# 金融应用场景介绍,查询客户主要信息
# 相关知识
为了完成本关任务,你需要掌握:
SELECT 语句的用法;
单表查询;
对查询结果排序。
如果需要自建调试环境,你还需要掌握:
从 gitee.com 上获取初始化数据的代码文件;
用获取的代码文件初始化数据库;
在 MySQL 的命令行调试语句。
# 背景
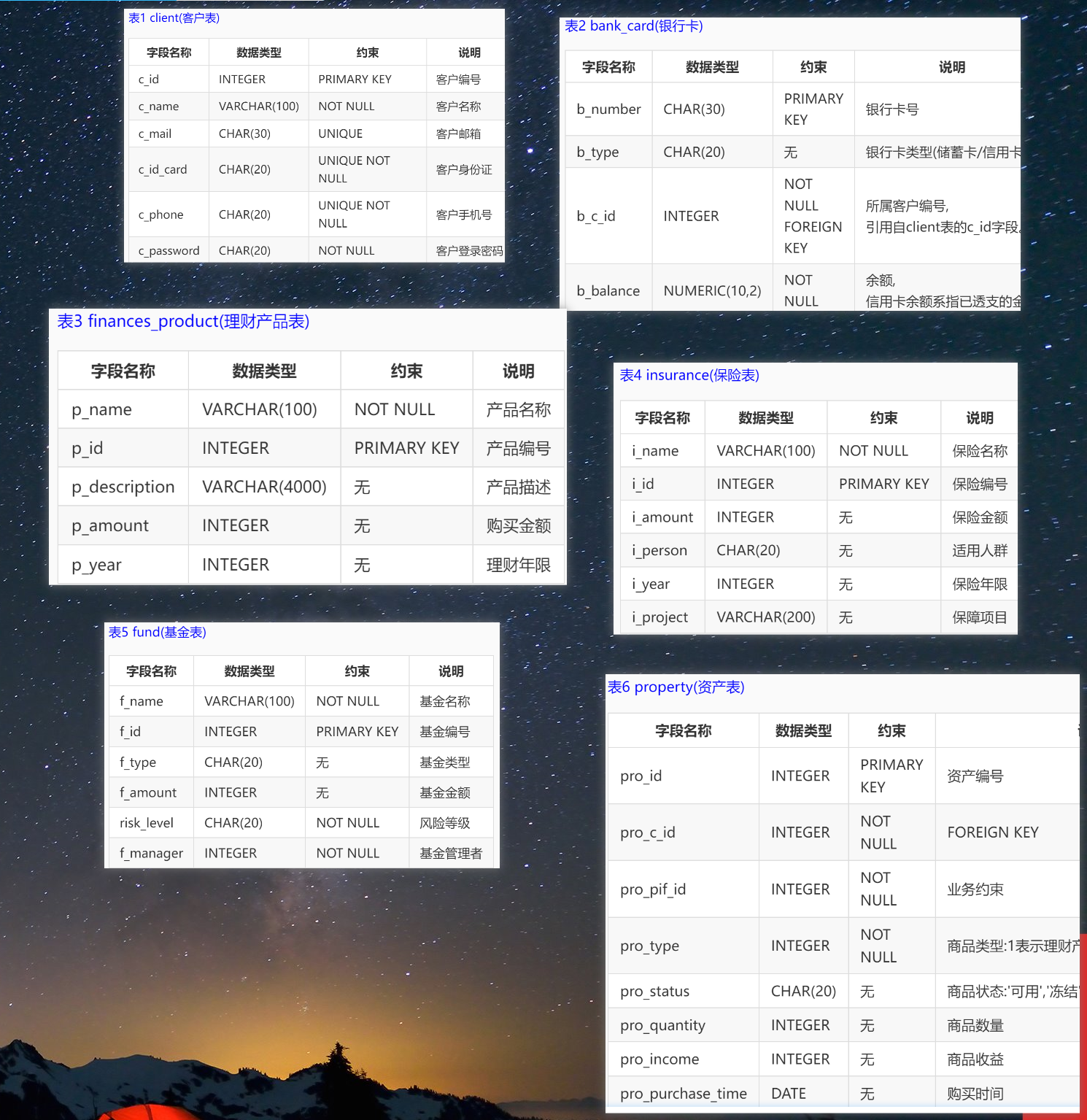
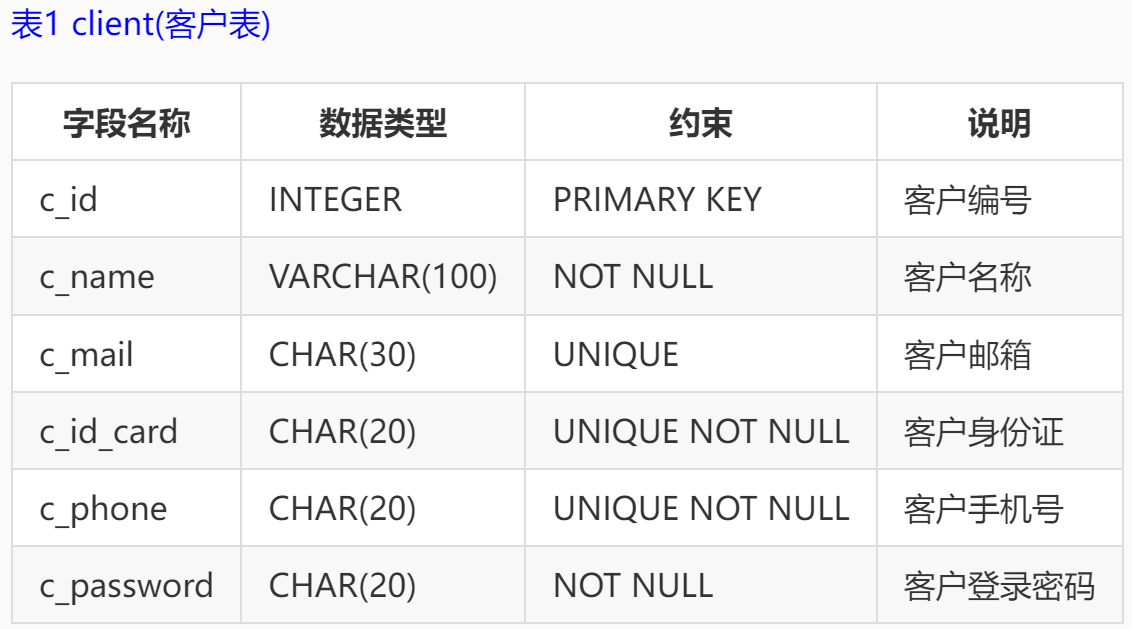
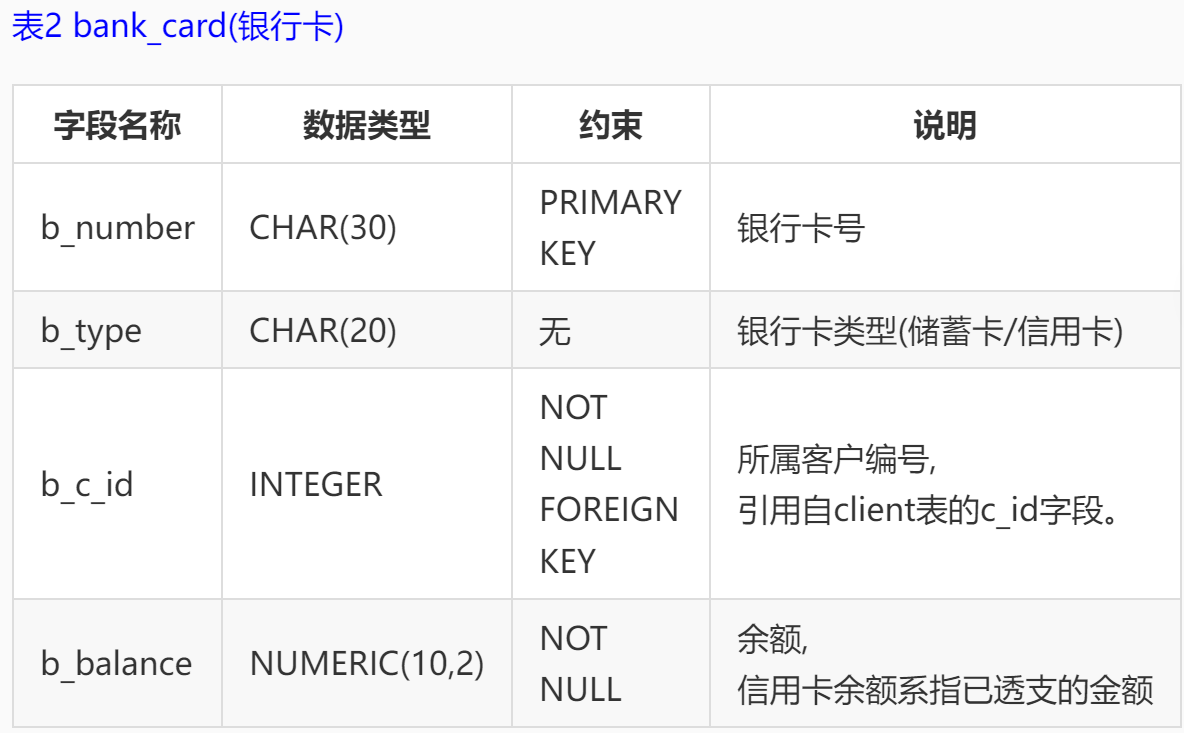
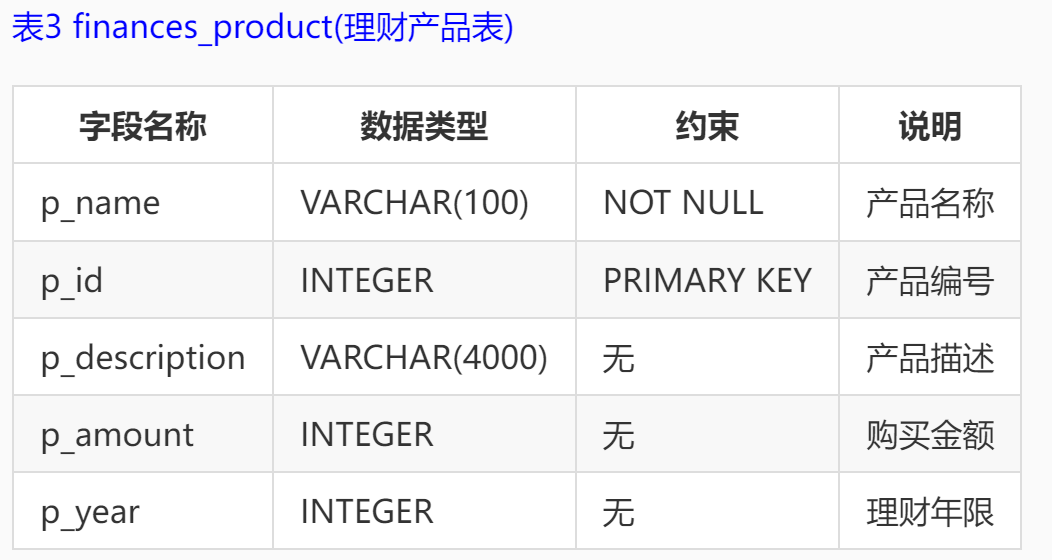
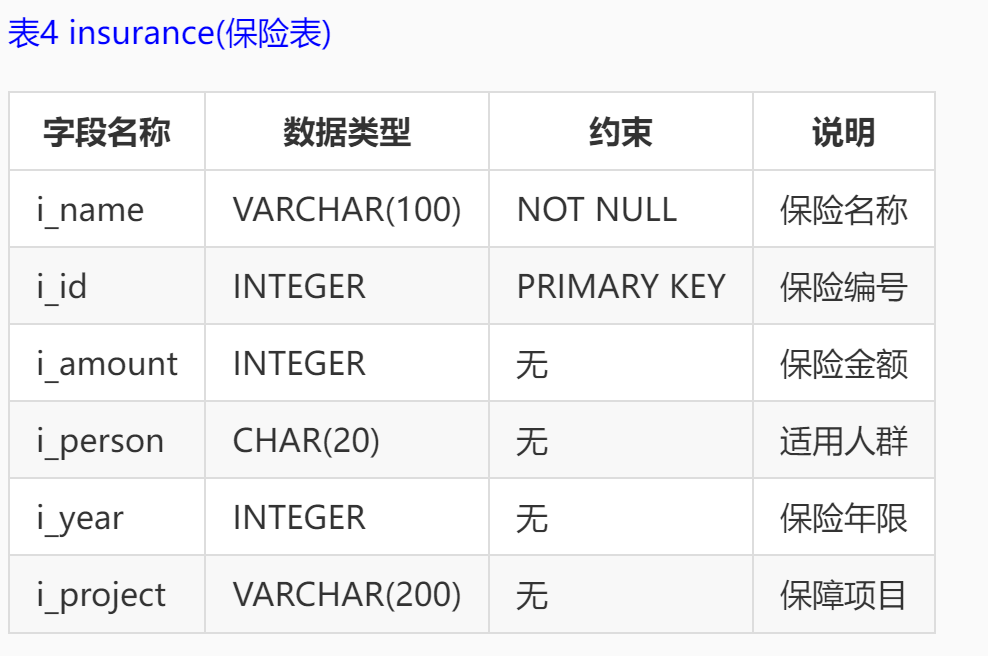
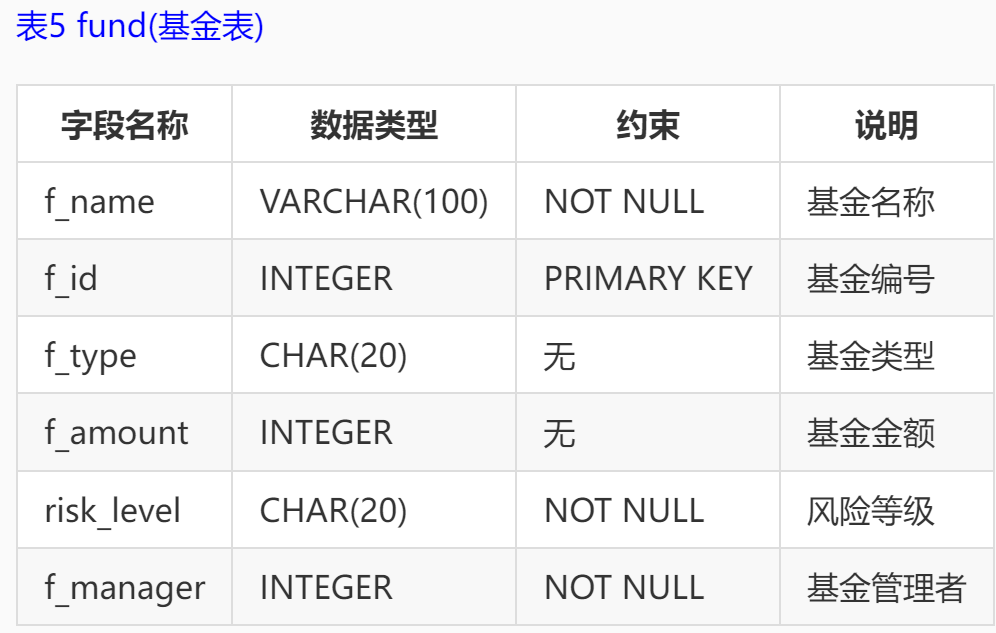
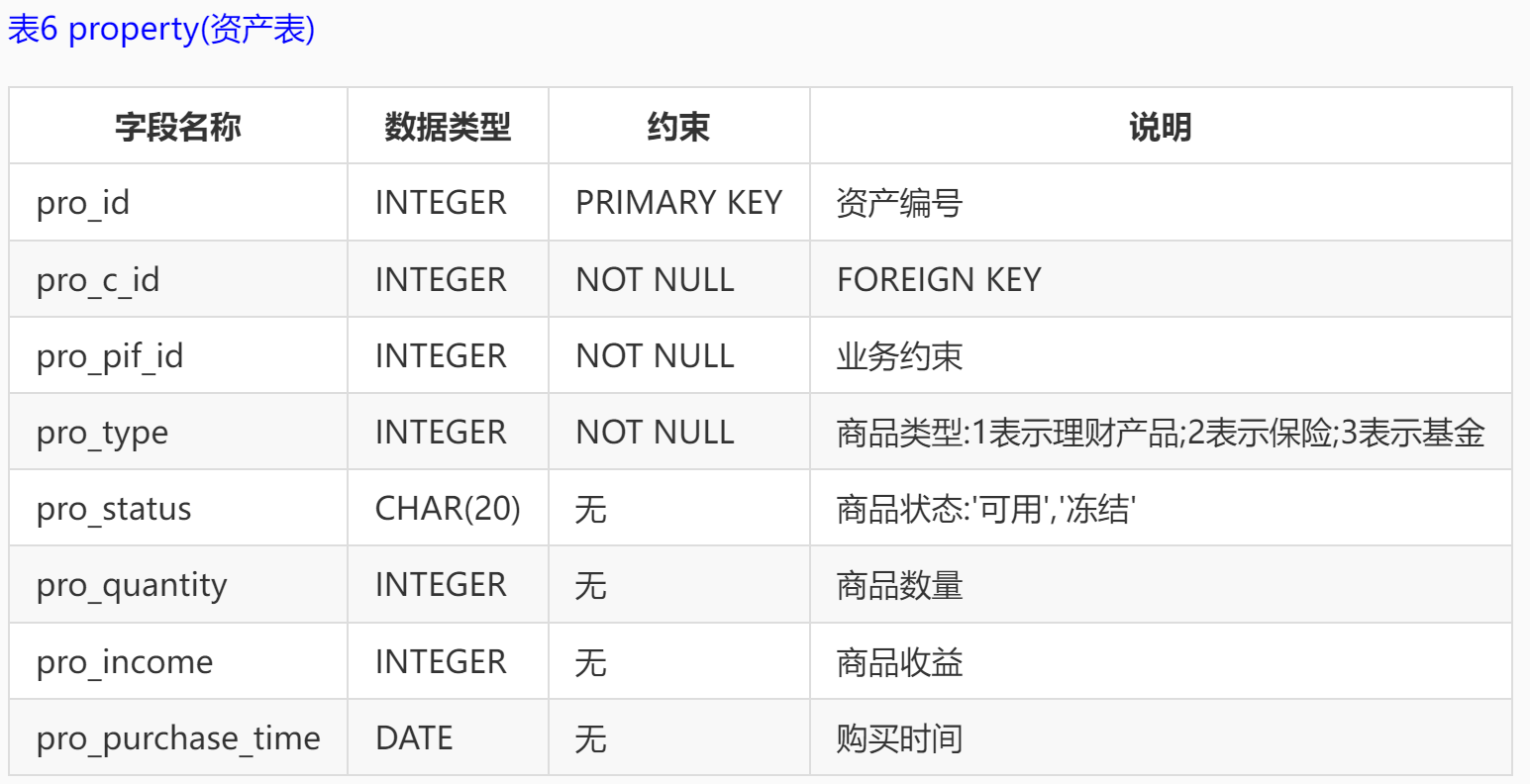
本实训采用的是某银行的一个金融场景应用的模拟数据库,数据库中表,表结构以及所有字段的说明如下:
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询所有客户的名称、手机号和邮箱信息。查询结果按照客户编号排序。
-- 1) 查询所有客户的名称、手机号和邮箱信息。查询结果按照客户编号排序。 | |
-- 请用一条 SQL 语句实现该查询: | |
SELECT c_name, c_phone, c_mail FROM client ORDER BY c_id | |
/* end of your code */ |
# 邮箱为 null 的客户
# 相关知识
null 值的判断。
# 编程任务
请用一条 SQL 语句完成以下查询任务:
查询客户表 (client) 中没有填写邮箱信息 (邮箱字段值为 null) 的客户的编号、名称、身份证号、手机号。
-- 2) 查询客户表 (client) 中邮箱信息为 null 的客户的编号、名称、身份证号、手机号。 | |
-- 请用一条 SQL 语句实现该查询: | |
SELECT c_id, c_name, c_id_card, c_phone | |
FROM client | |
where c_mail is NULL | |
/* end of your code */ |
# 既买了保险又买了基金的客户
# 相关知识
为了完成本关任务,你需要掌握:
SELECT 语句的用法;
嵌套查询;
多条件查询。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询既买了保险又买了基金的客户的名称、邮箱和电话,结果依客户编号排序。
-- 3) 查询既买了保险又买了基金的客户的名称、邮箱和电话。结果依 c_id 排序 | |
-- 请用一条 SQL 语句实现该查询: | |
select c_name, c_mail, c_phone | |
from client | |
where exists | |
(select * from property where pro_c_id = c_id and pro_type = 2) | |
and exists | |
(select * from property where pro_c_id = c_id and pro_type = 3) | |
order by c_id; | |
/* end of your code */ |
最终需要的数据:客户的名称、邮箱和电话 都是在客户表 client 中取得的,因此从左到右的第一个 from(主 / 父查询中的 from 后面的表只有 client 一个表),对其他表的查询都是判断从父表 client 查询到的这条数据是否满足约束条件。
# 办理了储蓄卡的客户信息
# 相关知识
为了完成本关任务,你需要掌握:
SELECT 语句的用法:
多表连接的用法;
条件查询。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询办理了储蓄卡的客户名称、手机号和银行卡号。注意一个客户在本行可能不止一张储蓄卡,应全列出。查询结果结果依客户编号排序。
-- 4) 查询办理了储蓄卡的客户名称、手机号、银行卡号。 查询结果结果依客户编号排序。 | |
-- 请用一条 SQL 语句实现该查询: | |
select c_name, c_phone, b_number | |
from client, | |
bank_card | |
where b_type = '储蓄卡' | |
and b_c_id = c_id | |
order by c_id; | |
/* end of your code */ |
最终需要的数据:客户名称、手机号和银行卡号来自两张表:客户表 client 和银行卡表 bank_card,因此第一个 from 后面得接这两个表的名称。
# 每份金额在 30000~50000 之间的理财产品
# 相关知识
带条件的单表查询;
between 的用法;
对结果升序和降序排序。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询理财产品中每份金额在 30000~50000 之间的理财产品的编号,每份金额,理财年限,并按金额升序排序,金额相同的按照理财年限降序排序。
