# gpt-1
# 标题
先看 gpt,文章的标题叫做 "Improving Language Understanding by Generative Pre-Training" 使用通用的预训练来提升语言的理解能力。
# 摘要
接下来我们来看一下摘要。摘要写的比较简单,我们先来看一下前面两句话讲的是会解决什么问题。他说在自然语言理解里面呢有很多不一样的任务,然后说虽然我们有很多大量的没有标号的文本文件,但是呢,标好的数据是相对来说比较少的,
这使得我们要去在这些标好的数据上训练出分辨模型的话,会比较的难,因为我们的数据相对来说还是太小了,接下来就讲作者怎么解决这个问题,他的解决方法是说我们先在没有标号的数据上面训练一个预训练模型。这个预训练模型是一个语言模型,接下来呢再在有标号的这些子任务上面训练一个分辨的微调模型,这个在计算机视觉里面早在八九年前以及是成为主流的算法,但是,在 np 领域一直没有流行起来,是因为在 nlp 里面没有像 ImageNet 那么样大规模标好的那种数据在计算机视觉里面我们要标好的 100 万张图片 ImageNet。
在 nlp 的话,并没有那么大数据集。虽然说机器翻译那一块我们也选能做到 100 万的量级,但是你一个句子和一个图片不在的一个尺度上面。上面一张图片里面含有的信息。那个像素的信息比一个句子里面能去抽取的信息来得多很多,所以一张图片可能能换 10 个句子的样子。那么意味着是说,你至少有 1000 万句子级别的标好的数据集才能够训练比较大的模型,在导致在相当一段时间里面深度学习在 nlp 的进展没有那么的顺利,直到 gpt 和后面的 bert 的出现才打开了局面。
注意这里我们还是向计算机视觉那样,先训练好预训练模型再来做微调,但是这个不一样的是说我们使用了是没有标号的文本。这个就往前走了一大步,然后再 gpt 系列后面的文章,再做 Zero Shot。那去走了另外一大步,如果说深度学习前面五年,主要是计算机视觉在引领整个潮流的话,那么最近几年可以看到这些创新很多来自于自然语言处理界,而且这些创新也在反馈回计算机视觉里面。比如说,之前我们读过的 mae 这篇文章就是把 bert 用回到计算机视觉上面,
我们在上介绍了 CLIP 也是打通了文本和图像。当然在自然语言处理前用没有标号的文本,它也不是第一次了。比如说十几年前就很火的 wordtovector 这个词嵌入模型就是用到大量的没有标号的文本,但是我们跟之前工作了一个区别,是说在微调的时候,构造跟你任务相关的输入,从而使得我们只要很少的改变我们模型的架构就行了,这是因为文本跟图片不一样,它的任务更加多样性一些。有些任务要对词进行判断。有些任务需要对句子进行判断。有些任务需要一对句子或者三个句子。还有些任务要生成一个句子,所以导致每个任务都需要有自己的模型。我们最早的词嵌入只是做一个词上面的一个学习,然后你的后面的模型还得去构造之前的一些工作需要把你的模型进行一些改变来适应各个任务,但是这个地方我们只要改变输入的形式就行了,而不需要改变的模型。当然我们读过 bert,我们知道这个是怎么做的,但是,g pt 是在 bert 之前,所以他提出来的时候,在当时来说,
当然是有新意的。最后实验结果可以看到是说他在 12 个任务里面有 9 个任务能够超过当前最好的成绩,所以看上去是稍微弱于贝尔特之后的结果,他在十几个任务上都超越了前面,再导致是说 bert 为什么出来之后比 g p t 更加有影响力,因为它效果更加好一点,但是从创新度来讲,我觉得 g ppt 应该在 bert 之上,因为它毕竟是前面的工作。贝尔特在很多时候跟他的思路是一样的。
接下来,我们来看一下导言,导言的第一句话讲的是我们之前提到的那个问题就是怎么样,更好地利用无监督的文本 作者提到在当时候最成功的模型还是词嵌入模型,然后接下来第二段话是讲用没有标号文本的时候使用它遇到的一些困难,他主要讲的两个困难,第一个困难是说你不知道用什么样的优化目标函数,就是我给你一堆文本,你到底你的损失函数长什么样子了,当时候有很多选择,比如说你用语言模型啦,你用机器翻译啦,或者是文本的一致性,但是问题说没有发现某一个特别的好,就一个目标函数在一些任务上比较好,另外一个目标函数还是在另外一些问题上也比较好,
就是说,看你的目标。函数跟你实际要做的子任务,他的相关度有多高了,第二个难点是说怎么样有效的把你学到的这些文本的表示啊传递到你下游的子任务上面,这也是因为 nlp 里面的子任务差别还比较大的,没有一个简单的统一的有效的方式,使得一种表示能够一致的迁移到所有的子任务上面好,接下来第三段就是说 g p t 这本文章,呢他提出了一个半监督的方法,然后呢在没有标号的文本上面训练一个比较大的语言模型,然后再在子任务上进行微调。
当然,我们现在对这一套比较熟悉,啊但是有意思说,你回到当年,作者用的是半监督学习这个词,半监督学习在机器学习间可能在十年前是非常的火的,他核心思想是说我有一些标好的数据,但我还有大量的相似的,但没有标号的数据,我怎么样,把这些没有标号的数据用过来,那就是半监督学习想学的东西,这个地方呢当然是可以放到半监督学习,里面啊就是说你在没有标号的模型上面训练以后一个模型之后,然后再在有监督的上面做微调,但是呢半监督学习里面还有很多别的算法,
但现在我们把 g p t 这一套方法和 bert 之后,所谓的工作也用到了类似方法,不叫做半监督学习,而叫自监督学习。这也是上一期的 clip 那篇文章,作者又说到同一个方法,但是在不同的论文的作者把它归类成不一样的办法。下一段讲的是,他用到的模型可以看到它,主要是要两点,第一点是说它的模型是基于 transformer 这个架构的,因为这篇文章发表在 transformer 这篇文章出来一年之后,当然,作者在作者工作的时候,应该可能更早,可能是 transformer 出来就几个月,
所以在试用 transform 松。还适用 rnn 的模型的时候,在时候不是那么显而易见的,所以作者解释了一下大概的原因。他说,跟 rrn 这种模型相比,啊他发现 transformer 在迁移学习的时候,他学到的那些 feature 更加的稳健一些,作者觉得原因可能是因为 transformer 里面有更结构化的记忆,使得能够处理更长的这些文本信息从而能够抽取出更好的句子层面和段落层面的这些语义信息啊。第二个技术要点是说他在做迁移的时候,啊。用的是一个任务相关的书的一个表示,
我们在之后会看到他到底长什么样子?最后一段就讲我的实验结果了,我们就不再这里给大家看了,下面是相关公司相关工作,我们就不给大家自己讲了,他就讲了一下,在 np 里面半监督是怎么回事,然后讲的是无监督的预训练的模型,还有是说我在训练的时候需要使用多个目标函数的时候会怎么样,这分别对应的是你的大的 gpt 模型怎么样,在没有标号的数据上训练出来以及说你怎么样,在子任务上运用有标号的数据进行微调,最后的时候,你在做微调的时候,它使用了两个训练的目标函数,
第三章就是讲这个模型的本身,我们来看一下。这节里面有三个小节,分别对应的是,我怎么在没有标号的数据上训练模型,怎么样做微调以及说我怎么样对每个子任务表示我的输入,
我们先来看 3.1,就是在没有标号的数据上面做预训练。假设我们有一个文本没有标号的文本,你们每一个词呢表示成一个 ui,那么它整个文本就表示成意直大。外,它是有个序列信息的,就此我们不会交换你的顺序。G p t 使用一个标准的语言模型的目标函数来最大化下面这一个似然函数我们来看一下就怎么回事。
具体来说,语言模型就是要预测第 i 个词出现的概率。那么,第二个词记为 ui,它怎么预测呢它是把 ui 的前面的 k 个词就是 ui 减 -,一直到 ui 减 k。K 这个地方是你的窗口大小,或者要做上下文窗口。也就是说每一次我们拿 k 个连续的词,然后再预测这个词后面那一个词是谁,具体来说,它的预测是用一个模型,这个模型继承坏,在这个地方给定你 k 个词给定模型,那么,预测这 k 个词下一个词,它的概率把每一个这样子的词啊就是 I,
它的位置从零一直到最后,把全部加起来,就得到我们的目标函数这个地方记为一,它不是你的那个范式里面的一,它就是第一个目标函数。因为它后面还有一个别的目标函数,它为什么是加是因为取 log 的原故,如果你做指数放回去的话,那就是所有这些词出现的概率相乘,也就是这个文本出现的联合概率就是说,我要训练一个模型,使得它能够最大概率的输出。跟我的文本长得一样的一些文章,所以这个地方坏模型是你的参数呢,k 是你的超参数就是你的窗口的大小。
