# 编译过程
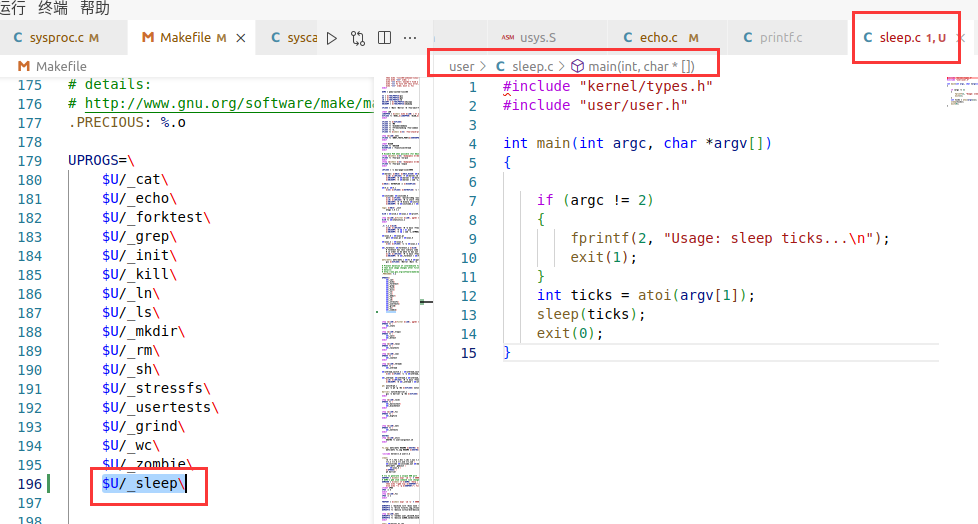
在将程序的名字添加到 makefile 中的变量中。
在 xv6 中输入 ls 后,输出的文件名字和 UPROGS 中的名字一样呐。
UPROGS =》 U PROG S => user programs 用户程序
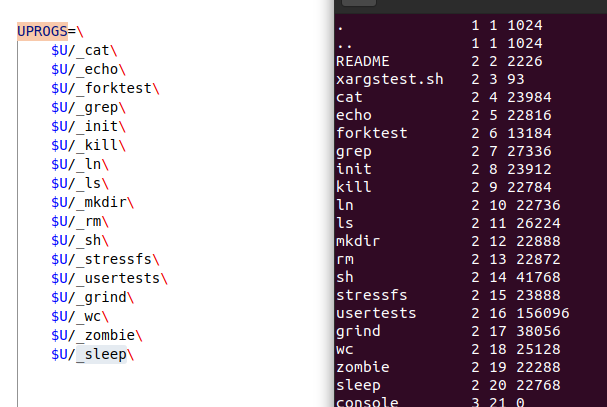
这里的流程是怎么样的呢?是怎么将添加的 sleep.c 文件进行编译的呢?
在初始时或者运行 make clean 命令后的文件如下所示:
运行 make qemu 命令时,会生成 .d 和 .o 文件,在 user 目录下还生成了以下划线为开始字符的可执行文件、 .asm 文件和 .sym文件 。
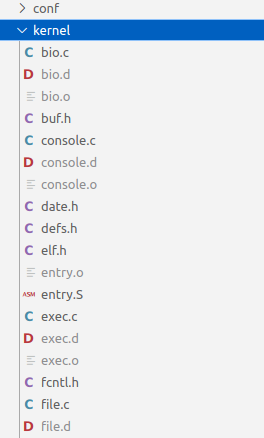

对比了是否在 UPROGS 添加 $U/_sleep\ ,发现如果没添加的话,是没有编译 sleep.c 文件的,一旦添加就完成编译成 o,并链接成可执行文件了。
通过比较是否添加 $U/_sleep\ 时执行 make qemu 的输出,
riscv64-unknown-elf-gcc -Wall -Werror -O -fno-omit-frame-pointer -ggdb -DSOL_UTIL -DLAB_UTIL -MD -mcmodel=medany -ffreestanding -fno-common -nostdlib -mno-relax -I. -fno-stack-protector -fno-pie -no-pie -c -o user/sleep.o user/sleep.c | |
riscv64-unknown-elf-ld -z max-page-size=4096 -N -e main -Ttext 0 -o user/_sleep user/sleep.o user/ulib.o user/usys.o user/printf.o user/umalloc.o | |
riscv64-unknown-elf-objdump -S user/_sleep > user/sleep.asm | |
riscv64-unknown-elf-objdump -t user/_sleep | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$/d' > user/sleep.sym | |
mkfs/mkfs fs.img README user/xargstest.sh user/_cat user/_echo user/_forktest user/_grep user/_init user/_kill user/_ln user/_ls user/_mkdir user/_rm user/_sh user/_stressfs user/_usertests user/_grind user/_wc user/_zombie user/_sleep |

UPROGS 是作为依赖项出现的,那是在哪里作为目标生成呢?
