# 使用流程控制语句的存储过程
# 任务描述
本关任务:创建一个存储过程,向表 fibonacci 插入斐波拉契数列的前 n 项。
# 相关知识
为了完成本关任务,你需要掌握:
- 变量的定义与赋值;
- 复合语句与流程控制语句;
- 存储过程的定义;
- 存储过程的创建和调用;
- 存储过程的查询和删除。
# 变量的定义与赋值
用 declare 语句定义变量,并赋予默认值或初始值,未赋默认值 则初始值为 null:
DECLARE var_name [, var_name] ... type [DEFAULT value] |
上面的 type 是啥意思,如果同时有多个变量,那么 default 是不是同时设置这多个变量为同一个值
用 set 语句给变量赋值:
SET variable = expr [, variable = expr] |
set 语句还可以设置许多 MySQL 的配置参数。
还可以通过 select 语句给变量赋值:
select col into var_name from table; #将 table 表中的 col 列值赋给变量 |
上面的语句中,是将表中这一列的数据都一次性赋值给变量么?如果是多列数据呢
select 语句可以带复杂的 where,group by,having 等短语。
# 补充
mysql 中变量不用事前申明,在用的时候直接用 “ @变量名 ” 使用就可以了。
https://www.cnblogs.com/franson-2016/p/11640452.html#:~:text=mysql 中变量不用事前申明,在用的时候直接用 “%40 变量名” 使用就可以了。 第一种用法:set %40num%3D1%3B 或 set %40num%3A%3D1%3B %2F%2F 这里要使用变量来保存数据,直接使用 %40num 变量 第二种用法:select,%40num%3A%3D1%3B 或 select %40num%3A%3D 字段名 from 表名 where ……
https://www.cnblogs.com/Marydon20170307/p/14112059.html
# 复合语句与流程控制语句
MySQL 常用的语句有:
# 复合语句 BEGIN...END
BEGIN | |
[statement_list] | |
END; |
# if 语句
IF search_condition THEN statement_list | |
[ELSEIF search_condition THEN statement_list] ... | |
[ELSE statement_list] | |
END IF; |
# while 语句
WHILE search_condition DO | |
statement_list | |
END WHILE; |
程序的三种基本结构是顺序、选择、循环。上述语句可以用来构建复杂的程序。其实 MySQL 还有很多其它语句,这里不一一介绍 。更详细内容,请参考 MySQL 的手册。
# 存储过程的定义
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的 SQL 语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
简单的说存储过程就是具有名字的一段代码,用来完成一个特定的功能。
