# 笔记一
记录自 https://www.bilibili.com/video/BV1PL411M7eQ?spm_id_from=333.337.search-card.all.click&vd_source=1c562831fab1cb4101e5b95d41c170e0
在计算机视觉里面很早的时候,我们就可以在一个大的数据集上,比如说 ImageNet 上面训练好一个 CNN 的模型,然后这个模型可以用来帮助一大片的计算机视觉的任务来提升他们的性能。
但是在 NLP 在 Bert 之前呢一直没有一个深的神经网络,使得我训练好之后能够帮助一大片的 LP 的任务,这就导致在 NLP 里面我们很多时候还是对每个人构造自己的神经网络,然后在自己上面做训练。
bert 出现使得我们终于可以在一个大的数据上训练好一个比较深的神经网络。然后应用在很多 NLP 的任务上面
pre-training 的意思是说我在一个数据集上训练好一个模型,然后这个模型主要的目的是用在一个别的任务上面。所以别的任务如果叫做 training 的话,那么在大的数据上训练我这个任务叫做 pre-training。
transformer 主要是用在于机器翻译这个小任务上面

总结下来就是这篇文章是关于 bert 这个模型,它是一个深的双向的 transformer,是用来做预训练的。针对的是一般的语言的理解任务,
bert 是用来设计去训练深的双向的表示。使用没有标号的数据。再联合左右的上下文信息。
设计导致训练好的 bert 只用加一个额外的一个输出层,就可以得到一个不错的结果,在于很多的 NLP 任务上面包括了问答,包括了语言推理。而且不需要对任务啊做很多任务,特别的架构上的改动。
GPT 它其实考虑一个单向的,它用左边的上下网信息去预测未来。bert 这里不一样是说它用了右侧和左侧信息,所以它是一个双向的。
ELMo 用的是一个基于 RNN 架构,而 BERT 是 transformer,所以 ELMo 在用到一些下游的时候。他需要做调整,但是 bert 比较简单,只需要改最上层就行了。
使用预训练模型做特征表示的时候,一般有两类策略。第一策略叫做基于特征的另外一个策略叫做基于微调的。
基于特征的代表作是 ELMo,对每一个下游任务构造一个跟这个任务相关的神经网络,他用的其实用的是 rnn 这个架构。然后预训练好的这些表示,比如词嵌入,它作为一个额外的特征和你这个输入是一起输入这个模型里面。我希望这些特征已经有了比较好的表示,所以导致你的模型训练比较容易。这也是 NLP 里面使用的一些预训练模型最常用的一个做法,就是把你学到这些特征跟你的输入一起放进去做了一个很好的特征的表达。
第二类是基于微调的,如 GPT,把预训练好的模型放在下游的任务的时候不需要改变太多,只需要改变一点,然后这个模型它预训练好的参数
会在下游的数据上进行微调,就是所有权重再根据你的新的数据集进行微调
在预训练的时候这两个途径它都是使用一个相同的目标函数,都是使用单向的语言模型。