-- 5) 查询理财产品中每份金额在 30000~50000 之间的理财产品的编号,每份金额,理财年限,并按照金额升序排序,金额相同的按照理财年限降序排序。 | |
-- 请用一条 SQL 语句实现该查询: | |
select p_id,p_amount,p_year from finances_product | |
where p_amount>=30000 and p_amount<=50000 | |
order by p_amount,p_year desc; | |
/* end of your code */ |
# 商品收益的众数
# 相关知识
为了完成本关任务,你需要掌握:
子查询;
分组统计与 COUNT () 函数;
ALL 关键词或者 MAX () 函数;
给表达式列命名。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
众数是一组数据中出现次数最多的数值,有时众数在一组数中会有好几个。查询资产表中所有资产记录里商品收益的众数和它出现的次数,出现的次数命名为 presence。
-- 6) 查询资产表中所有资产记录里商品收益的众数和它出现的次数。 | |
-- 请用一条 SQL 语句实现该查询: | |
select pro_income, | |
count(*) as presence | |
from property | |
group by pro_income | |
having count(*) >= all (select count(*) | |
from property | |
group by pro_income); | |
/* end of your code */ |
where 的讲解:http://c.biancheng.net/view/7416.html#:~:text = 在 MySQL 中,可以使用 HAVING 关键字对分组后的数据进行过滤。 HAVING 关键字和 WHERE,WHERE 关键字中所有的操作符和语法。 一般情况下, WHERE 用于过滤数据行,而 HAVING 用于过滤分组 。
# 未购买任何理财产品的武汉居民
# 相关知识
为了完成本关任务,你需要掌握:
- LIKE 的用法;
- 子查询;
- not exists 谓词。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
已知身份证前 6 位表示居民地区,其中 4201 开头表示湖北省武汉市。查询身份证隶属武汉市没有买过任何理财产品的客户的名称、电话号、邮箱。依客户编号排序
-- 7) 查询身份证隶属武汉市没有买过任何理财产品的客户的名称、电话号、邮箱。 | |
-- 请用一条 SQL 语句实现该查询: | |
-- 第一种方案: | |
select | |
c_name, | |
c_phone, | |
c_mail | |
from client | |
where c_id_card like "4201%" | |
and not exists ( | |
select | |
pro_type | |
from property | |
where pro_c_id = c_id | |
and pro_type = 1 | |
) | |
order by c_id; | |
-- 第二种方案 | |
select | |
c_name, | |
c_phone, | |
c_mail | |
from client | |
where c_id_card like "4201%" | |
and c_id not in ( | |
select | |
pro_c_id | |
from property | |
where pro_type = 1 | |
) | |
order by c_id; | |
/* end of your code */ |
在第一种方案中,子查询用到了父查询中的字段,构成了类似嵌套循环的的形式;第二种方案中,则是将子查询返回作为一个集合,再判断父查询中一条数据的字段值是否在集合内。
两种方案最终需要获取的数据都来自一张表,故不涉及表的连接,父查询的 from 后只有一个表名。
# 持有两张信用卡的用户
# 相关知识
为了完成本关任务,你需要掌握:
子查询;
分组统计。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询持有两张 (含)以上信用卡的用户的名称、身份证号、手机号。查询结果依客户编号排序
-- 8) 查询持有两张 (含)以上信用卡的用户的名称、身份证号、手机号。 | |
-- 请用一条 SQL 语句实现该查询: | |
-- 第一种方案 | |
select | |
c_name, | |
c_id_card, | |
c_phone | |
from client | |
where (c_id, "信用卡") in ( | |
select | |
b_c_id, | |
b_type | |
from bank_card | |
group by b_c_id, b_type | |
