我们将训练英语和西班牙语的双语模型。在本节结束时,您将拥有一个可以总结客户评论的模型,如下所示:
# Preparing a multilingual corpus 准备多语言语料库
我们将使用 Multilingual Amazon Reviews Corpus 来创建我们的双语摘要生成器。此语料库由六种语言的 Amazon 产品评论组成,通常用于对多语言分类器进行基准测试。但是,由于每个评论都附有简短的标题,因此我们可以将这些标题用作模型学习的目标摘要!首先,让我们从拥抱面部中心下载英语和西班牙语子集:
from datasets import load_dataset
spanish_dataset = load_dataset("amazon_reviews_multi", "es")
english_dataset = load_dataset("amazon_reviews_multi", "en")
english_dataset
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})
如您所见,对于每种语言,train 有 200,000 条评论,每种语言 validation 和 test 拆分都有 5,000 条评论。我们感兴趣的评论信息包含在 review_body 和 review_title 列中。让我们看一些例子,创建一个简单的函数,训练集中随机抽取样本:
def show_samples(dataset, num_samples=3, seed=42):
sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
for example in sample:
print(f"\n'>> Title: {example['review_title']}'")
print(f"'>> Review: {example['review_body']}'")
show_samples(english_dataset)
'>> Title: Worked in front position, not rear'
'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
'>> Title: meh'
'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
'>> Title: Can\'t beat these for the money'
'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'
我们将专注于为单个产品域生成摘要。为了了解我们可以选择哪些域名,让我们转换 english_dataset 为 pandas 并计算每个产品类别的评论数量
english_dataset.set_format("pandas") 改变了数据集中表的组织方式,其他的没变。原先表是用字典的形式存放的,现在变成了 pandas.core.frame.DataFrame ,
english_dataset.set_format("pandas")
english_df = english_dataset["train"][:]
# Show counts for top 20 products
english_df["product_category"].value_counts()[:20]
home 17679
apparel 15951
wireless 15717
other 13418
beauty 12091
drugstore 11730
kitchen 10382
toy 8745
sports 8277
automotive 7506
lawn_and_garden 7327
home_improvement 7136
pet_products 7082
digital_ebook_purchase 6749
pc 6401
electronics 6186
office_product 5521
shoes 5197
grocery 4730
book 3756
Name: product_category, dtype: int64
仅使用 book 和 digital_ebook_purchase 部分数据集,使用 Dataset.filter () 函数。
def filter_books(example):
return (
example["product_category"] == "book"
or example["product_category"] == "digital_ebook_purchase"
)
现在,当我们将此函数应用于 english_dataset 和 spanish_dataset 时,结果将仅包含涉及书籍类别的那些行。在应用过滤器之前,让我们将 english_dataset 的格式从 pandas 切换回 arrow
english_dataset.reset_format()
然后,我们可以应用过滤器功能,作为健全性检查,让我们检查一个评论样本,看看它们是否确实是关于书籍的
spanish_books = spanish_dataset.filter(filter_books)
english_books = english_dataset.filter(filter_books)
show_samples(english_books)
'>> Title: I\'m dissapointed.'