# 存储过程的创建和查询
创建存储过程: create procedure 存储过程名(参数)
# 下面我们来创建第一个存储过程
每个存储的程序都包含一个由 SQL 语句组成的主体。此语句可能是由以分号( ; )字符分隔的多个语句组成的复合语句。例如:
CREATE PROCEDURE proc1() | |
BEGIN | |
SELECT * FROM user; | |
END; |
在命令行客户端中,如果有一行命令以分号结束,那么回车后,MySQL 将会执行该命令,但在创建存储过程中我们并不希望 MySQL 这么做。
MySQL 本身将分号识别为语句分隔符,因此必须临时重新定义分隔符以使 MySQL 将整个存储的程序定义传递给服务器。
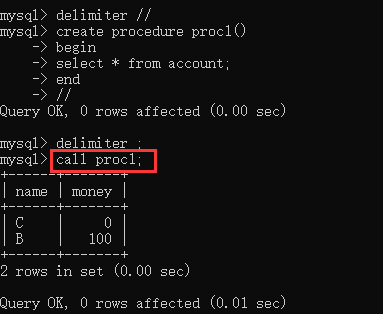
要重新定义 MySQL 分隔符,请使用 delimiter 命令。使用 delimiter 首先将结束符定义为 //,完成创建存储过程后,使用 // 表示结束,然后将分隔符重新设置为分号( ; ):
DELIMITER // | |
CREATE PROCEDURE proc1() | |
BEGIN | |
SELECT * FROM user; | |
END // | |
DELIMITER ; |
注意: / 也可以换成其他符号,例如 $ ;
# 执行存储过程: call 存储过程名
# 创建带有参数的存储过程
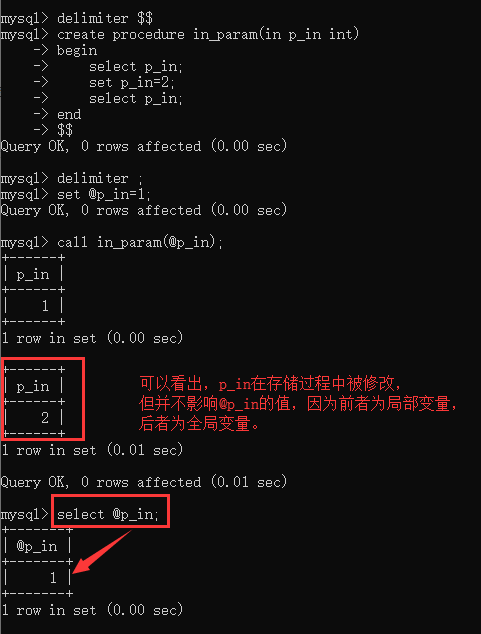
存储过程的参数有三种:
存储过程的参数有三种:
IN:输入参数,也是默认模式,表示该参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回;
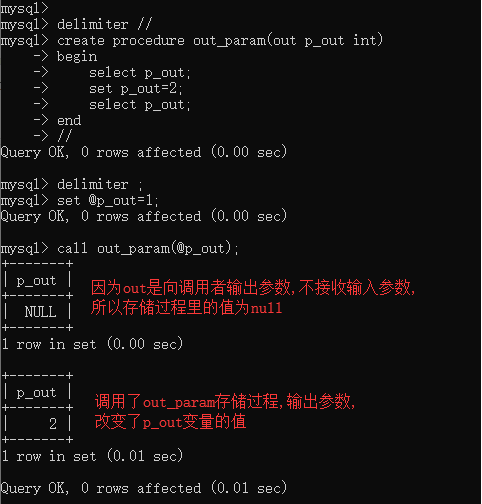
OUT:输出参数,该值可在存储过程内部被改变,并可返回;
INOUT:输入输出参数,调用时指定,并且可被改变和返回。
IN 参数示例:
OUT 参数示例:
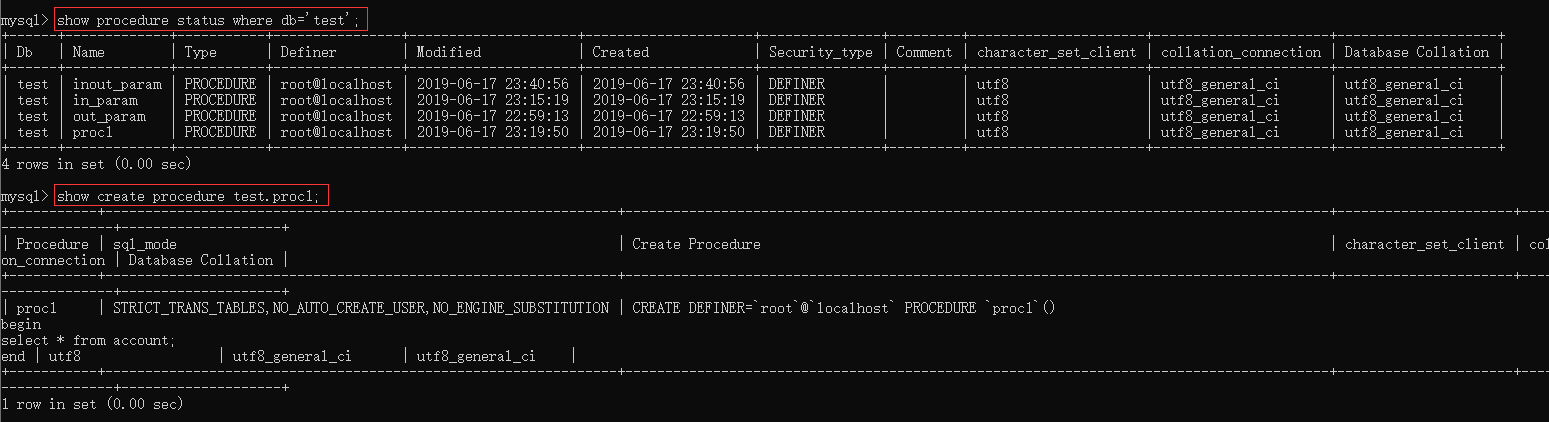
# 存储过程的查询和删除
SHOW PROCEDURE STATUS WHERE db='数据库名'; |
查看存储过程的详细定义信息:
SHOW CREATE PROCEDURE 数据库.存储过程名; |
当我们不再需要某个存储过程时,我们可以使用:
DROP PROCEDURE [IF EXISTS] 数据库名.存储过程名; |
# 编程要求
数据库中有表 fibonacci,用来储存斐波拉契数列的前 n 项:

斐波拉契数列的前 5 项为:
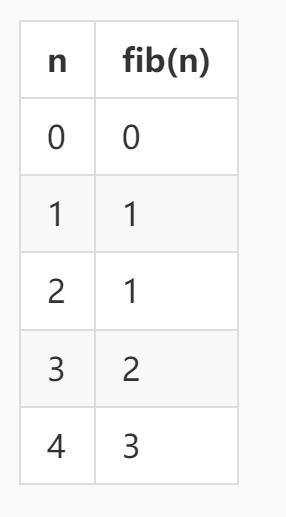
推导公式为:fib (n) = fib (n-1) + fib (n-2)。
创建存储过程 sp_fibonacci (in m int),向表 fibonacci 插入斐波拉契数列的前 m 项,及其对应的斐波拉契数。fibonacci 表初始值为一张空表。请保证你的存储过程可以多次运行而不出错。
use fib; | |
-- 创建存储过程 `sp_fibonacci (in m int)`,向表 fibonacci 插入斐波拉契数列的前 m 项,及其对应的斐波拉契数。fibonacci 表初始值为一张空表。请保证你的存储过程可以多次运行而不出错。 | |
drop procedure if exists sp_fibonacci; | |