从神经网络角度来言,那你就是你输入序列的长度,你的序列越长的话,你的网络看到东西就越多,就是它。越会倾向于在一个比较长的文本里面去找里面的关系,你可以越短的话,当然,你的模型相对说比较简单。只要看比较短的就行了,所以这个地方如果你想让你的模型很强的话,那么 k 可能要取到几十几百或者甚至上千,呐他在下面有解释了一下具体这个模型是谁,他用到的模型是 transformer 解码器,我们回忆一下,transformer 有两个东西,一个是编码器,
一个是解码器,他们最大的不一样在于是说编码器哪一个序列进来,它对第二个元素抽特征的时候,他能够看到整个序列所有的元素,但是对解码器来讲,因为有掩码的存在,所以他在对第 i 个元素抽特征的时候,他只会看到当前元素和他之前的这些元素,它后面那些元素的东西。通过一个掩码,使得在计算注意力机制的时候,变成零,所以它是不看后面的东西的这个地方,因为我们用的是标准的语言模型,我们只对前预测我们预测第 i 个词的时候,不会看到这个词后面的这些词是谁,
所以一定是往前的这个地方,所以我们只能使用 transformer 的解码器,而不能使用它的编码器,然后下面它给了稍微这个模型的一些解释单假设你对 transformer 比较了解了,他说如果要预测 u 这个词,它的概率的话,那么,把这个词前面这些词啊全部拉出来,就 k 个拿出来,继成一个大 u,然后把它做一个投影。就词嵌入的投影,再加上一个位置信息的编码,那得到你的第一层的输入,那么接下来我要做 n 层这样子的 transformer 块,每层我们把上一次的输出来进来,然后得到输出,因为我们知道 transformer 模块不会改变你的输入输出的形状,
所你一直做完之后最后拿到你最后一个 transformer 块的输出,然后再做一个投影用 softmax 就会得到他的概率分布了,如果大家忘记了 transformer 块就怎么定的话,欢迎回到我们之前,全这篇文章的讲解,视频里面有详细的讲解,因为我们已经读过了贝尔特篇尔章,我们稍微来讲一下他跟贝尔特的区别。贝尔滕我们知道他用的不是标准的语言模型,它用的是一个带掩码的语言模型,它就是完形填空,所以完形填空是时给一个句子。我把中间的一个词挖掉,让你预测中间的就是说,
你在预测的时候,我既能看见它之前的词能看见之后的词,所以它可以对应的使用的编码器编码器成看到所有所以使用编码器和解码器到不是他们两个的主要的区别,主要的区别在于你的目标函数的选取这个地方。G p t 用的是一个更难的,就是给前面一段话,预测后面一个词,预测未来,哎当然比完型填空要难。具体来说,我给你股票的信息到当前的股价之前都知道,我让你预测明天的股价远远的,难于是说我告诉你到今天为止的股价,但是我昨天的股票不告诉你,
然后你预测昨天这个股票的价格,你的知道过去和未来那么中结差值就能得到,中间就是预测的开放式的结局比预测中间一个状态要难很多,这也是导致了 g p t 在训练上和效果上,它其实比贝尔特要差一些的一个原因之一吧。那么,反过来讲,如果你的模型真的能预测未来的话,那么你比贝尔特这种通过完型填空学,然模型要强大很多,这是为什么作者需要一直不断的把模型做到,而且一直不断落易才能最后做出 g p 三那样子效果经验的模型出来,
这也是我们之前讲到的作者选了一个更难的技术路线,但很有可能,它的天花板也就更高了,所以这就是预选的模型,这也是为什么?我们说,g p 就是称丰满的一个解码器的简单来讲,就是什么回事对吧?接下来我们来看一下它是怎么样做微调的,在微调任务里面,我是有标号的。具体来说,每次给你一个长为 m 的一个词的序列,然后我告诉你这个序列,它对应的标号是 y,那么就是说我们每一次给这个序列去预测它的具体来讲,就是说,我每次给你 x,
一直到 xm,我要预测 y 的概率。这里的做法是把整个这个序列啊放进我们之前训练好的 GPt 的模型里面,然后拿到 transformer 的最后一层的输出他对应的 hm 这个词的这个输出,然后再乘以一个输出层,然后再做一个 softmax 就得到他的概率了。这是微微调任务里面所有的带标号这些序列对 我们把这个序列三输入进去之后计算我们真实的那个标号,上面的概率,我们要对它做最大化,这是一个非常标准的一个分类目标函数,然后作者说,
虽然我们在微调的时候,我们只关心这一个分类的精度,但如果把之前的这个语言模型同样放进来效果也不错,意思是说我们在做微调的时候,有两个目标函数。第一个是说给你这些序列,然后预测序列的下一个词和给你完整的序列,让你预测序列对应的标号。这两个一起训练效果是最佳的,然后他通过一个 lambda 把这两个目标函数加起来,最后这东西是可以调的,也是一个超 参数了。那我们知道微调长什么样子的情况下,接下来要考虑的是怎么样把 nlp 里面那些很不一样的子任务
表示成一个我们要的形式,就是说表示成一个序列和他一个对应的标号,那就是第 3.3 小节要讲的事情呢,
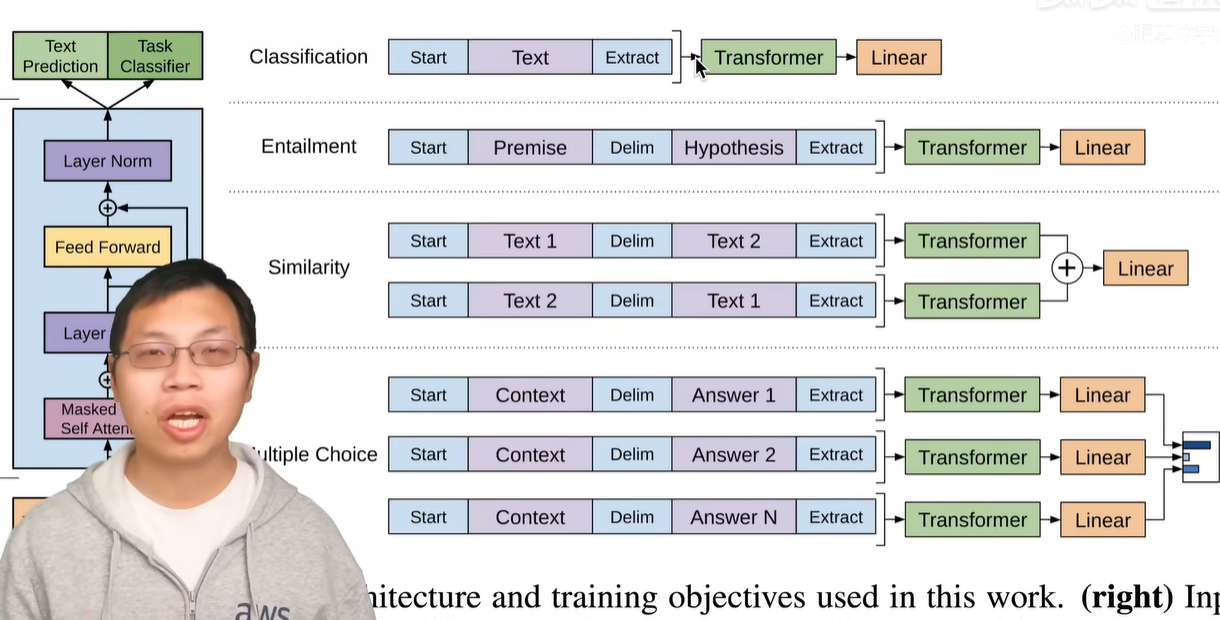
我们可以直接通过图一就能给大要讲清楚,大底是怎么表示的?这里给 nlp 里面四大常见的,用我们下面来看一看他们都是什么,第一类是最常见的分类就是说给我一句话或者一段文本,我来判断他对那一个标号,比如说,一个用户对一个产品的评价是正面的,还是负面的,他这里的做法是说,我把我要分类的这段文字啊。在前面放一个初始的词源,在后面加一个抽取的资源,然后就做成一个序列,序列放进的 transformer 解码器里面,然后模型对最后一个词,他抽取的特征啊。放进一个线性层,里面线性层就投影到那个标号的空间就是说,如果我要做十类分类的话,那么你的线性层它的输出大小就是 10,是在训练的时候,就是对每一个文本和标号对,我们把文本变成一个这样子的序列,然后标号呢就放在这个地方。参加训练。在预测时候,当然是说我们只拿到这个序列信息,然后对他直接做预测就行了,
所以这个地方跟之前的语言模型还是有那么一点区别的,因为这个线形层啊是我新加的,就是在微调的时候,我重新构造了一个新的线形层里面的权重可能是随机初始化的。让他的输出大小跟我的标号的大小是一致的,第二个应用叫做蕴含,就是说我给你一段话,然后再问你一个假设,你看一下我前面这段话,有没有蕴含我假设提出的东西,比如说 a 送给 b 素玫瑰假设我的假设是说 a 喜欢 b。那么,你就说我前面这段话是支持你这个假设了,如果说 a 讨厌 b。那么,
你可认为前面这段话是不支持这个假设了。如果我说 a 和 b 是邻居。那么你可以说前面假设既不支持,也不反对我这个假设,所以说白了就是一个三类的问题。我给你两段文本,然后让你做一个三分类的问题,他在表达的时候,就是把这两个文本串成一个长的序列。用一个开始符在这个地方,啊分隔符和抽取符。当注意到我们这里写的分隔符,但是在真实表达时候,你不能用这个词放进去了,是因为这些词可能在文本里面也要出现,所以这三个词源是一个特殊的句号,
必须要跟我的词典里面那些别的词是不一样才行的,不然的话,模型就会混淆了。第三个应用是相似,就是判断两段文字是不是相似,这个应用在 nlp 里边用的是非常广泛,比如说我一个搜索词和我一个文档是不是相似的,或者说两个文档是不是相似,我这样子能来去重。或者说两个问题。问的是不是相似来去重,因为相似是一个对称的关系,就是说 a 和 b 相似,那么意味着 b 和 a 也是相似的,但是我们在语言模型里面是有个先后的顺序,所以这个地方它做两个序列,
第一个序列里面第一段文字放在第二段文在前面,中间还是一样,用分隔符分开,前面加一个起始符和一个结束符,第二个序列就是把文字一和文字二交换顺序,第二个序列就是把文字一和文字交换顺序,这是因为它的对称关系,然后在两段序列分别进入我的模型之后得到最后的这个输出,然后再在上面做加号,最后进入我的线性层得到我们要的是相似还是不是相似的,一个二分类的问题,最后是一个多选题,就是说我问你一个问题,然后给你几个答案,
你在里面选出,你觉得正确。那一个答案,它的做法需要如果有 n 个答案的话,那我们就构造个序列,其中前面的都是你的问题,然后每一个答案作为第二个序列放在这个地方,每一个序列分别进入你的模型,然后用一个线性投影层,它的输出大小是 1,在得到你这个答案是我这个问题。问到的正确答案的一个置信度,对每个答案我都算一个样的标量,然后最后做一个 softmax,就知道我对这个问题,我对每个答案觉得是他正确答案的置信度是等于多少了,可以看到,
虽然这些应用上它的数据都长得不那么一样,但是基本上都会构造成一个序列。要么就是有一段话,要么就是要两段话,但是,分格开来如果更复杂的话,我可以构造出多个序列出来,但是这个地方不管我的输入形式怎么变我的输出它的构造怎么变?中间这个 transformer 模型是不会变的。就是说,我预训练好我的 transformer 模型之后,我再做下游的任务时候我都不会对这个模型的结构做改变。这也是 g p t 跟之前工作的一个大的区别,也就是这篇文章卖的一个核心点呢。