'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
'>> Title: Good art, good price, poor design'
'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
'>> Title: Helpful'
'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'
好的,我们可以看到评论并不严格地与书籍有关,并且可能涉及日历和电子应用程序(如 OneNote)之类的内容。尽管如此,该领域似乎可以训练一个总结模型。在我们查看适合此任务的各种模型之前,我们还有最后一点数据准备工作要做:将英语和西班牙语评论合并为一个 DatasetDict 对象。 Datasets 提供了一个方便的 concatenate_datasets () 函数(顾名思义)将两个 Dataset 对象堆叠在一起。因此,要创建我们的双语数据集,我们将遍历每个拆分,连接该拆分的数据集,然后随机处理结果以确保我们的模型不会过度拟合到一种语言
english_books.keys()
dict_keys(['train', 'validation', 'test'])
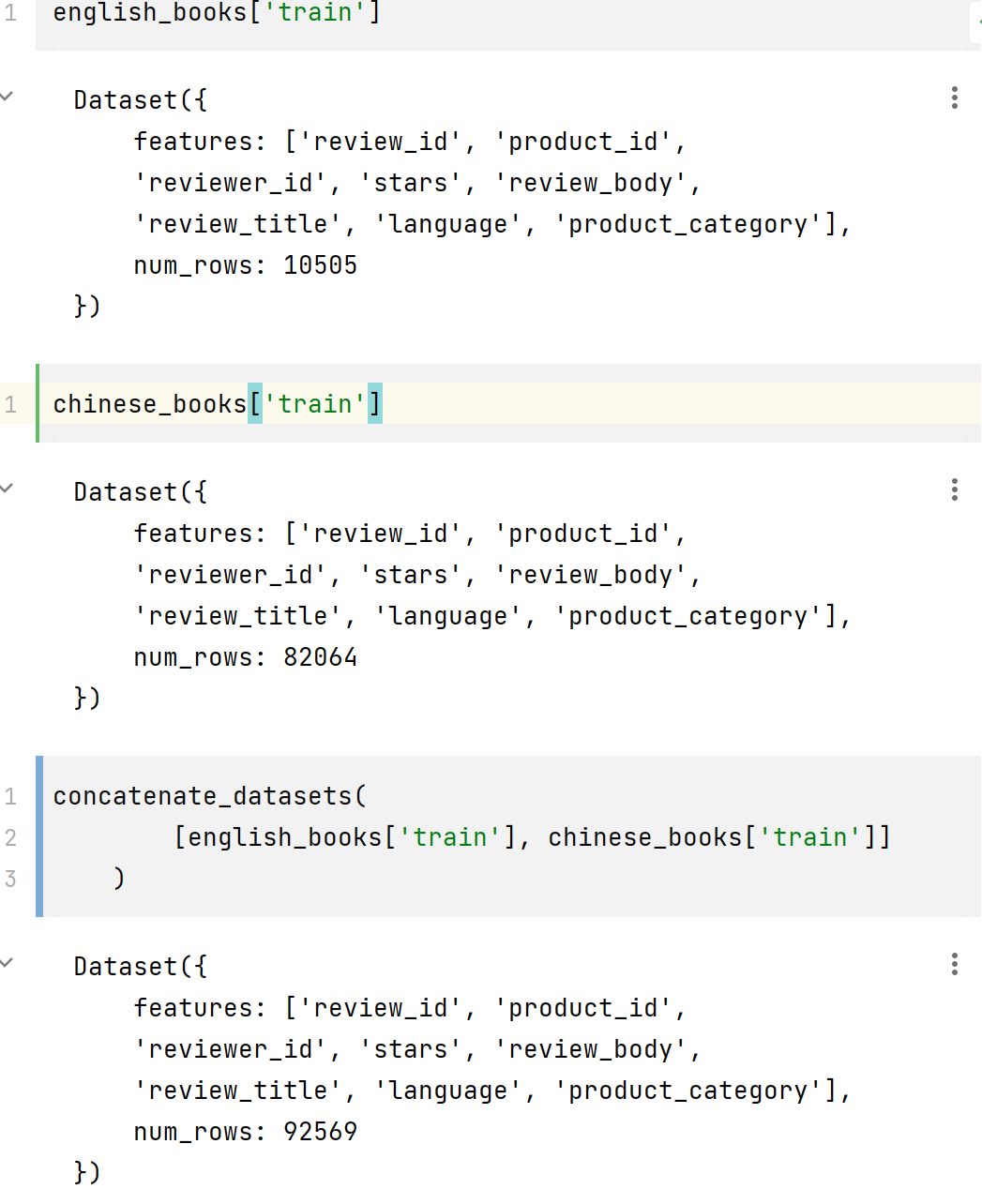
观察上面的行数,可知 concatenate_datasets() 是将两个表的行合并在一起。
from datasets import concatenate_datasets, DatasetDict
books_dataset = DatasetDict()
for split in english_books.keys():
books_dataset[split] = concatenate_datasets(
[english_books[split], spanish_books[split]]
)
books_dataset[split] = books_dataset[split].shuffle(seed=42)
# Peek at a few examples
show_samples(books_dataset)
'>> Title: 小说故事'
'>> Review: 内容是网络小说的那种感觉,整本书的质感还是不错的。 还附赠了一个小本,类似奏折的那种。'
'>> Title: 佳品'
'>> Review: 王叔晖的作品,内容没得说。这本彩色连环画印刷清晰,装帧精美 ,适于欣赏和收藏。但相比起来,个人觉得原稿尺寸系列的西厢记(上、下 册)更优:1.内容多出很多;2.黑白的,线条细腻;3.画幅更大,更能体会原作的震撼。'
'>> Title: What A Beautiful Story!'