delimiter $$ | |
create procedure sp_fibonacci(in m int) | |
begin | |
set m = m - 1; | |
with recursive cte (id, cur, pre) as ( | |
select | |
0, 0, 0 | |
union all | |
select | |
id + 1, | |
if (id < 2, 1, cur + pre), | |
cur | |
from cte | |
where id < m | |
) | |
select | |
id n, | |
cur fibn | |
from cte; | |
end $$ | |
delimiter ; |
上面的思想是将当前值和上一个值在递归过程中进行传递。
在 With Recursive as 的后面不加分号,这是为什么?因为它不属于一个完整的语句吧,应该只是用来创建临时表的
With Recursive as:
https://blog.csdn.net/WHYbeHERE/article/details/125440856
指明递归的字段和 select 后面的字段应该是一一对应的
# 使用游标的存储过程
# 游标 (CURSOR)
# 游标的特点
SQL 操作都是面向集合的,即操作的对象以及运算的结果均为集合,但有时候,我们需要一行一行地处理数据,这就需要用到游标 (CURSOR),它相当于一个存储于内存的带有指针的表,每次可以存取指针指向的一行数据,并将指针向前推进一行。游标的数据通常是一条查询语句的结果。对游标的操作一般要用循环语句,遍历游标的每一行数据,并将该行数据读至变量,再根据变量的值进行所需要的其它操作。
游标有以下持点:
- 不可滚动。即只能从前往后遍历游标数据 (即从第 1 行到最后一行),不能反向遍历,不能跳跃遍历,不能直接访问中间的某一行。
- 只读。游标里的数据只能读取,不能修改。
# 游标的定义与使用
创建并使用 MySQL 游标,至少会用到 DECLARE, OPEN, FETCH, 和 CLOSE 语句。
# DECLARE 语句
用 DECLARE 语句定义游标、变量以及特情处理程序。
在一个 BEGIN...END 语句块内,DECLARE 定义的顺序要求如下:
- 变量
- 游标
- 特情处理
即变量定义在游标之前,特情处理程序定义在游标之后。
变量用来存储从游标读取的数据,根据编程逻辑的需要,可能还要定义其它变量;游标用来存储 SELECT 语句读取的数据集;当某些特定情形出现时,会自动触发对应的特情处理程序。在游标的使用中,你至少需要定义当遍历至游标数据结束 (抛出 NOT FOUND 异常) 时该怎么办 (当然是结束循环)。
定义变量:
DECLARE var_name [, var_name] ... type [DEFAULT value] |
定义游标:
DECLARE cursor_name CURSOR FOR select_statement |
任何合法的 select 语句 (不能带 INTO 短语),都可以定义成游标。此后可用 FETCH 语句读取这个 select 语句查询到的数据集中的一行数据。
注意游标必须定义在变量之后,特情处理程序之前。
一个存储过程可义定义多个游标,但不能同名。
定义特情处理例程:
DECLARE handler_action HANDLER | |