语言模型就是单向的,给一些词,预测下一个词
标准的语言模型是一个单向的,如 GPT 是从左到右的。如果要做句子层面的一些分析的话,比如说我要判断一个句子他的情绪是不是对的的话,一次看所有就说从右看到左都是合法的,另外就算是词源上的一些任务,比如说 QA(question answer)的时候,我其实也是能够看完整个句子让我去选答案,而不是真的要去一个一个往下走。如果我把两个方向的信息都放进来的话,应该是能提升这些任务的性能的。
bert 是为了解决语言模型是单向的限制,使用了 masked language model。带掩码的语言模型。
带掩码的语言模型干什么事情:每一次随机的选一些字元然后把它盖住,目标函数是预测那些被盖住那些字。等价是说给个句子,然后挖这些空,然后让你填完形填空了。允许你看左右的信息。
在训练带掩码的语言模型之外,他还训练了一个别的任务叫做下一个句子的预测。核心思想是说我给你两个句子,你给我判断说这 两个句子在原文里面是不是相邻的,还是说我其实就是随机的采样两个句子放在一起。这样子的话能让你的模型去学习句子层面的一些信息。
三点贡献:
展示了双向信息的重要性。
假设你有个比较好的预训练模型的话,你就不用对特定任务一些特定的模型的改动,他说 bert 是第一个基于微调的模型。在一系列的 nlp 任务中,包括了句子层面和词元层面上都取得了最好的成绩。
代码模型公开
结论,最近一些实验表明是使用非监督的预训练是非常好的,这样子使他资源不多的任务,比如说我训练比较少的任务也能够享受深度神经网络。主要的工序,就是把前人的结果拓展到深的双向的架构上面,使得同样的一个预训练模型能够处理大量的不一样的自然语言的任务
有意思的是说 bert 和他之后的一系列工作证明了在 NLP 上面需要没有标号的大量的数据集训练成模型效果,比你在有标号的相对说小点数据上去的模型效果更好。同样一个想法现在也在慢慢的被计算机视觉采用就是我在大量的没有标号的图片上训练出来的模型也可能比你在 ImageNet 这个 100 万数据集上训练模型可能效果还更好。
bert 里面有两个步骤,第一个叫做预训练,第二个叫做微调。
预训练里面这个模型是在一个没有标号的数据集上训练的,在微调的时候我们同样是用一个 bert 的模型,但是它的权重被初始化成我们在预训练中得到的那个权重,所有的权重在微调的时候都会被参与训练,用的是有标号的数据。
每一个下游的任务都会创建一个新的 bert 模型,虽然他们用的都最早那个预训练好的 bert 模型作为初始化,但是对每个下游任务都会根据自己的数据训练好自己的模型。
架构:bert 模型就是一个多层的双向的 transformers 的编码器,直接基于原始的论文和它原始的代码。
调了三个参数,一个是 L 就是那个 transformer 块的个数;第二个是隐藏层大小;第三个是你在自注意力机制里面那个多头,的头的个数。