having count(*) > 1 | |
); | |
-- 第二种方案:where,group by,having 将约束条件给均衡分布了 | |
select c_name,c_id_card,c_phone | |
from client | |
where c_id in ( | |
select b_c_id | |
from bank_card | |
where b_type = "信用卡" | |
group by b_c_id | |
having count(*) > 1 | |
); | |
/* end of your code */ |
# 购买了货币型基金的客户信息
# 相关知识
为了完成本关任务,你需要掌握:
SELECT 语句的用法:
相关子查询,多层嵌套,NOT EXISTS 的的用法。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询购买了货币型 (f_type=' 货币型 ') 基金的用户的名称、电话号、邮箱。依客户编号排序
-- 9) 查询购买了货币型 (f_type=' 货币型 ') 基金的用户的名称、电话号、邮箱。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
c_name, | |
c_phone, | |
c_mail | |
from client | |
where c_id in ( | |
select | |
pro_c_id | |
from property | |
where pro_type = 3 | |
and pro_pif_id in ( | |
select | |
f_id | |
from fund | |
where f_type = "货币型" | |
) | |
) | |
order by c_id; | |
/* end of your code */ |
# 投资总收益前三名的客户
# 相关知识
为了完成本关任务,你需要掌握:
多表连接;
分组统计;
衍生表 (派生表);
子查询;
top n 查询。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
查询当前总的可用资产收益 (被冻结的资产除外) 前三名的客户的名称、身份证号及其总收益,按收益降序输出,总收益命名为 total_income。不考虑并列排名情形。
一个客户可以有基金、保险和理财产品等多种资产,那么在资产表中就对应有多条记录,所以要求总收益,就得根据客户编号进行分组,再对分组中的所有资产记录收益进行求和。
-- 10) 查询当前总的可用资产收益 (被冻结的资产除外) 前三名的客户的名称、身份证号及其总收益,按收益降序输出,总收益命名为 total_income。不考虑并列排名情形。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
c_name, | |
c_id_card, | |
sum(pro_income) as total_income | |
from client | |
inner join property | |
on pro_c_id = c_id | |
and pro_status = "可用" | |
group by c_id | |
order by sum(pro_income) desc | |
limit 3; | |
/* end of your code */ |
# 黄姓客户持卡数量
# 相关知识
为了完成本关任务,你需要掌握:
外连接;
分组统计。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
给出黄姓用户的编号、名称、办理的银行卡的数量 (没有办卡的卡数量计为 0). 按办理银行卡数量降序输出,持卡数量相同的,依客户编号排序。
-- 11) 给出黄姓用户的编号、名称、办理的银行卡的数量 (没有办卡的卡数量计为 0), 持卡数量命名为 number_of_cards, | |
-- 按办理银行卡数量降序输出,持卡数量相同的,依客户编号排序。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
c_id, | |
c_name, | |
count(b_c_id) as number_of_cards | |
-- 上面的 b_c_id 可以换成 bank_card 表的任一字段,因为在 left join 的 | |
-- 时候,如果右表对应的数据不存在,此处得到的都是 null,但是注意不能 | |
-- 换成 *,因为 count (*) 对于 null 也会计数成为 1 的 | |
from client | |
left join bank_card | |
on c_id = b_c_id | |
where c_name like "黄%" | |
group by c_id | |
order by number_of_cards desc, c_id; | |
-- 在连接之后再进行 where 条件 | |
/* end of your code */ |