FOR condition_value [, condition_value] ... | |
statement | |
handler_action: { | |
CONTINUE | |
| EXIT | |
} | |
condition_value: { | |
mysql_error_code | |
| SQLSTATE [VALUE] sqlstate_value | |
| condition_name | |
| SQLWARNING | |
| NOT FOUND | |
| SQLEXCEPTION | |
} |
游标应用中至少需要定义一个 NOT FOUND 的 HANDLER (处理例程):
DECLARE CONTINUE HANDLER FOR NOT FOUND SET finished = 1; |
其含义是当抛出 NOT FOUND 异常时,置变量 finished 的值为 1, 程序继续运行。当然,在此之前,应当先定义变量 finished,并初始化为 0 (也可在循环语句之前初始化为 0),finished 作为循环的控制变量,仅当 finished 变成 1 时,循环结束。
如果特情处理例程由多条语句组成,可以用 BEGIN...END 组成复合语句。
当一个存储过程中存在多个游标时,对任何一个游标的读取 (FETCH) 都可能会触发特情处理。比如一个游标的数据被遍历完毕,再试图 FETCH 下一行时,会触发 NOT FOUND HANDLER, 并进而改变某个变量的值,但另一个游标中可能还有未处理完的数据。编程者应当自己想办法区分是哪个游标的数据处理完毕。
# OPEN 语句
OPEN cursor_name |
该语句打开之前定义的游标,并初始化指向数据行的指针 (接下来的第一条 FETCH 语句将试图读取游标的第 1 行数据)。
# FETCH 语句
FETCH [[NEXT] FROM] cursor_name INTO var_name [, var_name] ... |
FETCH 语句读取游标的一行数据到变量列表,并推进游标的指针。关键词 NEXT, FROM 都可省略 (或仅省略 NEXT)。注意 INTO 后的变量列表应当与游标定义中的 SELECT 列表一一对应 (变量个数与 SELECT 列表个数完全相同,数据类型完全一致,每个变量的取值按 SELECT 列表顺序一一对应)。
FETCH 一个未打开的游标会出错。
# CLOSE 语句
CLOSE cursor_name |
Close 语句关闭先前打开的游标,试图关闭一个未曾打开 (OPEN) 的游标会出错。
没有 CLOSE 的游标,在其定义的 BEGIN...END 语句块结束时,将自动 CLOSE。
# 游标应用举例
设有表 epl (英超足球比赛记录) 结构如下:
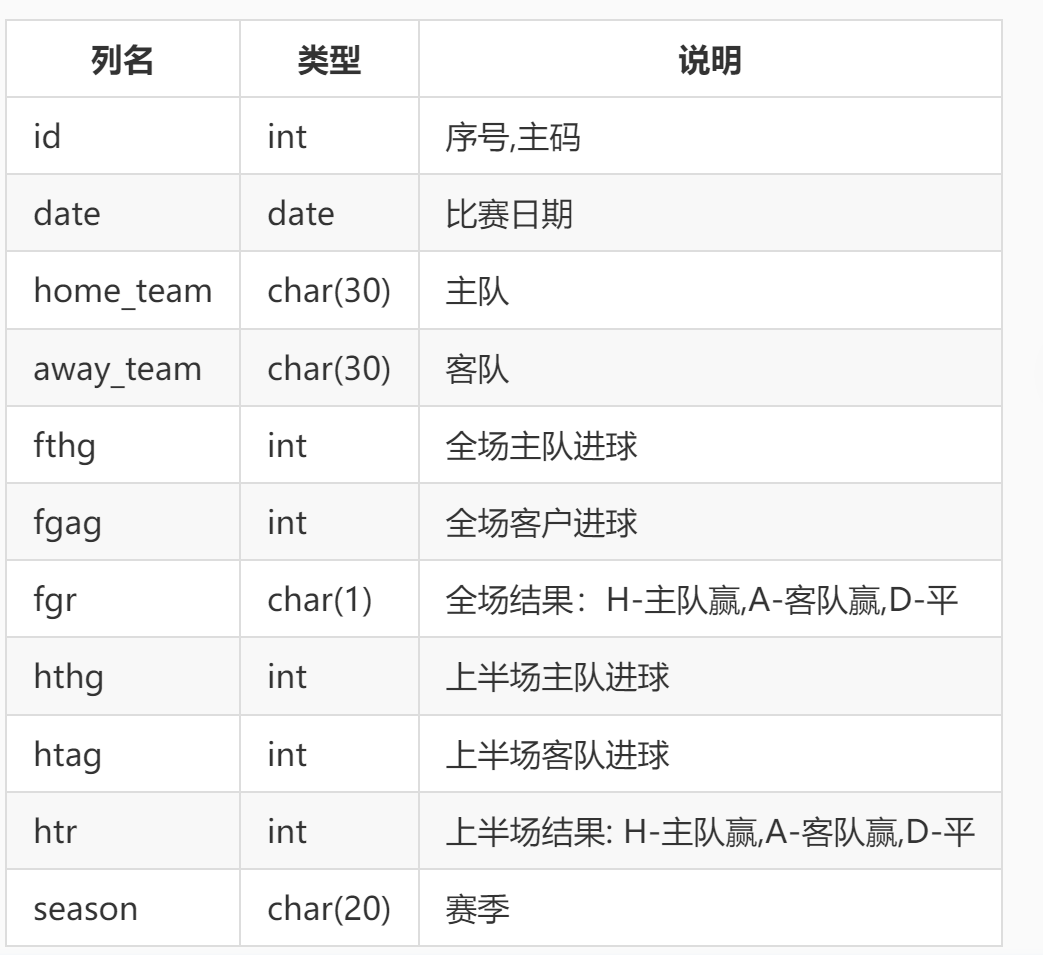
使用游标编写存储过程 sp_cursor_demo 计算 Liverpool 足球队在主场获胜的比赛中,上半场的平均进球数,结果通过参数传递。示例程序如下:
DELIMITER $$ | |
CREATE PROCEDURE sp_cursor_demo(INOUT average_goals FLOAT) | |
BEGIN | |
DECLARE done INT DEFAULT FALSE; | |
DECLARE matches int DEFAULT(0); | |