有两个模型,一个叫做 bert base,一个是 bert large。bert base 用的是 12 层,宽度是 768,你的头的个数是 12,所以它总共的可以学习的参数是一个亿。
L=12, H=768, A=12
L=24, H=1024, A=16
large 的话呢就是把层数翻了一倍,然后你的宽度从 768 变成了 1024。
589,824
1,048,576
BERT 模型的复杂度跟你的层数是一个线性关系,跟你的宽度是一个平方关系,因为你的深度变成了以前的两倍,那么你在宽度上面呢也选择一个值的这个增加的平方大概是之前的两倍。
它的头的个数变成了 16 这是因为每个头它的维度都固定在 64,因为你的宽度增加了,所以头数也增加了。
大的模型它的可学习的参数是 3.4 个亿。
把那个超参数换算成你可学习参数的大小也作为 transformer 架构的一个小回顾
模型里面的可学习参数主要来自两块,第一块是你的嵌入层,第二块就来自于你的 transformer 块了。
嵌入层就是一个矩阵。它的输入是你字典的大小 30k,输出等于你的隐藏单元的个数就是 H。它的输入会进入你的 transformer 块。
这 transformer 块里面有两个东西一个是你的自注意力机制一个是你后面的 MLP。自注意力机制本身是没有可学习参数的,但是对多头注意力的话,它会把你所有的进入的 K V Q 分别做一次投影,然后每次投影它的维度是等于 64。然后因为你有各个头,头的个数乘以 64 是等于 H
进来的话,有一个 K V Q,都会有自己的投影矩阵,投影矩阵在每个头之间合并起来,就是一个 H 乘以 H 的一个矩阵了。同样道理我拿到输出之后我们还会做一次投影,同样道理它也是一个 H 乘以 H 的东西。所以它的自注意力它可学习的参数是 H 的平方 ×4
然后再往上是你的 mlp,mlp 里面需要两个全连接层,第一个层的输入是 H,但是它的输出是一个 4 乘 H 的东西,另外一个全连接层它的输入是 4 乘 H,但是它的输出是 H。所以每个矩阵它的大小是 H 乘 4h,所以两个就是 H 的平方乘以 8。这两个东西加起来是你一个 transformer 块里的参数,然后你还要乘以 L,所以总数应该是 30K 乘以 H,。
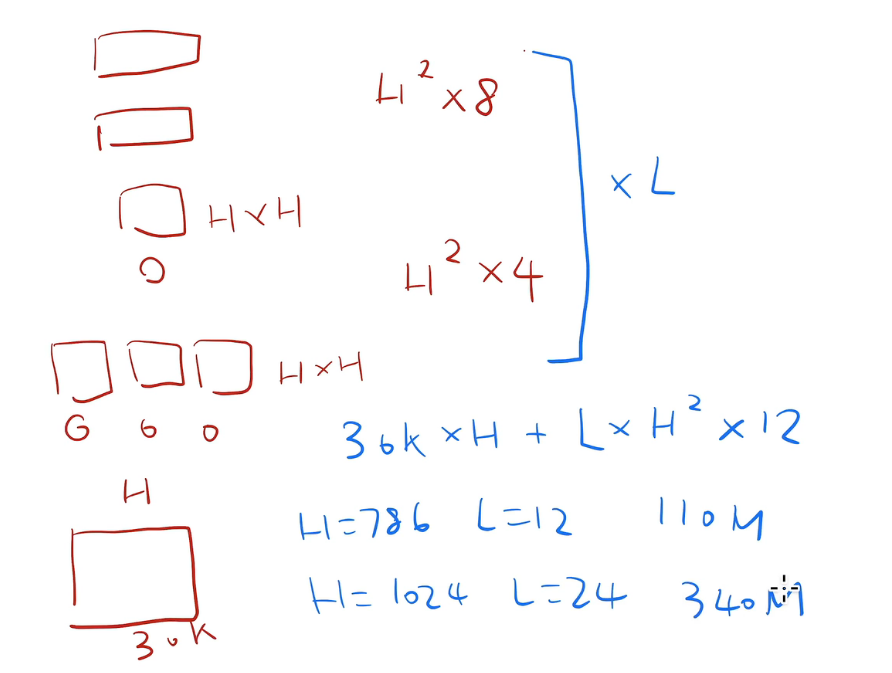
输入和输出,对下游任务的话有些任务是处理一个句子有些任务是处理两个句子所以为了使得 bert 模型能处理所有的这些任务的话,它的输入法既可以是一个句子,也可以是一个句子对。具体来说是一个句子的意思是一段连续的文字不一定是真正上的语义上的一段句子。输入叫做一个序列,所谓序列就是可以是一个句子,也可以是两个句子。这个跟我们之前讲的说的 transformer 是有一点不一样的,transformer 它训练的时候它的输入是一个序列对,因为它的编码器和解码器分别会输入一个序列,但是 bert 这个地方只有一个编码器。所以我们为了能处理 2 个句子的情况,我们需要把两个句子变成一个序列。