'>> Review: I simply loved A PERFECTLY SCANDALOUS PROPOSAL! Poignant, passionate, witty, and wonderful, this book touched my heart with its sweetness! I adored our Heroine, Maggie, and admired her for her determination and spunk. She is so easy to love, and our leading man, Gabriel, is simply perfect for our sweet Heroine. I loved the plot, and it flowed smoothly along. A beautiful ten star read!'
这当然看起来像是英语和西班牙语评论的混合体!现在我们有一个训练语料库,最后要检查的一件事是评论及其标题中单词的分布。这对于汇总任务尤其重要,在摘要任务中,数据中的简短引用摘要可能会使模型偏向于在生成的摘要中仅输出一个或两个单词。下面的图显示了单词分布,我们可以看到标题严重偏向于仅 1-2 个单词:
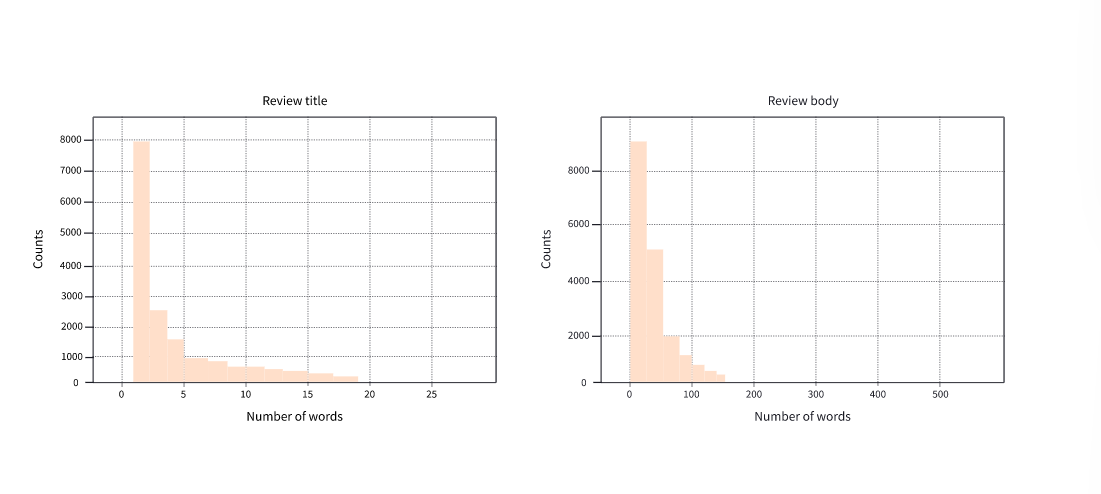
为了解决这个问题,我们将过滤掉标题非常短的示例,以便我们的模型可以生成更有趣的摘要。由于我们正在处理英语和西班牙语文本,因此我们可以使用粗略的启发式方法在空白处拆分标题,然后使用我们的 Dataset.filter () 方法,如下所示:
books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)
# Models for text summarization
从此表中可以看出,大多数用于汇总的 Transformer 模型(以及大多数 NLP 任务)都是单语的。如果您的任务是使用英语或德语等 “高资源” 语言,那就太好了,但对于世界各地使用的数千种其他语言则不那么重要。幸运的是,有一类多语言变形金刚型号,如 mT5 和 mBART,可以挽救。这些模型是使用语言建模进行预训练的,但有一个转折:它们不是在一种语言的语料库上进行训练,而是同时在 50 多种语言的文本上进行联合训练!
