中,在登录时会存储全局信息 store,但是如果刷新之后,全局信息就没有了,但是 jwt-token 还在,可以不用登录就进入主界面,
我可以将用户的这些信息也存储在 token 中,因为这些信息不包括密码,本来也不是很隐私的。在路由守卫中获取这些信息置到全局信息 token 中。
在 ts 文件中是无法使用 pinia 的,所以换一种思路,如果当前全局 store 信息为空,则获取 token 的值,重新置到 store 中
You called this URL via POST, but the URL doesn't end in a slash and you have APPEND_SLASH set. Django can't redirect to the slash URL while maintaining POST data. Change your form to point to 127.0.0.1:8840/login/ (note the trailing slash), or set APPEND_SLASH=False in your Django settings.
、
在人脸登录时,先使用 mediapipe 检查摄像头是否检测到人脸,提供登录按钮。如果未检测到人脸,则在前端直接拒绝,如果检测到人脸,则生成 base64 发送到后端,后端检查数据库是否存在该人脸(设置余弦相似度阈值)并返回名字
# 主功能界面
# 用户的个人中心
# 录入人脸
使用人脸检测和姿态估计,防止录入姿态不对的人脸
# 人脸库的处理
之前做的桌面软件,用户有打开和关闭软件的动作,在这两个过程中才进行特征向量的读取和写入,其他时间特征向量都是报错在内存中的,
现在服务器也有打开和关闭,那么可以重用上面的操作,由于人脸特征向量使用 numpy 存储的,选择特定的文件夹,选择人物 id 文件名,numpy 直接导出
# 人脸登录
将 video 标签设置为绝对定位,就可以不用修改其他代码而只显示识别界面了
先在前端判断是否检测到人脸,如果点击登录时没有检测到人脸,则直接 alert,不向后端发送图片。
现在在向后端发送图片的时候,要同时传送图片的宽高。
# 找回密码功能
前端:弹出对话框,提示用户输入邮箱(发送验证码)和验证码,之后发送给后端校验后,将密码发送到邮箱。
后端:
# 其他的个性化功能如名字之类的参考其他设计
注意这里要同步数据库
参考网上的评论,决定数据库中不使用外键(自行搜索原因),因此我们在建立用户的表的时候要考虑到所有可能用到的字段
数据库使用关系型的 sqlite(大概率吧),也有可能是 mysql(小概率)
# md 编辑
https://blog.csdn.net/m0_46627407/article/details/126581340
https://blog.csdn.net/qq_40889256/article/details/108117721
https://juejin.cn/post/6915440865255112718
# 自习室(聊天室)
url 中使用正则表达式,将房间名提取出来,进入房间时使用相同的房间页面,相同的 view 函数
,但是发送 websocket 连接时使用到房间名,这样进入同一个房间的人就能连接到相同的
websocket 服务器了
# 坐姿方面
用户先自定义端正好坐姿时脸的高度,之后假如摄像头前的用户弓着腰导致坐姿不端正了,给予一定的提醒
# 手势切换 PPT
就是字面意思
设置内部 div 和浏览器界面之间无缝隙
# 运动姿态
基于人体骨架,譬如下蹲计数等
# nlp 领域的我不是很敢确定,gpt 可以用来做文本生成的,像辅助理解之类的应该有模型
在 huggingface 上找到的模型
# summarize
中文到中文:https://huggingface.co/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
https://huggingface.co/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
英文到中文:https://huggingface.co/csebuetnlp/mT5_m2o_chinese_simplified_crossSum?text=Videos+that+say+approved+vaccines+are+dangerous+and+cause+autism%2C+cancer+or+infertility+are+among+those+that+will+be+taken+down%2C+the+company+said.++The+policy+includes+the+termination+of+accounts+of+anti-vaccine+influencers.++Tech+giants+have+been+criticised+for+not+doing+more+to+counter+false+health+information+on+their+sites.++In+July%2C+US+President+Joe+Biden+said+social+media+platforms+were+largely+responsible+for+people's+scepticism+in+getting+vaccinated+by+spreading+misinformation%2C+and+appealed+for+them+to+address+the+issue.++YouTube%2C+which+is+owned+by+Google%2C+said+130%2C000+videos+were+removed+from+its+platform+since+last+year%2C+when+it+implemented+a+ban+on+content+spreading+misinformation+about+Covid+vaccines.In+a+blog+post%2C+the+company+said+it+had+seen+false+claims+about+Covid+jabs+%22spill+over+into+misinformation+about+vaccines+in+general%22.+The+new+policy+covers+long-approved+vaccines%2C+such+as+those+against+measles+or+hepatitis+B.%22We%27re+expanding+our+medical+misinformation+policies+on+YouTube+with+new+guidelines+on+currently+administered+vaccines+that+are+approved+and+confirmed+to+be+safe+and+effective+by+local+health+authorities+and+the+WHO%2C%22+the+post+said%2C+referring+to+the+World+Health+Organization.
中文到文言文
https://huggingface.co/raynardj/wenyanwen-chinese-translate-to-ancient
# 文本生成
从关键词生成文本:https://huggingface.co/cocoshe/gpt2-chinese-gen-ads-by-keywords
将句子改成带有修辞的:https://huggingface.co/figurative-nlp/Chinese-Simile-Generation
# 人脸模块
# 人脸对齐

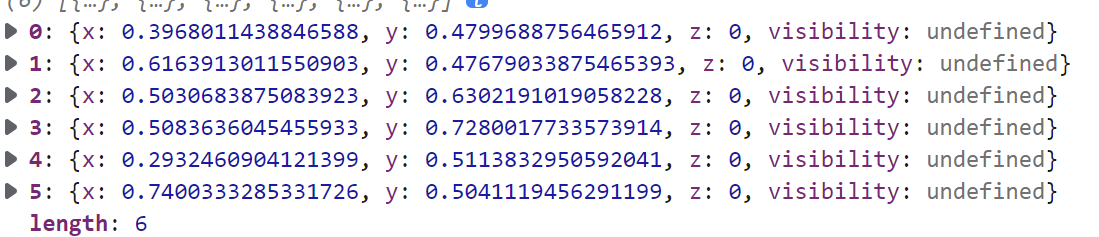
上面的图片和关键点是在 500x500 的摄像区域中操作的
大约估计如下
x=0.4, y=0.48 为左眼
x=0.6, y=0.48 为右眼
x=0.5, y=0.62 为鼻子
x=0.5, y=0.71 为上嘴唇尖点
x=0.3, y=0.5 为面部左侧点