展完模性之后,我们来看展他的实验。实验上我们在底不会仔细给大家讲,大家只要注意到,这有两点就是了。第一点是他是在一个叫做 BooksCorpus 一个数据集上训练出来的。这个地方有 7000 篇没有被发表的书。第二个说候,他的模型的大小是要长成这个样子的,它用的是二层的一个 transformer 的解码器,然后每一层的它的维度是 768,所以我们关心的是说你用一个多大的模型,在一个多大的数据集上训练好的,在结果上它当然比了之前那些算法,他说,我们这样子的方法呀比前面的人都要好点这个是 g p 这个算法,
然后加黑市。表示我在京度上都比别人靠啊这个是那么几个数据集,上面基本上都是比前人高,然后我们再回过头来看一下我们之前讲过的。贝篇文章。注意到这个论文文,你就换成贝尔特了。这个地方是贝到 bertbase 他用的是一十二层,它的维度也是 768,所以贝尔特就是为了跟 g ppt 做对比的,虽然贝用的是编码器。G p 用的是解码器。编码器在同样的层数和维度大小的时候,它比解码器歧示那么简单一点点,因为它少一块带掩码的那个模块,
但是基本上你可以认为它也是差不多等价的,所以贝尔特贝斯作者就是为了跟 gp ppt 对比,然后你看贝尔特 large,他的层数翻了一倍,然后他的宽度翻了 1.3 倍啊。然后,最后,你的贝蜡是你的贝贝斯的基本上复杂度是差不多三倍的样子,那为什么你可以做三倍?呢是因为贝尔用的数据集更大一些。这个地方讲的是贝尔特他用的数据机,它用了 g p 的那个布普的数据机,那就是这个里使用的是词的歌数是用的八亿个词,然后他还用了一个基本上是三倍大 20 亿个词的 v k 的数据,
所以贝尔特的整个数据大小基本上是 g p 用的数据解的大概四倍的样子,所以他在这个数据体上训练的一个比 g p 大三倍的模型,那也是可以理解的,然后再回过头看一下贝尔特的实验。这个地方比较了是 g p t,然后贝尔特贝虽然跟你 g p 的模型是差不多,但实际上在整个的平均的精度上还是比较好一点,你看它是 75.1。那贝尔特做到了 79,然后如果你把模型做更大的话,他还能从 79.6 提升到 82.1。这是对我们讲过的。
贝尔特一个非常简单的回顾好,
# gpt2
接下来我们来看一下。G 第二就当你发现你的工作被别人用更大的模型更大的数据打败的时候,那么你怎么样去回应。g b tr 这篇文章,它的标题啊 Language Models are Unsupervised Multitask Learners 叫做语言模型,使无监督的多任务学习器,我们等会儿来看多任务学习气是什么意思,但无监督我们理解啊语言模型,我们理解做的上一座没有变化,最后一个做者也没有变换。之前。G p 那篇文章中间是要两个作者现在全部换掉了,换成了 4 个作者就是说主力干活的作者还是大脑板也没有变,
但是对原就换了一波,
就在看摘要之前,大家想一想,如果你说我用一个解码器训练一个和好的模型效果非常好,觉得自己棒棒的,但是几个月之后被人用一个编码器用一个更大的数据机训练一个更大的模型打败了,那你心里怎么想?那你在打回去,对吧?首先你不能换你的解码器了,因为你已经站好对了,如果你再换回编码器说编码器真的好。那么你前面的工作就浪费了,所以因为一座没有变,所以这个技术路线是不能变的,我还需要认为解码七号。
那么怎么打回去呢很简单,我可以把我的模型做得更大,数据做了更大,但如果我通过做更就能把前面的工作打败的话,那么我写文章也没什问题,但问题是在于如果你变大了,但是你还是打不赢打你的那个工作的话,那么你怎么办?呢这就是 g 第二这个工作要面临的情况我们可以大看一下。首先他做了一个新的数据集,叫做 wepText,然后有百万级别的文本。那么,跟之前的 v 点和那么,当然,这个数据要更大了,你有了更大的数据级之后,你能干嘛?
那就可以训练一个更大的模型,一十五亿个参数的去记得贝尔特拉,它最大只是 3.4 个亿,现在直接跳到了 15 亿。那就是说你的文本变成了百万级别的文本。那么你的模型变成了十亿级别的模型,但可惜的是说,当你变得那么大的情况下,你发现跟贝尔特比可能优势并不大,这时候做的就要找了另外一个观点叫做的 zero-shot 的一个设立,他,其实在 g p t 那篇文章的最后一节有奖,他用 zero-shot 来做一些实验,主要这些了解这个模型的训练的基石,在 g p 二这篇文章就把 zero-shot 的作为为他的一个主要的卖点拿了出来。
我们这篇文章主要看一下是他怎么去卖 zero-shot 这个事情呢在导言里面,作者说,现在一个主流的途径就是对一个任务收集一个数据集,然后在上面训练模型做预测。为什么这个东西很流行,是因为现在的模型,它的泛化性是不是很好的,就是说,你在一个数据集一个应用上训练好的模型很难直接用到下一个模型上面,然后他又提到叫做多任务学习,多任务学习一开始的观点是说,我在训练一个模型的时候,同时看多个数据集,而且可能会通过多一个损失函数来达到一个模型,
能够在多个任务上都能用。这个是在 90 年代末提出来的,在 2000 年到 2010 年之间啊也曾经是比较流行的一个话题。他作者说,虽然这个东西看上去比较好,但是,在 lp 里面其实用的不多,在 lp 里面,现在主流的算法也就是之前 g p 一和贝尔特那一类的就是说在一个比较大的数据上做一个预训练的模型,然后再对每个任务上做一个有监督的一个微调。当然这样子还需要两个问题,啊第一个是说对每一个下游的任务,你还是得去重新训练你的模型。
第二个是说你也得收集有标号的数据才行,这样导致你在拓展到一个新的任务上,是还是有一定的成本的,然后导论的最后一段话,就是说 g p t2 要干什么事情,他受我还是在做我的语言模型,但是呢,我在做到下游任务的时候,我会用一个叫做 zero-shot 的设立,zero-shot 是说我在做到下游的任务,在时候不需要下游任务的任何标注的信息。那么当然也不要去训练我的模型。这样子的好处说,我只要训练一个模型,在任何地方都能用,最后句话是说,我们得到了的,
而且有一定竞争力的结果。回到我们前面。讨论的,如果作者就是在 gp 基础上用一个更大的数据集训练更大的模型说,我比贝尔特好一些,可能也就好。那么,一点点不是好。那么多的情况下。那么,这篇文章有没有意思,大家会觉得没什么意思,工程味特别重。那么,现在来了,我换一个角度,我选择一个更难的问题,我说做 zero-shot 就不训练,不要下游任务的任何标号,然后跟你得到也还不错,差不多的,有时好一点,有时候差一点的结果。虽然这个时候从结果上看没那么厉害,
但新意度一下就来了对吧,所以这也给大家做研究。有一些提示,你不要一条路。走到黑做工程,可以一条路走到黑,你就把精度往死里做,但是在做研究的时候,你一定要比较灵活一点,尝试。从一个新的角度来看,问题,接下来我们来看一下方法,第二件,因为 g p 二和 g p 一在模型上基本上是长得一样的,所以我们不给大家一段一段读了,而是给大家讲一下。跟之前方法的一些不同的地方,在什么地方?回忆一下,我们在之前做 g p 的时候,
我们在预训练语言模型的时候,是在自然的文本上训练的,但是在做下游的任务的时候,我们对他的输入进行了构造,特别的是说我们加入了开始符结束符和中间的分隔符。这些符号在之前模型是没有看过的,但是因为你有微调的环节,所以模型会去认识这些符号,你给我一些去练样本,我去认识这个符号代表什么意思,但现在你要做 zero-shot,那你的问题是什么?你在做下游的任务时候我的模型不能被调整了,但是,如果你还引入一些模型之前没见过的
符号的话,模型就会感到很困惑,所以在这个设定下,我们在构造下游任务的输入的时候,就不能引入那些模型没有见过的符号,而是要使得整个下游任务,他的输入啊。跟你之前在预训练模型看到文本长得一样,就是说你的输入的形式应该更像一个自然的语言。这个地方,作者给了两个例子。第一个例子是说做机器翻译,如果你想把英语翻译成法语,你可以表达成这样一个句子,首先是翻译成法语给你英语的那个文本,然后接下来是你英语对应的法语的文本,所以前面这三个词啊,
你可以认为就是做了一个特殊的分割符的意思,在后面的文献里面,这个叫做也叫做提示,就如果你要做阅读理解的话呢,它又说,我可以设计一个提示。叫做回答这个问题,接下来是你读的那个文本,然后是你的问题,最后是你的答案,这个地方回答这个问题,作为一个提示啊。模型知道哦我现在要去做这个任务,接下来还有大段讨论你为什么可以这么做,因为这个东西不是作者提出来,是前面的工作,这篇工作提出来的东西。后面这些话基本上做都在讨论是说这个途径到底为什么可以工作?