我们将重点介绍 mT5,这是一种基于 T5 的有趣架构,在文本到文本框架中进行了预训练。在 T5 中,每个 NLP 任务都是根据提示前缀如来制定的,例如 summarize,模型根据提示调整生成的文本的条件。如下图所示,这使得 T5 非常通用,因为您可以使用单个模型解决许多任务!
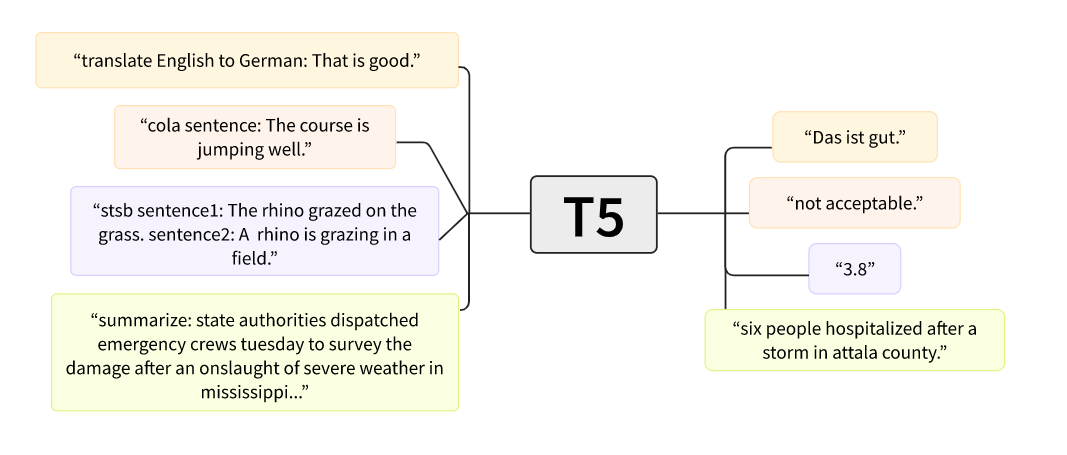
mT5 不使用前缀,但具有 T5 的大部分多功能性,并具有多语言的优势。现在我们已经选择了一个模型,让我们来看看如何准备用于训练的数据。
# Preprocessing the data
我们的下一个任务是标记和编码我们的评论及其标题。像往常一样,我们首先加载与预训练的模型检查点关联的分词器。我们将 使用 mt5-small 作为检查点,以便在合理的时间内微调模型:
在 NLP 项目的早期阶段,一个好的做法是在一小部分数据样本上训练一类 “小” 模型。这使您可以更快地调试和迭代端到端工作流。一旦您对结果有信心,您始终可以通过简单地更改模型检查点来扩展模型!
让我们在一个小例子中测试 mT5 分词器
inputs = tokenizer("I loved reading the Hunger Games!")