x=0.75, y=0.5 为面部右侧点
x=0.4, y=0.48 为左眼
x=0.6, y=0.48 为右眼
x=0.5, y=0.62 为鼻子
x=0.5, y=0.71 为上嘴唇尖点
x=0.3, y=0.5 为面部左侧点
x=0.75, y=0.5 为面部右侧点
# 框


进行人脸对齐主要是使用相似变换矩阵,所以我们可以先把人脸图片给截出来,
登录和路由 https://www.bilibili.com/video/BV1Ad4y1z7X9?p=3&vd_source=1c562831fab1cb4101e5b95d41c170e0
人脸部分
- 人脸对齐
- 特征提取
- 前端获取的数据格式对应的调整
下面是关键点的位置坐标,只需要提取出 xy 并乘以图像的宽高就可以了
下面是框的信息
# 提取字段并乘以图像的宽高 | |
xCenter = myDict['xCenter'] * 500 | |
yCenter = myDict['yCenter'] * 500 | |
height = myDict['height'] * 500 | |
width = myDict['width'] * 500 | |
# 计算左上角坐标和右下角坐标 | |
left_corner = [xCenter - width / 2, yCenter - height / 2] | |
right_corner = [xCenter + width / 2, yCenter + height / 2] | |
# 得到 bbox |
# nlp 模块
# 文章续写
# uer/gpt2-chinese-cluecorpussmall
https://huggingface.co/uer/gpt2-chinese-cluecorpussmall
通过对 Common Crawl 的中文部分进行语料清洗,
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline | |
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall") | |
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-cluecorpussmall") | |
text_generator = TextGenerationPipeline(model, tokenizer) | |
text_generator("这是很久之前的事情了", max_length=100, do_sample=True) |
# 提取式 QA
# uer/roberta-base-chinese-extractive-qa
可以看看有没有 large
from transformers import AutoModelForQuestionAnswering,AutoTokenizer,pipeline | |
model = AutoModelForQuestionAnswering.from_pretrained('uer/roberta-base-chinese-extractive-qa') | |
tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-chinese-extractive-qa') | |
QA = pipeline('question-answering', model=model, tokenizer=tokenizer) | |
QA_input = {'question': "著名诗歌《假如生活欺骗了你》的作者是",'context': "普希金从那里学习人民的语言,吸取了许多有益的养料,这一切对普希金后来的创作产生了很大的影响。这两年里,普希金创作了不少优秀的作品,如《囚徒》、《致大海》、《致凯恩》和《假如生活欺骗了你》等几十首抒情诗,叙事诗《努林伯爵》,历史剧《鲍里斯·戈都诺夫》,以及《叶甫盖尼·奥涅金》前六章。"} | |
QA(QA_input) |
# 诗歌生成
# uer/gpt2-chinese-lyric
https://huggingface.co/uer/gpt2-chinese-lyric
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline | |
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-lyric") | |
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-lyric") | |
text_generator = TextGenerationPipeline(model, tokenizer) | |
text_generator("最美的不是下雨天,是曾与你躲过雨的屋檐", max_length=100, do_sample=True) |
现代诗歌
# uer/gpt2-chinese-poem
https://huggingface.co/uer/gpt2-chinese-poem
古文
from transformers import BertTokenizer, GPT2LMHeadModel,TextGenerationPipeline | |
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-poem") | |
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-poem") | |
text_generator = TextGenerationPipeline(model, tokenizer) | |
text_generator("[CLS]梅 山 如 积 翠 ,", max_length=50, do_sample=True) |
# 摘要
# csebuetnlp/mT5_m2o_chinese_simplified_crossSum
https://huggingface.co/csebuetnlp/mT5_m2o_chinese_simplified_crossSum?text=Videos+that+say+approved+vaccines+are+dangerous+and+cause+autism%2C+cancer+or+infertility+are+among+those+that+will+be+taken+down%2C+the+company+said.++The+policy+includes+the+termination+of+accounts+of+anti-vaccine+influencers.++Tech+giants+have+been+criticised+for+not+doing+more+to+counter+false+health+information+on+their+sites.++In+July%2C+US+President+Joe+Biden+said+social+media+platforms+were+largely+responsible+for+people's+scepticism+in+getting+vaccinated+by+spreading+misinformation%2C+and+appealed+for+them+to+address+the+issue.++YouTube%2C+which+is+owned+by+Google%2C+said+130%2C000+videos+were+removed+from+its+platform+since+last+year%2C+when+it+implemented+a+ban+on+content+spreading+misinformation+about+Covid+vaccines.In+a+blog+post%2C+the+company+said+it+had+seen+false+claims+about+Covid+jabs+%22spill+over+into+misinformation+about+vaccines+in+general%22.+The+new+policy+covers+long-approved+vaccines%2C+such+as+those+against+measles+or+hepatitis+B.%22We%27re+expanding+our+medical+misinformation+policies+on+YouTube+with+new+guidelines+on+currently+administered+vaccines+that+are+approved+and+confirmed+to+be+safe+and+effective+by+local+health+authorities+and+the+WHO%2C%22+the+post+said%2C+referring+to+the+World+Health+Organization.