作者觉得如果你的模型足够强大,它能理解你的提示覆盖的事情,他当然就比较好,另外一个是说可能在文本里面这样子的话,也很常见,可能本来就出现在这里面。那么他在下面一节讲数据。那一节稍微对第二点做了一些解释,我们来看一下他的训练数据长什么样子的?这一节里面他详细讲了一下它的数据是怎么样出来的?首先,第一段话是前面的人,大家用啊贝尔特用到 vcp。那么,他们自己用的是书。那么,接下来你要构造一个更大的数据集才行。
他说,一个可行性的办法,需要一个叫做 com 的一个项目。Com 是一个公开的网页抓取的项目。就有群人写了一个爬虫,然后不断的去在网上抓取网页,然后把的网页放在 aws 的三上面,然后供大家免费的下载。这个项目已经做了很多年,目前来说,应该是有 tb 级的数量级,应该是目前能够很方便下到的最大的一个文本。数记作者说,这个数据集啊不好用,这是因为它的信噪比比较低,因为抓回来的网页里面很多,可能是没有含有比较有意思的信息的可能就是一些很垃圾的网页,
那么你要怎么去清理他需要花很多很多的时间。就是说,虽然我没有能力,现在把你很好的标出来,但是它可以去利用网上大家已经过滤好的一些网页。具体来说,它用的是 reddit 是一个美国排名很靠前的一个新闻聚合王页在国内好像没有类似的一个服务,他的想法是说每个人可以去提交你感兴趣的一些网页,然后把你分门别类的放在每一个类别下面。接下来的用户就是对你投票说喜欢或者不喜欢,然后给他进行评论,然后你投票的话,会产生一个叫做 karma 的一个东西,
它最早来源于佛教里面的一个术语,啊当我不是专家,你大概可以理解成一个轮回报应值,在上面看。karma 可认为是用户对一个帖子的一个评价,让他选取了所有至少有三个 karma 的帖子。reddit 的用户已经帮你读过,而且觉得里面有一定的价值,然后他去把它所有的爬下来,最后得到了 4500 万个链接,然后再把它里面的文字信息给你抽取出来,就这样子得到了一个数据集。这个数据集最后大概是 800 万个文本,然后一共是 47GB 的文字,然后,在表 1 里面,
它有拎了一些句子出来证明说其实在我爬下来的数据里面就是对于英语翻译法语这个例子来讲,已经有了很多的这样子的样例。比如说这句话是说有人写了在法语里面写了一句这样子的话,然后如果翻译成英语来说,那就是长这样子啊。下面都是说,这些都是都是怎么样对应的?英语语句翻译成法语,讲什么样子,做者想表达一些。是说如果你在这样子数据上面训练语言模型的话,很有可能,他确实就可以真的把英语翻译成法语,因为你的文本里面出现过很多这样子的例子,
当你有了更大的数据集的时候,你当然可以把模型做了更大了。作者一共设计了 4 个模型,第一个模型有十二层,每一层,他的宽度是 768 一,共有一亿个可学习的变量,那么就是来自于之前的 g p 或者贝贝斯第二个模型就是 bert large 了,然后他在之上啊最大的情况下,是说他把层数再翻了一倍就是 24 就是 24 变成了 48,然后你的宽度啊也从 1024 变成了 1600,基本上是 1.5 倍的样子,得到了,一共有 15 亿个可学习元素的模型就后面是一些实验,
我们就没打算给大家仔细的去过,因为它的实验啊。主要是跟别的做 zero-shot 的方法比会长什么样子?比如说在这个地方,你看到了,是他的这 4 个模型跟当前在不同这些任务上面的 zero-shot 的 sota,它的方法的比较,这些方法不是我们之前讲过的 bert 那一类还是说专门做这些 zero-shot 那一类怎么样,当然是说 gp t,我们比你们多好,因为你用到的模型,复杂度和数据量确实比人家甩出几条接出来,让在最前面其实有一张表显示呢是他在几个任务上面的一些体现,
比如说这个是你的阅读理解,翻译摘要和问题,回答下面你的走分别适应的模型大小,因为它这个地方有 4 个,所以他一共有 4 个点,然后这个地方你看到阅读理解上来说,它似乎跟别人还是不错的,就是说这个是比较好的方法。摘要上面就差一点,啊这个是 secret,加上注意力机制的一个模型。还差一点,如果你在上面,那就你跟现在的比较好。模些差的远,因为现在比达模型还在远的上面很远的地方了,所以你还找得很,所以就是说在摘要里面。
作者说,虽然我们的结果还是比较有意思的,在一切任务上还做不错,另外一些任务上是有那么一点的意思,所以他讲的也是比较维婉的,但是注意到是说随着你的模型的增大,你的性能还是在上升的?也就是说你还是有希望训练更大的模型,使用更大的数据集使得你的模型的性能啊能够突破天际,使得跟真正的在有监督上面训练出来,效果是一样,这就是接下来工作 g p 三样干的事情,这样我们就快速的。过了一下。G 二这篇文章,
# gpt3
然后接下来我们来看 g ppt 三这篇文章。
G 第三这篇文章呢题叫做语言模型是在讲 g ppt 的时候,我们有讲过,他在文章的最后一段了,其实也做了一些实验,就是在子任务上面,我给你提供一些样本,但是不是在子任务上所有的样本的时候,其实语言模型能够用这少数的样本能极大的提升性能。G pt2 二是在 g p 上往前走了一大步,说在子任务 上面,我不给你提供任何相关的训练,样本,直接使用预训练模型,去对子任务上做预测。作者之所以这么做很有可能就是为了跟贝文章在新意度上能够有所区分,
我们有讲过一篇论文的价值,取决于你的新意度,要乘以,你的有效性,当然,要 乘以你问题的大小,这是不管是 g p 还是贝他做的是同样的问题,所以问题的大小是固定的。G p t2 二虽然在新一度上拉得特别高,但是有效性比较低,所以导致它论文的价值,最后很难说是一篇特别重要的文章,所以 g p 三就是尝试去解决 g p 二的有效性,所以有回到了。G p 一开始考虑的设置,就是说我不再去追求很极致的,我在一个子任务上不给你任何样例,
其实在现实生活中也很少,就算他是人类,你要学习的时候,你也要通过一些样本来来学习,只是说,人类在样本的的有效性上做得比较好,就通过一点点样本就行了。但是语言模型需要大量的样本,所以在这里的 few-shot 意思是说,我还是给你一些样本,但不用太多,只要你的样本的个数是在可控的范围里面,所以这个成本还是非常低的。在作者上面可以看到作者基本上换掉了啊 gpt 和 g p tr 的一座,以经跑到了最后前面的这些的,其实之前基本上都没有出现过的。
当然,如果大家感兴趣的话,可以跳到文章的末尾,他有详细的解释的,每个作者是干的什么事情,呢我觉得 gp 三这篇文章的一大贡献,真的就是虽然我画了很多作者的名字,但是我还真后面解释了每个作者干了什么事情,也是给大家一个标杆说你可以很么名字没关系,但是你至少告诉我说,这些人真的是干,能么活,不是就是上面挂个名字来转一个引用了。而且大家如果去仔细看的话,基本上看到前面这些做的基本上都是在做实验的上面。 G p 三次篇文章真的是做特别特别多的实验。
这也是整个 open ai,它做文章的一大特点,就如我们之前的文章,他也是做了大量的实验,所以导致有大量的作者,接下来我们来看一下摘要。摘要的前面几句话,没有什么特别好看呢?就跟之前没有什么太多区别,具体来看到是说我们训练的一个 g p 三的模型。这也是一个自回归模型,但是它有 1750 亿个可学习的参数比之前所有的那些非稀数的模型。稀疏的模型是说你整个权重可以是稀疏的,里面有大量的零,但如果你的模型很多,
很多零的话,你把这些零算进去的话,你的模型也算的特别大,所以它作为对比,啊它跟那些非稀疏的就是说不会存在很多的 0。这些模型相比,它比他要大十倍,就在可学习的参数上面,然后,因为你的模型已经那么大了。那么,在做子任务的时候,你如果还要去训练你的模型的话,那么的成本上是很难的所在这个地方,g p t3 上在作用到子任务上面,时候不做任何的梯度更新,或者是微调,就是就算是在 few-shot 的情况下给你一些样本情况下,g p 三也不是用微调,
因为因微调需要你总是去算梯度。那么大的模型算梯度是非常非常难的事情。从这个地方,它是不做任何的梯度更新的也是它的一大特点,然后他说,我在所有的这 lp 的任务上取得了很好的成绩,这也是跟 g ppt 二,它能区分开来。G p 二它的成绩跟我们想要的还差得很远,然后最后作者说,g p 三能生成一些新闻的文章,而且人类读起来是很难区分,看你到底是模型生成的还是人类写的,这也是第三,哪一大卖点也就是后面大占能通过他玩出花样来的一个主要的地方,
在这个地方还有,这就是摘要,就是说 g b 三特别大,在做子任务的时候,不需要算梯度,这是因为它特别大,而且它的性能特别好,这是他想要表达的东西,接下来是他的目录,这也是我们第一次读到,在论文的也放目录的文章了。然可以看到前面两节是讲它的方法写了实验,然后是他一个长长的结果。他又写了实验,在后面是一个长达 20 页的一个讨论,在讨论之后还有一个 20 页的附录,里面讲的是一些细节,所以整个文章有 63 页。它不是一篇投稿的文章,
而是一个技术报告。所谓的技术报告是讲没有发表了文章,因为他们要版面啊。和艺术的限制,你可以写得特别长,当然常有长的好处啊。他可以把东西写得特别细,所以你在赌他时候可能没有相关的背景。知识。读起来也没问题,但是长的坏处是说你的阅读门槛就增加了,如果我就想了解一下你做什么事情,我要赌 63 页。那我怎么读,但这个地方我的个人看法是 g p 三,真的没必要写那么长,他写那么长,他并没有把前面的东西交代的特别详细,