# 客户理财、保险与基金投资总额
# 相关知识
为完成本任务,你需要掌握以下知识:
分表合并;
分组统计;
对结果排序。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
综合客户表 (client)、资产表 (property)、理财产品表 (finances_product)、保险表 (insurance) 和基金表 (fund),列出客户的名称、身份证号以及投资总金额(即投资本金,每笔投资金额 = 商品数量 * 该产品每份金额),注意投资金额按类型需查询不同的表,
投资总金额是客户购买的各类 (理财,保险,基金) 资产投资金额的总和,总金额命名为 total_amount。查询结果按总金额降序排序。
-- 12) 综合客户表 (client)、资产表 (property)、理财产品表 (finances_product)、保险表 (insurance) 和 | |
-- 基金表 (fund),列出客户的名称、身份证号以及投资总金额(即投资本金, | |
-- 每笔投资金额 = 商品数量 * 该产品每份金额),注意投资金额按类型需要查询不同的表, | |
-- 投资总金额是客户购买的各类资产 (理财,保险,基金) 投资金额的总和,总金额命名为 total_amount。 | |
-- 查询结果按总金额降序排序。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
c_name, | |
c_id_card, | |
ifnull(sum(pro_amount), 0) as total_amount | |
from client | |
left join ( | |
select | |
pro_c_id, | |
pro_quantity * p_amount as pro_amount | |
from property, finances_product | |
where pro_pif_id = p_id | |
and pro_type = 1 | |
union all | |
select | |
pro_c_id, | |
pro_quantity * i_amount as pro_amount | |
from property, insurance | |
where pro_pif_id = i_id | |
and pro_type = 2 | |
union all | |
select | |
pro_c_id, | |
pro_quantity * f_amount as pro_amount | |
from property, fund | |
where pro_pif_id = f_id | |
and pro_type = 3 | |
) pro | |
on pro.pro_c_id = c_id | |
group by c_id | |
order by total_amount desc; | |
-- 修改了一下的 | |
-- 12) 综合客户表 (client)、资产表 (property)、理财产品表 (finances_product)、保险表 (insurance) 和 | |
-- 基金表 (fund),列出客户的名称、身份证号以及投资总金额(即投资本金, | |
-- 每笔投资金额 = 商品数量 * 该产品每份金额),注意投资金额按类型需要查询不同的表, | |
-- 投资总金额是客户购买的各类资产 (理财,保险,基金) 投资金额的总和,总金额命名为 total_amount。 | |
-- 查询结果按总金额降序排序。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
c_name, | |
c_id_card, | |
ifnull(sum(pro_amount), 0) as total_amount | |
from client | |
left join ( | |
select | |
pro_c_id, | |
pro_quantity * p_amount as pro_amount | |
from | |
(select * from property where pro_type = 1) as temp | |
-- 上面要加表的别名,不然会报错,下面 on 那里 表名。列名 | |
-- 中的表名可加可不加 | |
inner join | |
finances_product | |
on pro_pif_id = finances_product.p_id | |
union all | |
select | |
pro_c_id, | |
pro_quantity * i_amount as pro_amount | |
from property, insurance | |
where pro_pif_id = i_id | |
and pro_type = 2 | |
union all | |
select | |
pro_c_id, | |
pro_quantity * f_amount as pro_amount | |
from property, fund | |
where pro_pif_id = f_id | |