this model tries to summarize text written in any language in Chinese(Simplified).
import re | |
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM | |
WHITESPACE_HANDLER = lambda k: re.sub('\s+', ' ', re.sub('\n+', ' ', k.strip())) | |
article_text = """Videos that say approved vaccines are dangerous and cause autism, cancer or infertility are among those that will be taken down, the company said. The policy includes the termination of accounts of anti-vaccine influencers. Tech giants have been criticised for not doing more to counter false health information on their sites. In July, US President Joe Biden said social media platforms were largely responsible for people's scepticism in getting vaccinated by spreading misinformation, and appealed for them to address the issue. YouTube, which is owned by Google, said 130,000 videos were removed from its platform since last year, when it implemented a ban on content spreading misinformation about Covid vaccines. In a blog post, the company said it had seen false claims about Covid jabs "spill over into misinformation about vaccines in general". The new policy covers long-approved vaccines, such as those against measles or hepatitis B. "We're expanding our medical misinformation policies on YouTube with new guidelines on currently administered vaccines that are approved and confirmed to be safe and effective by local health authorities and the WHO," the post said, referring to the World Health Organization.""" | |
model_name = "csebuetnlp/mT5_m2o_chinese_simplified_crossSum" | |
tokenizer = AutoTokenizer.from_pretrained(model_name) | |
model = AutoModelForSeq2SeqLM.from_pretrained(model_name) | |
input_ids = tokenizer( | |
[WHITESPACE_HANDLER(article_text)], | |
return_tensors="pt", | |
padding="max_length", | |
truncation=True, | |
max_length=512 | |
)["input_ids"] | |
output_ids = model.generate( | |
input_ids=input_ids, | |
max_length=84, | |
no_repeat_ngram_size=2, | |
num_beams=4 | |
)[0] | |
summary = tokenizer.decode( | |
output_ids, | |
skip_special_tokens=True, | |
clean_up_tokenization_spaces=False | |
) | |
print(summary) |
# IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
https://huggingface.co/IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
from transformers import PegasusForConditionalGeneration,BertTokenizer | |
# Need to download tokenizers_pegasus.py and other Python script from Fengshenbang-LM github repo in advance, | |
# or you can download tokenizers_pegasus.py and data_utils.py in https://huggingface.co/IDEA-CCNL/Randeng_Pegasus_523M/tree/main | |
# Strongly recommend you git clone the Fengshenbang-LM repo: | |
# 1. git clone https://github.com/IDEA-CCNL/Fengshenbang-LM | |
# 2. cd Fengshenbang-LM/fengshen/examples/pegasus/ | |
# and then you will see the tokenizers_pegasus.py and data_utils.py which are needed by pegasus model | |
from tokenizers_pegasus import PegasusTokenizer | |
model = PegasusForConditionalGeneration.from_pretrained("IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese") | |
tokenizer = PegasusTokenizer.from_pretrained("IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese") | |