也就是为什么我们在讲 g p 三之前需要给大家讲一下什么是 g p 和 g p 二,因为这两账的内容在 g 三这篇文章里面是没有覆盖的,就是说。虽然我写了 63 页,但我并没有讲前面两个工作什么东西,而且 g p 三是完全基于 g p 二个模型的。63 页,并没有讲这个模型,而是他画了大量的篇幅去想着结果啊和后面的一些讨论,所以导致说在读这个 63 页的论文之。那我们先得把前面两个论文给读了才行,所以我个人是非常不推荐大家这种写法,
你要么就写的短一点,大家读下来,很快就知道你的中心思想。要么你就写得长一点,把前面的背景知识给大家。详细的介绍一下,我不需要读前面的文章。从你这篇文章开始,我也能知道你在做什么?像这种,你既需要读前面文章,又需要读过很长的文章,只要当你的工作是真的是特别特别好的时候,你才可以。那么任性别人才会来读你的文章了,我们接下来看一下导言。导研的第一段,还是说,最近一些年来,nlp 里面大家都使用预训练好的语言模型,
然后再作微调,第二道话是说这当时有问题的。他说问题。呢他说,我们对每个子任务还是需要一个跟任务相关的数据集,而且呢要跟你任务相关的一个微调。具体来说,他立了三个问题,第一个问题是说你需要一个大的数据集,你得去标号吧。这当然是有问题的。G pt2 也讲到这个事情了,第二个我觉得就相对来说,比较虚一点,就是说,当你的一个样本没有出现在你的数据分布里面的时候,你泛化性不见得就比你那个小模型要好,所以是说,如果你在微调上面的效果很好的话,
也不能说明你的预训练的模型,它的泛化性就特别好,他很有可能就是你过拟合你的预训练的训练数据,而且这个训练数据跟你的微调所要的那些任务啊。刚好有一定的重合性,就导致你在这些微调任务上是做得比较好的,就个之前用书来做与训练。用 vtp 做与训练,或者是在网上爬到网页做预训练。这些文字里面刚好包括你所有下游 任务,他要的那些文字,他们都是类似的一些文字,所以导致你的微调效果比较好,但是如果你换到一个别的语种,啊或者换到一个更专业性的文本上面,
你的表现里可能就不那么的好了,所以作者在这里的意思是说,假设我不允许你做为一条,不允许你改变你预训练模型的参数的话,那么你就是真的就是拼的预训练模型的泛化性假设我允许你微调的话,那么,预训练模型可能好一点,坏一点他都差别不那么大了。第三个是说人类啊大家都会受到人类人类不需要一个很大的数集来做一个任务,啊就是说你又一定的语文工底的话,我让你做一个别的事情,你可能给你两个例子告诉你怎么做就行了,你不需要再采集成千上万,
就你不要做个基本习题集 ,才会掌握一个小应用了,当然后,作者提出这个问题之后,要讲他的解决方案,他的解决方案 其实也就是做 few-shot 或 zero-shot 的学习了。他这个地方呢作者呢他又换了一个名词来了。他说,一个解决这个问题的办法叫做 meta-learning,叫做元学习,我觉得作者在取名的这个事情上不见得是那么的,精确就是跟 g p 二用的是多任务学习,但是它其实跟之前的 multi-task learning 还是有那么一点点区别的,然后在这个地方,他又试图去重新定义什么叫做 meta-learning,
他有一个注释。啊有一个常常的注释。讲的说啊他我们跟之前大家叫的 meta-learning 当然是有一点的不一样了,所以这个地方我们有我们自己的定义,但我觉得你如果想重载前面大家都知道的一些名词的话,除非有特别多的必要啊。不然没意义,因为你会给大家造成误解,而且大家现在讲到 g p 三这篇文章的时候,也不会去提它是用的 meta-learning,是 multi-task learning。那你获者是他是用的是 t,然后他当然在后面又定了一个名词,叫做 in-context learning 那里就是在上下文之间的学习。虽然然用的是 few-shot few-shot,
它在这个地方在摘有面已经讲过我是不更新我的模型的,因为在计算机视觉里面我们也讲 zero-shot 的好理解。那我什么都不干,没关系,但是作为 few-shot 的话,我给你一些样本的话,我还是可以用这些样本来对我的模型进行更新,这样子我能够更拟合这个上面去,但他这个地方他强调的是,我不要对我的权重做任何的更新,因为你的模型太大了,更新不了,所以呢他这个地方要需要跟前面做区分开来,所以他尝试的用了两个名词的这个地方一个是 meta-learning 的,一个是 in-context learning
但是大家理解一下他讲什么就行了。所谓的 meta-learning 就是我真的训练一个很大的模型,里面的泛华性还不错。in-context learning 是说我在后面的时候,即使告诉我一些训练样本我也不更新我的权重,他在前面有画一个图,啊就是图一,上面有讲了一下 meta-learning 的大概一个想法,他这个地方画的是有一点点的奇怪的啊。他看上去好像是讲我的模型是怎么训练?就是说我有一个通过 sgd 来做预训练的过程,然后呢在每一步里面好像要做一个什么样的事情,它其实它不是真正的讲 g p 三这个模型怎么训练出来的,
而是说这个语言模型呢你可以怎么样类比成一个 meta-learning,呢他就说,如果你这一个是一个样本,这也是一个样本,而且每个样本来自不同的文章的时候,可能他要干的事情不一样,比如说这个样本有这一段话告诉你的是各种加法,怎么做就下面的话,告诉你是一个错别字,怎么样?改成一个正确的,然后再后面就是英语。翻成法语,所以说在每一个段落或者一个文章,如果来自很不一样地方的时候,他可能教你不一样的东西,如果你在大量的这种很多样性的文章上做训练的时候,
你的模型多多少少有在做一个元 学习的过程,就是他学习的大量的任务,而且每一个段落,你可以认为是一个叫上下文的学习,因为他们之间是相关的,然后你啊从上下文来得到一些信息,但是它们之间呢它就没有太多关系了,就是多个任务之间了,所以这个东西放在这里啊。其实放不放,我觉得大都不影响到它的模型的,啊但是,放在这里,我们就讲一下,但是,大家如果一开始读的时读的有点奇怪啊。可以忽略不要紧,然后再讲了他的设定之话,他有说,
最近啊大家的模型的大小变大越来越大,但是,其实我觉得也就是 open ai 把整个军备竞赛给大家搞了起来,叫 g p 三一出来,大家都觉得哇你可以做那么大,然后别的公司也纷纷的跟进。不管是美国的还是国内的公司,大家也愿意去参加这样子的比赛,然后在后面也是说 gb 三是一个 1751 个可学习参数的模型,让它的模型,它的评估适用的做三个办法。一个叫做 few-shot,也就是说,对每个子 任务啊。我跟你提供大概十到 100 个的训练样本。
那么,他的一个特殊的情况叫做 one-shot learning,就是每一个任务,我只给你一个样本,就说英文翻译法语的时候,我就告诉你一个英文,哈喽,沃尔怎么翻成法语的那一个词,然后让你接下来给我继续翻下去。那么接下来是 zero-shot 就是说我一个样本的,不告诉我就让你英语翻法语,然后他在一开始啊给大家的一张图,给大家展示了一下,在三个设定下它的模型的一个区别,它的轴在这个地方是整个语言模型课,学习参数的大小。啊这 1.3 基本上就是 g p 二的模型,
然后你的轴是你的,当然你在很多子人物上面他做了一个平均就是这些虚线是每一个子任物上的,然后他做品均就变成了三个实现,然后这里有三条线,颜色不一样的线。黄色表示是绿色。表示的是 one shop。蓝色。表示的是 de 之前我们讲过的 g 二这篇文章你可以认为就是 1.3 这个模型,然后用 de。那么精度可以认为是平均下来是 30% 左右的样子,然后你把 1.3 变成了 175 的时候,就这个点。那时候而且使用了就允许给你十到 100 个的样本的时候。
那么,基本上看到他的精度接近了 60% 啊就是基本上你的精度翻了一倍了,所以可以看到效果还是非常明显的好。这就是他的导言,接下来我们来看一下,第二章业就是他的模型的部分,在模型的部分呢,它给大家又重新讲了一下什么叫做 fine-tuning,然后他的 few-shot 和他 one-shot 以及他的 zer o-shot 到底是什么区别,但其实你在这个地方你可以通过下面这个图啊是看得比较清楚的。首先,右边讲的是微调是怎么做的。在微调的时候,我们训练好预训的模型之后,在每一个任务上面,
我们提供一些训练样本,然后这个地方假设我使用批量大小为 1 一来训练的话,就每次给你一个样本。这个是英语犯法语的样本,因为我有标号,所以我能计算损失,然后我就可以去对它的权重进行更新,然后再拿到一个新的样本。继续更新就可以当做一个很正常的训练任务来做,但是跟之前不一样的说微调。通常对数据量的要求要少于从零开始训练,而且在学习率上通常可以做了比较小一点,这是因为微调的初始值。啊那个模型是用预训练好的模型做的,
所以他跟你最终的解已经很近了,所以你只要大概稍微调一下就行了,暂时在 g p 三模型的设置里面,它追求的是不做梯度更新,但不做模型更新,他肯定是有他的新意度了,但反过来讲。那么大一个模型假设换了一个新任务上还得在做更新的话,那么他的使用门槛是比较高,所以也不可能使得像现在那样,大家可以在 g p 三上面玩出花来它,这里使用的是英语翻法语这个例子,他想干的事情是说把英语的 cheese 翻成法语的对应的单词假设在直接的 short 里面怎么办?