inputs
{'input_ids': [336, 259, 28387, 11807, 287, 62893, 295, 12507, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
让我们使用分词器的 convert_ids_to_tokens () 函数对这些输入 ID 进行解码,看看我们正在处理哪种分词器:
tokenizer.convert_ids_to_tokens(inputs.input_ids)
['▁I', '▁', 'loved', '▁reading', '▁the', '▁Hung', 'er', '▁Games', '</s>']
特殊的 Unicode 字符 ▁ 和序列结束标记 </s> 表示我们正在处理 SentencePiece tokenizer,,它基于第 6 章中讨论的 Unigram 分割算法。Unigram 对于多语言语料库特别有用,因为它允许 SentencePiece 对重音,标点符号以及许多语言(如日语)没有空格字符的事实不可知。
# Metrics for text summarization
与本课程中介绍的大多数其他任务相比,衡量摘要或翻译等文本生成任务的性能并不那么简单。例如,给定 “I loved reading the Hunger Games” 之类的评论,有多个有效的摘要,例如 “I loved the Hunger Games” 或 “Hunger Games is a great read”。显然,在生成的摘要和标签之间应用某种完全匹配并不是一个好的解决方案 —— 即使是人类在这样的指标下也会表现不佳,因为我们都有自己的写作风格。
总而言之,最常用的指标之一是 ROUGE 分数(用于指导评估的面向召回的学习 Recall-Oriented Understudy for Gisting Evaluation 的缩写)。此指标背后的基本思想是将生成的摘要与通常由人类创建的一组参考摘要进行比较。为了使这更精确,假设我们要比较以下两个摘要:
generated_summary = "I absolutely loved reading the Hunger Games"
reference_summary = "I loved reading the Hunger Games"
比较它们的一种方法是计算重叠单词的数量,在本例中为 6。但是,这有点粗糙,因此 ROUGE 基于计算重叠的精度 precision 和召回 recall 率分数
scikit-learn 中的参考
对于 ROUGE,召回率衡量生成的参考摘要捕获了多少参考摘要。如果我们只是比较单词,recall 可以根据以下公式计算


对于我们上面的简单示例,此公式给出了 6/6 = 1 的完美 recall; 即,参考摘要中的所有单词都是由模型生成的。这听起来可能很棒,但想象一下,如果我们生成的摘要是 ““I really really loved reading the Hunger Games all night”。这也将具有完美 recall,但可以说是一个更糟糕的总结,因为它是冗长的。为了处理这些场景,我们还计算精度,在 ROUGE 上下文中,精度测量生成的摘要中有多少是相关的:


将此应用于我们的详细摘要会得到 6/10 = 0.6 的精度,这比我们较短的摘要获得的 6/7 = 0.86 的精度差得多。在实践中,通常同时计算精度和召回率,然后报告 F1-score(精度和召回率的谐波平均值)。我们可以通过首先安装软件包 rouge_score 在 Datasets 轻松完成此操作
!pip install rouge_score
,然后按如下方式加载 ROUGE 指标
import evaluate
rouge_score = evaluate.load("rouge")
然后,我们可以使用 rouge_score.compute () 函数一次计算所有指标
scores = rouge_score.compute(
predictions=[generated_summary], references=[reference_summary]
)
scores
{'rouge1': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
'rouge2': AggregateScore(low=Score(precision=0.67, recall=0.8, fmeasure=0.73), mid=Score(precision=0.67, recall=0.8, fmeasure=0.73), high=Score(precision=0.67, recall=0.8, fmeasure=0.73)),
'rougeL': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
'rougeLsum': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92))}
哇,输出中有很多信息 —— 这一切意味着什么?首先,🤗数据集实际上计算精度,召回率和 F1 分数的置信区间;这些是您可以在此处看到的 low、mid 和 high 属性。此外,数据集在比较生成的摘要和参考摘要时,🤗会根据不同类型的文本粒度计算各种 ROUGE 分数。rouge1 是 unigrams 的重叠 - 这只是一种说单词重叠的方式,正是我们上面讨论的指标。为了验证这一点,让我们提取分数的 mid 值
scores["rouge1"].mid
Score(precision=0.86, recall=1.0, fmeasure=0.92)
太好了,精度和召回率数字匹配!那么其他的 ROUGE 分数呢? rouge2 测量双字母之间的重叠(想想单词对的重叠),rougeL rougeLsum 同时通过在生成和参考摘要中查找最长的常用子字符串来测量最长的单词匹配序列。rougeLsum 中的 “sum” 是指此指标是在整个摘要中计算的,而 rougeL 作为单个句子的平均值计算的。
Creating a strong baseline
文本摘要的常见基线是简单地取文章的前三句话,通常称为 lead-3 基线。我们可以使用句号来跟踪句子边界,但这在 “U.S.” 或 “U.N.” 等首字母缩略词上会失败 - 所以我们将使用库 nltk,其中包括更好的算法来处理这些情况。您可以使用如下方式安装软件包