text = "在北京冬奥会自由式滑雪女子坡面障碍技巧决赛中,中国选手谷爱凌夺得银牌。祝贺谷爱凌!今天上午,自由式滑雪女子坡面障碍技巧决赛举行。决赛分三轮进行,取选手最佳成绩排名决出奖牌。第一跳,中国选手谷爱凌获得69.90分。在12位选手中排名第三。完成动作后,谷爱凌又扮了个鬼脸,甚是可爱。第二轮中,谷爱凌在道具区第三个障碍处失误,落地时摔倒。获得16.98分。网友:摔倒了也没关系,继续加油!在第二跳失误摔倒的情况下,谷爱凌顶住压力,第三跳稳稳发挥,流畅落地!获得86.23分!此轮比赛,共12位选手参赛,谷爱凌第10位出场。网友:看比赛时我比谷爱凌紧张,加油!" | |
inputs = tokenizer(text, max_length=1024, return_tensors="pt") | |
# Generate Summary | |
summary_ids = model.generate(inputs["input_ids"]) | |
tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0] | |
# model Output: 滑雪女子坡面障碍技巧决赛谷爱凌获银牌 |
# 现代中文和文言文的翻译
# raynardj/wenyanwen-chinese-translate-to-ancient
https://huggingface.co/raynardj/wenyanwen-chinese-translate-to-ancient
from transformers import ( | |
EncoderDecoderModel, | |
AutoTokenizer | |
) | |
PRETRAINED = "raynardj/wenyanwen-chinese-translate-to-ancient" | |
tokenizer = AutoTokenizer.from_pretrained(PRETRAINED) | |
model = EncoderDecoderModel.from_pretrained(PRETRAINED) | |
def inference(text): | |
tk_kwargs = dict( | |
truncation=True, | |
max_length=128, | |
padding="max_length", | |
return_tensors='pt') | |
inputs = tokenizer([text,],**tk_kwargs) | |
with torch.no_grad(): | |
return tokenizer.batch_decode( | |
model.generate( | |
inputs.input_ids, | |
attention_mask=inputs.attention_mask, | |
num_beams=3, | |
bos_token_id=101, | |
eos_token_id=tokenizer.sep_token_id, | |
pad_token_id=tokenizer.pad_token_id, | |
), skip_special_tokens=True) |

# 环境配置
pip install --no-binary=protobuf protobuf
# 界面设计篇
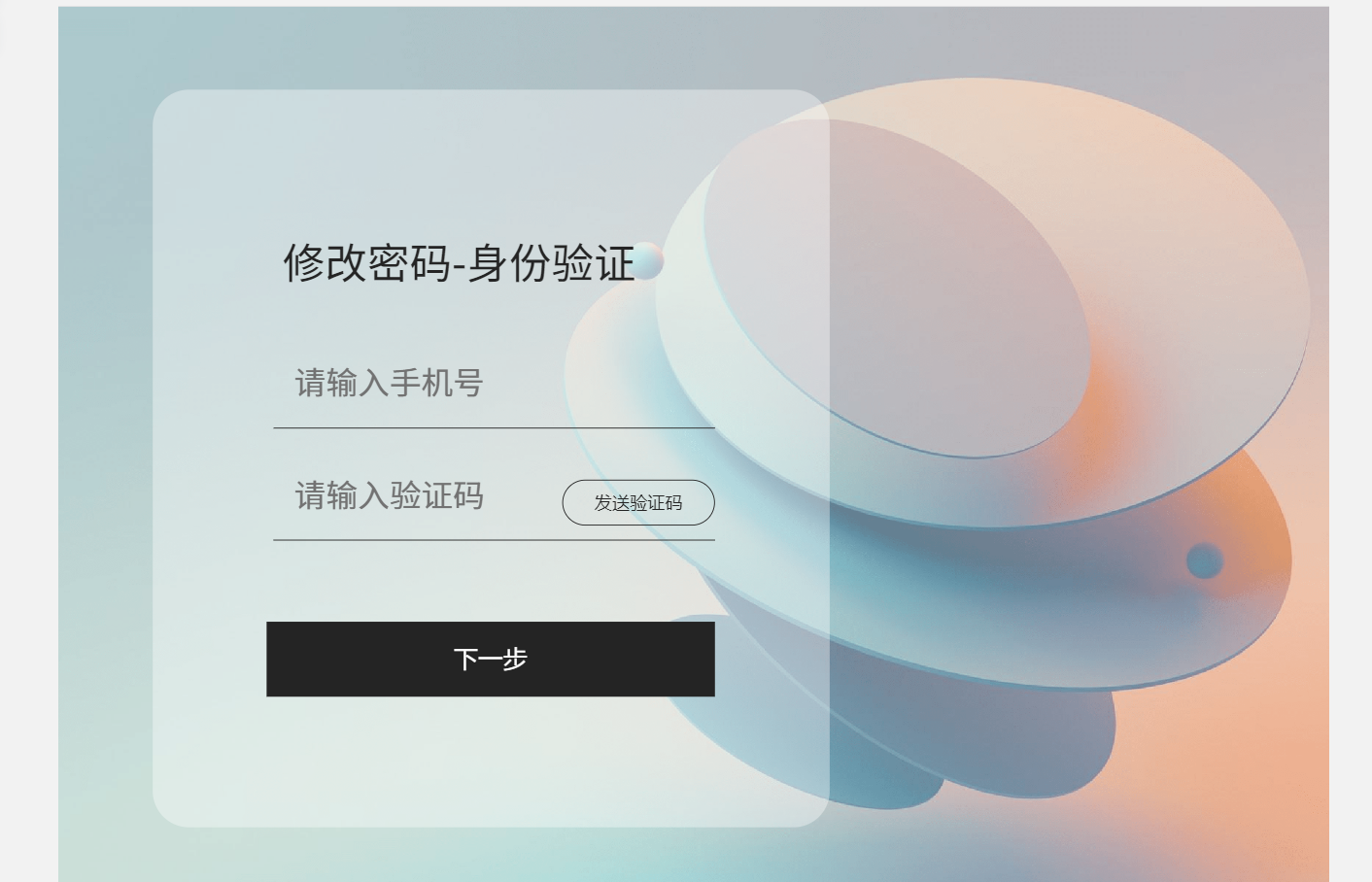
模糊效果
整体参考
https://modao.cc/community/mtkkqgddgzmqcxlp?title = 私人医疗健康管理平台【01】
https://modao.cc/community/mtkty7weivdy4sbb?title = 仓库巡检平台
在首页上展示基本的学习情况,如一周以来的学习时长,每日一句,TODO
高度和宽度分别使用 vh 和 vw 作为单位,这个是将浏览器视图进行划分的方法,
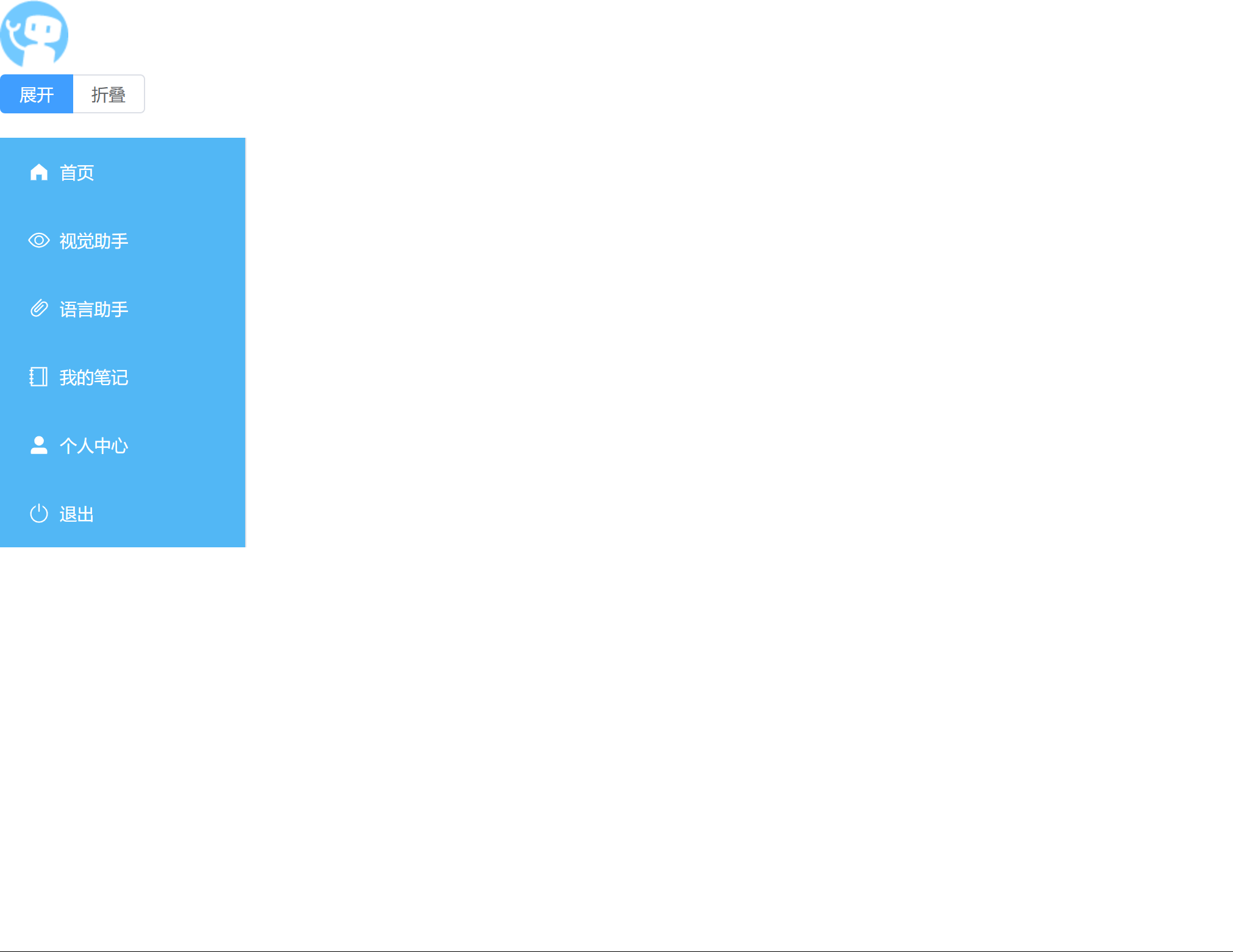
- 如何将侧边栏占满余下的全部高度呢?
将侧边栏的三个部分进行 vh 划分,
<el-menu default-active="user" class="el-menu-vertical-demo" :collapse="isCollapse" | |
@open="handleOpen" @close="handleClose" :router="true" text-color="#fff" | |
background-color='#52B7F5' style="border-radius: var(--el-border-radius-round);" |
应该添加一个顶部栏的
在左侧导航栏折叠和打开的时候,其占有的宽度应该要发生改变,这里可以使用计算属性或者监听控制展开和折叠的选项,
另外展开和折叠变成一个,
顶部可以显示一些激励性的话语
导航栏折叠和展开时内容之间的宽度占比是不一样的,控制类名
当使用编程式导航时,运行 router.push('/pdfControl') 时,如果该路由使用的界面是某个组件的子组件时(如这里在有侧边栏的主界面中使用 pdfControl),侧边栏是不会变的。
pdf 采用的是绝对定位,所以 上一页 的按钮不应该放在 pdf 的下面,这里就选择放在右侧吧
那怎么保证 pdf 一定在界面内呢?貌似仅仅调节 id="pdf-container" 的宽度,它就可以进行自适应的调整高度了
<el-row> | |
<el-col :span="24"> | |
<div class="facedetect"> | |
<!-- 注意下面的两个标签都设置镜像翻转 --> | |
<div class="videocanvas"> | |
<video ref="videoElement" style="transform:rotateY(180deg)"></video> | |
<canvas class="output_canvas" ref="canvasElement" :width="canvasWidth" | |
:height="canvasHeight" style="transform:rotateY(180deg)"></canvas> | |
</div> | |
</div> | |
</el-col> | |
</el-row> |
控制 el-col 或 el-row 的内容居中用 justify-content: center;
在选择 pdf 之后,它的高度和宽度是自己计算出来的,认为的给定高度或宽度都会造成拉伸。所以应该主动获取元素的高度和宽度
在 url 改变的时候,整个文档还没加载出来,因此获取的宽度和高度都是之前加载的文档的。
那就同时给定高度和宽度的调节滑块
当首次使用滑块的时候先拿到 canvas 的值,
当成功切换文件时重置
设置弹出消息的时候,给出一个布尔值,当第一次坐姿不端正时,设置布尔值为 true,
当坐姿端正后,需要系统自动关闭消息弹出框,
自习研讨室
自习室应该显示有数量显示
先在侧边栏点进去的时候,有目前公开的自习室列表,同时支持用户自行创建一个自习室,
先不设置自习室的时长功能,貌似这个得要设置死循环,在循环中不断查看当前时间,
前端界面中的自习室列表功能得需要 websocket 连接,因为当有用户新创建了一个自习室的时候,要及时更新所有用户的自习室列表。
自习室还得提供群主功能,如果群主关闭连接了,则自习室就解散了,使用 StopConsumer() ,那么就要标识群主的身份。
创建自习室就是创建一个 websocket 连接,
当目前已在一个自习室中仍要加入其他自习室的时候,要弹出提示框说明 “您当前在一个自习室中,加入新的自习室将自动退出当前自习室”
房间的区分依靠的是名字,同时使用正则表达式,将房间的名字放在 websocket 连接的 url 的最后。
房间列表的 websocket 连接的 url 是固定的
我先根据名称连接上,后端从 url 中提取出名称,然后全部的连接都进行保存,
查看连接的时候能不能携带信息过去
- 我要怎么把创建的房间名称传给后端呢?