他就在前面加一句说把英语翻成法语,然后冒好,这是你这个任务的描述,但是他希望你预训练好的 gp 三模型的理解。这句话是想干什么事情,然后是把我要翻译的词放进来,加一个箭头。这个东西叫做 prompt,也叫做提示,告诉你这个模型说好,接下来就是轮到你输出了,然后把这句话放进模型模型对下一个词的预测这个词,那就应该是 cheese,它对应的翻译的单词。如果你对了,那就是对了。如果错了,那就是你模型预测错误。
如果使用 one shot,
怎么做,呢就是在你任务描述之后和在你真正的做。翻译之前,我插一个样本。进来就是在定义好这个任务之后,我再告诉你一个例子。英语单词翻成法语单词应该是这么翻译的,就希望你在模型在看到整个句子的时候,能够从这条里面提取出有用的信息来帮助你做后面的翻译。注意到这一点是说这是一个样本。放进去的,它只是做预测它不做训练。就是说虽然他是一个训练样本,但是他放进去之后是不会对模型算梯度也不会对模型做更新,所以他希望的是,
你在模型在做前向推理的时候,能够通过注意力机制是然后去处理比较长的序列信息,从而从中间 抽取出来有用的信息。能够帮助你下面做事情,这也是为什么叫做上下文的学习就是你的学习,只是限于你的上下文。那么,few-shot,就是对 one-shot 的一个拓展了就之前我是给你一个样本,现在我会给你多个样本,当你可以更长,但是更长不一定有用,因为你这个模型不一定能处理特别特别长的数据就是说,如果你的序列很长的话,那么模型也不一定要能力把整个句子里面的信息跟你抽取出来,
然后让你帮助到生成做这个事情,所以看完这个图就有大家就知道这两种模式之间的区别。Gp 三采用了这序列当然是对新的任务更加友好了。就是说我碰到一个完全之前没见过的任务的话,我不要去更新我的模型,因为做模型的推理和做模型的训练,在你的设置上是很不一样的,因为在训练的时候,我对内存的要求更高,而且有超参数要调,而且得很好的准备你的训练数据,现在我只要做预测就行了,哪一个新任务给你,你把结果返回给我就行了,这当然是他的好处,
但也有一点的坏处啊。坏处是说假设我真的有很多训练样本,那怎么办,比如说我就做英语到法语的翻译,大家很容易在网上找到个几百上千个样本来帮助你翻译,对吧,这个时候你发现你想放进去其实是很难的一些事情,你难道你要构造个样本,里面把整个子任务的训练数据 放进去吗?那么就是特别长,你可能模型处理不了第二个问题还是相关的,就是说我假释有一个还不错的训练样本,然后你的模型呢在不给你的训练。样本上表现不行,我需要给你个训练样本,
但是每一次我都给你,就每一次做一个新的预测的时候,我都把你给你,因为你这个模型是每一次的时候,要从中间去抓有用的信息,就我不能把上一次模型从中间抓取的信息给你存下来,存到你在模型里面,所以这也导致说,虽然 g p t 三在一年半前就把这个效果做得那么好,但实际上好像用 few-shot 做这种上下文的学习些似乎用的还不那么的,多
2.1 节讲的是它的模型和架构。他说,g p 三的模型跟 g p 二的模型是一样的,后面补充了 g p 二模型跟之前 g p 的区别是你的模型的初始改变了,
啊把你的 normalization 放到了前面。那和可以反转的词元,但是也做了一点的改动。具体来说,它是是把 p 这个工作啊里面的那些改动给你拿了过来,然后他设计了 8 个不同大小的模型,具体来社会看,在表 2.1 年讲了,这个表里面没一行。表示的是一个模型,每个劣能表示的是模型的一些参数,比如说这个列表示的是,你模型,里面要多和可学习的参数,然后你在模型里面要多少层,然后你每一层呢你那个词表示成一个多么长的向,量以及在多头注意力里面有多少个头就是你每个头的那个维度大小,
它就是等于你。这个低摩处于你安在训练的时候,每一个小批量大小多大,最后是你在训练的时候,用的学习率是多少?首先看一下第一个模型。啊第一个模型是 g p 三,可以看到他一十二层每一层大学是 768,是不是很熟悉,他就是 g p 模型,它的参数是这样子的,然后他的科学是参数是 1.25 个亿,也是贝尔特贝斯,他的我心的大小 g p 三米点 24 层每一层大小是 1024,然后大家知道这个尺寸是贝尔特拉去的尺寸,然后在后面几个模型呢就是陈塑没有变,
但是你每一层的那个宽度有增加,然后看到 1.3 这个模线虽然之前我们在讲图画的时候,讲到这个结果时候,我们说这个结大概等在于 g p 二的模型。G p 二的大小是 1.5b,但实际上它的大小是跟 g p 二是不一样的。G p 二在这个地方其实它有 48 层,但是它的模型的宽度是要窄一些,所以 g b 三 xl 跟 gp 比,它是要浅一线,然后要宽一些,然后他一直甲成加到最后就是 g p 三 175 或也简称是 g p 三。这个模型的话,
他用的是 96 层,然后面一层的大家一经到了 12000 的左右了,所以这个已经是非常非常大的一个尺寸了,然后大家可能会问好这些参数怎么样定出来的?那我觉得这个可能是作者拍拍脑袋吧,但我们知道就是说你把你陈数增加的时候,呢你的宽度也应该增加,我们知道,把陈数增加的时候,你的宽度也要对应的增加,因为你的计算复杂度是跟你的宽度是频分关系更成熟是现线关系,它整体来说,g b 三的模型是比较偏贬一点的,比如说 g p 三最大的模型跟前面比,
那就是 16 倍的大小关系,但是,在 96 这个参数上呢,其实跟前面比也就是最终是八倍的关系了,然后看到量的大小在大小可以看到,当你训练很大的模型都他用的是 3.2 个 million。也就是说,你一个小批一样,里面有 320 万个样本。这是一个非常巨大的一个 pn 大小了,这个对你内存的考也是非常大的,因为你在计算的时候,因为你在计算梯度的时候,你中间变量的那一个大小是跟你的批量大小成正比关系的。当然,在分布式的情况下,
假设你在机器与机器之间用的是数据并行的话,那么你每台机器要计算的判大概就是 320 万,除以你机器数量的大小,所以如果你有很多来机器的话,你 100 或上千乃机器的话,每台机器也还是能撑住的做的。有提到,你为什么要用相对来说比较大的批量,大家因为你批量大小一大的话,你的计算系能会好,就每台机器的并行度更高,而且你的通讯量也变低,所以分布式是比较好的。之所以你在小的模型你不有很大的偏大小是因为对小的模型其实是更容易过,
你和一些就是你需要用一个相对来说,比较小的批量的大小,这样子导致你在采样的手数面噪音是比较多的,然后你当你的模型变得很大的时候,你相对来说,用大的批价大小,你降低了 pr,里面来噪音好像对大的新来说,问题不是那么的大,这有一点点反直觉啊。这一块其实最近有很多工作去研究,为什么这么回事?当你的模型变得越来越大的时候,似乎你的过敏和没有那么的严重,大家怀疑有两个原一样一个原因是说你神经网络它背后这么设计下来,
大家训练出来能得到比较好结果。其实背后有一定的后使得它不那么容易,就像简单的 mp 一样直接的这那么过拟和了,第二个是说当你的模型变得越来越大的情况下,而且在有结构的情况下,它能搜得了范围更广,而且这样就更有可能去概括到一个可能存在的一个比较简单的一个模型架构,如果你的模型比较小的话,你可能搜索空间都搜不到那一个简单的模型那边去,但你模型很大。需要那的 sd 能够帮助你去找到那一个模型,最后导致你的泛化精度比较好,
当然都都是一些猜想,啊大家有在做研究工作,我们在座里就不展开,给大家讲了,大家最后学习率,啊学习率,他就是当你批量大小变大的时候,你的学习率,他是往下剪的,这个其实也是跟之前的一些工作,他的检论是项悖论的。啊之前,facebook 的一个工作是说当你的批上大小网上真的时,你的学习率要线性的往上,但这个地方他其实是一个反过来的,他学习的往下降,作者在段落中有提到,为什么他是要往上合?往下啊大家可以去看一下他文章里面提到的原始论文里面的解释,
反过头来看 2.1 章,啊它真的就是比较短小的就是两段话,就解决了一种半夜的样子。就是说,在一篇 63 页的文章里面整个模型的架构就写了不到半演,而且这个地方你根本就没写清楚,是说我的模型跟 g p 二是一样的啊。那么你再去看一下级 ppt,然后说我在上面又做了一下改进呀。用了一个叫 p 结构,你得也去看这篇文章,然后这个地方还提了一句说,g pr,其实跟 g p 一改了,这些东西就导致说作为一个读者的话,你想搞清楚 g p 三整个模型长什么样的话,
你得去读一系列的参考文献。当你这篇章已经有 63 页的情况下,我觉得这么做是没有那么的必要性的,你在这个地方就给大家讲一下。G p 二模型长什么样子?甚至是 g p 模型长什么样子以及说你这个 p 长什么样子,你就算是放在一个相关工作里面或者放在后面都是可以的,因为这样的话,会给没有读过之前那些文章的读者带来很大的便利,这是因为你去读前面工作的话,你还得把它的完整的故事读一遍,对吧,他的记号用能什么他的这些表达是什么样子?