接下来具体看一下我们的序列是怎么构成的,用的切词的方法是 WordPiece,核心思想是说假设我按照空格切词的话,一个词作为一个 token,因为我的数据量相对来说比较大,会导致我的词典大小特别大,可能是百万级别。那么根据我们之前算模型参数的方法,那么你如果是 100 万级别的话。就导致我的整个可学习参数都在我的嵌入层上面。
WordPiece 的想法是说如果一个词在我整个里面出现的概率不大的话,那么我应该把它切开看它的一个子序列。如果它的某一个子序列很有可能是一个词根了,出现的概率比较大的话。那就只保留这个子序列就行了。这样的话可以相对比较长的词切成很多一段一段的片段,这些片段而且是经常出现的。这样的话我可以用一个相对来说比较小的 3 万的一个词典就能够表示为一个比较大的文本了。
切好词之后我们看一下怎么把两个句子放在一起,
我这个序列它的第一个词永远是一个特殊的一个记号是 [cls] ,代表是 classification,这个词的作用是说 bert 希望它最后的输出代表是整个序列的一个信息,比如说的一个整个句子层面的一个信息,因为 bert 使用的是 transformer 的编码器,所以它的自注意力层里面每一个词都会去看输入里面所有的词的关系,就算是这个词 [CLS] 放在我的第一个的位置它也是有办法能看到之后所有的词。
第二个是它把两个句子合在一起,但是因为我要做句子层面的分类,所以我需要区分它的这两个句子。它有两个办法来区分,一个是在每个句子后面放一个特殊的词 [SEP] 。第二个是说他学一个嵌入层来表示这个句子到底是第一个句子还是第二个句子。
对每一个词元它进入 bert 那个向量表示它是这个词元本身的 embedding 加上它的在哪一个句子的 embedding,再加上你的位置的 embedding,
图二演示的是 bert 的嵌入层的做法,就是给一个词元的序列,然后得到一个向量的序列,这个向量的序列会进入你的 transformer 块。
一个方块是个词元,
第二个是 segment,他就表示第一句话还是第二句话,a 还是 b
后面是一个位置的嵌入层,它的输入的大小是这个序列最长有多长。它的输入就是每一个词元的这个序列里面的位置信息
transformer 里面的位置信息是手动构造出来的一个矩阵,但是在 bert 里面不管你是属于哪个句子还是你的位置在哪里,它对应的向量表示都是通过学习得来的。
上面是 bert 对于预训练和微调都同样部分接下来我们来讲一下,在预训练和微调之间不一样的部分。
在预训练的时候主要有两个东西比较关键一个是说你的目标函数,第二个是说你用来做预训练的数据。
掩码的语言模型
对一个输入的词元序列如果一个词元是由 WordPiece 生成的话那么它有 15% 的概率会随机替换成一个掩码,但是对于那些特殊的字元就是说第一个词元和中间的分隔词元我们那我们就不做替换了。