设置 id 字段,
创建房间(在创建后发送)
id: 0
room_name:
theme:
permission: private / public
根据 permission 字段来确定保存不保存当前连接对象,方面后面的信息列表获取
加入房间:
id: 1
room_name:
python 中的列表可以同时装不同的数据类型
采用字典,键值对为:
- 房间名 -->[连接对象,...]
在使用列表保存所有的房间名和其对应的主题
[{name:'k', 'theme': 'k'}, ... ]
正常聊天功能
id: 2
sentence: 句子
加入自习室和创建自习室可以写到一起,判断当前自习室是否存在就行了
在房间信息中要包括房间人数
在服务端可以推送什么类型的数据给前端呢?只能是字符串么?可以是字典类型么?
在创建房间的时候同时发送两个 websocket 数据
影响公开的房间信息的时间有:
- 当创建新房间时
- 有人加入房间时(人数变化)
- 有人离开房间导致该房间的人数为空时(房间自动删除)
两个后端 consumer 不能直接通信,但是可以通过前端来进行间接通信。
roomListSocket 首次连接时,后端向前端推送所有的房间信息。
当有人通过 chatSocket 创建新房间的时候,前端同时通过
当有人通过 chatSocket 加入房间时,前端同时通过 roomListSocket 发送请求,之后后端向所有的前端用户推送最新的房间信息
有人离开房间(chatSocket 关闭)导致房间的人数或房间的总个数发生变化时,在 chatSocket 的 onclose 方法中向 roomListSocket 发送信息,之后 roomListSocket 向所有前端用户推送最新的房间信息
前端从后端拿到的数据有两种类型:
- 房间信息 info_id = 0
- 转发的聊天信息 info_id = 1
没必要进行上面的区分,两个信息是通过不同的 socket 进行交流的
目前发现当前端进行刷新的时候,前端应该是关闭连接了,但是房间中的人数却没有发生变化,说明后端是没有删除 consumer 对象的
上面应该是 vue 热加载的缘故,当手动关闭连接的时候,后端的 websocket_disconnect 是正常运作,删除关闭连接的对象的
如果我能创建带有类名的元素,
对于统计用户时长,在进入页面的时候拿到当前时间并保存到 token 中,在关闭页面的时候拿到当前时间