然后我们已经读到这个地方了,所有的标号,啊整个写作风格,我们已经读下来是比较熟悉了,如果你在这个地方写清楚,或者甚至是你在后面的附录写清楚,那我也不需要重新再读一个新的故事,还是直接知道这个技术细节上什么样就行了,这也符合这篇文章卖的就是上下文的学习。当然,我们这个不是要批评这篇文章写得不好,啊只是给大家指出了说独自篇文章上遇到这样子一些障碍,大家自己在写作手,可以想办法去避免这样的事情。第 2.2 节讲的是,
他的训练的数据,当你要做一个很大的模型的是,当你的训练数据就得非常大了,特个地方,他们的训练数据是基于 com 的。在 g pd 二次篇文章里面他有提到说我们可以考虑 com,但是他觉得 com 里面的数据太脏了,用起来比较难,所以他采用了是另外一个啊在这个地方,如果你想训练一个比 g pd 二要大 100 倍的模型的话,那它得不得不去重新去考虑 com 这个数据了。具体来说,它做了三个步骤来使得这个数据让它变得更干净。首先,
他们过滤了一个版本,然后是基于他的相似性和一个更高的一个数据集,具体说他干了什么事情,呢啊大家回一下在 g ppt 二里面,他把的上面爬下来,然后把卡码大于三的那些帖子跟你下载下来,作为一个高质量的网络数据机。那这个地方他干的事情就是说把 com 下下来,然后呢把它的样本作为复力,然后之前 g p 二那个网页数据集啊作为正理。那个是高质量的 com 目框,你认为大部分是低质量的,然后在上面做了一个很简单的逻辑,做一个二分内,
正内是 g p 二的爬下来的术语机负类是 com 里面的。那么接下来做预测对 com 里面所有的网页拿出来,如果分类器认为你是偏正类的话,就是说你的比较高的话,那么他就留下来。如果是如果是判断出来很复类的话,那么就是过滤掉第二个是他做了一个去虫的过程就是说,如果一篇文章跟另外一篇文章很相似的话,那我们就把这篇文章去掉。它。具体用到的是一个加造哎 sah 的算法,它可以很快的判断。一个集合,一篇文章是一集合,就是一些词的集合和另外一个很大的一个集合之间的相似度。
这个在一里面是一个非常长的技术,如果大家不熟悉的话,可以就看一下。这也是在面试中间,大家很喜欢问的一类问题。那第三个是说我们有加了一些已知的高质量的数据,就是把之前的贝尔特 g p 二啊。G 的所有数据都拿过来,也加进来,最后就得到一个非常大的一个数据机了,可以看一下,在放在下面这个地方。首先,第一行就是空目,就是他们新价进来的数据。这里面一共有 41000 个字台,就是 g p 二用的数据机,它上面一个比下面一个大 20 倍的样子啊。
但是它的已经大了 100 倍啊。然后接下是书的数据结和 v k 点,就虽然 com 里面给你带来了大量的数据,但是作者认为它里面质量还是相对来说比较差的,所以在采样的时候,它是用了稍微不一样的采量率,所然 com 你比后面这些加起来呀大那么七八倍的样子,但是,在采样的时候,也是说一个批量大小一个 100 万大小的批量,里面也就是 60% 的数据是来自于 com 有 22% 的数据是来自于的,就你看到 com 框里面的数据也就比下一个多三倍。
虽然你的大小上来说多了 20 倍,而且下面这些 k pd 啊虽然它的大小比你上面要少很多很多,但是它的权重并不低,也就是导致说在裁料的时候,他大量的采样的不 kp 不可一和泰数据这样子保证你这个小批让里面有大部分的数据,它其实的质量还是很高的,但具体来这个权重怎么来的,好像做这也没有解释的。那么清楚了,二点 30 个呃非常短小的段落来讲整个模型怎么训练的?啊这个又是这篇文章不那么厚,到了一个地方。G p 三这个模型是非常难训练的,
你想他有接近 2100 个科以学习的参数。整个模型是非常大的,你训练它的话,当然需要分布式训练,然后你需要做非常好的模型分割和数据分割,然后他说它是在一个 100 的,有的贷款很高的集群上训练的。这个集群来自于微软,但实际上说他用的是 djx 万的一个集群。那里面的贷款是非常非常高的,一般的人是买不起,所以他就依句话叫带过了。虽然他说我在复鲁比里面有讲这些东西,实际上他也没讲什么东西就讲了一点草山是怎么训练的这一块啊如果要真的讲的话,
其实有很多很多东西可以说 2.4 解释讲模型的评估。跟之前不一样,因为这个地方它不需要做微条,所以它不需要一个。额外来章解说我唯一条就怎么做了,而是说我预训练模型好了,这我就直接对他进行评估。在评估的时候,他用的是上下文的学习,啊具体来说,它在每个下游的任务里面,他的训练级面采让个样本作为你的条件,但 kk 等于零啊一啊或者十到 100,然后它的用的是森冒号或者冒好,只是说我要做分类的时候,比如说,那么我就把几个样本采样出来。
放那前面你在前面加一个我要干什么事情,如果你是二分类的话,那么你的答案要么是去,要么是 false,而不是说一个灵和一,因为零或一在训练数据中出现的概率没呢?和 f 那么高。接下来,如果你的答案是一个自由的形式的话,比如说,我在做问答的时候,假设你的答案是要真的给我回答一个自己编出来答案的话,那么他就采用的是冰塞区,就是跟机器犯一样啊。我生成一个序列出来,然后用冰塞区去找到一个比较好答案,所以到这里他就讲完了他整个模型的部分可以看到。
虽然到这个地方已经有实业的样子,啊但实际上他真正的讲模型啊训练。那一部分是相当相当的少的,他画了很多时间去讲,他整个设定长什么样子?换一个图告诉大家,所以在那么长的论文里面就那么一点点地方讲,你真正的干货是一个比较奇怪的做法,这也是为什么我们在之前先给大家讲的 g pd 和 g p 这篇文章再来讲,gp 三,如果你直接读 g 三这篇文章的话,你会发现读起来还是不那么容易的,接下是长达二事业的结果,我们就不给大家一一的详去讲了,
这给大家过一下比较有意思的一些图吧。下面第一个图展现的是不同大小的模型,在训练的时候,他跟你的计算量的一个关系。轴表示的是计算量你的歪轴表示的是你的验证的损失,它地方用验证损失是因为他发现验证损失。跟你这些子任务上的精度是有一定关系的,所以能够很好地表示预训练模型的一个好坏就每一根线。啊表示的是一个参数的模型,当你训练时间变长的话,你的计算点会跟着增加这个地方每一根线。啊表示的是一个不同设置的模型,
这个黄色表示的是 g p 三最大的那个模型,当这个线表示的是最小的个模型,当你随着你的训练的增加,那么,你的计算力会增加,因为它算然审理到目前为止所得计算量可以看到这地方基本上就收敛了。虽然你的计算还在往上涨,但是你的损失没有再往下加最好的一个权衡这个地方相对计算量和损失来讲,最低的是这个点,就是说你训练到这个地方就差不多了,你不用往下训练了,如果你要往下训练的话,你把模型做得更复杂一点,所以你把所有这些模型它的最好的这个点啊妈成一条线的话,
你要发现这是一个叫做 pa 烙的分布。也就是说,在你最好的情况下,就是说你找到一个合适的模型,而且不用训练过度训练的情况下,那么你随着你计算量的指数的增加,你的损失是线性的。往下降,这个一直是继续学习的一个痛点啊就是当你想持续线性的提升,你的精度的时候,你得不断的指数去翻你的数据量。数据量当然弄起来是很难的一件事情,二个是说你数据量增加之后,你的计算量也是跟着指数的增加,这个地方讲的是我的数据固定的时候,
我如果想线性的降低我的损失,我一样的计算量都得指数的往上增加。当然跟人类比还是差的太远,呢人类的大脑相当于一个 60 瓦的一个灯泡的号栏,然后人。那在学系的时候,远远的不需要那么多的样本,你想想,你学会阅读的时候,你要读多少本书学写的,你可能读小学语文。那几本书就行了,但是他这个地方,他把整个互联网上东西全部抓了下来,才能够学习到可能更人类相比还是有点差距的地方,所以我们还有很长的路要走啊。然后再往下面看很多这样子图,
啊它这个地方轴还是表示了你模型的参数的大小到后面这个线就是你最大的模型,然后你的轴是你的精度,这个地方是使用直得最好的模型啊人类的这个地方,然后在这个地方,他发现,当你增加模型大小的时候,他当然是能够超越目前最好的那些这些受到的算法,而且如果你使用非的话,跟人类的精度还是有那么接近的地方,在这个地方,然后,但下面很多这样子的图啊在这个地方,他讲的是一个叫做 open 妹的一个 q v,就是在开放区域的一个问答,