我们在做掩码的时候就会把词元替换成一个特殊的 token [mask] 。在训练的时候有,在微调的时候是没有这个东西的,因为微调的时候我不用这个函数,所以没有 Mark 的东西。导致在预训练的时候和微调的时候看到的数据会有一点点不一样,这会带来一点问题。它的解决方法是,这 15% 的被选中去掩码的词,有 80% 的概率我是真的把它替换成这个特殊的掩码符号,还有 10% 的概率我把它替换成一个随机的词元,还有 10% 的概率我什么都不干。中间的情况是给你加入了一些噪音,最后一个情况其实是用来你和你真的在做微调的时候,你真实看到数据是没有变化的,所以你真是看到数应该就是它了。
预训练中的第二个任务就是预测下一个句子,在 qa 和在语言推理里面他们都是一个句子对,所以呢如果能够让他学习一些句子层面的信息是不错的。具体来说我们的一个输入序列里面有两个句子 A 和 B, 然后有 50% 的概率 b 是在原文中间真的是在 a 之后,还有 50% 的概率 B,就是一个随机从一个别的地方选取出来的一个句子。那么意味着说 50% 的样本是正例 50% 的样本是负例。
我们应该用文本层面的一些数据集就是我在里面是一篇一篇的文章,而不是一些随机打乱的一些句子,这是因为 transformer 确实能够处理比较长的序列。
用 bert 做微调的一个一般化的介绍,
bert 跟一些基于编码器解码器的家伙有什么不一样,transformer 是编码器和解码器,因为我们把整个桔子堆都放在一起进去了,所以 self-attention 能够在两端之间相互能够看。但是在编码器和解码器这个架构里面,编码器一般是看不到解码器的东西的。
bert 不能像 transformer 那样做机器翻译了,
在做下游任务的时候,会根据我的任务设计我们任务相关的输入和输出。好处是说我的模型其实不怎么样变,主要是怎么样把我的输入改成我要的那个句子对,
如果你就只有一个句子的话,比如说我要做一个句子的分类的话,那我 B 就没有了,然后根据你下游的任务要求要么是拿到第一个词元对应的输出做分类或者是拿到对应那些词元的那些输出做你要的那些输出。不管怎么样,都是在最后加一个输出层,然后用一个 softmax,得到我要的那些标号。
# 笔记二 代码解读
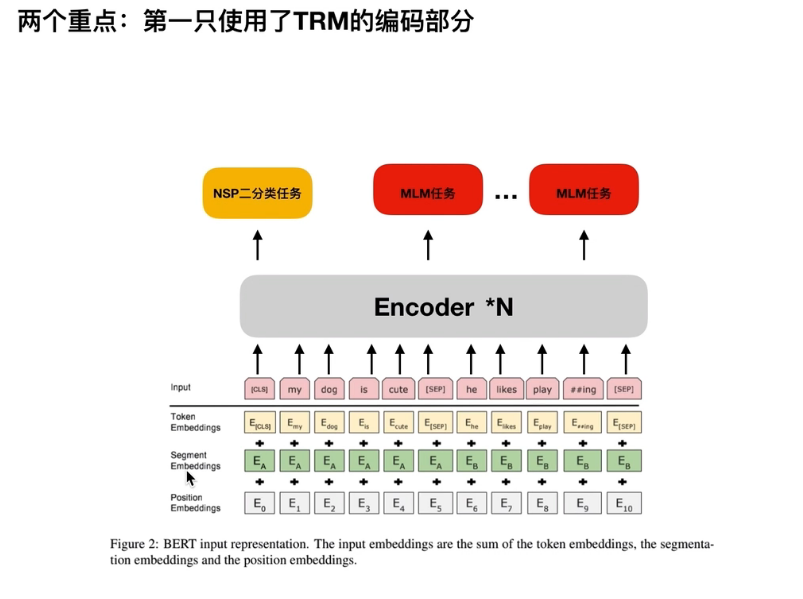
token embedding,代表的是数字符对应的索引,对应的词向量
segment embedding 一般引用用于区分不同的句子,我们通常是用 0 和 1 去区分不同的句子。
position embedding,这里是可以训练的,区别于 transformer 中的 position encoding
使用的是第一个字符 cls 最后的输出,然后去接 linear 层做这个二分类任务。
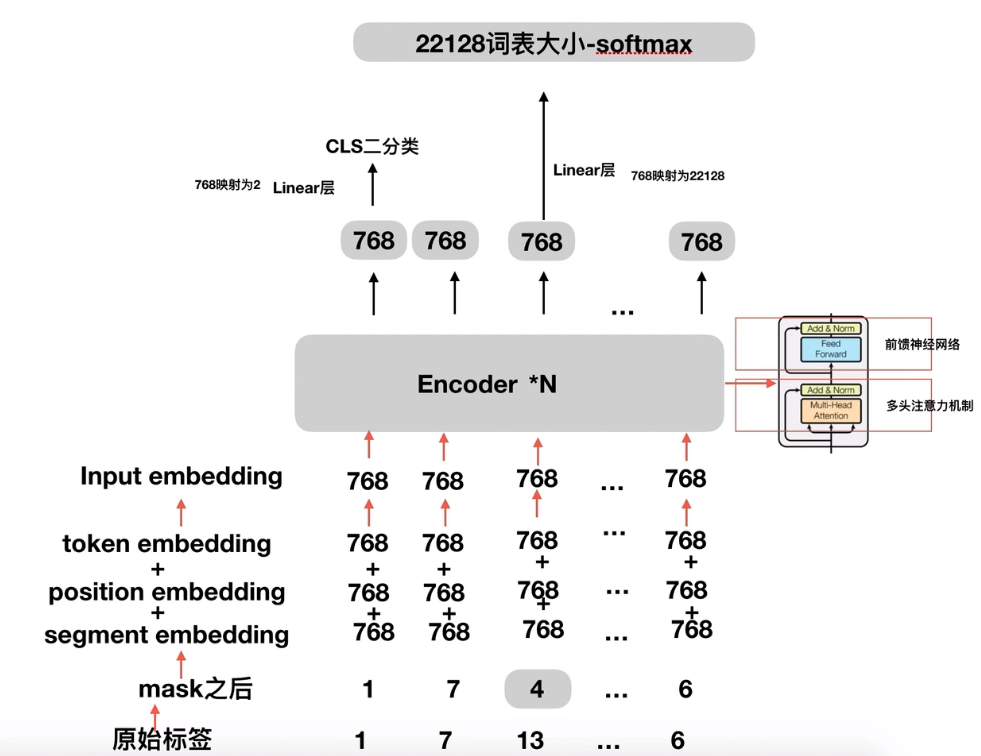
原始标签即把字符转换成数字之后对应的是哪些数字。在上图中, [cls] 对应 1, [mask] 对应 4,把 13mask 成 4 了。每个 embedding 对应的都是 768 个维度