数据库那里怎么保存用户时长呢?
数据库建立 8 个字段,分别为用户 id,周日~周六的在线时长
我在前端这里拿到的是在线时长,发送到后端的话包括今天是星期几,
用户一天内可以有多次登录系统,这些时长应该被累加起来,但是在数据库中还保存有上一个星期的时间统计?难道要人为清除?
在每个分钟的 0 秒发送一个字段到后端,后端检测到有几个这种字段,就是用户在线了几分钟
每分钟的 0 秒前端发送一个特殊字段到后端
后端收到以后,把数据库里的在线时长(分钟)字段 + 1
在线时长用 int 存储
单位是分钟
一天内甭管登录多少次都是正常累加的
所以后端还需要保存一个 “last modified” 字段
来记录上一次修改这个 int 存储的在线时长的时间
如果发现上次修改在线时长已经是 1 天前了,清零
用 post 方式,
前端对该数据库有两种请求
- 获取这一个星期的数据
- 更新这一天的数据
用户进入首页的时候,首页请求用户的在线时长数据,
用户登录之后,在 NewIndex 页面中,每隔一分钟就发送数据
两个都使用 post 方法,那么就要用 id 字段来进行区分。
获取数据
id: 0
user_id: number
更新这一天的数据
id: 1
user_id: number
day: number
如果在获取或更新的时候在数据库中没有该 user_id 的数据,则先创建一条
# 注册
# 验证码功能
在仅输入邮箱的情况下,可以将邮箱发送到后端,后端返回发送信息给前端,如果前端根据返回信息检测到邮箱发送失败,则提示用户检查邮箱是否输入正确。
对于时间戳,不用进行年月日,时分秒转换。只要比较两个时间戳的差值就行了
设置一个全局字典,保存键值对
邮箱 -》 验证码 + 时间戳
拿到邮箱之后,先检查该邮箱是否在全局字典中,如果在全局字典中,检查时间是否超过 60 秒。如果超过则重新生成验证码并发送,如果没有超过则返回剩余给前端,前端再提醒。
如果发送失败则返回邮箱可能不正确的信息给前端,前端再提醒
表单验证中,增加验证码字段
设置不为空即可。
设置每个邮箱只能注册一次
那就还要加上用户的注销
# 全局用上人脸检测功能
建立全局变量存储
# 解决人脸检测宽度和高度问题
如果实现设定高度的话,那么页面在缩放时会产生问题
查看别人的网站可以知道,当浏览器的缩放比例为 100% 时,页面正好完全显示,当把页面放得更大的时候或者浏览器的窗口变小的时候,浏览器的窗口内是出现滚动条的
vh、vw 是根据浏览器窗口设置比例的,就不能使用了