user 目录下的 .d 和 .o 文件都是怎么编译生成的呢?
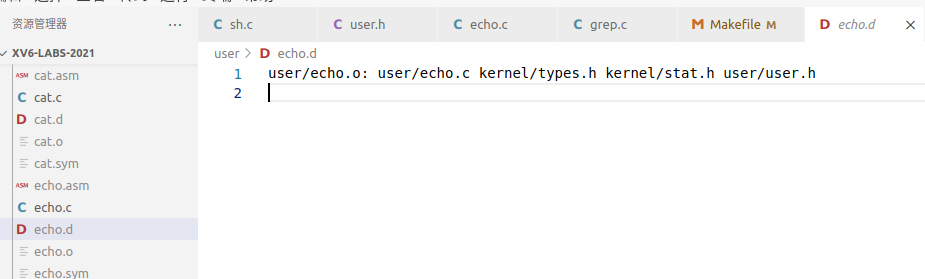
在 .d 文件中写着每个 .o 文件的依赖关系。 .d 文件也是 make qemu 后才生成的,
对 kernel 下的 c 文件编译成 o 文件。
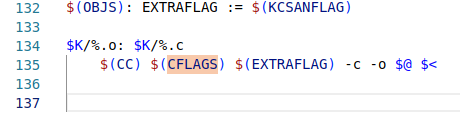
对比 kernel 下的文件和 user 下的文件的编译,发现两者的编译器和编译参数什么的,都是一样的。

对 user 目录下 .c 文件编译成 .o 文件是通过隐含规则完成,可以进行如下的尝试:
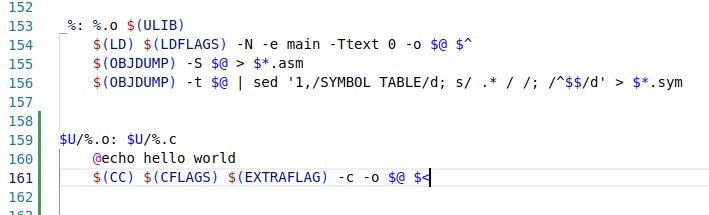
$U/%.o: $U/%.c | |
@echo hello world | |
$(CC) $(CFLAGS) $(EXTRAFLAG) -c -o $@ $< |
之后在编译 user 下的 c 文件的时候发现输出了 hello world。
make 的隐式规则:
https://www.gnu.org/software/make/manual/html_node/Implicit-Rules.html
https://www.jianshu.com/p/755f27ecad9e
编译的目标执行文件是以下划线开头的,但是在 xv6 中的执行文件没有以下划线开头,这里是怎么处理的呢?