DECLARE goals int DEFAULT(0); | |
DECLARE half_time_goals INT; | |
DECLARE team_cursor CURSOR FOR SELECT HTHG FROM epl WHERE (home_team = 'Liverpool') and (ftr = 'H'); | |
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; | |
OPEN team_cursor; | |
FETCH team_cursor INTO half_time_goals; | |
WHILE NOT DONE DO | |
SET goals = goals + half_time_goals; | |
SET matches = matches + 1; | |
FETCH team_cursor INTO half_time_goals; | |
END while; | |
SET average_goals = goals / matches; | |
CLOSE team_cursor; | |
END $$ | |
DELIMITER; |
存储过程定义后,可通过以下语句定义参数,调用过程,再从返回参数中获取结果:
SET @average_goals = 0.0; | |
CALL sp_cursor_demo(@average_goals); | |
SELECT @average_goals; |
上述带前缀 @的变量属于 MySQL 的用户自定义变量,只在该用户的会话期内有效,对别的用户 (客户端) 不可见。@前缀变量不用申明变量类型,初始化时,由其值决定其类型。
上述存储过程仅用来演示游标的用法,事实上,下面的这条查询语句,即可获得相同的结果,且效率更高:
select avg(hthg) from epl where home_team = 'Liverpool' and ftr = 'H'; |
一般来説,仅当你需要遍历一个数据集,且一次只能处理其中的一行数据时 (比如对每一行,要作不同的业务处理),你才需要使用游标。当游标的数据集较大时,会造成较大的网络时延。使用游标时,应尽可能缩小数据规模 (去掉不必要的行和列)。
# 编程要求
医院的某科室有科室主任 1 名 (亦为医生),医生若干 (至少 2 名,不含主任),护士若干 (至少 4 人),现在需要编写一存储过程,自动安排某个连续期间的大夜班 (即每天 00:00-8:00 时间段) 的值班表,排班规则为:
- 每个夜班安排 1 名医生,2 名护士;
- 值班顺序依工号顺序循环轮流安排 (即排至最后 1 名后再从第 1 名接着排);
- 科室主任参与轮值夜班,但不安排周末 (星期六和星期天) 的夜班,当周末轮至科主任时,主任的夜班调至周一,由排在主任后面的医生依次递补值周末的夜班。
存储过程的名字为 sp_night_shift_arrange, 它带两个输入参数:start_date, end_date,分别指排班的起始时间和结束时间。排班结果直接写入表 night_shift_schedule,其结构如下:
表 night_shift_schedule (夜班值班安排表)
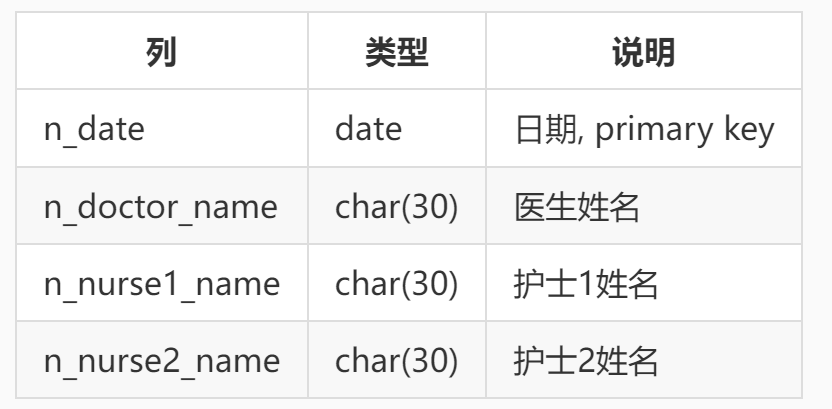
假定该科室没有同名的医生和同名的护士。
科室参与值班的医护人员存储在表 employee 中,其结构为:
表 employee (医护人员表)
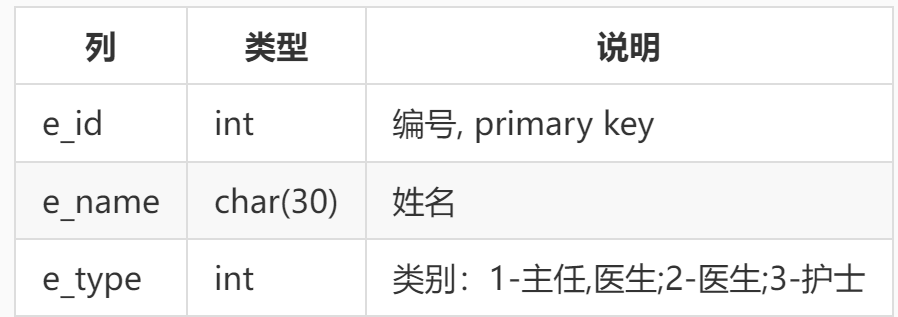
不用考虑其它信息 (比如科室之类的),在生产环境中,只需在 where 短语中施加条件限制即可明确选出所需科室的医护人员。这里,且把表中全部人员视为该科室人员。
-- 编写一存储过程,自动安排某个连续期间的大夜班的值班表: | |
delimiter $$ | |
create procedure sp_night_shift_arrange(in start_date date, in end_date date) | |
begin | |
declare done, tp, wk int default false; | |
declare doc, nur1, nur2, head char(30); | |
declare cur1 cursor for select e_name from employee where e_type = 3; | |
declare cur2 cursor for select e_type, e_name from employee where e_type < 3; | |
declare continue handler for not found set done = true; | |
open cur1; | |
open cur2; | |
while start_date <= end_date do | |
-- 选择第一位护士 | |
fetch cur1 into nur1; | |
if done then | |
close cur1; | |
open cur1; | |
set done = false; | |
fetch cur1 into nur1; | |
end if; | |
-- 选择第二位护士 | |
fetch cur1 into nur2; | |
if done then | |
close cur1; | |
open cur1; | |
set done = false; | |
fetch cur1 into nur2; | |
end if; | |
-- 选择医生 | |
set wk = weekday(start_date); | |
if wk = 0 and head is not null then | |
-- wk=0 表示星期一,head 保存因周末而没领班的主任的名称 | |
set doc = head; | |
set head = null; | |
else | |
fetch cur2 into tp, doc; | |
if done then | |
close cur2; | |
open cur2; | |
set done = false; | |
fetch cur2 into tp, doc; | |
end if; | |
if wk > 4 and tp = 1 then | |
-- 如果是周末,且取到的是主任 | |
-- 保存主任名称,再重新取 | |
-- 根据要求,科室中只有一名主任,再重新取的肯定是医生了 | |
set head = doc; | |
fetch cur2 into tp, doc; | |
if done then | |
close cur2; | |
open cur2; | |