and pro_type = 3 | |
) pro | |
on pro.pro_c_id = c_id | |
group by c_id | |
order by total_amount desc; | |
/* end of your code */ |
有些客户可能没有资产,要使用 left join。
上面涉及到资产表分别与理财产品表、保险表和基金表的连接,做相同的操作之后再 union all 合并起来,
整体思想是,资产表先分别与理财产品表、保险表和基金表做连接,再与客户表做连接。
# 客户总资产
# 相关知识
为了完成本关任务,你需要掌握:
多表连接查询,嵌套查询,衍生表的用法。
# 编程要求
请用一条 SQL 语句完成以下查询任务:
综合客户表 (client)、资产表 (property)、理财产品表 (finances_product)、保险表 (insurance)、基金表 (fund),列出所有客户的编号、名称和总资产,总资产命名为 total_property。总资产为储蓄卡总余额,投资总额,投资总收益的和,再扣除信用卡透支的总金额 (信用卡余额即为透支金额)。客户总资产包括被冻结的资产
-- 13) 综合客户表 (client)、资产表 (property)、理财产品表 (finances_product)、 | |
-- 保险表 (insurance)、基金表 (fund) 和投资资产表 (property), | |
-- 列出所有客户的编号、名称和总资产,总资产命名为 total_property。 | |
-- 总资产为储蓄卡余额,投资总额,投资总收益的和,再扣除信用卡透支的金额 | |
-- (信用卡余额即为透支金额)。客户总资产包括被冻结的资产。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
c_id, | |
c_name, | |
ifnull(sum(amount), 0) as total_property | |
from client | |
left join ( | |
-- 算理财产品的投资 | |
select | |
pro_c_id, | |
pro_quantity * p_amount as amount | |
from property, finances_product | |
where pro_pif_id = p_id | |
and pro_type = 1 | |
union all | |
-- 算保险的投资 | |
select | |
pro_c_id, | |
pro_quantity * i_amount as amount | |
from property, insurance | |
where pro_pif_id = i_id | |
and pro_type = 2 | |
union all | |
-- 算基金的投资 | |
select | |
pro_c_id, | |
pro_quantity * f_amount as amount | |
from property, fund | |
where pro_pif_id = f_id | |
and pro_type = 3 | |
union all | |
-- 算客户的总收益 | |
select | |
pro_c_id, | |
sum(pro_income) as amount | |
from property | |
group by pro_c_id | |
union all | |
-- 算银行卡余额,信用卡要取相反数 | |
select | |
b_c_id, | |
sum(if(b_type = "储蓄卡", b_balance, -b_balance)) as amount | |
from bank_card | |
group by b_c_id | |
) pro | |
on c_id = pro.pro_c_id | |
group by c_id | |
order by c_id; | |
-- 要实现不同属性的求和,得使用 union 将不同的属性列更名并合并到同一列 | |
-- 上面,再使用 sum 和 group by 来进行求和 | |
/* end of your code */ |
# 第 14 关:第 N 高问题
# 相关知识
为了完成本关任务,你需要掌握:
排序;
消重;
取第 N 高;
子查询。
# 编程要求
请用一条 SQL 语句实现本询要求:
查询每份保险金额第 4 高保险产品的编号和保险金额。在数字序列 8000,8000,7000,7000,6000 中,两个 8000 均为第 1 高,两个 7000 均为第 2 高,6000 为第 3 高。
-- 14) 查询每份保险金额第 4 高保险产品的编号和保险金额。 | |
-- 在数字序列 8000,8000,7000,7000,6000 中, | |
-- 两个 8000 均为第 1 高,两个 7000 均为第 2 高,6000 为第 3 高。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
i_id, | |
i_amount | |
from insurance | |