# sleep
# 分析过程
在 user 目录下,处理 printf.c、ulib.c、umalloc.c 中没有 main 函数,其他均有 main 函数。
可以使用下面的程序查看
import os | |
user_path = './user/' | |
filename_list = os.listdir(user_path) | |
filename_list = list(filter(lambda x: x.endswith('.c'), filename_list)) | |
filename_list | |
# 输出 c 文件 | |
filename_with_main = [] | |
filename_without_main = [] | |
for filename in filename_list: | |
with open(os.path.join(user_path, filename), 'r') as f: | |
if 'main' in f.read(): | |
filename_with_main.append(filename) | |
else: | |
filename_without_main.append(filename) | |
print(filename_with_main) | |
print(filename_without_main) | |
# ['grep.c', 'usertests.c', 'forktest.c', 'ls.c', 'rm.c', 'ln.c', 'sh.c', 'sleep.c', 'cat.c', 'init.c', 'zombie.c', 'grind.c', 'echo.c', 'kill.c', 'stressfs.c', 'wc.c', 'mkdir.c'] | |
# ['printf.c', 'ulib.c', 'umalloc.c'] |
UPROGS:U PROG S user program s
为用户程序
编写的程序是需要有一个 main 函数的。
对于 C 库函数都是自行写的。
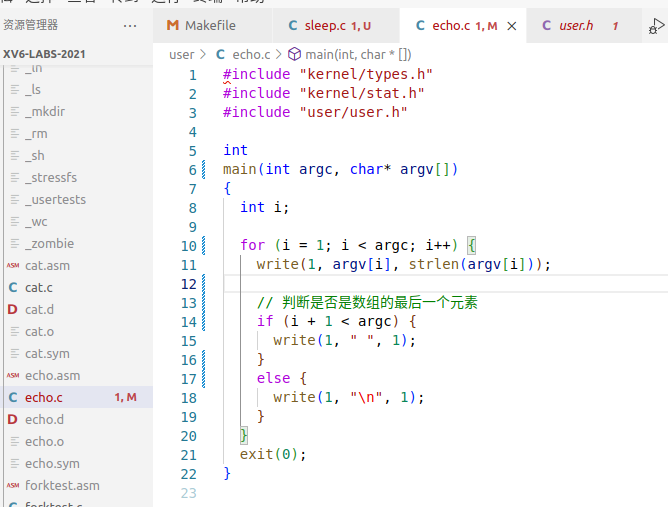
在 ubuntu 下的 echo 命令能够传入文件并打印出文件内容,但是在 xv6 下的 echo 命令仅仅能够输出传入的字符串。
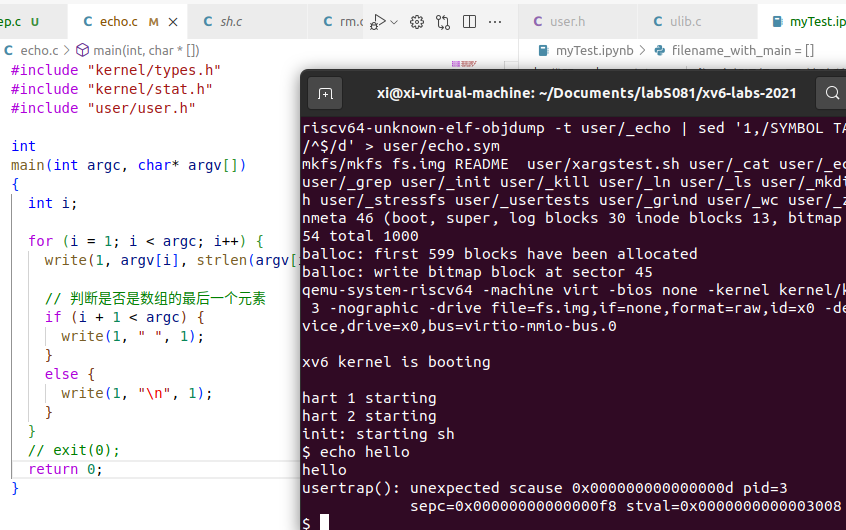
将 echo.c 中的 exit 改为 return 时,发生如下的状况。
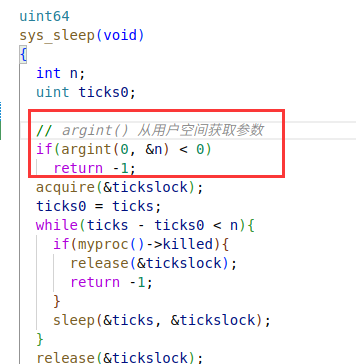
kernel/sysproc.c 中的 sys_sleep