然后他对比的是上来自于顾客的一个算法,你肯认为是编码器减全部拿过来。贝尔特用的是编码器。G p 用的是解码。G p 用的是编码器,解码器都有,然后你如果用做微调的话,g p t,其示你用啊。的和是汪笑的,他都比太要好了,然后你往下面翻的话,这也是另外一个的一个任务,然后这个是使用微调的时候,最好的一个季度。G b 三最大的模型已经跟他已经非常接近了,然后这个是机器翻译每一根线表示的是一个语言。翻译到另外一个语言实现是表示别人翻到英语,
那虚现表示英语。翻到别人,你的歪则认是不这个分数啊。这是记翻译最常见的分数,然后有意思的是说你看到别人。翻到与通常来说,比英语翻到别的语言要好,然后你往后面翻很远之后,你看到用 g p 生成的一个新闻稿。啊标题啊灰色部分是给 g p 三的输入啊。后面这些黑的部分就是是 g p 写出来的,让基本上你看一下,写的还是模式样的,让这里面有年份有各种数字呀,各种百分比啊。就讲的是模是一样的,所以这个地方有点的可怕。
G 三瞎扯起来真的是脸不红心不跳的是模是一样,然后后面又是一些样力,怎么让 gp 三做题就是说就是我告诉你一个词,他大概意义是什么?然后用这个词来造句,黑色就是 gp 造成来的句子,它基本上 g pt 三给你写写作业是没有问题的,啊在我们就很简单的给大家讲了一像实际,如果你去做这一块相关的话,你可以找到对应的那些数据信去仔细了解一下,啊如果只是想知道他大概模型的效果的话,我们就这么简单就过去了。接下来我们来看一下第五章,
讲的是这个模型的局限性,在这一章里面,作者列举了非常多的局限性。我们来稍微看一下他到底是什么?首先,他说,虽然我们笔记比掉好很多啊。但是我在文本生成上面呢还是比较弱的。就是,如果我让 g p 三生成一个很长的文本的话,可能可能给了几端之后,他有把上面的东西重新回过来写一下,所以如果你想让他来帮你写小说的话,就是比较难的,因为他很难得到一个剧情的的。往前推,但如果你告诉他说这一段我们要讲什么的话,他很有可能能把你补全的是模式样,
第二个时他说,我有一些结构和算法上的局限性。他讲的一个主要的局限性是说 gp 三因为用的是语言模型,它是往前看的,它不能像之前贝尔特尔反过放下来看,这也是一枚 g p 使用的是的。解码器的原股,然后他讲的另外一个居原性是说因为你训练是语言模型,每一次你要去预测下一个词,所以它这个地方是每一个词,啊它都是很均匀的。去预测下一个词,他没有告诉你说哪个词比较重要,哪一个词不重要,我们知道在语言面很多词都是一些常见词,
但是没有太多意的虚词,所以导致整个原模型花很多时间去学习,在虚词还不像真的要教小孩一样的告诉你这个是画重点,这个才是要去记住的东西。当然,他还有说我因为我用的只是文本啊,所以我对别的东西没见过,比如说没去过 video 长什么样子没见过。是的,这些物理的交互叫什么样子,因为人在学习的时候,读书只是整个人的活动中在的一块,所以他也就是在这一块做比较好,但是别的方面他基本上是没有涉及的,他还讲了一个是你的样本有效性不够,
因为你为了训练这个模型,我基本上这把整个网络上的文章都给你下下来了。那对人来讲,这个真的是太可怕了,另外一个问题,作者说,也可能不叫问题,就是不确信,是说,你在做这种,给你多个样本,在做上下文的学习的时候,他真的是去从头开始学习吗?他真的是说,我去通过你有了样本学写这个样本是长声样?还是说,我就是跟这个样本在我之前的文本里面找出相关的,然后把它记出就行了,就认出来这个任务。这两个当然不一样,我们当然喜欢说你从头开始学这个途径。
这样子的话,真的碰到一个你的训练样本上没有出现过的任务的话,我也能够泛化过去,如果就是我根据你的样本,从我的训练记忆里面把它相的东西找出来的话,那就真的最后拼的是你的训练数据的大小了,另外一个跟之前样本有效性的相关的,就是说训练起来非常的贵,最后一个 g b 三根很多深度学习模西一样都是无法解释的,就是我给你个数,然后你反和给我一个看上去很不错的。输出,但我并不知道你是怎么样?得到你的手黍的,你里面哪些权重真的起到作用,
而且你整个决策怎么做的?特别是对 g p 三那么大的模型来讲,去找出里面这些做关键决策,这些全重非常难的,所以我们最多能说 g 三真的就是大力,初奇。记了,接下来是对 g 三可能的一些影响的一些讨论,因为这个模型以及非常强大的可以直这接拿过去用了,就是说不署在生产环境里面。一旦你的部署到生产环境里面的话,那么,肯定会对人会对社会产生一些影响,最简单是它是不是安全的,大家不要觉得一个模型,它能够对人做成多少危害,
如果你真的依赖一个模型,做一些很重要的决策的话,那当然可能会带来很大的影响,ok,应该的很多工作有这样子讨论,我觉得是非常好的。那表示这个团队是很大的社会责任感的,我们这里简单的给大家过一下它。首先说,我这个模型可能会被用来做坏事,在 6.1 点一里面讲到说你有可能是散步一些不时的消息,生成一些垃圾邮件或者钓鱼邮件啊。然后论文造假,我们之前有看到他生成的那些新闻稿啊真的人是很难看出来区别的。我们读篇新闻的话,
你们对你面的数字啊一些很多事情,我们通常不会下意识的去怀疑他觉得你既然记得把他写出来。那么一定是你做过调查的,如果有人用疾三大量的生成,这样子的文件的话,可能会有很多读者获取信里面的东西,虽然现在很多这样的过滤机制,啊比如说你的邮箱里面会判断一份邮件是不是垃圾邮件,但如果 g 三能够大量的生成这样子的文章的话,那么,肯定是有一小部分的。让和这些机制,从而能够对人产生影响,然后他又讲了一下公平性啊偏宜。
啊比如在性别上,因为他下的文章里面很有可里面男性这种词居多。比如说你让 g p 去回答一个侦探是一个男人,还是一个女人,那么,g p 在很大的可能性上认为这是一个男人,接下来他调查来一下 g ppt 对一些性别的一些偏见,作者让 g p 回答信,或者是就是男性的,是怎么样的女性会怎么样的,然后他去判断一些词出现的概率,吧那些比较偏见那些词拿出来。比如说,对男性来说,g p 可能生成他是比较难的。对女性来说,
他很大概率会生成是非常漂亮的,就漂亮这个词不是一个贬义词,但是漂亮意味着是说你对女性的外表比较在意,这是一个偏见,第二个是对种族。比如说这一个啊女人非常的什么,你可以换成白的黄的黑的,然后下面这个图表示的是不同大小模型,对不同种族的一些证明还是负面的评价,这里您表示的是正常正的,是表示的是这这个种族比较正面的反馈数是表示比较负面的,对黑人就是这一根线相对来说比较负面的,但是,对于审整体来说是比较正面的,
虽然作为亚洲人看到这个结果可能会比较开心,但是,当你发现一个模型对不同种族的区备有那么大的时候,你可要注意到说可能换一个模型。那个模型可能是丑视亚洲人的,但还有是可能有宗教啊宗教之间相互歧视也是非常严重的最后一点,关于的是能耗,因为你训练 g p 模型啊需要几百台机器训练很多天。那么一台机器,那么就是几千瓦的能耗的话,那么,训练下来,你的能耗也是相当夸张的,最后是他的结论,他说,我们做了一个有 1750 意参数的原模型,
然后在许多的 lp 的任务上面,我们做了 the one 的学习。在很多情况下,他能够媲美到使用更多代表号数据的基于微调的算法,然后他的一个卖点是能够生成高质量的一些文本。让他们展示的一个不用基于微的一个可能性,然后我们对整个 g p t g p tr g 三测三个工作做一个评论,你可认为 g p 是起了一个大早,他先把成这个模型拿过来做预训练,然后证明他在效果上很好,但是没想到在选择路线上啊二学一的时候,选择一条路,
但是,没想到另外一条路走得更容易点是贝特和他之后的工作,但作者没有气馁,啊因为我有钱,我有人,所以我一条路走到 g p 二就是把模型做了更大,然后尝试一个更难的问题就是不再下游的人。务上做微调,如果你发现你还是打不赢的话,怎么办?那就再饶人吧,然后再准备一点钱,我做一个更大的 100 倍更大的模型出来,所以后搬回去,不管怎么样?G p 系列给我们开了演讲,让大家发现语言模形式可以暴力出奇迹的。