where i_amount = ( | |
select | |
distinct i_amount | |
from insurance | |
order by i_amount desc | |
limit 3, 1 | |
); | |
-- 方案二 | |
select i_id, i_amount | |
from insurance | |
where i_amount = ( | |
select | |
i_amount | |
from insurance | |
group by i_amount | |
order by i_amount desc | |
limit 3, 1 | |
); | |
/* end of your code */ |
# 基金收益两种方式排名
# 相关知识
为了完成本关任务,你需要掌握:
分组统计,对分组统计的结果进行排序;
两种排名次需求及对应策略。
# 排名问题
排名是数据库应用中的一类经典问题,实际又根据具体需求细分为 3 种场景:
- 连续排名,同数不同名次,无并列名次。例如 300、200、200、150、150、100 的排名结果为 1, 2, 3, 4, 5, 6。这种排名类似于编号;
- 同数同名次,总排名不连续。例如 300、200、200、150、150、100 的排名结果为 1, 2, 2, 4, 4, 6;
- 同数同名次,总排名连续。例如 300、200、200、150、150、100 的排名结果为 1, 2, 2, 3, 3, 4。
不同的需求对应着不同的查询策略。本关的任务是实现后两种方式的排名。
# 编程要求
请分别用两条 SQL 语句实现下述两个任务:
查询资产表中客户编号,客户基金投资总收益,基金投资总收益的排名 (从高到低排名)。总收益相同时名次亦相同 (即并列名次)。总收益命名为 total_revenue, 名次命名为 rank。第一条 SQL 语句实现全局名次不连续的排名,第二条 SQL 语句实现全局名次连续的排名。不管哪种方式排名,收益相同时,客户编号小的排在前
-- 15) 查询资产表中客户编号,客户基金投资总收益,基金投资总收益的排名 (从高到低排名)。 | |
-- 总收益相同时名次亦相同 (即并列名次)。总收益命名为 total_revenue, 名次命名为 rank。 | |
-- 第一条 SQL 语句实现全局名次不连续的排名, | |
-- 第二条 SQL 语句实现全局名次连续的排名。 | |
-- (1) 基金总收益排名 (名次不连续) | |
select | |
pro_c_id, | |
sum(pro_income) as total_revenue, | |
-- 下面的 sum (pro_income) 不能换成上面的 total_revenue | |
rank() over(order by sum(pro_income) desc) as "rank" | |
from property | |
where pro_type = 3 | |
group by pro_c_id | |
order by total_revenue desc, pro_c_id; | |
-- (2) 基金总收益排名 (名次连续) | |
select | |
pro_c_id, | |
sum(pro_income) as total_revenue, | |
dense_rank() over(order by sum(pro_income) desc) as "rank" | |
from property | |
where pro_type = 3 | |
group by pro_c_id | |
order by total_revenue desc, pro_c_id; | |
/* end of your code */ |
在资产表中,同一编号的客户可以购买了同一种类型 pro_type 的多份资产。
# 持有完全相同基金组合的客户
# 相关知识
为了完成本关任务,你需要掌握:
多层嵌套查询;
not exists 的用法;
元组消重。
# 编程要求
请用一条 SQL 语句实现查询任务:
查询持有相同基金组合的客户对,如编号为 A 的客户持有的基金,编号为 B 的客户也持有,反过来,编号为 B 的客户持有的基金,编号为 A 的客户也持有,则 (A,B) 即为持有相同基金组合的二元组,请列出这样的客户对。为避免过多的重复,如果 (1,2) 为满足条件的元组,则不必显示 (2,1),即只显示 编号小者在前的那一对,这一组客户编号分别命名为 c_id1,c_id2。
-- 16) 查询持有相同基金组合的客户对,如编号为 A 的客户持有的基金,编号为 B 的客户也持有,反过来,编号为 B 的客户持有的基金,编号为 A 的客户也持有,则 (A,B) 即为持有相同基金组合的二元组,请列出这样的客户对。为避免过多的重复,如果 (1,2) 为满足条件的元组,则不必显示 (2,1),即只显示编号小者在前的那一对,这一组客户编号分别命名为 c_id1,c_id2。 | |
-- 请用一条 SQL 语句实现该查询: | |
with pro(c_id, f_id) as ( | |
select | |
pro_c_id c_id, | |