user/usys.S
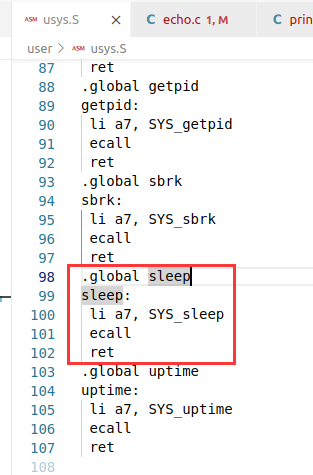
.global sleep 说明将 sleep 设置为全局可调用。
chatgpt 的解释如下:

在汇编语言中是不区分大小写的,因此在 user/usys.S 中的 SYS_sleep 的地址即为 kernel/sysproc.c 中的 sys_sleep 的地址。
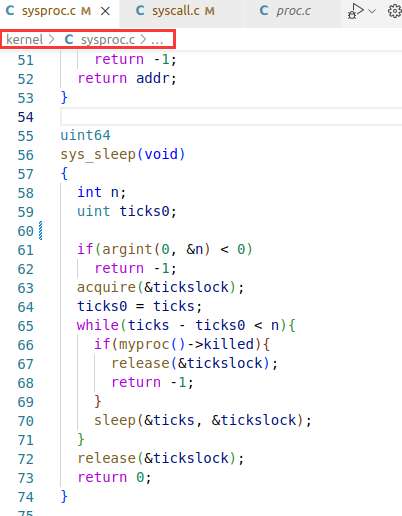
在 user/user.h 中只需要给出 sleep 的生命即可。

上面也即是程序在用户态和内核态的函数转换过程。
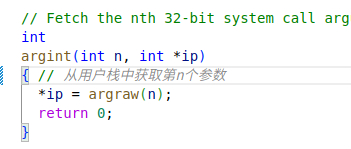
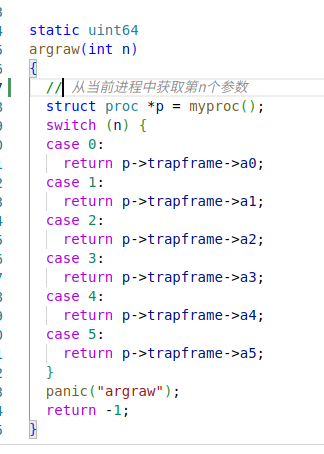
内核态函数 sys_sleep 获取参数的过程分析呢?()
内核态函数好像都是没有参数的。
用户态函数在调用的时候,函数参数和函数地址在内存中的存放位置是怎样的呢?
利用 copilot 获得的解析注释如下:
# 答案确定
在 UPROGS 中添加 $U/_sleep\
在 user 目录下新建 sleep.c 文件,写入下面的内容
#include "kernel/types.h" | |
#include "user/user.h" | |
int main(int argc, char *argv[]) | |
{ | |
if (argc != 2) | |
{ | |
fprintf(2, "Usage: sleep ticks...\n"); | |
exit(1); | |
} | |
int ticks = atoi(argv[1]); | |
sleep(ticks); | |
exit(0); | |
} |
# pingpong
# 分析过程
题目要求使用一对管道在两个进程之间传递字节。
看样子得需要知道这些系统函数调用的功能,参数是啥意思才能做。这部分内容要通过看 xv6 的课本。
在用户态函数(user 目录)中可以使用 write(1, 字符串, 字符串长度); 输出结果,但是在内核态函数中怎么输出呢?
内核态函数怎么返回参数给用户态呢?
在 qemu 中运行程序的时候,只需要在命令行输入文件的名字即可;但是在 Ubuntu 的命令行中需要输入 ./文件名 。
可能是系统变量的原因?
pipe 是内核缓冲区,在 fork 之后,父进程和子进程的文件描述符是独立的。

在上面的代码中, close(p[0]) 是关闭了本进程管道的读端,但是管道对象还是存在的。
在父进程中调用 wait,是因为,子进程要给父进程发送数据,假如父进程提前结束了,那么父进程就接受不到子进程发送的消息了。