set done = false; | |
fetch cur2 into tp, doc; | |
end if; | |
end if; | |
end if; | |
insert into night_shift_schedule values (start_date, doc, nur1, nur2); | |
set start_date = date_add(start_date, interval 1 day); | |
end while; | |
end$$ | |
delimiter ; | |
/* end of your code */ |
思路:先将护士和医生(包括主任)分别提取到两个游标中
每次 fetch 一行数据都要检查 done 是否为 true
当这一次 fetch 的时候已经是最后一条数据,下一次 fetch 的时候就会引起异常,没有取到数据,这时只要关闭游标后再重新打开,执行 fetch 时就可以从头开始取数据了。
cur1 保存护士名称,每次直接取即可
cur2 保存 e_type (主任还是普通医生) 和 e_name(名称)
如果两天的周末,取到的两位都是主任,head 会不会被覆盖
weekday 函数:https://blog.csdn.net/moakun/article/details/82528816
date_add:
https://www.w3school.com.cn/sql/func_date_add.asp
# 使用事务的存储过程
# 相关知识
为了完成本关任务,你需要掌握:
- 事务的定义和应用;
- 存储过程的定义和应用。
# 事务的定义和应用
开启事务:
- START TRANSACTION 或 BEGIN (前者兼容性更好)
事务提交:
- COMMIT
事务回滚:
- ROLLBACK
开启或关闭当前会话的自动事务模式
- SET autocommit = ON|OFF
也可用 1|0,true|false 代替 ON|OFF。
缺省情况下,autocommit 模式被设置为 ON,即你在命令行提交的每一条语句会自动封装成一个事务,即使下一条语句发生错误,前一条语句产生的结果也不可撤销。
注意,事务内部不允许嵌套另一个事务,尽量不要在事务内部使用 DDL 语句,因为即使事务回滚,DDL 语句对数据库的修改也不会撤销。
# 编程要求
在金融应用场景数据库中,编程实现一个转账操作的存储过程 sp_transfer,实现从一个帐户向另一个帐户转账。该过程有 5 个输入参数:
- applicant_id 付款人编号
- source_card_id 付款卡号
- receiver_card_id 收款人编号
- dest_card_id 收款卡号
- amount 转账金额
还有 1 个整型输出参数: - return_code 1:正常转账;0: 转账不成功
转账操作涉及对表 bank_card 的操作 (在生产环境中,至少还要记录转账操作本身相关的信息至转账表,在实验环境中没有设计这样的表,从略;另外,生产环境中,当银行卡被冻结,或被卡主挂失后,都不能进行转账,在实验环境中,没有设计相应的字段 ,故也从略)。
注意事项:
- 仅当转款人是转出卡的持有人时,才可转出;
- 仅当收款人是收款卡的持有人时,才可转入;
- 储蓄卡之间可以相互转账;
- 允许储蓄卡向信用卡转账,称为信用卡还款 (允许替它人还款),还款可以超过信用卡余额,此时,信用卡余额为负数;
- 信用卡不能向储蓄卡转账;