group_concat(distinct pro_pif_id order by pro_pif_id) f_id | |
-- 上面的 distinct 可去掉,因为 pro_pif_id 为外键,是唯一的 | |
from property | |
where pro_type = 3 | |
group by pro_c_id | |
) | |
select | |
t1.c_id c_id1, | |
t2.c_id c_id2 | |
from pro t1, pro t2 | |
where t1.c_id < t2.c_id | |
and t1.f_id = t2.f_id; | |
-- 改了 | |
with pro as ( | |
select | |
pro_c_id c_id, | |
group_concat(pro_pif_id order by pro_pif_id) f_id | |
from property | |
where pro_type = 3 | |
group by pro_c_id | |
) | |
select | |
t1.c_id c_id1, | |
t2.c_id c_id2 | |
from pro t1, pro t2 | |
where t1.c_id < t2.c_id | |
and t1.f_id = t2.f_id; | |
/* end of your code */ |
思路,先找出每个客户购买的基金组合(作为一个字段)建成临时表,再嵌套循环查看基金组合是否相同
# 购买基金的高峰期
-- 17 查询 2022 年 2 月购买基金的高峰期。至少连续三个交易日,所有投资者购买基金的总金额超过 100 万 (含),则称这段连续交易日为投资者购买基金的高峰期。只有交易日才能购买基金,但不能保证每个交易日都有投资者购买基金。2022 年春节假期之后的第 1 个交易日为 2 月 7 日,周六和周日是非交易日,其余均为交易日。请列出高峰时段的日期和当日基金的总购买金额,按日期顺序排序。总购买金额命名为 total_amount。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
t3.t as pro_purchase_time, | |
t3.amount as total_amount | |
from ( | |
select | |
*, | |
count(*) over(partition by t2.workday - t2.rownum) cnt | |
from ( | |
select | |
*, | |
row_number() over(order by workday) rownum | |
from ( | |
select | |
pro_purchase_time t, | |
sum(pro_quantity * f_amount) amount, | |
datediff(pro_purchase_time, "2021-12-31") - 2 * week(pro_purchase_time) workday | |
from property, fund | |
where pro_purchase_time like "2022-02-%" | |
and pro_type = 3 | |
and pro_pif_id = f_id | |
group by pro_purchase_time | |
) t1 | |
where amount > 1000000 | |
) t2 | |
) t3 | |
where t3.cnt >= 3; | |
/* end of your code */ |
要求中说明了只有交易日才能购买,那么就不用对是否是交易日进行约束校验。
“连续 3 个交易日” 意味着周五和下周一也算是连续的交易日, @row := datediff(pro_purchase_time, "2021-12-31") - 2 * week(pro_purchase_time) workday ,求出这天到上一年最后一天的间隔,再减去中间周末的时候(2 即表示周末的两天),即得这天是第几个交易日,
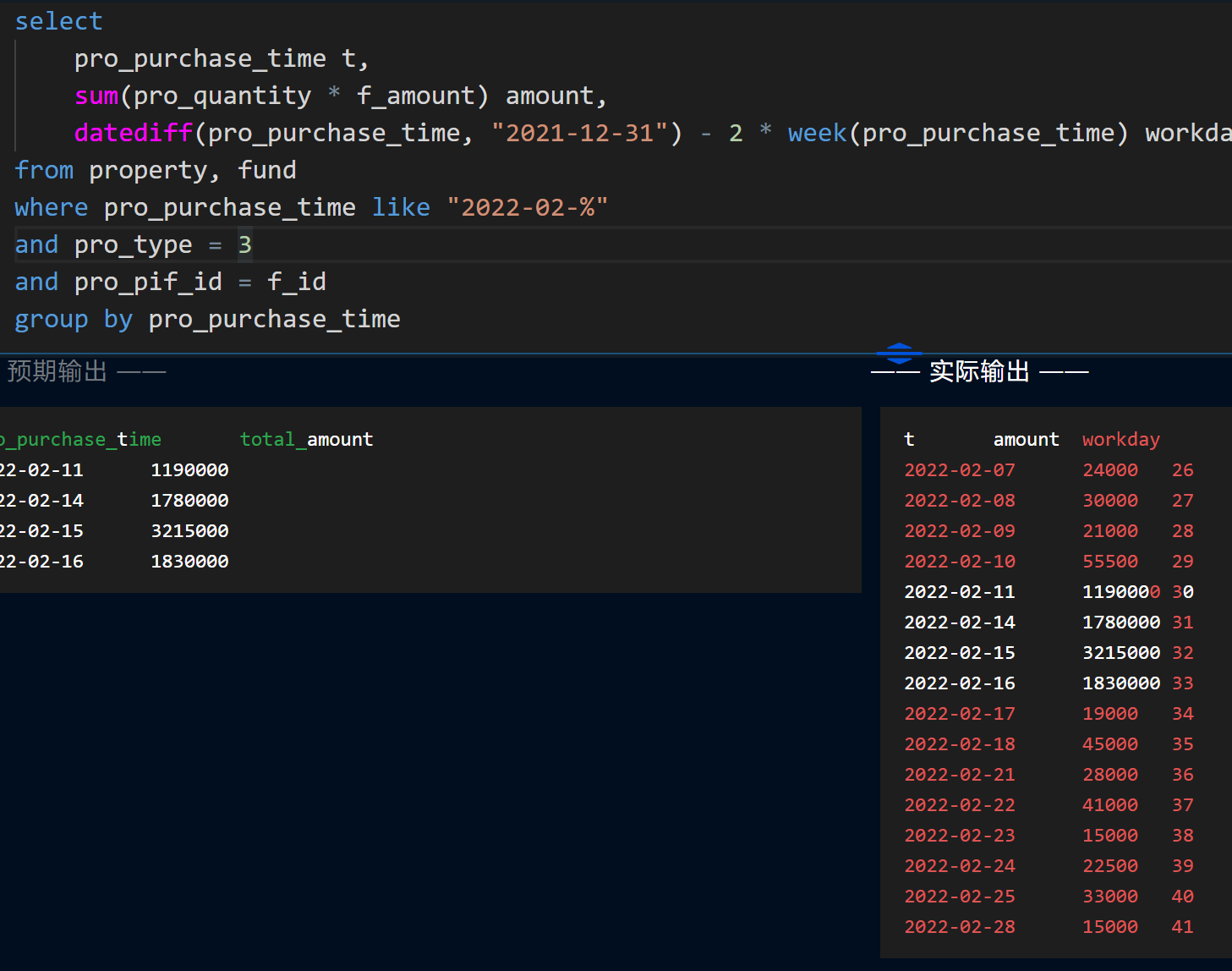
根据日历,排除掉周末后,上面的过程没有算上春节的
进行编号
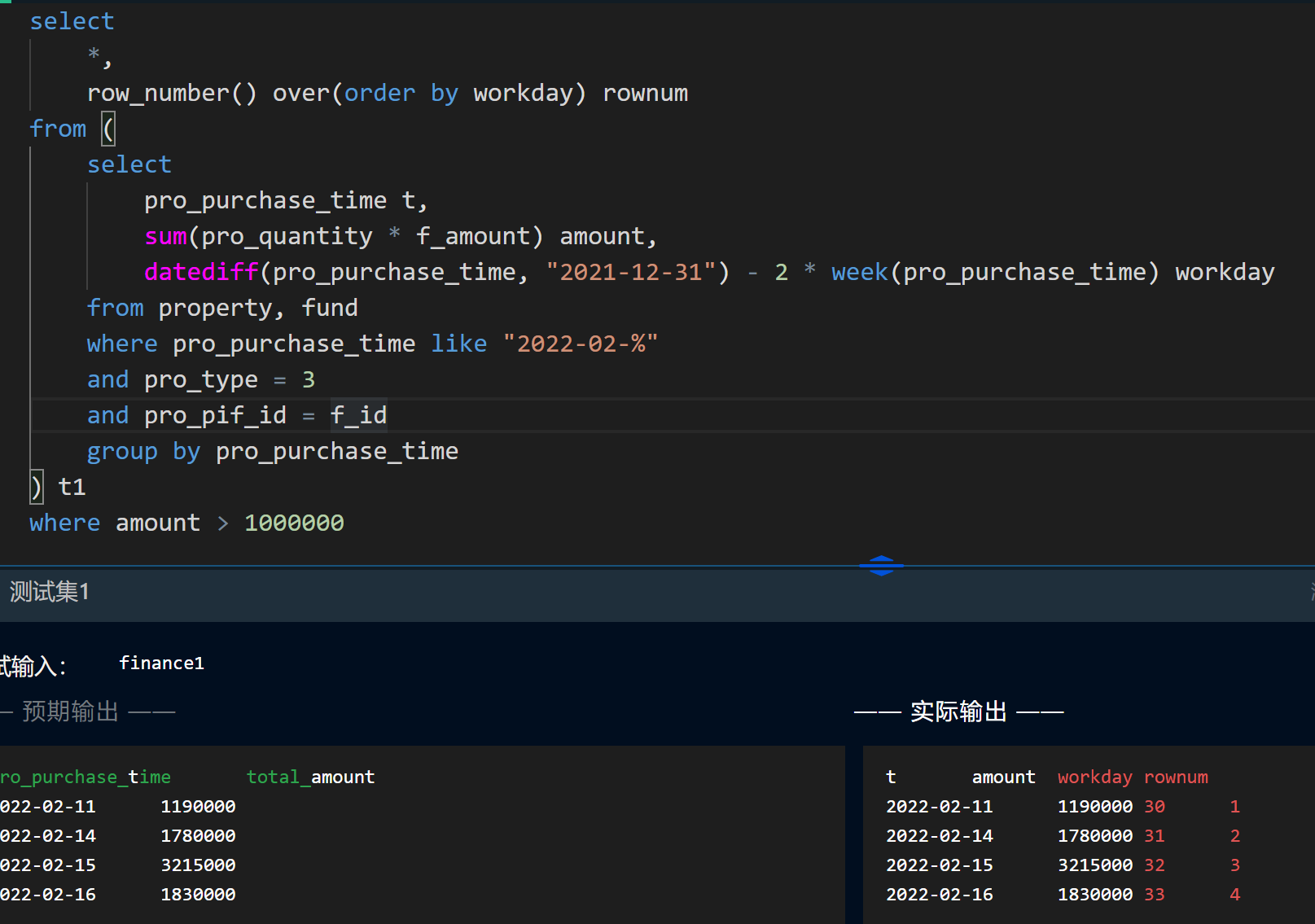
workday 和 rownum 都是逐行递增的, partition by t2.workday - t2.rownum ,则说明在连续的交易日中,
# 至少有一张信用卡余额超过 5000 元的客户信用卡总余额
# 相关知识
为了完成本关任务,你需要掌握:
分组统计;
分组筛选与行筛选;
派生表;
子查询;
# 编程要求
请用一条 SQL 语句实现以下查询要求:
查询至少有一张信用卡余额超过 5000 元的客户编号,以及该客户持有的信用卡总余额,总余额命名为 credit_card_amount。查询结果依客户编号排序。
-- 18) 查询至少有一张信用卡余额超过 5000 元的客户编号,以及该客户持有的信用卡总余额,总余额命名为 credit_card_amount。 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