如果直接用 px 作为高度和宽度的单位,那么当高度和宽度超过浏览器的大小的时候,会自动出现滚动条。
但是,这样子做的话,在手机界面上打开就相当于缩小的浏览器,就会出现界面的不适配。
# 跨域问题解决
# 访问公开的接口
当在本机上运行的时候,可以正常访问到公开的接口
https://tenapi.cn/zhihuresou/
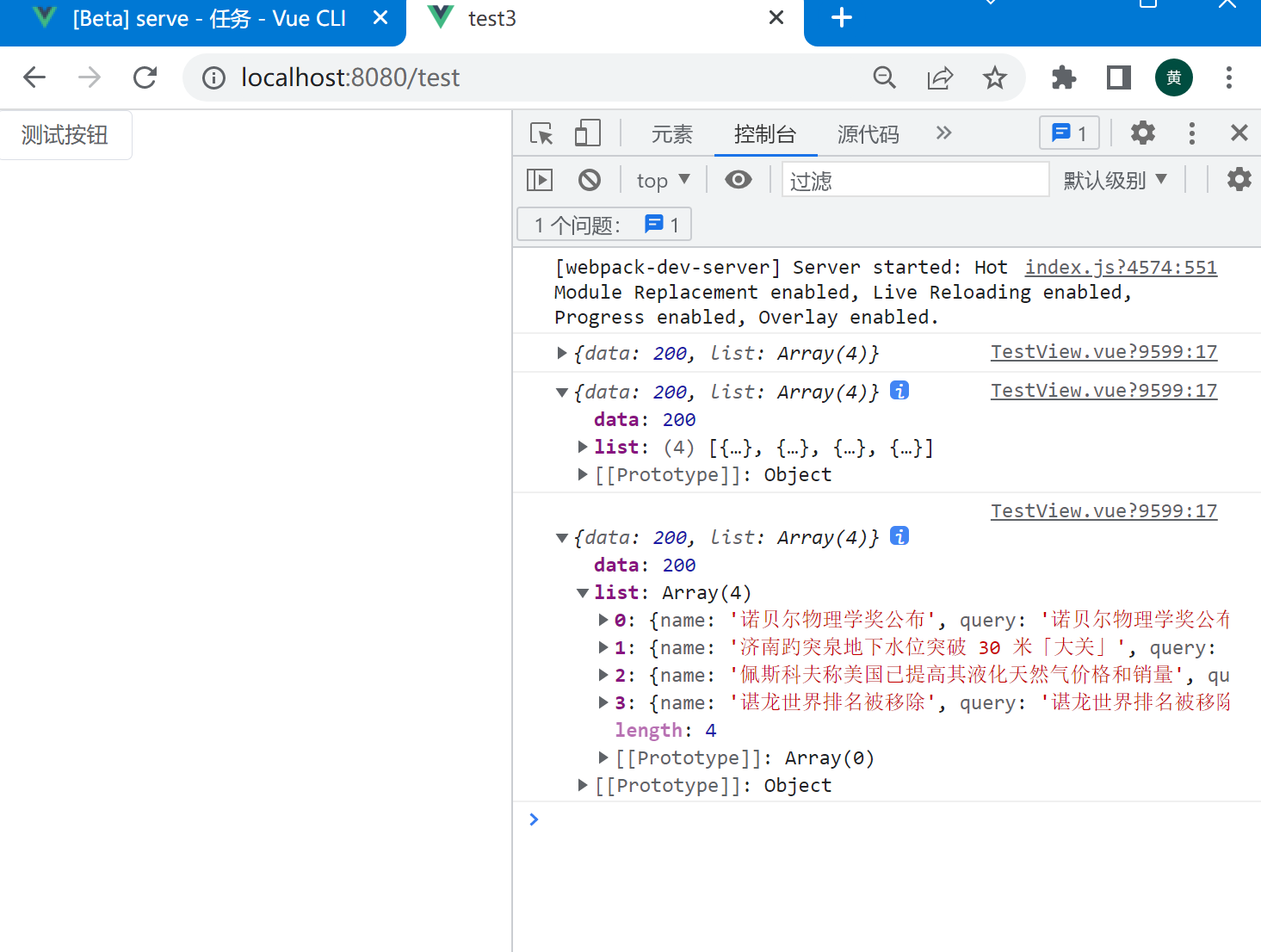
在虚拟机访问网页也是可以访问公开的接口的
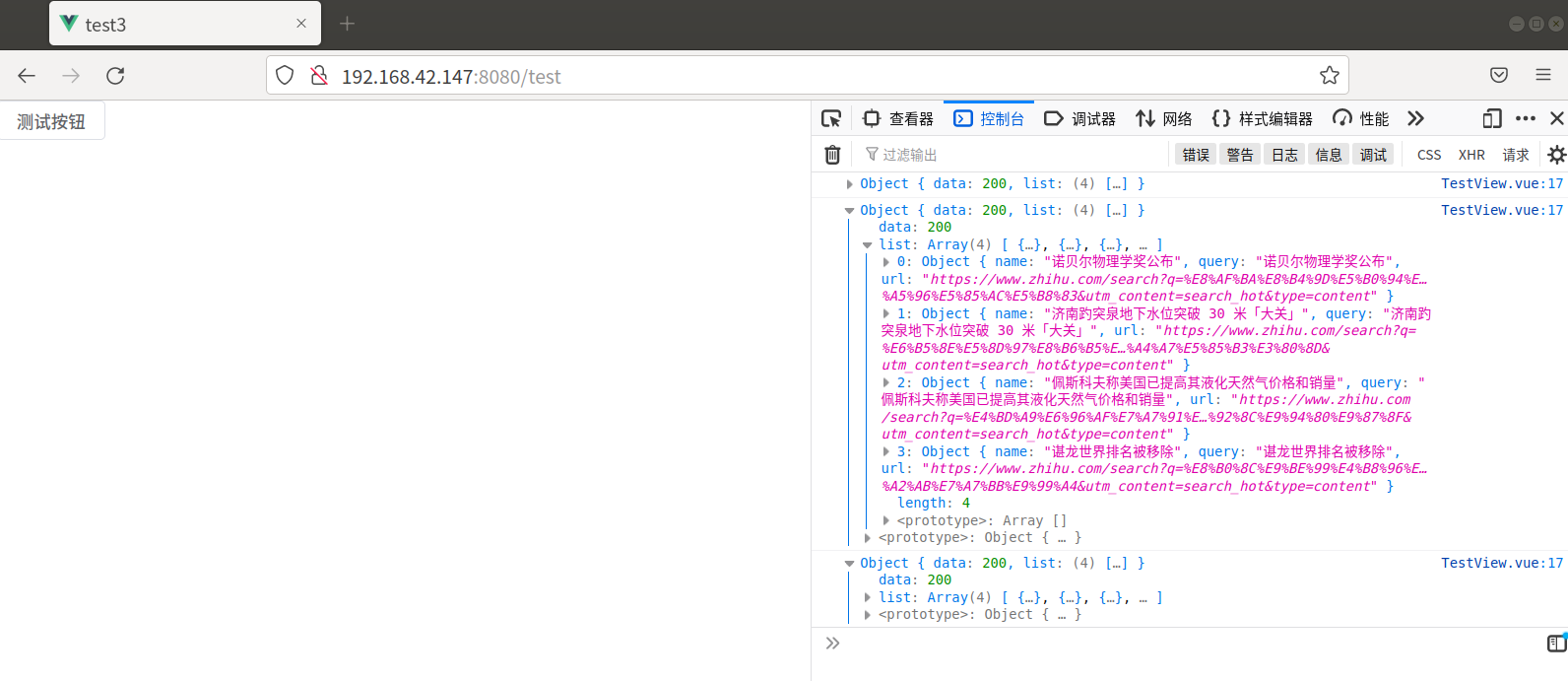
# 访问自己写的接口
在本机上运行可以正常访问
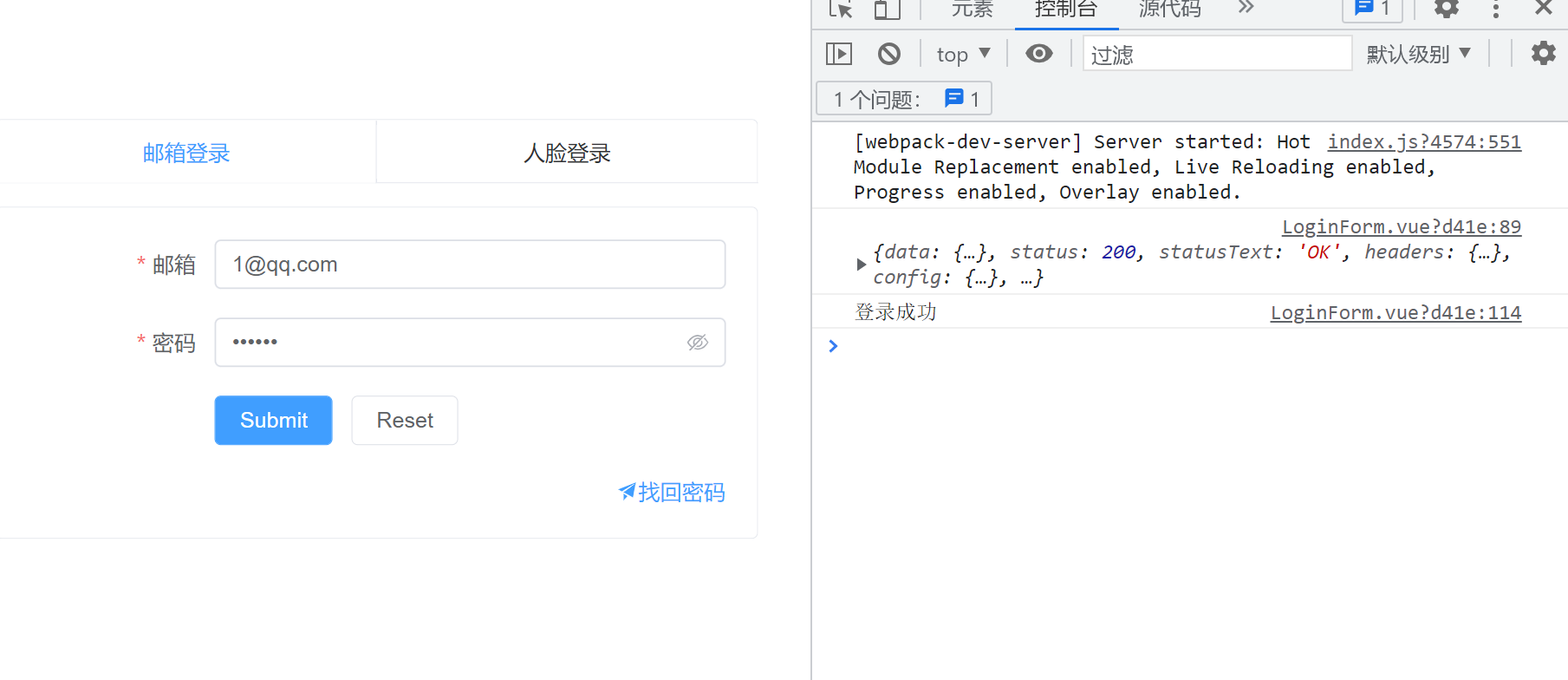
在虚拟机上访问时出错
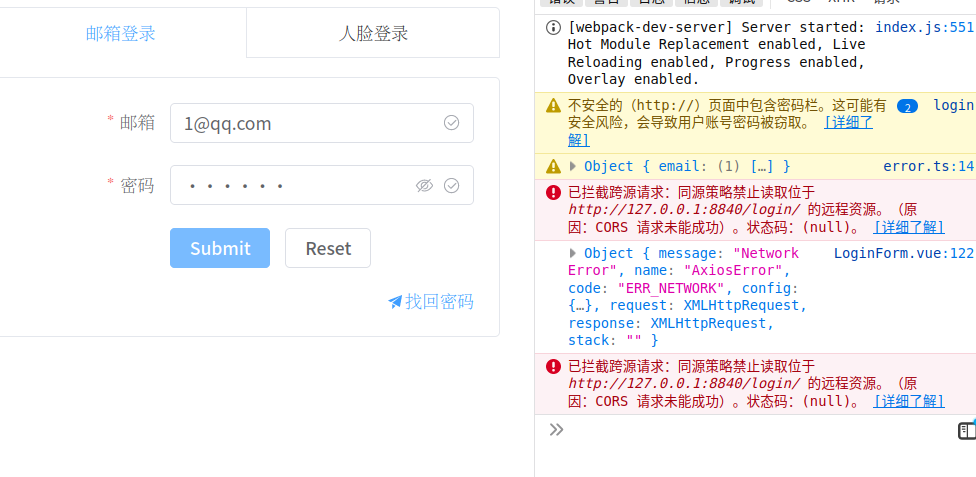
此时后端没有收到任何响应,推测是前端代码或者浏览器的问题
已拦截跨源请求:同源策略禁止读取位于 http://127.0.0.1:8840/login/ 的远程资源。(原因:CORS 请求未能成功)。
# 尝试解决
上面两个请求一个 https、一个是 http。推测是浏览器自动拦截了 http 的请求
后来尝试了
# 目前解决方案
使用 zerotier 内网穿透,得到本机的内网地址,之后访问网页和请求都是向这个网址

django 后端 runserver 0.0.0.0:8840,并在 drfdemo(项目名)的 setting.py 中 ALLOWED_HOSTS = ['10.241.126.172']
在本机上运行可以正常访问
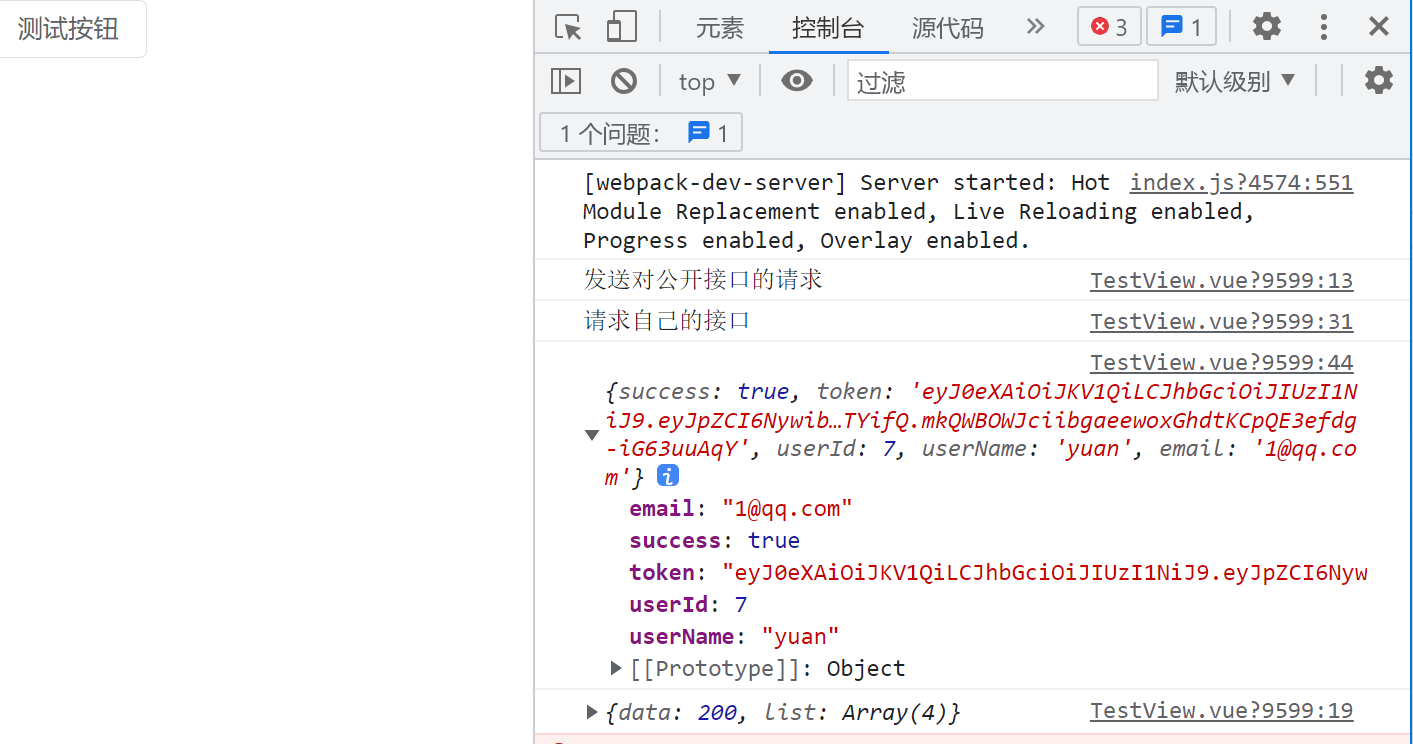
在虚拟机上也可以正常访问了(自己的接口和公开的 https 接口)
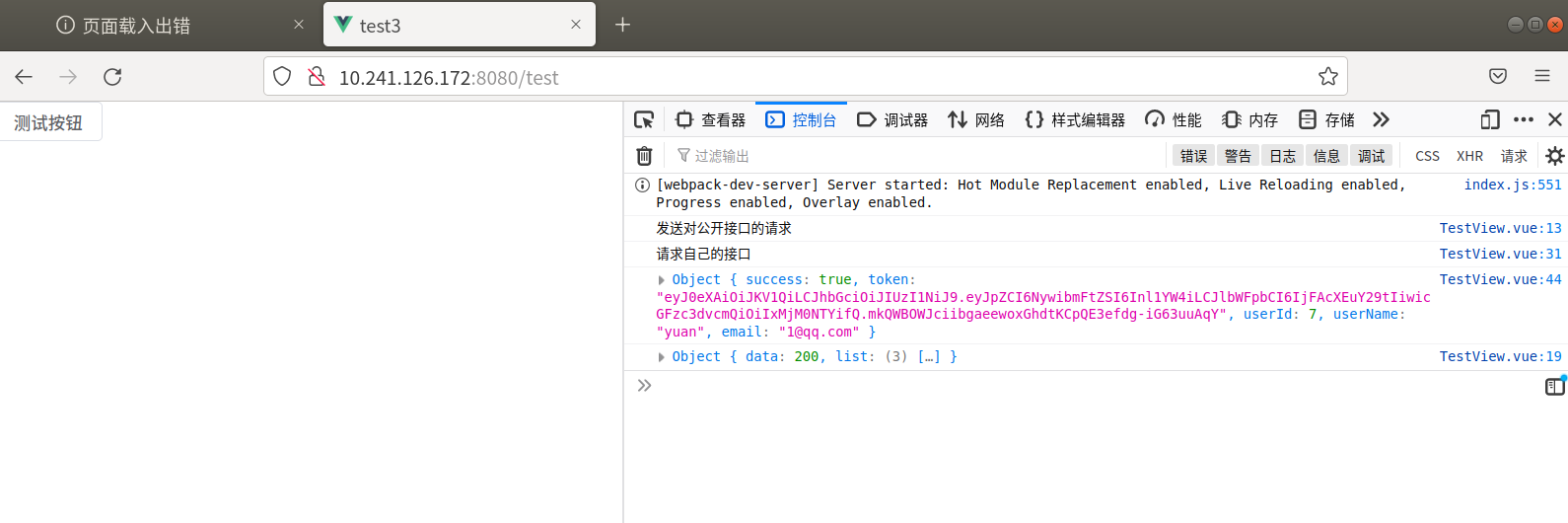
但值得注意的时,这时候访问网页的网址不再是 vue ui 中输出的地址了,而是 zerotier 中创建的地址
# 浏览器的摄像头问题
通过内网穿透访问摄像头时出现错误,但是之前不使用内网穿透访问摄像头时没有出错,说明不是浏览器的版本之类的问题
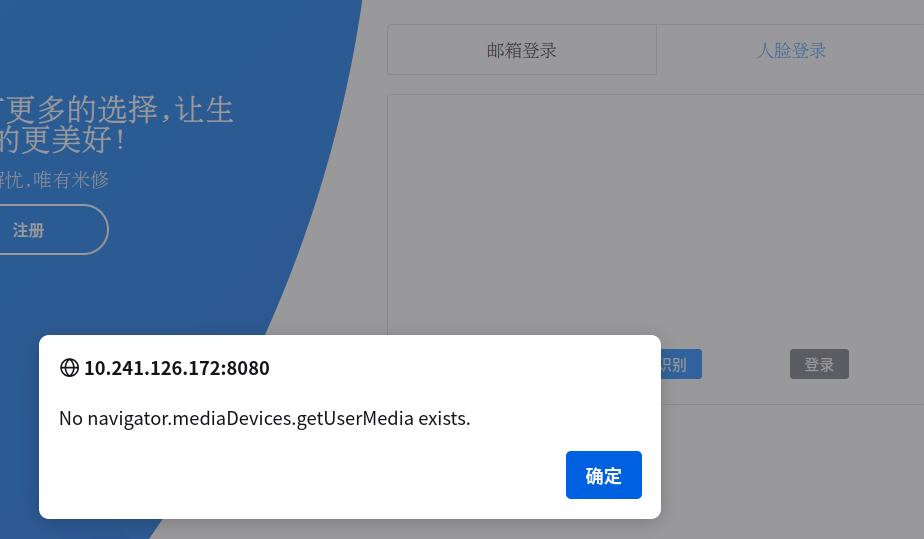
No navigator.mediaDevices.getUserMedia exists.