- 转账金额不能超过储蓄卡余额;
当从储蓄卡中转出的金额大于余额时也转账失败
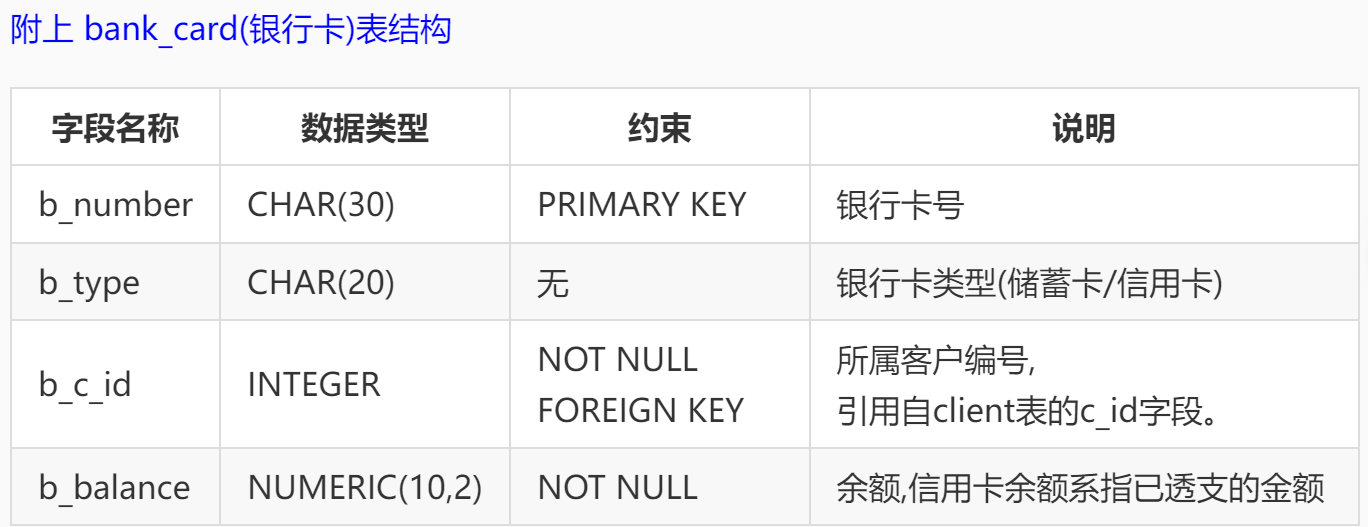
use finance1; | |
-- 在金融应用场景数据库中,编程实现一个转账操作的存储过程 sp_transfer_balance,实现从一个帐户向另一个帐户转账。 | |
-- 请补充代码完成该过程: | |
delimiter $$ | |
create procedure sp_transfer( | |
IN applicant_id int, | |
IN source_card_id char(30), | |
IN receiver_id int, | |
IN dest_card_id char(30), | |
IN amount numeric(10,2), | |
OUT return_code int) | |
pro: | |
BEGIN | |
declare s_id, r_id int; | |
declare s_type, r_type char(20); | |
declare s_b, rcv_amount numeric(10, 2) default amount; | |
-- 根据转款人的银行卡号获得其所属的客户编号,余额和银行卡类型 | |
select | |
b_c_id, b_balance, b_type | |
into | |
s_id, s_b, s_type | |
from bank_card | |
where b_number = source_card_id; | |
-- 根据收款人的银行卡号获得其所属的客户编号和银行卡类型 | |
select | |
b_c_id, b_type | |
into | |
r_id, r_type | |
from bank_card | |
where b_number = dest_card_id; | |
if s_id != applicant_id or r_id != receiver_id or (s_type = "信用卡" and r_type = "储蓄卡") or (s_type = "储蓄卡" and s_b < amount) then | |
set return_code = 0; | |
leave pro; | |
end if; | |
if s_type = "信用卡" then | |
set amount = -amount; | |
end if; | |
if r_type = "信用卡" then | |
set rcv_amount = -rcv_amount; | |
end if; | |
update bank_card set b_balance = b_balance - amount where b_number = source_card_id; | |
update bank_card set b_balance = b_balance + rcv_amount where b_number = dest_card_id; | |
set return_code = 1; | |
END$$ | |
delimiter ; |
在 begin...end 前写上一个标号 pro ,在 begin...end 中使用 leave pro; 来终止语句的执行
注:信用卡转出去是加,转进来是减