b_c_id, | |
sum(b_balance) as credit_card_amount | |
from bank_card | |
where b_type = "信用卡" | |
group by b_c_id | |
having max(b_balance) >= 5000 | |
order by b_c_id; | |
/* end of your code */ |
一个客户可能有多张信用卡
# 以日历表格式显示每日基金购买总金额
# 相关知识
为了完成本关任务,你需要掌握:
分组统计;
日期函数的应用;
if 或 case 函数的用法;
有规律的行列转换。
# 几个重要函数
- week (d1) - 日期 d1 在当年的周次。week ('2022-2-7') = 6;
- dayofweek (d1) - 返回 d1 在本周的次序 (1 = Sunday, 2 = Monday, …, 7 = Saturday)
- weekday (d1) - 同上,但次序含义不同 (0 = Monday, 1 = Tuesday, … 6 = Sunday)
- IF (expr1,expr2,expr3) - 若 expr1 为 TRUE,返回 expr2,否则返回 expr3.
# 编程要求
请用一条 SQL 语句完成以下查询任务:
以日历表格式列出 2022 年 2 月每周每个交易日基金购买总金额,输出格式如下:
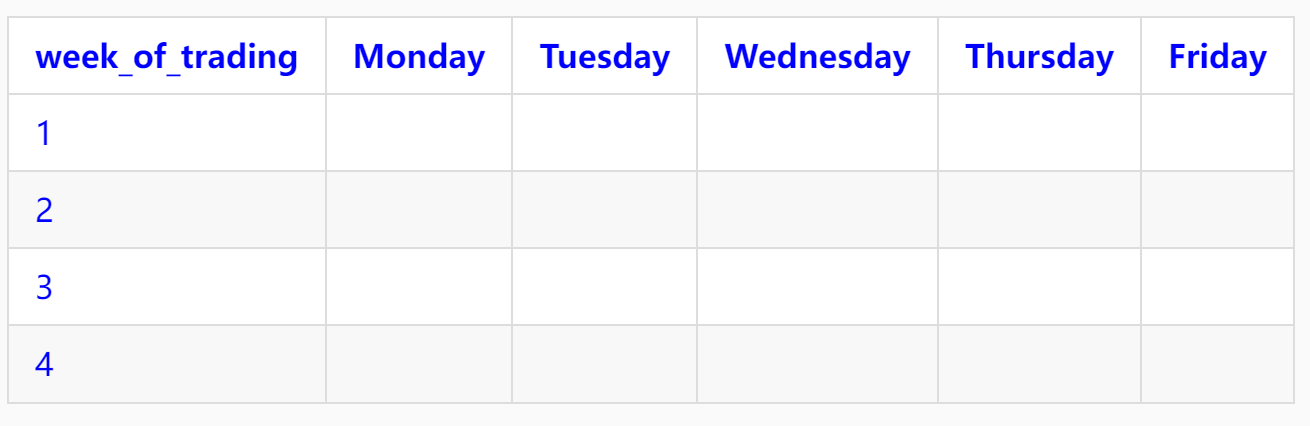
列表中第 1 列为周次,2022 年 2 月 7 日 (星期一) 为当月的第 1 个交易日,这一周记为第 1 周次。注意显示结果并不需要画表格线,只需按这个格式输出结果即可了。
-- 19) 以日历表格式列出 2022 年 2 月每周每日基金购买总金额,输出格式如下: | |
-- week_of_trading Monday Tuesday Wednesday Thursday Friday | |
-- 1 | |
-- 2 | |
-- 3 | |
-- 4 | |
-- 请用一条 SQL 语句实现该查询: | |
select | |
wk week_of_trading, | |
sum(if(dayId = 0, amount, null)) Monday, | |
sum(if(dayId = 1, amount, null)) Tuesday, | |
sum(if(dayId = 2, amount, null)) Wednesday, | |
sum(if(dayId = 3, amount, null)) Thursday, | |
sum(if(dayId = 4, amount, null)) Friday | |
from ( | |
select | |
week(pro_purchase_time) - 5 wk, | |
weekday(pro_purchase_time) dayId, | |
sum(pro_quantity * f_amount) amount | |
from | |
property | |
join fund | |
on pro_pif_id = f_id | |
where | |
pro_purchase_time like "2022-02-%" | |
and pro_type = 3 | |
group by pro_purchase_time | |
) t | |
group by wk; | |
-- 改了一下 | |
select | |
wk week_of_trading, | |
sum(if(dayId = 0, amount, null)) Monday, | |
sum(if(dayId = 1, amount, null)) Tuesday, | |
sum(if(dayId = 2, amount, null)) Wednesday, | |
sum(if(dayId = 3, amount, null)) Thursday, | |
sum(if(dayId = 4, amount, null)) Friday | |
from ( | |
select | |
week(pro_purchase_time) - 5 wk, | |
-- 减 5 是因为根据要求要从 1 开始,直接 week,2 月份是从 6 开始的 | |
weekday(pro_purchase_time) dayId, | |
sum(pro_quantity * f_amount) amount | |
from | |
( | |
select | |
* from property | |
where | |
pro_purchase_time like "2022-02-%" | |
and pro_type = 3 | |
) temp | |
join fund | |
on pro_pif_id = f_id | |
group by pro_purchase_time | |
) t | |
group by wk; | |
/* end of your code */ |