http://localhost:8000/tasks/D:\Projects\vue_projects\testpiana\test3:serve
# 界面设计调整
# 我的笔记
两个部分的内容所占的 px 是固定的,不应该使用浏览器窗口作为宽度单位
在 LoginRegister 中,最外层的 div(类名为 container)设置宽度为 100% 了,应该是撑满整个父盒子的意思,但是在窗口的大小变化的时候(浏览器的窗口大小变化),它的高度和宽度是会发生变化的
怎样才能将 container 的高度和宽度设置为浏览器能打开的最大高度和宽度呢?
目前给 container 设置了 min-width,这样在宽度缩小到一定的宽度时会出现的滚动条。
但是继续缩小时,整个动画笑话就会乱掉。
<el-row class="row1"> | |
<el-col :span="2" style="text-align:center;"> | |
<!-- <el-col :span="2" style="text-align:center;line-height: 10vh;"> --> | |
<a href="http://localhost:8080/NewIndex"> | |
<div> | |
<img src="@/assets/robot.png" alt=""> | |
</div> | |
</a> | |
</el-col> | |
<el-col :span="3" | |
style="text-align:center;font-weight: bolder;font-style: italic;font-size: larger;"> | |
<span style="color:cornflowerblue;">AI学习</span> | |
<span style="color:green">助手</span> | |
</el-col> | |
<el-col :span="19" style="text-align:right;"> | |
<el-button type="success" :icon="SwitchButton" round @click="logOut">退出登录</el-button> | |
</el-col> | |
</el-row> |
https://blog.csdn.net/qq_24767091/article/details/119385206